基于FCN的图像语义分割算法研究
2022-03-27王汉谱瞿玉勇刘志豪谷旭轩贺志强彭怡书
王汉谱,瞿玉勇,刘志豪,谷旭轩,贺志强,彭怡书,何 伟
(湖南理工学院 a.信息科学与工程学院; b.机器视觉与人工智能研究中心,湖南 岳阳 414006)
近年来,深度学习的发展非常迅速,其中深度卷积神经网络是重要的分支之一,在计算机视觉领域大放异彩。在日常生活中,计算机视觉技术常用于目标物体的检测和识别,在许多需要人工重复的简单任务中已经逐渐走向自动化。图像语义分割是很多任务处理的前提步骤,其分割效果直接影响着整个网络模型的表现性能。随着计算机技术的发展,分类网络的成功,进一步推动了图像分割的发展[1~4]。
传统的图像语义分割方法有基于阈值的图像分割方法[5]、基于K-means像素聚类的图像分割法[6]、基于边缘检测的图像分割方法[7]等,但这些方法无论是结果精度还是特征通用性都比较差。
为解决上述问题,Long等[8]中提出自行设计的全卷积神经网络(Fully Convolutional Network,FCN),该网络结构是在非常深的网络结构(VGG Very Deep Convolutional Networks,VGGNet)上面进行改进的。Ronneberger等[9]提出一种经典的编码器-解码器结构U-Net,该结构中解码器是通过逐步恢复物体细节和图像分辨率,广泛应用于医学图像分割;Badrinarayanan等[10]提出SegNet网络结构,其解码器是根据编码器索引而设计的上采样方式;Chen等[11]的DeepLab方法使用了空洞卷积。DeepLab共有3个版本。DeepLab v2第一次使用了空洞卷积,提升了感受野[12],获得了图像多尺度信息。对于条件随机场,Deeplab v2采用全连通条件随机场(Conditional Random Fields,CRF)来增强捕获细节的能力,从而来改善被分割对象边界的连续性。DeepLab v3版本[13]对原来多孔空间金字塔池化模块的并行连接结构进行了微调,模块串联了多个配置不同扩张率的空洞卷积结构来增大感受野,捕获多尺度信息与背景。
此外,一些学者依据多尺度、金字塔结构来捕获足够的上下文。Lin等[14]第一次提出了特征金字塔网络(Feature Pyramid Networks,FPN)来连接语义信息丰富的高等级特征和边缘细节丰富的低等级特征,从而各个尺度都包含丰富的语义特征;Zhao等[15]设计了场景解析网络(Pyramid Scene Parsing Network,PSPNet)来对不同区域的上下文信息聚合,提升了分割性能;Zhao等[16]提出实时语义分割网络(Image Cascade Network,ICNet);Xong等[17]以不同尺度的图像作为网络输入,并对多尺度特征进行融合;徐天宇等[18]在上采样路径之前采用特征金字塔方法进行信息增强,从而整合多级特征;He等[19]依据全局导向的局部亲和力在构建有效语境中至关重要,提出了自适应金字塔上下文网络(Adaptive Pyramid Context Network,APCNet);Wu等[20]提出联合金字塔上下样模块(Joint Pyramid Upsampling,JPU)来将低分辨率特征图上采样为高分辨率特征,极大地降低了计算复杂度和内存占用。
针对原始全卷积神经网络对小目标和物体边缘分割效果困难的问题,本文通过设计模块捕获图像多尺度特征,并使用密集上采样方式替换原始反卷积方式,并在Pascal VOC 2012数据集上进行实验,从而进一步提升语义分割效果。
1 模型框架
本文图像语义分割算法相对于原始FCN最大的改进是使用了空洞空间金字塔池化模块(Atrous Spatial Pyramid Pooling,ASPP)对特征图进行重采样以获取多尺度信息,上采样方法由反卷积法改变为密集上采样卷积法。下面将对图像语义分割算法中所使用的网络结构进行详细描述。
1.1 基本网络选择
一般情况下,通过加深网络深度,使其能够表示更加复杂的映射关系。这同样适用于图像语义分割模型,更深层次的网络结构一般可以进一步提升图像语义分割最终的效果,模型复杂度稍微有所增加,但是仅仅通过增加网络规模来提高识别准确率的做法无法提取更加有效的图像特征。近年来,许多学者提出了应用于计算机视觉领域的优秀网络结构,如深度残差网络ResNet-50,ResNet-101[19]等。本文算法采用的基础网络正是ResNet-50,其主要优点是克服了由于网络深度过深带来的学习退化、梯度消亡问题。ResNet-101网络参数更多,而表现的性能却相差无几。
ResNet-50中最关键的技术是残差块,其详细结构如图1所示。残差块的核心在于通过短连接实现的恒等映射,可以有效缓解网络的梯度消失问题。
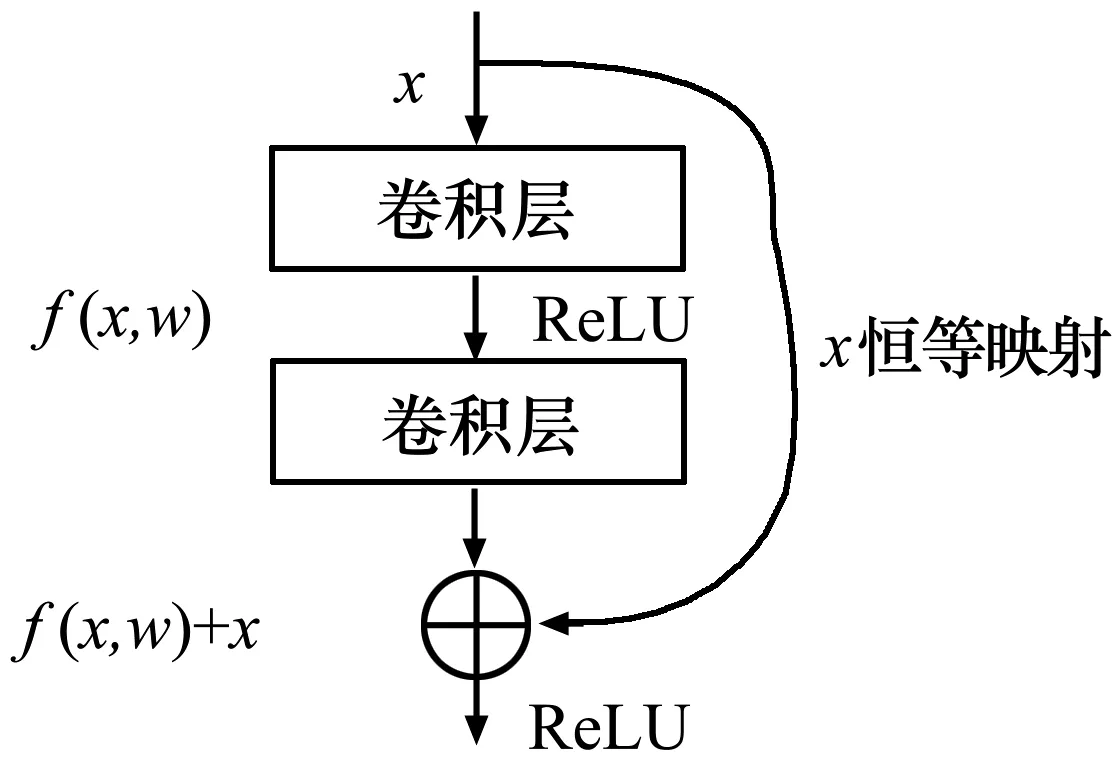
图1 残差块结构
和VGG-16[22]一样,ResNet-50也具备提取图像全局和局部特征的能力,且其可训练参数更少,模型的表达能力更强。模型采用的激活函数是在近几年使用十分广泛的ReLU函数,由于其计算简单,能使得网络收敛更快,ReLU函数计算公式如式(1)所示,对应的图像如图2所示。
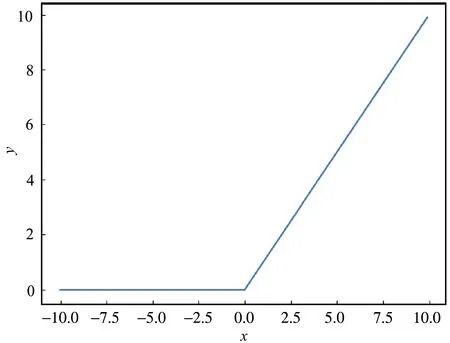
图2 ReLU激活函数
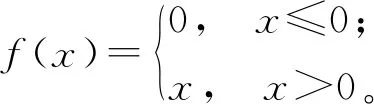
(1)
1.2 ASPP与特征融合降维
ASPP受早先的SPPNet和R-CNN中的空间金字塔池化的启发[19]。如图3所示,ASPP结构中没有池化层,而拥有4个卷积核大小为3×3、不同扩展率的空洞卷积。使用空洞卷积会带来网格效应,导致滤波器有效权重逐渐变少(有效权重是非填充的零值),特征提取受到损失,使用多个不同扩展率的空洞卷积能够缓解这种效应,进而可以捕获更加全面有用的特征信息。这种结构也称为并行ASPP结构,因为4个卷积操作是同时并行执行的,不同尺度的并行卷积比单个卷积的感受野更加开阔。此外,也存在着另外一种串行的ASPP结构。
具体的ASPP结构如图3所示。1个常规卷积,3个不同空洞率的空洞卷积,1个用于提取全局特征的全局平均池化模块,此外,对所得特征,进行特征融合操作和降维操作,因此可以将特征值维持在一个较小的范围内取值,可以提升模型分割精度以及降低模型过拟合的风险。此外,还将空洞率的3×3空洞卷积替换为1×1的卷积,解决了由于图像边界效应导致的远距离信息无法捕捉的问题。
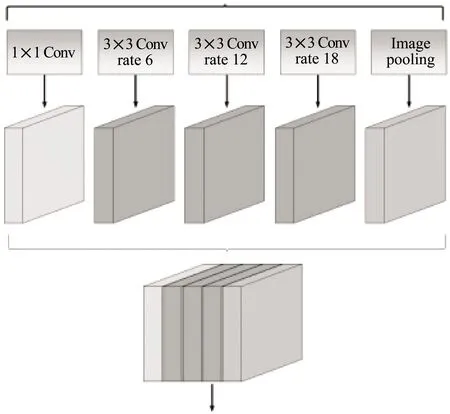
图3 改进后的ASPP模块结构
ASPP并行结构得到的特征是分离的,接下来的操作需要将这些特征进行融合,以获得完整的全局上下文信息。特征融合操作在张量中也被称为拼接。
改进后的ASPP结构对不同尺度的特征进行了重采样,不同扩张率的空洞卷积并行连接可以准确且有效地对任意尺度区域进行分类,解决了图像的多尺度问题。完成特征融合之后,可以通过卷积核大小为1×1的卷积操作实现特征图不同通道的线性组合以达到高维度通道线性降维的目的。
1.3 密集上采样卷积
ASPP模块生成的特征图经过1×1卷积的降维后,特征图的分辨率仅是输入图像的1/16,无法实现图像语义像素级别的分类,这样处理得到的结果不够精确。为了完成图像全局性的分类预测,对像素逐个求其在21张图像中位置的最大概率作为该像素的分类。DUC方法最初是用于将视频图像从低分辨率转换到高分辨率的一种技术,本次用于图像分割输出上原理是相同的。
DUC是对高等级特征图进行卷积,从而获得像素级别预测。DUC上采样的方法复杂性不高,在实际使用中较为容易,并且能够实现像素级精度的图像分割,它与转置卷积的目的相同,都是想要将特征映射扩大到与输入图像大小相同的密集特征映射。它是一种高效的图像和视频超分辨率技术,能够实现低分辨率图像到高分辨率的变换。
经过对模型结构的修改,加入密集上采样卷积后的处理效果确实更加精细,很少出现对象分割不连续的情况。缺点在于产生的可训练参数相比不可训练的双线性插值法多很多,一是内存占用增多,二是模型训练速度下降。综合来看,加入密集上采样卷积还是值得的,以处理速度换取更好的性能表现。
DUC过程如图4所示,一张输入图片的高度是H、宽度是W、通道数是C的图像,我们要获得同样大小的预测图,每个特征图中每个像素被单独标注。图像经过Resnet处理后得到图像特征图大小是h×w×c,其中h=H/d,w=W/d,d为下采样因子。在本文算法中由于使用了空洞卷积,最后一个卷积块的特征图分辨率没有变化,设计的下采样值为d=16。所提模块是对中间特征图进行操作,从而得到h×w×(d2×L)大小的特征图,L为数据集中样本类别数目。
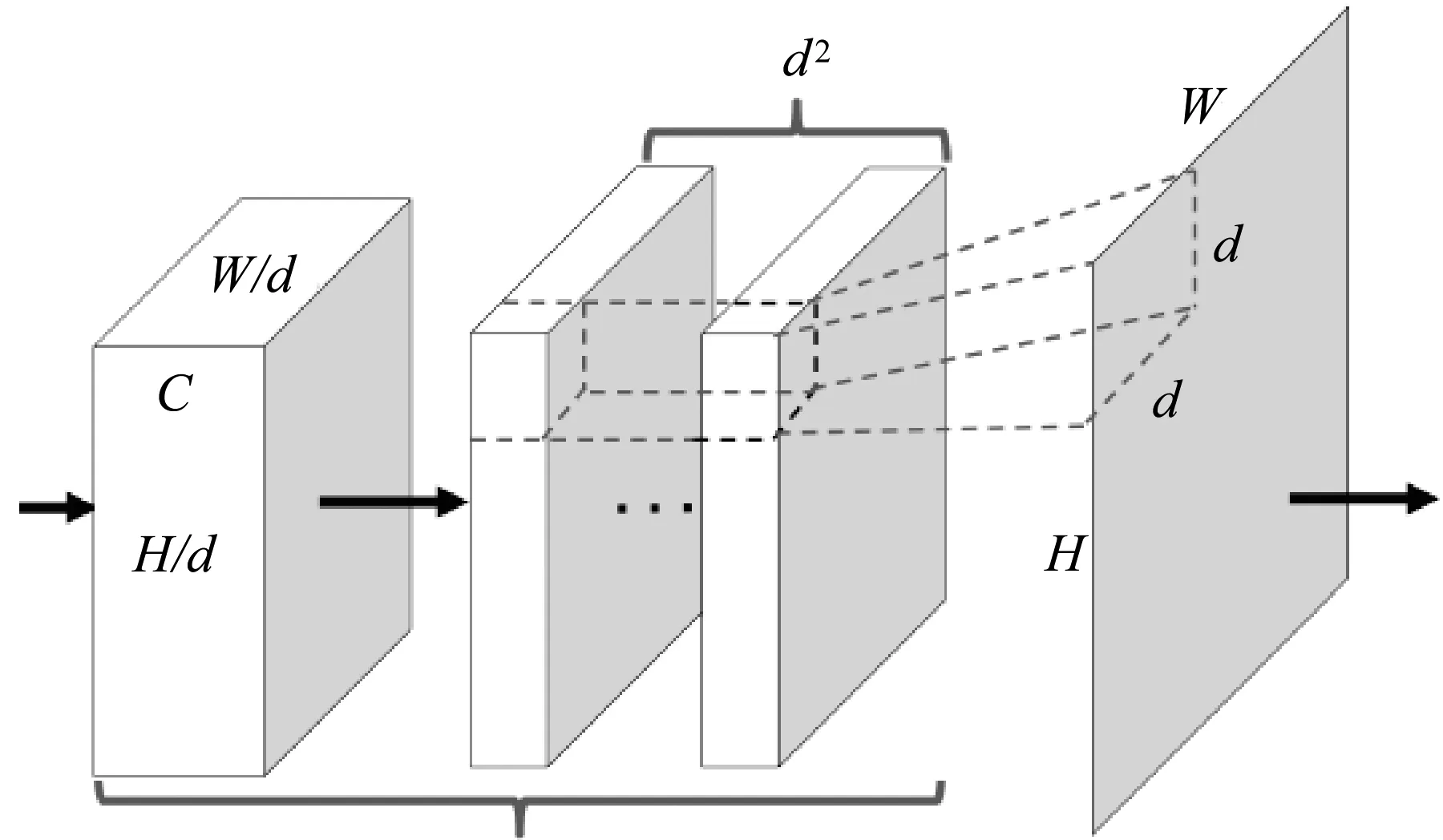
图4 密集上采样卷积示意图
经过像素重组(reshape)后将特征图形状(shape)转化为h×w×L,并运行argmax(对应程序语句tf.argmax)算子得到最终的预测图。argmax通过选取维度(axis)的不同返回每行或者每列最大值的索引值。
语义分割任务下的网络基本都具有编码模块和解码模型,它们组合在一起形成端到端的训练网络,而大多数网络在解码时使用的是双线性插值法。双线性插值在特征图上采样时容易丢失信息,导致上采样恢复对象的效果不佳。然而上采样方法并不唯一,在众多方法中DUC是一个比较好的选择。因为DUC是可学习的,针对数据集的特点,具有一定的自适应性,还能提升特征图分辨率,获得比双线性上采样更精确的结果。
2 实验
在Linux系统下,使用TensorFlow框架搭建深度学习网络模型,在GeForce RTX 2080 Ti上运行网络结构。
2.1 数据集
神经网络的训练需要大量的训练数据用以发现大数据中隐含的内在联系,同时通过梯度反向传播迭代更新网络参数,使得网络更适合当前任务,加快模型收敛速度,最终得到的分割结果更加精确。本实验使用Pascal VOC 2012[23],这是一个标准数据集,图像数据丰富,在计算机视觉领域被广泛接受。数据集包含20个目标类别和1个背景类别。在计算机视觉挑战赛上经常使用此数据集对算法进行验证,常用于3个主要物体识别竞赛分别为分类、检测和分割。对于语义分割任务来说,Pascal是非常合适的。本次实验使用到的有2 913张图片共6 929个物体,为验证实验结果提供了较为丰富的数据集。
为了使数据格式适合于训练本次的网络,首先需要进行适当的图像预处理。第一,由于标签图像是三通道的,需要转换为二维图像,转换的方法是将对应物体所属类别的彩色三通道映射为单通道的灰度值,取值范围为0~20对应着21种(包括背景)不同类别的物体,方便计算模型输出与真值标签之间的损失对网络进行反馈。第二,数据集的图像大小是不一致的,为了方便训练网络和展示结果,在训练之前先将图像尺寸统一变换为512×512大小。
2.2 评价指标
衡量算法优劣的指标通常有多种,在图像语义分割领域,常用的指标是像素精度(Pixel Accuracy,PA)和平均像素比(mean Intersection over Union,mIoU)。像素精度的定义是分类正确的像素与图像总像素个数的比值。计算式如式(2)所示:
(2)
式中:pii表示预测正确的像素数;N代表共有多少类;pi表示属于i类的像素的总数;pji表示应该属于i类的像素被误判为j类像素的数量。
平均像素交并比是两组实际值与预测值的交并比,得到每一类的平均值。本次实验使用mIoU作为算法的性能指标:
(3)
2.3 模型训练过程
待训练模型的参数较多,学习率的设置会对模型收敛速度以及最终效果有较大影响。如果学习率很低,训练过程的损失值通常会比较平稳地下降,但是会导致模型训练耗费较长的时间,因为模型可训练参数每一个步长是梯度与学习率的乘积;如果学习率过高,那么模型在训练时通常难以收敛,表现为损失值时高时低,没有一致的变化方向。为了让模型能够较快收敛又不至于导致模型的损失值频繁震荡,决定使用分步训练的方式对模型进行训练。分步训练的整个过程中一共用到3个不同的学习率,按训练模型的顺序分别为0.001 0、0.000 5、0.000 1。由于接近3 000大小的训练集算不上多,网络的误差收敛速度较快,所以模型训练迭代次数(epoch)不用过多,设置为40次。批量大小(batch size)的设置也很重要,过小的批量容易让模型学习到过多的噪声。本次训练将批量大小设置为6,那么训练的每一轮的批次大小是486,这样既能使模型较快收敛,也能充分学习到数据集的表示。最终,文献[8]方法和本文算法迭代1个批量所需时间和总训练时长如表1所示。

表1 算法训练时间
2.4 实验结果与分析
图5为文献[8]方法和本文方法在Pascal VOC 2012数据库上的可视化结果。可以发现本文算法加入了空洞卷积和ASPP层后,使得它对图像的全局信息把握更好,对较大型的物体分类精度更高,较少出现同一对象的像素分属到多个分类中,即分类夹杂在一起的情况。FCN-8s在部分细节和全局上下文的把握上还做得不够,容易出现同一物体分割“断裂”和丢失细节的情况。

(a)原始图像 (b)真实值 (c)FCN-8s (d)改进算法
本次实验使用mIoU评判标准对算法进行评估,各种算法精度对比如表2所示。

表2 算法精度
3 结语
本文算法的基础网络采用ResNet-50,相对之前基于VGG-16的全卷积网络而言,在残差网络中引入了跳跃连接,使得梯度的反向传播更加平滑,缓解了在进行梯度下降优化时出现的梯度消亡问题,加速了模型的收敛。采用可学习的密集上采样卷积,达到改善部分细节的目的。通常参与一次卷积计算的像素块的大小对比如原始图像的尺寸来说太小,因此,该算法只能提取非常有限的局部特征信息,限制了分类的性能。为此在算法中加入了空洞卷积块与ASPP模块来进行改进。最后对设计的网络结构在谷歌开源的深度学习工具TensorFlow上进行了仿真实验,使用公开数据集Pascal VOC 2012完成对模型的训练。实践结果表明了本文方案在基于mIoU评判标准上取得的效果要更好。
