卷积神经网络在表情识别上的研究综述
2022-04-12赵宣栋陈曦
赵宣栋 陈曦

摘 要: 近年来机器学习和深度学习在机器视觉方面已取得了很大进展,表情识别已然成为其中的热门领域。表情识别的应用使得计算机可以更好的理解人类情绪,具有较高的研究价值和应用前景。本文归纳了表情识别领域常用公开数据集;介绍了表情识别的基本流程与常见方法,以及不同卷积神经网络在表情识别方面的方法研究与分析;针对表情识别领域现存问题和未来发展进行了分析总结。
关键词: 表情识别; 卷积神经网络; 机器学习; 深度学习
中图分类号:TP391.41 文献标识码:A 文章编号:1006-8228(2022)04-01-04
Research of convolutional neural network in expression recognition
Zhao Xuandong Chen Xi
(1. School of Computer Science and Information Engineering, University of Harbin Normal University, Harbin, Heilongjiang 150000, China;
2. Zhengzhou University of light industry, College of computer and communication engineering)
Abstract: In recent years, machine learning and deep learning have made great progress in machine vision, and expression recognition has become a hot field. The application of expression recognition makes computer better understand human emotion, which has high research value and application prospect. In this paper, the common public data sets in the field of expression recognition are summarized; the basic process and common methods of expression recognition, as well as the research and analysis of facial expression recognition based on different convolutional neural networks are introduced; the existing problems and future development in the field of expression recognition are analyzed and summarized.
Key words: facial expression recognition; convolutional neural network; machine learning; deep learning
0 引言
19世紀,达尔文[1]第一次提出对表情进行研究,直到现在对表情的研究仍在继续。1969年,Ekman等[2]人通过深刻的研究将人的表情详细划分,建立了面部动作编码系统,这一系统对之后的研究影响深远。在Ekman的面部动作编码系统基础上,很多学者通过将人脸划分为多个动作单元,再组合一个或多个动作单元,来描述人的面部动作,进而对人脸面部细微表情进行检测。目前,表情识别不仅广泛地使用在司法、临床、治安等领域,也引起了社会媒体和科学界[3]的广泛关注。
1 基于卷积神经网络的表情识别研究与进展
1.1 表情数据集
人的表情并非单一的,所以收集数据集时很难保证每个表情都具有单一性,加之收集时受外界条件影响较大,而非专业人员又难以准确鉴别,因此专业性的表情数据集数量较少[4],详细数据集情况如表1所示。
1.2 基于LeNet-5模型的表情识别
20世纪末,LeCun研究团队开发了第一个卷积神经网络模型--LeNet-5模型[5]。该模型适合用于字符识别,如果想要使用LeNet-5模型对表情来识别,需要对嘴巴、眼睛以及其他面部皱纹的细微变化分别进行识别,因此需要大量的特征图像。同时,由于其网络结构过于复杂,且对硬件配置要求过高,导致训练时间过长,所以其实用性,性价比较低。因此,在实验中一般使用改进后的LeNet-5模型,增加C1和S1层的特征图数量,降低C3和S4层的特征图数量,仅保留一个全连接层。
改进的LeNet-5的优点是可用于实际自然场景下和非证明的表情识别,其正确率和有效率远远高于LeNet-5模型,并且随着训练次数的不断增加,每批样本的损失函数会逐渐下降,最终逐渐趋于平缓。当训练达到38000次左右时,损失函数的变化就会小于0.001。但是,由于需要更多特征图来检测面部表情的细微变化,因此,需要更长时间来计算卷积,所以改进后的LeNet-5训练时间会相对较长。
1.3 基于AlexNet模型的表情识别
相比于LeNet-5网络,AlexNet网络有很大的改进,主要体现在GPU训练,通过将网络扩展在两个GPU上进行训练,加速网络训练速度和加深网络的层数,且将原LeNet-5网络的7层扩展到11层。加深网络的深度可以增进训练速度,但是同样也暴露出Sigmoid激活函数存在的问题。据研究数据显示,当网络深度随着需求增加时,Sigmoid激活函数出现明显的梯度弥散。为解决这一问题,AlexNet网络选择放弃Sigmoid激活函数,改用Relu激活函数。除此之外,AlexNet网络新加了LRN层[6],从而促进了大的响应神经元,抑制了反馈小的神经元,同时提高了模型的泛化能力。此外,该模型也利用大量的ImageNet和Dropout机制来减少过拟合情况。7342C20B-B95E-461D-9C3C-9DD9AA43235D
1.4 基于VGGNet模型的表情识别
VGGNet[7]是由Google Deep Mind团队和牛津大学合作完成的,可以说是 AlexNet的高配加深版。与AlexNet模型相比,VGGNet通过不断增加网络层数,发现了神经网络的网络深度对模型性能产生的直接影响。VGGNet的卷积核采用小而多的形式,使用了三个3×3的卷积核,而不是一个大的卷积核。这样做的好处是既增大了网络的深度,也没有加大运算量。在相同的感受野下,可得到更为精密高效的计算结果。此外,VGGNet具有较强的场景迁移性,在任何场景与环境上都具有较强的泛化能力。
VGGNet與同时推出的GoogleNet都是在AlexNet网络结构的基础上改进而得到,它们共同的特点就是“深度”[8]。GoogleNet模型的突出点在于模型结构,而VGGNet更注重网络深度。与GoogleNet相比,VGGNet使用三个3×3的卷积核,使原始图像的感受野达到一个7×7的卷积核的效果,但是与一个7×7的卷积核相比,图像经过3次激活函数的非线性变换具有更好的表达性,也能够相对减少参数量,这也是VGGNet远超其他网络泛化能力的根本原因。在实验中,将进行VGG-16网络在Softmax损失+中心性损失+人脸验证损失和三元组损失两种不同训练下的性能统计。在两种损失信号都能达到99.2%的情况下,用VGG-16进行表情识别时,同样以RAF-DB和CK+作为数据集,其正确率可以分别达到67.06%和91.10%。
1.5 基于GoogleNet模型的表情识别
GoogLeNet相对于其他卷积神经网络来说,是较为新的卷积神经网络算法。首次提出是在ILSVRC14比赛上,GoogLeNet是一个深达22层的深层网络[9]。GoogLeNet的研究核心是如何优化卷积神经网络的局部稀疏结构,使其尽可能的接近实际密集内容。
在GoogLeNet中,每个模块的输入都是在上一个分支在获得一个特征映射后,将这些相同比例的特征映射拼接在一起,再传递给该模块。为避免模块的对齐问题,Inception结构采用了不同尺度的嵌套低维滤波器,可以保留多个感受野的局部相关信息。在这种情况下研究发现,使用5*5的卷积核仍然会给程序带来巨大的计算量。为解决这个问题,GoogLeNet选择了与VGGNet完全不同的方法,通过在每个分支上加一个1×1的卷积核,来有效的减少参数数量。
与AlexNet和VGG不同的是,Inception V1用全局平均池化层代替全连接层,这一改进将参数的数量减少到前所未有的少量,但研究人员可以添加全连接层来微调和再训练,以便在其他模式识别场景中使用;其次,为了解决网络深度过深造成的梯度消失现象,Inception V1额外增加了两个分类器层,反向传播使用多个损失信号进行参数梯度计算;最后Inception V3基于NIN思想的精髓,设计了一个精细的Inception模块,以提高网络参数的利用率。
在实验时我们使用CK+数据集进行扩充,进行预处理后进行训练,结果显示,GoogleNet无论是从头训练还是微调的情况下都能够取得比AlexNet更好的识别效果。
1.6 基于ResNet模型的表情识别
2015年,ResNet [10]在ILSVRC 2015比赛中夺冠,进而进入大家的视野当中。ResNet引入了残差单元,利用残差的思想成功训练了深度高达152层的神经网络,从此一鸣惊人。为避免深度网络中的性能下降,ResNet[10]采用了对网络中模块学习目标函数进行变换的方法。打个比方,如果输入n网络模块,那么其他神经网络学习目标函数为H(n),但如果n是直接连接到输出,那么学习目标则为H(n)-n,所以只需要学习最初学习目标和网络模块输入数量的差值即可,这也是“残差”的由来,这样做的最大优势是简化了学习的目标数量和难度,也为超深层网络的训练提供了方向。
在两层残差学习单元模型中,k层直接输入x1到k+2层输出,然后将k+2层输出作为k+3的输出。而只有维度相同的向量才可以相加,所以在残差过程中不能进行池化操作,并且卷积核数和输出数必须相等,否则就必须使用一个1×1卷积进行线性变换。而在第三层残差学习单元模型中,使用了两个1×1的卷积核,可以通过卷积核的个数实现特征图的降维和升维操作。
2016年,KaimingHe等人提出ResNetV2。该模型易于训练,具有较强的泛化能力。与ResNet相比,ResNetV2将ReLU激活函数改为同等映射函数,且在每一层中添加了批量归一化技术。
在表情识别中,ResNet网络在表情识别数据集进行训练时,其正确率高达67.50%和92.21%,比VGGNet和AlexNet都要高出很多,同时其参数量又远小于其他经典网络。
2 存在的问题及发展趋势
2.1 存在的问题
⑴ 缺乏对现实人类的研究。表情识别研究所用数据集绝大部分为基本表情数据集,虽然在这一方面取得了不小进展,但是由于人的表情是多变和复杂的,所以绝大部分研究成品都无法应用到现实中。
⑵ 面部表情数据严重不足。现在已有的表情数据库中每个表情的数据都比较少,而且都非常刻意,表情流露不自然,与自然境况下的表情存有一定的差异,难以成为十分精确有效的数据,并且其中的动态序列图像更是严重缺乏。
⑶ 研究场所多为实验室,缺少真实情况下的训练。表情识别的研究绝大部分是在理想适合的条件下进行的。但是由于自然环境下会出现遮挡物体、遮挡人脸,不同时间亮度不同,以及周围环境等其他的情况,都会对面部表情识别结果产生较大的影响,最终导致实际结果与实验结果有所不同。
⑷ 当前表情识别多数仅能在单一表情情况下识别。人类表情是丰富多彩的,每种表情之间的界限与区别都是模糊的,就像一个人的图片是睁大眼睛的,这有可能代表害怕,也有可能代表惊喜或惊奇。7342C20B-B95E-461D-9C3C-9DD9AA43235D
⑸ 不同人的脸部存在差异。在同种人的情况下,由于每个人的民族、年龄、生长条件等因素都会影响到识别的正确性。且不同种族下人的习惯又存在差异,导致人脸很难使用统一的模型来归类,增加了识别难度。
2.2 发展趋势
⑴ 研究新的更加高效,更加精准的识别算法。一个新的高效算法可以有效增加识别效率和降低识别时间,可以更大范围的应用到各个场景当中。
⑵ 加强三维立体面部表情识别的研究。与二维图像相比,三维立体图像更接近于真实环境,其能包含更多、更准确的人脸特征,結合三维信息可以更好地解决光照亮度等问题。
⑶ 在现实生活的应用。一个人的表情往往可以直接反应出其内心的心理变化。如果可以把表情识别与心理学、神经科学、犯罪学等学科结合,那么对于社会发展与治安将会产生巨大效益。
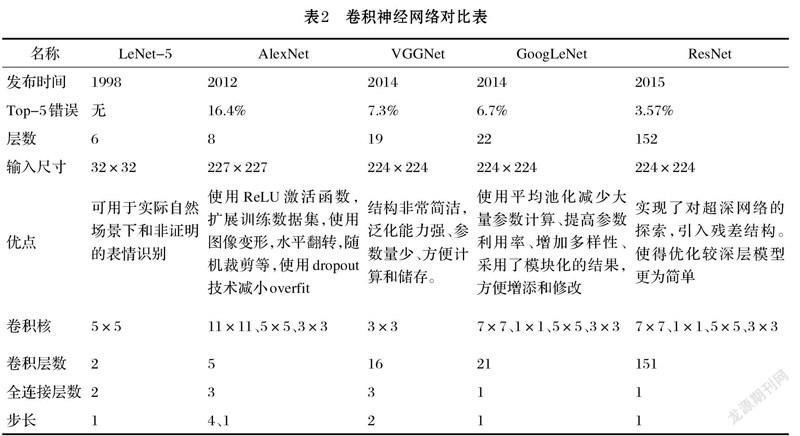
卷积神经网络的适用范围越来越广,可处理的数据越来越多,其模型层数也从几层变为上百层。本文对比和总结了热门模型情况。如表2所示。
3 结束语
算法在不断改进,而卷积神经网络依然是计算机视觉乃至深度学习和机器学习领域的主流模型,但是由于人类表情具有多样性、模糊性等特点,导致真实情况与研究情况产生误差。因此,与其他识别相比,表情识别发展相对较慢,在现实中的应用也较少。但表情识别在临床医学、人机交互以及心理分析等方面具有不可代替的地位,具有广阔的应用前景。除此之外,表情识别技术在理论上已相当成熟,但在真实情况下的识别率和准确度还有待提高,例如在室外的识别需加大研究力度。总的来说,卷积神经网络强大的特征提取能力极大地促进了表情识别领域的发展,基于卷积神经网络的表情识别具有巨大的发展潜力和应用前景。
参考文献(References):
[1] DARWIN C. The expression of the emotions in man and
animals[M]. University of Chicago Press,1965
[2] EKMAN P, Friesen W V. The repertoire of nonverbal
behavior: categories, origins, usage, and coding [J]. Semiotica,1969,1(1):49-98
[3] SCHUBERT S. A look tells all [J]. Scientific American
Mind, 2006,17(5):26-31
[4] DAILEY M N, JOYCE C, LYONS M J, et al. Evidence and
a computational explanation of cultural differences in facial expression recognition [J]. Emotion,2010,10(6):874-893
[5] YANN L C, BOTTOU L, BENGIO Y, et al. Gradient-
based learning applied to document recognition[J]. Proceedings of the IEEE,1998,86(11):2278-2324
[6] DHALL A, GOECKE R, Lucey S, et al. Collecting Large,
Richly Annotated Facial-Expression Databases from Movies[J].IEEE Multimedia,2012,19(3):34-41
[7] SIMONYAN K, ZISSERMAN A. Very Deep Convolutional
Networks for Large-Scale Image Recognition[J]. Computer Science,2014,1409(15):1-9
[8] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking
the Inception Architecture for Computer Vision[C],Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:2818-2826
[9] HE K, ZHANG X, REN S, et al. Deep Residual Learning
for Image Recognition[C].Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015:770-778
[10] HUANG G, LIU Z, et al. Densely Connected
Convolutional Networks[C],Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:4700-47087342C20B-B95E-461D-9C3C-9DD9AA43235D
