基于SU和AMB的网络流量特征选择算法①
2022-05-10庞玉林李喜旺
庞玉林,李喜旺
1(中国科学院 沈阳计算技术研究所,沈阳 110168)
2(中国科学院大学,北京 100049)
随着联网设备的增多,越来越多的网络设备暴露在公网内,网络空间扫描工具Shodan 甚至可以轻而易举获取到隐私家用摄像头的内容.在工业网络中,原本封闭的环境变得开放,联网设备版本难以升级,不易管理,这使得工业网络内的专业设备有着更容易被入侵的风险[1],如果我们能够及时获取联网设备信息,掌握网络中设备之间的拓扑关系,有效的进行资产管理和资产分析,了解设备的脆弱点,及时将漏洞信息和设备脆弱点结合起来,在发生故障时能够及时进行故障定位和故障处置分析.目前现有的网络设备识别研究中大多数都是通过主动探测的技术来发现设备,这种方法会干扰或者中断设备的运行状态,但在实际环境中,大部分设备过时或计算能力较低,并不支持中断或干扰其系统[2-4].基于网络流量特征的被动式识别方法具有干扰性小、自动化高的特点,所以其目前成为学者们的研究热点,也更符合未来的发展要求.
在基于网络流量分析的网络设备识别研究中,利用Wireshark 在特定环境中抓取的网络流量数据包中的特征属性集往往是高维的,这些属性集中存在许多冗余或不相干的属性,这些冗余信息不但会降低数据集的数据质量,也会影响后续网络设备识别效率和精确率,妄加无效的工作量,所以为了保证数据集的数据质量和设备识别效率及精确率,有效地对数据包中的数据特征属性进行降维是一项非常重要的工作.
1 相关工作
目前网络流量特征选择算法在网络流量分类的研究中应用比较广泛,大多数的文献主要是针对网络流量分类的效率和精确率来对网络流量特征选择算法进行研究和改善[5].刘雪亚等人[6]、唐宏等人[7]和赵择等人[8]的工作主要是针对网络流量不均衡,面向网络流量数据中单个类别的分类,刘雪亚等人[6]提出了一种基于卡方算法和SU(对称不确定性)算法的结合来提高小类别的网络流量数据的分类精确率;唐宏等人[7]提出一种基于FCBF 的特征选择算法更容易地选择出来与小类别流量具有强相关性的特征;赵择等人[8]提出一种基于改进一对一算法的集成学习方式把网络流量分类的多分类任务拆解为多个相互独立的二分类任务,其思想的重点不在于特征选择的工程如何改善,而是把重点放在了利用集成学习的策略上来充分挖掘每类流量的数据特征来提高分类性能;曹杰[9]在工作中提出了一种Filter-Wrapper 混合的特征选择模型,其先利用信息增益对有分类贡献的特征进行性能评估排序,在候选子集上再利用Wrapper 方式进行二次特征选择.
但本文的研究目的是选择出能够更高效、更精确地对网络设备进行识别的网络流量特征,Nguyen-An等人[10]提出了一种通过计算网络流量特征的信息熵来对网络设备进行识别的方法;Jeon 等人[11]提出了把网络端口和一系列TCP/IP 协议栈的相关特征字段作为设备识别的指纹特征,但是这类基于人为分析选取的网络流量特征的被动式设备识别方法在通用性,精确度方面还有待提高.
2 算法设计
2.1 FSSA
本文主要是针对网络设备的操作系统类型进行识别,所以针对这个问题本文提出了一种将Filter 和Wrapper 方式相结合,基于SU[12]和AMB[13]的网络流量特征选择算法FSSA(feature selection based on symmetric uncertainty and approximate Markov Blanket),该算法首先在Filter 方式中利用SU 算法选择出对于各个类别具有分类贡献的特征,去除不相关的特征属性;然后在候选特征子集中利用马尔可夫毯算法删除冗余特征,最后再采用Wrapper方式,基于C4.5 决策树分类算法选择出使分类器效果最好的最优特征集,这样不仅可以对特征集进行降维,也可以提高分类器的性能.
2.2 SU 算法
假设样本总数为N,样本中有j个类别的样本,类别用C表示,特征属性集F={f1,f2,,···,fi},SU 可以用来描述特征属性fi和特征属性所属类别C之间的相关性,也可以描述特征属性集F中特征属性与特征属性的相关性[12,14].
首先我们引入信息熵H(F)和条件熵H(F|C)的定义,如式(1)和式(2),其中p(fi)表示fi在特征属性集F中出现的概率,p(cj)表示类别cj的出现概率,p(fi|cj)表示特征fi在类别cj条件下的条件概率.

由式(1)和式(2)可以得到特征属性与类别的信息增益IG(F,C),如式(3).

由式(1)和式(2)推算式(3)可以得到如下关系,此处不再赘述.

最后,由上述4 个公式我们可以得到特征fi与类别C之间的对称不确定性SU(fi,C),如式(5).

首先通过计算特征fi与类别C的对称不确定性SU(fi,C),对所有结果进行一个降序排序,排名越靠前的值其对应的特征对类别分类的贡献就越大,通过选取合适的阈值δ,对于SU 值大于阈值δ的特征,将其放入候选特征子集内.
2.3 AMB 算法
马尔可夫毯是进行特征冗余性分析的一种常用的工具,在一个特征空间中,目标特征的马尔可夫毯包含了它的所有信息,所以非马尔可夫毯就可以看成是目标特征的冗余特征.因此通过发现目标特征的马尔可夫毯就可以精确确定目标特征的冗余特征,从而降低特征空间的维数,达到特征选择的目的[13].
首先引入马尔可夫毯的概念:假设在随机变量的全集U中,对于给定的变量X∈U和变量集MB⊂U且X∉MB,若满足式(6),则称能满足上述条件的最小变量集MB为X的马尔可夫毯.

由式(6)我们可以给出特征的近似马尔可夫毯:若存在特征集合F,对于给定特征fi,使得特征子集MBi⊂F且fi∉MBi,满足式(7)时,称MBi是特征fi的马尔可夫毯.

由式(6)和式(7)我们可以定义冗余特征:对于上述特征集合F,如果满足式(8),即对于给定特征fi和分类C 是弱相关的,并且可以在F内找到它的近似马尔可夫毯fj,那么特征fi就是冗余特征,应该在F中移除.

2.4 算法流程描述
本文提出的算法伪代码如算法1所示,主要分为两大模块,第一模块是Filter 式特征选择,分别利用SU(代码1-5 行)和AMB(代码6-16 行)进行特征初选,第二模块是Wrapper 式(代码17-27 行)特征选择,利用C4.5 分类器,在第一模块选取出的候选特征子集种,依次选取排名靠前的特征放入最优特征集中,并根据这个最优特征集预处理数据集,一边记录分类器训练测试效果,一边进行最后的最优特征子集搜索,最后选择出分类器测试效果最好的特征子集作为最优特征子集.

算法1.算法流程代码F(f1,f2,···,fN,C),δ输入://training set and predefined threshold Fbest输出:,PR //the best feature set and precision rate fi∈F 1.for SU(fi,C)2.calculate SU(fi,C)≥δ 3.if fiF′4.put into SU(fi,C)F′5.sort by descending of F′≠∅6.while fj=getFirstElement(F′)7.fj≠∅8.while fi=getNextElement(F′,fj)9.fi≠∅10.while f′i fi 11.=SU(fi,f j)≥SU(fi,C)12.if fiF′13.remove from fi=getNextElement(F′,f′i)14.fi=getNextElement(F′,fi)15.else fj=getNextElement(F′,fj)16.Ftop=F′17.F*best=∅PR0 18.,=0 Ftop≠∅19.while fi∈Ftop 20.for fi into F*best 21.put Ftop 22.Preprocessed training set S and testing set D using S′23.Training C4.5 model using training set D′24.Testing C4.5 model using testing set PRi 25.calculate PRi≥PRi-1 26.if Fbest=F*best 27.
3 实验分析
3.1 实验环境与数据集
本文使用Weka 平台作为仿真环境,Weka 是基于Java 环境下开源的机器学习以及数据挖掘软件,该软件集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类、回归、聚类、关联规则以及在新的交互式界面上的可视化[15,16].
本文的操作系统指纹数据集分别来自Network-Miner、 p0f、 Nmap 的指纹文件[17-19]设计的指纹特征库,本文对这些指纹特征库进行整理,形成本次实验的数据集.数据集中包含的操作系统类别详细信息如表1所示,所有类别包含的特征和特征代表的涵义如表2所示.

表1 数据集详细信息

表2 数据集特征属性详细信息
3.2 实验流程
本实验根据操作系统的不同类别将操作系统指纹数据集分为7 个数据子集,每个子集中训练集Training与测试集Test 的比例为7:3.
本文提出算法实验流程如图1所示,在实验过程中,分别将未处理的全部特征数据集(10 维特征)、本文提出的算法FSSA、FCBF 特征提取算法[12]、基于改进SU 的特征选择算法[1],通过实验得到的特征子集数目、网络设备识别精确率、网络设备识别召回率、算法时间复杂度、实际算法分类消耗时间进行对比分析,说明本文算法的优势;此外,在实验的基础上,将本文算法的冗余特征分析部分的近似马尔可夫毯算法换成mRMR 算法[20](后文中称之为FSSM),与本文提出的算法做对比实验,验证马尔可夫毯算法的冗余特征分析能力.关于SU 特征选择算法部分对于阈值δ的设定参考了文献[1]中的参数设定,本文算法阈值δ设为0.02,关于mRMR 实验部分实验参数参考文献[20],此处不再赘述.
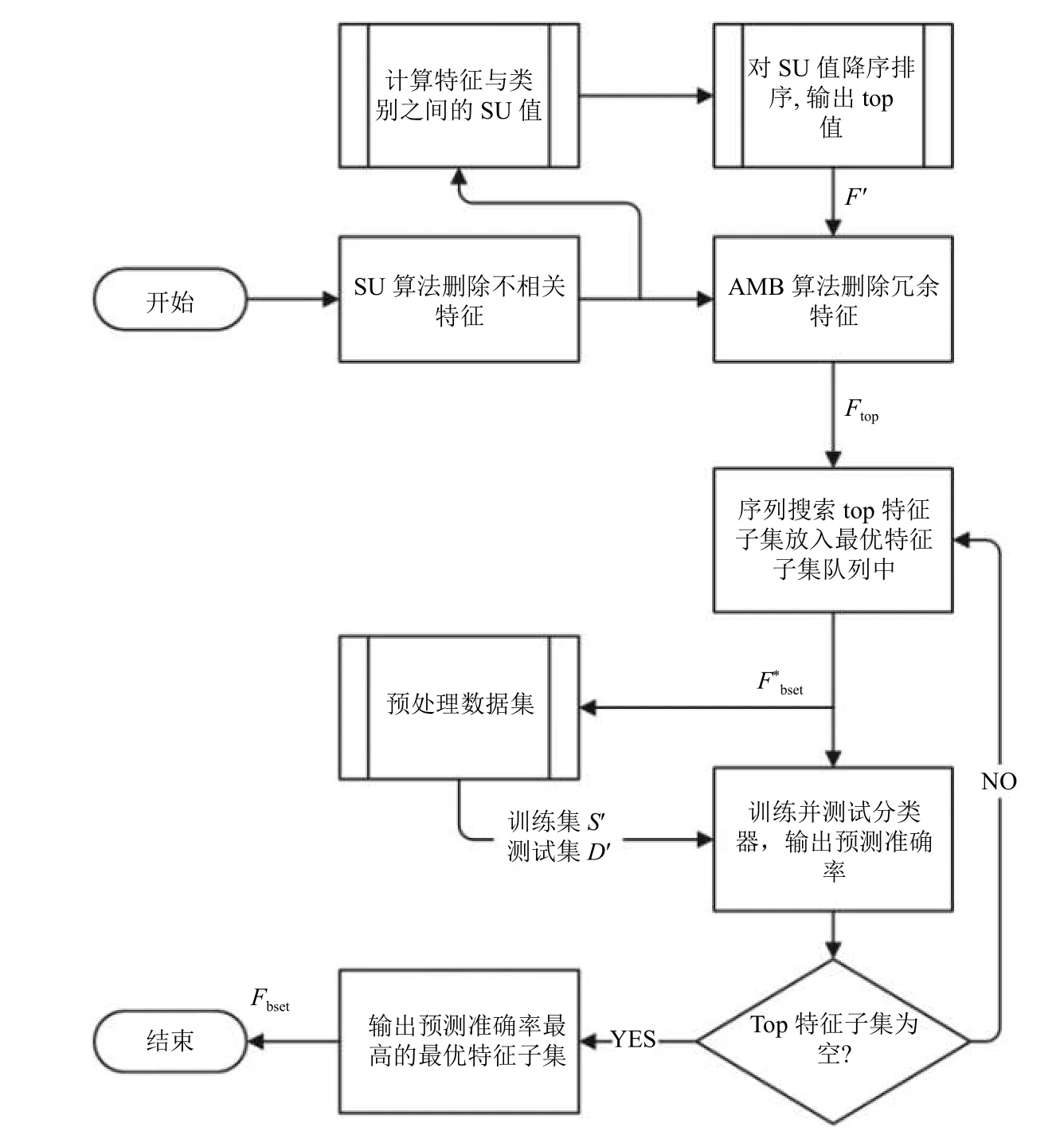
图1 算法实验流程图
3.3 评价指标
本实验采用整体识别精确率和召回率来衡量本文特征选择算法对网络设备操作系统识别的精确性.其中精确率和召回率根据表3 的定义如下:

表3 二分类矩阵
3.4 实验结果与分析
3.4.1 算法识别精确率对比
按照实验方案进行实验,可以得到各特征选择算法获得到的最优特征个数,如表4,可以看出本文提出的算法在各类型样本的特征属性集上都有不错的降维效果,在特征选择的数目上看,对于个别操作系统类型,其它3 种算法和本文提出的算法大致相同,但是本文提出的算法在各类型的数据集上得到的特征数目是基本持平的,其他3 类算法均有波动,说明对于不同类别的数据集,这3 类算法的特征选择结果不稳定;表5 展示了各特征选择算法在各类操作系统类型上的整体识别精确率,可以明显看出本文提出的算法在各个类型的设备识别精确率都较高,其它算法虽然在个别类别上的识别精确率也不错,但是在小类别的数据集上,本文提出的算法明显优于其它3 类算法,这是由于在特征选择的过程中,本文算法加入了Wrapper 式的特征选择过程,直接将分类器的性能作为特征选择的评价标准,这大大提高了本文算法在设备识别上的精确率;表6 展示了各特征选择算法在各类操作系统类型上的召回率,在特征选择的过程中,本文算法能够在小类别的数据(比如Windows XP 和Linux 2.4)的特征属性中选择出更具有强相关性的特征,能够减少小类别数据被错分为其他类别的数量,所以本文算法无论是在小类别数据还是大类别数据上表现都优于其他算法.

表4 各特征选择算法所选特征数目(个)

表5 各特征选择算法的精确率(%)

表6 各特征选择算法的召回率(%)
FSSA 算法和FSSM 算法整体来看特征选择数目相对来说比较平均,但是在小类别数据上可以看出,FSSM 算法选择出的特征明显多于本文算法;在设备识别准确率和召回率上看,本文算法明显优于FSSM,这是因为mRMR 算法原理是用互信息来衡量特征于类别、特征与特征之间的相关性,而本文算法中的马尔可夫毯算法部分利用的是对称不确定性来衡量特征与类别、特征与特征之间的相关性,实验数据也表明,在相同的条件下进行特征相关性分析、不同的条件下进行特征冗余性分析,本文算法选用的马尔可夫毯在冗余特征分析上效果更好.
3.4.2 算法复杂度对比
假定当前特征总数为n,m是数据集的实例总数.表7 定性分析了各特征选择算法的时间复杂度[7,12,21],表8 展示了实际实验过程中,应用各特征选择算法后对数据进行分类的时间,从表中可以看出,本算法由于加入了Wrapper 式特征选择方法,所以在特征选择的时间复杂度上比较大,在实际运行的特征选择过程中时间也较长,但是由于本文算法选择出的特征相关性高,冗余小,所以在分类时运行的时间大大缩小.本文所采用的算法和FCBF 算法均使用马尔可夫毯算法进行特征冗余性分析,在实际分类时间上均比使用mRMR 算法进行冗余性分析的FSSM 要短,所以本文选用的马尔可夫毯算法在进行冗余性分析时效果更好.

表7 各算法时间复杂度

表8 各算法实际分类时间(s)
4 结论与展望
本文主要是在面向基于网络流量分析的网络设备识别应用中,网络流量特征选取的问题进行了研究,针对这个问题提出了一种将Filter 和Wrapper 方式相结合,基于SU和AMB的网络流量特征选择算法FSSA.实验表明,该方法下选择出的特征对网络设备操作系统类型识别的精确率相较于经典的特征选择方法有了一定的提高,在小类别数据上的召回率也得到了提升,但是在进行Wrapper 式特征搜索时性能代价也较高.所以针对实验过程中的问题,如何对网络设备更多版本的操作系统类型进行识别,如何更新完善目前的数据集,如何提高模型的性能,以及除了操作系统信息之外,如何获取网络设备其它信息是我们下一步的工作重点[22].
