基于Swin-Unet的云分割算法的研究
2022-04-01张文康
张文康
(北方工业大学 信息学院,北京 100144)
0 引言
近些年来,在众多对地观测手段中,卫星遥感图像作为一种更加高效的技术受到了包括国防与民生建设、自然灾害预测等多行业的青睐。鉴于其拥有其巨大的市场和应用,形成了遥感图像处理这样的学术研究领域,取得了长足的发展。云作为一种典型的气象和气候要素,广泛的存在于光学卫星遥感图像当中(例如:我国四川盆地常年云覆盖率超过60%)。此外,云的形状,亮度和纹理在一定程度上是随机的,并时常随着时间,高度、厚度、太阳仰角等因素而变化。这将导致云的局部形状可能与某些地物有较高的相似度,同时,卷云本身亮度较低,存在大量的纹理。相比于厚云,卷云特征在某种程度上更加接近于地物,云的这些特性大大影响了图像的完整性和价值,增加了提取地面信息的难度。此外,这种低价值的图片还极大的占用了卫星下行链路的带宽以及储存空间,形成了资源的浪费。因此,准确识别卫星图像中的云区域是一个关键的课题。
在早期,机器学习是卫星应用的主要方法,其包括了单波段和多光谱数据,后者由于包含了更多的地物反射信息,具有更高的精准度。但在某些特定情况下,如夜晚、下垫面为沙漠、海岸线、河、冰川和内陆湖时,由于云与下垫面反射率类似,系统很难正确区分。因此,这些干扰的存在会导致错误的检测与识别,进而影响后续的分析与处理结果。与此同时,多变的云图特性会使阈值法的效果受到很多方面因素的干扰。例如:云的种类、高度、厚度和太阳高度角等。传统的遥感图像分割技术在分割过程中,容易忽略遥感图像中同一个地物的类内差异或纹理相似度较高的不同地物之间的差异。这是因为其主要技术为针对灰度或纹理差异较大的不同地物。
深度学习是机器学习领域中一个新的研究方向,其在视觉处理、数据挖掘、自然语言处理等领域都取得了很好的成果。目标识别作为其中的一种,已经在人脸识别、车辆检测、卫星图像分析当中取得了广泛的应用。在遥感领域,基于深度学习来进行云分割的方法也受到了研究人员的青睐。在之前的研究中,卷积神经网络(CNN)在目标识别网络中取得了里程碑式的进展,在多种图像处理任务中取得了优秀的成绩,但是,由于卷积操作的局限性所限,其无法学习全局,完成远端的信息交互。Swin-Unet是一种基于图像分割经典模型U-Net改进的纯Transformer模型,相比于其他图像分割算法,其在U型架构中,将图像块通过跳跃连接送到基于Transformer的U形编码器-译码器架构中,更好的进行了局部以及全局的语义特征学习,取得了更优的性能。后续,Swin-Unet也被应用于包括车辆检测在内的其他图像分割领域,提升分割的准确率。因此在本文中,也将借鉴深度学习领域的Swin-Unet分割模型完成遥感图像中的云区域识别。
1 网络结构
目前的图像分割主要基于全卷积神经网络(FCNN),其中以U型网络结构最为常用。传统的U型网络,如U-Net,是一个对称的编码-解码网络结构,并且包含跨层连接(skip connection)。编码器通过一系列卷积和下采样操作提取不同感受视野下的语义特征;解码器通过上采样操作将提取到的特征图恢复到原始分辨率,进行像素级别的密集预测;跨层连接则负责将同层的编码器提取的信息与解码器进行融合,从而减少因为下采样操作导致的空间信息丢失问题。通过精巧的结构设计,U-Net已经在诸多图像分割任务中取得优异的效果,但其仍然局限于CNN模型,无法捕捉全局和长程的语义信息。
受Transformer在NLP领域中的启发,目前研究人员正将Transformer迁移到计算机视觉领域。本文中使用的Swin-Unet即是一种纯Transformer架构。与CNN相比,其计算两个位置之间的关联所需的操作次数不随距离增长,这意味着其可以更好地捕捉到全局的语义信息。此外,Transformer的自注意力(Selfattention)机制可以产生更具可解释性的模型,各个注意头(Attention head)可以学会执行不同的任务。
1.1 面向云分割的Swin-Unet网络
整个Swin-Unet网络框架可以分为以下3个部分:编码器(左侧部分),解码器(右侧部分)以及skip connection(中间跨线部分),如图1所示。其中,Swin-Unet网络的基础模块Swin Transformer在2.2节进行详细介绍,而本节着重从框架层面介绍各个部分的结构和功能。

图1 Swin-Unet网络架构Fig.1 Swin-Unet Network architecture
1)编码器
该模块首先将输入的图片切分成大小互不重叠的分块,随后对输入分块进行线性映射。随后映射过的token被送入Swin Transformer模块和patch merge层用来生成不同尺度的特征表述;Swin Transformer模块负责学习特征,patch merge层负责下采样操作。
2)解码器
解码器由多个Swin Transformer模块和patch expanding层组成,跨线依旧负责特征融合,弥补原始信息的丢失,patch expanding层则进行的是上采样操作,将该层feature map扩充至2x分辨率;最后一个patch expanding层会扩充至4x分辨率;然后通过线性层进行像素级别的预测。
3)跨线连接
和传统的U-Net一样,跨线会以级联的方式将特征图输送到解码器当中,以此来融合多尺度特征。
1.2 Swin Transformer基础模块
Swin Transformer是整个网络最基础的模块,和传统的MSA结构并不一样,Swin Transformer主要是基于滑动窗口(shifted window)构建的,图2展示了两个串联的Swin Transformer模块。

图2 Swin Transformer模块Fig.2 Swin Transformer module
每个Swin Transformer由层归一化(Layer Norm,LN)层、多头自注意力模块、残差连接和2个包含有激活函数GELU的多层感知机组成。
在2个连续的Transformer模块中分别采用了基于窗口的多头自注意力模块(Window-based Multihead Self-attention)和基于移动窗口的多头自注意力模块(Shifted Window-based Multi-head Self attention),前者用w(g)表示,后者用s(g)表示。因此,基于这种窗口划分机制的连续Swin Transformer Block可表示为:


其中,LN(g)对应层归一化网络层;MLP(g)表示包含有激活函数GELU的多层感知机;和Z l分别表示(SWMSA)模块和第l块的MLP模块的输出。
2 实验与评价
2.1 数据集
数据集是训练神经网络的关键要素,数据集的选择决定了神经网络训练效果的好坏。因此,选择一个好的数据集格外重要。本文采用了38-Cloud数据集进行训练。该数据集包含38幅Landsat 8场景图像及其手动提取的像素级地物真实标签,用于云检测。这些场景的整个图像被裁剪成384×384个斑块,以适合于基于深度学习的语义分割算法。数据集被划分为8400个斑块进行训练,9201个补丁进行测试。每幅图像有4个相应的波段,分别是红色(波段4)、绿色(波段3)、蓝色(波段2)和近红外(波段5)。

图3 数据集图片示例Fig.3 Example of a dataset image
在本文中,数据集被划分为训练集、验证集和测试集。将数据集8400张图片,5000张划分为训练集,1000张划分为验证集,剩余的2400张则为测试集。
2.2 评估标准
1)Dice系数
Dice系数(Dice Coefficient)本质上是为了衡量两个样本的重叠部分。此度量范围为0~1,其中Dice系数为1时表示两样本完全重合。
Dice系数的计算公式如下:

2)准确率
在本文研究的云区域分割任务中,预测过程将图片信息分为两类:云像素为正类,地物像素为负类。则准确率的计算公式如下:
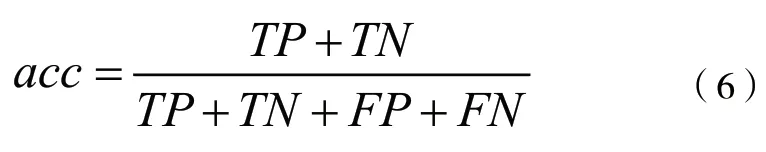
其中,TP代表正确识别云像素的个数;TN代表正确识别地物像素的个数;分子为两者之和,代表所有正确识别的像素个数;FP代表错误识别云像素的个数;FN代表错误识别的物像素的个数;分母为所有像素个数。
2.3 与其他模型进行对比
本文测试了在不同学习率下的模型表现。此外,也将传统的U-Net网络作为对照组,进行对比。
1)Swin-Unet最优模型选择
本文分别对Swin-Unet选取了不同的学习率进行了训练,并通过验证集的最大准确率选择最佳模型,在不同学习率下Swin-Unet模型的表现结果见表1。根据实验结果,选取了学习率为0.0001时的模型为最优模型,其验证集和测试集在此时都达到了最优值(测试集准确率为0.9830,测试集Dice系数为0.9745)。

表1 不同学习率下,Swin-Unet最优模型训练集的Loss、验证集准确率和Dice系数、测试集准确率和Dice系数对比Table 1 Comparison of Loss, validation set accuracy and Dice coefficient, test set accuracy and Dice coefficient of Swin-Unet optimal model training set under different learning rates
根据实验结果,选取了学习率为0.0001时的模型为最优模型,其验证集和测试集在此时都达到了最优值(测试集准确率为0.9830,测试集Dice系数为0.9745)。
2)U-Net网络最优模型选择
将传统的U-Net网络进行了训练,在U-Net网络中,使用交叉熵函数(Cross Entropy Loss)作为网络的损失函数。交叉熵作为损失函数的好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。其公式表示如下:

其中,P(x)表示语义分割的标注;q(x)为预测值。
通过对参数的调整,得出传统U-Net模型在训练达到最优时测试集准确率达到0.9769,测试集Dice系数为0.9184。
3)与主流模型对比
在训练过程中发现,传统U-Net模型在训练达到第47代时模型达到最优,而Swin-Unet在训练到第45代时性能最优,这说明了Swin-Unet在云分割领域比传统的以CNN为架构的U-Net模型收敛更快。
此外,对比不同模型下的最佳表现,传统U-Net模型在训练达到最优时测试集准确率达到0.9769,测试集Dice系数为0.9184。而Swin-Unet模型的测试集准确率为0.9830,测试集Dice系数为0.9745。这表明了Swin-Unet在云分割领域拥有更好的识别效果。
2.4 云分割效果
本小节示意图中均包含3幅小图像,其中第1幅为输入样本,第2幅为真实标记云分布,第3幅图为经过系统分割后预测的云分布。第2、第3幅图可以进行直观对比观察本文分割模型效果。
1)厚云
如图4所示,若需分割的云为厚云时,模型可对云进行准确率较高的分割,但在云的边缘范围,无法实现较为精准的分割效果,存在一定的误差。

图4 厚云输入下的真实标记和预测结果Fig.4 Ground-truth labeling and prediction results under thick cloud input
2)薄云
如图5所示,若需分割的云为薄云时,模型可对云进行准确率较高的分割,大致范围与精标准结果吻合,仍在云和地面交接处存在一定的误差。

图5 薄云输入下的真实标记和预测结果Fig.5 Ground-truth labeling and prediction results under thin cloud input
3)朵云
如图6所示,若需分割的云为朵云时,模型可对云进行准确率较高的分割,如上述二者相比效果更好。

图6 朵云输入下的真实标记和预测结果Fig.6 Ground-truth labeling and prediction results under Duoyun input
4)雪山垫面
如图7所示,当下垫面为雪山时,地表信息中的雪基本不会对云的分割效果产生极大干扰,云的边缘无法精准分割,存在小范围误差。
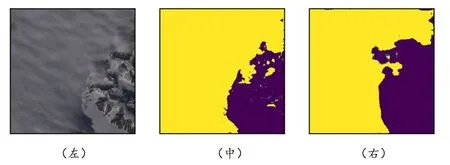
图7 雪山下垫面输入下的真实标记和预测结果Fig.7 The real label and prediction results under the input of the underlying surface of the snow mountain
5)海洋垫面
如图8所示,当下垫面为海洋时,虽然其中的云亮度较低,但可以看出分割效果较好,只存在小范围的细节无法精准分割,总体分割效果优秀。

图8 海洋垫面输入下的真实标记和预测结果Fig. 8 Ground-truth labeling and prediction results under the input of ocean surface
6)平原垫面
当下垫面为平原时,由图9可以看出无法做出很精细的分割效果,与金标准结果相比,大致轮廓吻合,云的边缘与细节存在一定程度的误差。

图9 平原垫面输入下的真实标记和预测结果Fig.9 Ground-truth labeling and prediction results under plain mat input
