植株样本量对云南松子代苗期遗传力估算的影响
2022-04-11李熙颜李江飞车凤仙孙继伟诗吴俊文蔡年辉许玉兰李金才
李熙颜 李江飞 车凤仙 孙继伟 陈 诗吴俊文 蔡年辉 许玉兰 李金才
(1. 西南林业大学西南山地森林资源保育与利用教育部重点实验室,云南 昆明 650233;2. 西南林业大学云南省高校林木遗传改良与繁育重点实验室,云南 昆明 650233;3. 弥渡县林木育种培育站,云南 大理 675600;4. 普洱市林业和草原科学研究所,云南 普洱 665099)
云南松(Pinus yunnanensis)分布于我国西南地区,是云南省主要森林植被类型之一,占全省林地面积的52%、占有林地蓄积量的32%。云南松为喜光性强的深根性树种,适应性强,是西南地区荒山造林的先锋树种[1-2]。云南松纯林较多,生物多样性低[3],且近年来受人为原因和自然因素的干扰,现存云南松林分中优良基因资源减少,不良个体增加,使部分云南松林出现不同程度的退化[4-5],目前保有的优质高效人工林较少,所以对云南进行遗传改良势在必行。
遗传测定是林木良种选育工作的重要内容,历来受到林木育种工作者的重视,精确的、系统的林木遗传测定与遗传评估可有效地缩短育种周期,提高育种效率,其中,遗传参数估算是遗传测定最主要的研究内容,也是林木育种程序中最重要的环节之一[6-8]。性状遗传参数的估算会受群体样本容量大小的影响,足够大的样本量是提高遗传力估算准确性的必备条件,适当的采样数目不仅可以节省大量的人力和物力,减少不必要的浪费,而且可以提高分析问题的效率。然而目前,对于云南松的遗传测定研究,大量集中在天然林分、母树林、种子园等[9-13],在样本量对遗传参数估算结果的影响方面研究较少。本研究以34个云南松半同胞家系的3 478株1年生子代实生苗为试验对象,苗高(H)和地径(D)为分析指标进行抽样分析,通过分析比较不同样本容量下对各性状遗传力及其标准误估算值的影响,确定遗传力估算所需的临界样本量,从而可减少云南松半同胞家系子代测定时的工作量,节约成本,为云南松育种的后续工作提供参考和选择策略,进一步推动云南松的育种工作,使其产生应有的效益。
1 材料与方法
1.1 试验地概况与材料
试验地设置于云南省昆明市西南林业大学温室大棚内,地处北纬25°04′00ʺ、东经102°45′41ʺ,海拔约1 945 m,为北亚热带高原山地季风气候,年平均气温14.5 ℃,年降水量在840 mm左右。
于玉溪市新平县进行样本的选择与采集,随机各选取50~60株生长正常、无明显病虫害的成年云南松植株,采集树冠中上部发育正常且成熟的饱满球果(种子)。
1.2 试验方法
1.2.1苗木培育
于2015年3月用点播的方式播种于苗床,株行距为5 cm×10 cm,采用完全随机区组设计,每个家系播种40粒,3次重复。播种后盖薄膜小拱棚,待苗出齐后,露天培养,期间不定期浇水。
1.2.2生长指标测定
于2015年12月底云南松苗木生长停止时,选取每个重复保存植株数量均在30株以上的家系用于后续分析,共有34个家系,3 478个单株作为参试材料。对苗木的苗高和地径进行测量,直尺测量苗高(精确至0.1 cm);电子游标卡尺测量地径(精确至0.01 mm)。
1.3 数据统计分析
1.3.1样本量设置
采用Microsoft Excel 2010整理数据,利用完全随机抽样程序对数据进行抽取,每家系的每重复抽取梯度为5、10、15、20、25株,共5个样本量梯度(S1,S2, ···,S5),每梯度重复10次。
1.3.2遗传参数估算
使用林木单地点半同胞家系子代测定分析软件HalfsibSS 1.0计算和分析每个性状的家系遗传力及其标准误[14]。对于单地点培育苗木的随机区组试验,该软件的半同胞家系子代遗传测定的分析模型为:
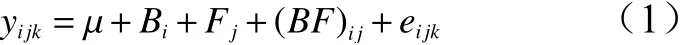
其中,yijk为第i个区组第j个家系第k个单株的数量性状值,μ为总体均值;Bi为第i个区组的固定效应;Fj为第j个家系的随机效应;(BF)ij为第i个区组第j个家系的随机效应;eijk为第i个区组第j个家系第k个单株的随机误差,同时所有因子间的协方差为0。
1.3.3单因素方差分析
利用Excel对数据进行整理,用SPSS 20.0对各性状的数据进行单因素方差分析,并计算变异系数(Coefficient of variation,CV),变异系数计算公式为:

式中:CV为变异系数;S为表型标准差;为不同家系样本量遗传力的均值。
若指标间出现显著或极显著差异,采用邓肯氏(Duncan's)法进行多重比较,做显著性检验(α=0.05)。
1.3.4临界样本量确定
本研究以苗高、地径的家系遗传力估算值随样本量的增加不发生显著变化时的样本容量作为临界样本量,参考文献[15]设计的3种方法,计算后综合分析得出临界样本量。
1)方法1:计算每个梯度与相邻梯度遗传参数差的绝对值,对所有结果取平均,得到所有梯度遗传参数估算值的平均绝对差值(MAD)。
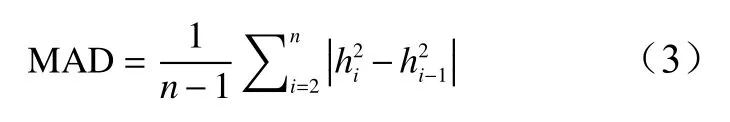
表示性状在梯度i时的狭义遗传力,n为梯度等级(1≤n≤5);同时再确定一个正整数m,使得相邻梯度间性状遗传力满足条件(其中i=m+1,m+2, ···,n)。正整数m的确定方法为:从最后2个梯度开始判断,若这两个梯度不能满足上述条件,则记m=n,即梯度n所含的家系样本量为临界样本量;若满足上述条件,则再往前推一个梯度,判断是否满足该条件,满足则继续依次进行判断,直至不满足为止记m=n-1。
2)方法2:计算所有梯度的性状遗传力估算值,求取平均值(AV),再确定1个正整数m,使得相邻梯度间遗传力满足条件AVm+k×AV(其中,k为随机比例因子,如0.1或0.2,AVm为最后n-m+1个梯度的遗传力的平均值。正整数m的确定方法同方法1。
3)方法3:计算所有梯度性状遗传力估算值的标准差(SD),再确定1个正整数m,使得相邻梯度间遗传力满足条件SD。正整数m的确定方法同方法1。
2 结果与分析
2.1 苗高和地径在不同样本容量下的基本状况
由在不同样本量下苗高和地径的均值可知该试验中1年生云南松的苗高约为7.05 cm,地径约为3.54 mm。苗高指标在不同样本容量下的生长范围是6.86~7.14 cm,其变异系数波动范围是34.41%~35.48%;地径指标在不同样本容量下的生长范围是3.40~3.61 mm,其变异系数范围是43.81%~45.79%,不同样本容量间变异系数波动小,说明随机抽取的不同样本容量内的样本比较稳定(表1)。

表 1 苗高和地径在不同样本量内的基本情况Table 1 The basic situation of seedling height and ground diameter in different sample sizes
2.2 苗高和地径的遗传力及其标准误估算受样本量容量的影响
2.2.1苗高的遗传力及其标准误受样本量的影响
对不同样本量云南松苗高遗传力的分析结果表明(表2),苗高指标在不同样本量梯度间的家系遗传力估算值具有极显著差异(P<0.01),苗高的家系遗传力估算值变化范围0.624 8~0.725 2。最大值为0.748 4,出现在样本容量为20株的梯度中;最小值为0.518 7,出现在样本容量为5株的梯度中。样本量大于10株以后,遗传力估算值变化趋于稳定且有小幅增长。变异系数的波动范围为2.03%~9.92%,当样本量较小时,变异系数较大,即遗传力估算值波动较大;苗高的标准误估算值的范围为0.004 7~0.019 6;当样本量为5株时出现最大值,样本量为25株时出现最小值,变异系数与标准误估算值随着样本量的增加而逐渐降低。多重比较结果,样本量为15、20、25株时的家系遗传力显著大于样本量为5、10株。

表 2 苗高家系遗传力的描述统计Table 2 Descriptive statistics of family heritability of seedling height
2.2.2地径的遗传力及其标准误受样本量的影响
对不同样本量云南松地径遗传力的分析结果显示(表3),不同样本量对云南松地径的遗传力估算值具有极显著影响(P=0.006<0.01)。地径的家系遗传力估算值变化范围0.235 2~0.392 4。最大值为0.494 5,出现在样本容量为25株的梯度中;最小值为0.031 6,出现在样本容量为15的梯度中。变异系数的波动范围为12.58%~49.10%,样本量小于10株时,变异系数较大,样本量大于10株,变异系数较小;地径的标准误估算值的范围为0.015 6~0.045 4,当样本量为5株时遗传力标准误出现最大值,样本量为25株时出现最小值,变异系数与标准误估算值随着样本量的增加呈下降趋势。多重比较结果表明,样本量为20、25株时的家系遗传力显著大于样本量为5、10、15株。

表 3 地径家系遗传力的描述统计Table 3 Descriptive statistics of family heritability of ground diameter
综上所述,在每个重复的样本量小于20株,总样本量小于60株时苗高和地径的遗传力估算值波动较大,标准误也较大。当样本量增加到每重复20株,总样本量60株时遗传力估算值随样本量的增加而呈逐渐平稳的趋势,标准误也逐渐降低并趋于平稳。
2.3 确定临界样本量
通过上述分析方法中确定临界样本量的3种方法进行分析判定,确定满足苗高和地径遗传临界样本量(表4)。

表 4 3种方法下苗高和地径遗传力估算所需的临界样本量Table 4 The critical sample size for estimating the heritability of seedling height and ground diameter under 3 methods
由表4可以看出,方法2确定的苗高遗传力估算所需临界样本量最小,为每重复5株,方法3的苗高、地径指标和方法一的地径指标确定的临界值最大,为每重复20株。方法2和方法3的确定结果与k的取值有关,k表示所要求的遗传力估算值的波动大小。方法1确定的临界家系样本量为每重复10~20株,此时遗传力波动较平稳;方法2确定的临界样本量为5~15株,此时遗传力不稳定,标准误估算值较大;方法3确定两性状遗传力估算值所需临界样本量为每重复20株。遗传力估算值波动较小。3种方法结合前文性状遗传力及其标准误可得,对于本研究的云南松群体若要得到1个较为精确的遗传力估算值,需测定云南松样本量大于每重复20株,即单株数每家系应大于60株。
3 结论与讨论
加强用材树种的遗传育种研究,可以有效促进林业产业发展,增加与提高我国木材的产量和质量。林木的苗高和地径等生长性状由于其方便测量且较为直观,一直以来都是林木改良的重要方向。现阶段云南松对遗传参数研究时大多采用随机抽样或全样本测量的方法[16],样本量太小,会使抽样误差过大;全样本测量,样本容量越大,样本的代表性会越好,但耗费的人力、物力也会越多[17]。了解林木的苗高及地径的遗传力估算值与样本容量的关系可以更快更好的进行相关研究,在林木子代试验及测定中,只有样本数量合适,才能得到正确可靠的分析结果[18]。
遗传力不是一个孤立的指标,而是一个与特定群体结构有关的动态函数,会受计算方法、试验群体、环境影响及样本量大小等因子的影响[19]。毕志宏等[20]发现不同的样本数量对白桦的各遗传参数的估算会有一定显著或不显著的影响;从本试验中能发现,云南松半同胞家系内遗传力估算值会因影响因子的存在而产生波动,样本量对苗高和地径家系遗传力估算影响显著,小样本量下苗高和地径的遗传力及其标准误估算值的变异系数较大,随着样本量的增加,苗高、地径的遗传力及其标准误估算值的准确度逐渐增加。所以临界样本量的确定要参考标准误估算值和遗传力估算值,在遗传力估算值逐渐趋于平稳,标准误估算值较小时确定临界样本量的大小。
陈强等[16]研究表明,参试子代样本数量的大小对遗传分析结果有显著影响,且随研究性状的变化而不同,对于同一性状,参试子代样本数越多,结果可靠性越高,相对误差越小。本研究也发现,当样本量较小时,云南松的遗传力及其标准误的估算值均有较大波动,随着样本量的增加而逐步趋于稳定,这与张帅楠等[21]通过对湿地松61个自由授粉家系测定林的研究表明随着测量样本容量或家系数的增加,测量结果的精度与准确性均有比较大的提高的结果基本一致。因此,遗传力估算时,为保证精确度应在条件允许的情况下提高样本量。但本研究仅讨论了苗高和地径这两个生长性状,对于张帅楠等得到的遗传力较低的性状其遗传力估算所需的临界样本量普遍大于遗传力较高的形状这一结论,无法进行探讨。
另外,通过本次试验测定群体,也能发现临界样本量不是一个固定的值,与研究性状、估算方法等相关,临界样本量的确定,能在保证遗传力估算值精度的同时减少人力、物力的消耗,是测定群体遗传力评估最经济有效的调查取样数量。
本研究以各性状的遗传力估算值趋于稳定时的样本量为临界样本量,遗传力估算值不会随样本量的增加有明显波动,此结果对于本研究来说具有代表性和应用价值,即对于本研究的34个云南松半同胞家系3 478株幼苗而言,3种确定临界样本量的方法间有差异,结合遗传力估算值及其标准误的变化趋势,要获得精确度较高的苗高和地径遗传力估算值,测定的云南松样本量应每家系不少于60株。选取的样本量越接近样本总量,遗传力估算值越精确,但遗传力估算值会由于不同的遗传测定群体、计算方法等不同,进一步导致临界样本量结果会存在差异,在实际应用中应充分考虑这些影响因素,在本研究外需进一步考虑实际情况。
