基于多任务分支SSD的目标检测算法
2022-03-22洪哲昊陈东方王晓峰
洪哲昊,陈东方+,王晓峰
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065; 2.武汉科技大学 智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
0 引 言
目前在目标检测算法[1-3]中,对不同尺度目标的检测一直是一个难点,其最直观的一种解决方式是采用多尺度图像金字塔[4],然而这种方式检测太费时,使其难以在实际生产中应用。一些其它的算法采用在网络内部构建特征金字塔的方式,降低图像金字塔的计算成本,例如SSD[5]、DSSD[6]、RSSD[7]、FPN[8]、YOLO系列检测器[9-11],还有一些两步检测的算法例如Faster R-CNN[12]、R-FCN[13]、Mask R-CNN[14]等。上述算法虽然取得了较好的检测结果,但仍然存在一些不足。SSD算法各层特征之间相互独立,没有充分利用各尺度特征的特点,导致小目标检测;DSSD和RSSD算法采用较深的网络结构进行特征融合,使其参数量大大增加导致检测速度过于缓慢;FPN网络只将高层特征引入底层,没有考虑底层特征对高层的影响,使得特征融合不够充分。为了解决上述存在的问题,从特征金字塔的角度出发,提出了一种多任务分支SSD的目标检测算法。第一个分支为高层和浅层融合位置信息和语义信息,第二个分支为中间特征层融合语义位置信息,之后通过多尺度通道聚合将两个分支结果融合,加强对不同尺度目标的检测能力和重要特征的表征能力。
1 相关工作
研究人员已经投入了大量的努力来提高不同尺度物体的检测精度,无论是一阶段检测器还是二阶段检测器,近年来针对检测过程中出现的尺度变化问题,主要有两个策略来改善尺度变换带来的影响。
第一个策略是图像金字塔,该策略将原图像缩放到不同尺度,以获取具有代表性的多尺度特征。不同尺度图像的特征分别产生预测,最后这些预测总和在一起作为最终的预测。在识别精度和定位精度方面,来自不同大小图像的特征确实超越了仅仅基于单尺度图像的特征。SNIP[4]就采用了这种策略,尽管在性能方面有所提高,但带来的问题是消耗了大量的时间和内存,这使得这种策略在实时任务中难以实现。
第二种方法是从网络内部的固有层提取特征金字塔来检测目标,同时只提取单一尺度的图像。与第一种策略相比,这种策略所需的额外内存和计算成本要少得多,因此可以实时的进行网络测试,更容易在实时任务中部署。MS-CNN[15]将多尺度特征引入到深度卷积神经网络中进行目标检测任务的构建;SSD使用VGG16网络结构作为基础特征提取网络,并从其结构中抽取不同尺度的特征层进行检测;DSSD采用ResNet加深了主干网络,并将反卷积层应用在深浅层的特征融合中;FPN使用横向连接操作构建了一个自顶向下的通路,实现了高层语义信息的传递。
在对特征金字塔的研究中[5,6,8,15-17]表明,高层和低层具有的特征信息是不相同的,高层具有更多的语义信息,而低层特征图的分辨率较大,含有更多的位置信息和细节特征,而整合不同尺度的特征有利于各种目标检测任务[18]。SSD采用不同尺度特征图分别检测,底层高分辨率的大特征图往往用于检测小目标,高层低分辨率的小特征图的感受野更大往往用来检测大目标,这样的结构可以看出各层特征之间没有关联,底层特征缺乏语义信息,使得小目标检测效果不好,而高层特征分辨率低没有足够的位置信息容易导致中大型目标出现漏检情况。FPN和DSSD能够有效的把高层语义信息传递到底层特征,使得在底层高分辨率特征图上进行小目标检测的效果有了提升。但同时只使用了单一的特征金字塔结构,忽略了底层特征对高层的影响,使最后融合的特征不够充分,有效检测中大型目标的高层特征仍然缺乏位置信息。
基于此,本文算法借鉴FPN的思想构建了两个分支,其中第一个分支针对语义信息和定位信息采用了不同的两个模块进行级联,加强对深浅层中所包含的语义和定位信息在深层和浅层特征中的表征能力,第二个分支采用融合分裂的方式将深浅层的信息传递到中间层,之后将两个分支的输出经过一个多尺度通道聚合模块,融合整体的特征得到一个具有多尺度的特征金字塔,这种结构加强了SSD网络中各层特征的关联,同时也弥补了原始FPN网络特征融合不充分的问题。
2 基于多任务分支SSD的目标检测算法
本文算法的整体结构如图1所示,整体上分为3步。第一步通过VGG16主干网络提取不同尺度的六层特征记为 {G1,G2,G3,G4,G5,G6}, 其各层特征的大小为(38,19,10,5,3,1),之后通过瓶颈层改变各个尺度特征的通道数。第二步是一个包含二个任务分支的并行结构,使用上一步瓶颈层处理之后的一组特征图作为输入,在第一个分支中,将语义信息增强模块(semantic information enhancement module, SIEM)和定位信息增强模块(localization information enhancement module, LIEM)级联,对深层特征所包含的丰富语义信息和浅层特征所包含的丰富定位信息进行双向传递;第二个分支才采用融合分裂增强模块(fusion split enhancement module, FSEM)将深浅层所具有代表性的语义和定位信息向中间层传递。第三步将第二部分中不同分支的输出送入多尺度通道聚合模块(multi-scale channel aggregation, MSCA),进行两个分支输出特征的融合,并为不同尺度特征通道之间引入权重系数,对同一尺度下不同特征的关系进行表征,增强了原本响应较大的特征同时也对那些不敏感的特征进行一定程度的抑制。最后同SSD相似,图1中Detection per Class这一步骤,通过在不同尺度的特征图上进行卷积来生成若干个不同形状与比例的预选框,每一个预选框都包含着预测的类别与边界位置信息。然后通过非最大抑制(non-maximum suppression, NMS)操作生成最终结果。
图1中Bottleneck为瓶颈层,为了减少网络的参数量和回传梯度过大带来影响,Bottleneck层使用了1×1卷积对主干网提取到的不同尺度的特征进行平滑处理,将各个尺度的特征通道数减少到256,以提高计算效率。同时因为G0的大小为(1,1),位置信息已经丢失,但其语义信息丰富,因此作为一个全局平均池化(global average pooling, GAP)之后的全局特征引入前五层特征。输出得到一组多尺度的基础特征 {C1,C2,C3,C4,C5} 和G0, 在这些特征图中,从C1到C5其特征图分辨率逐渐降低,包含的位置信息逐渐减少而语义信息逐渐增多。下面介绍网络中各个模块的具体细节。
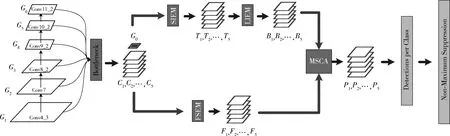
图1 本文算法具体网络结构
2.1 语义信息增强模块
语义信息增强模块(SIEM)主要采用自顶向下的特征金字塔结构,另外在基础FPN结构上做了一些修改:①使用了最小层的特征图G0作为GAP操作之后的全局特征引入到低层特征中,G0可以学习到更多的语义信息,突出识别出的目标区域;②采用双线性插值代替最邻近插值进行上采样操作,弥补最邻近插值带来的精度损失。SIEM结构如图2所示。
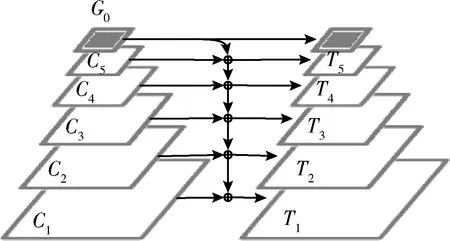
图2 SIEM结构
首先将G0层进行上采样到C5特征图同样大小,将其与C5特征图融合,把具有全局语义信息的特征传递到C5特征图上,之后把融合过的特征图通过一个上采样操作将分辨率增加到(10,10),之后将C4特征层与上采样操作过后的C5特征层进行融合,通过这样的方式得到五层融合过后的特征,最后对这五层特征分别使用一个3×3卷积来减少上采样导致混叠效应的影响,输出五层特征记为 {T1,T2,T3,T4,T5}。
自顶向下特征金字塔结构中的每一个特征图(Ti)由主干网中提取到的同一层特征图(Ci)和高一层的特征(Ti+1)融合得到
Ti=Ki⊗(S(Ti+1)+Ci)
(1)
式中:Ki为一个3×3大小的卷积核,⊗表示一个卷积操作,用于减少上采样带来的混叠效应, S(Ti+1) 表示一个将特征图大小增加为原来两倍的双线性插值上采样操作。这种自顶向下的特征金字塔将高层主干特征的语义信息逐层传播到分辨率更高的底层特征上,所以原本缺乏语义信息的低层特征得到了加强,对小目标的检测更加有利。
2.2 语义与定位级联模块
在SIEM中,自顶向下的特征金字塔将深层的语义信息传导至浅层特征中,让位置信息丰富的高分辨率特征图上具有了更多的语义信息,但是这种单一的特征金字塔结构没有考虑到浅层特征所包含的位置信息对深层特征的作用。本文设计了定位信息增强模块(LIEM),并于SIEM进行级联,在SIEM的基础上加强浅层特征定位信息向深层传递。SIEM和LIEM级联之后的结构如图3所示。

图3 SIEM和LIEM级联结构
LIEM与SIEM结构相反,利用SIEM输出的特征 {T1,T2,T3,T4,T5}, 从最大的特征图开始自底向上逐步构建特征金字塔,首先对T2进行上采样增大分辨率,将其与T1特征图融合,得到第一个融合的特征图,通过池化的方式减少分辨率并获取最重要的特征,第二次再以同样的方式对T2,T3进行融合。特别的,LIEM增加了对原始特征层相邻上下文的融合,以此方式减少池化时分辨率减小带来的信息丢失问题,最后得到的特征图记为 {B1,B2,B3,B4,B5}。
每一个自底向上特征金字塔中的特征层(Bi)都由同一大小的主干网特征(Ti)和其上一层特征(Ti+1)与特征金字塔中低一层的特征(Bi-1)融合得到
Bi=Ki⊗(M(Bi-1)+Ti+S(Ti+1))
(2)
式中:Ki同样为一个3×3的卷积核,⊗表示一个卷积操作来减小上采样带来的混叠效应的影响,M(·) 表示一个大小为2,步长为2的最大池化操作,将大特征图的尺寸减小为原始的一半。 S(Ti+1) 为一个双线性插值操作,将Ti+1这层特征图上采样到原来的两倍大小。由于这种自底向上的特征金字塔结构将底层主干特征的空间定位信息较好传播至高层特征,使得原本缺乏位置信息的高层特征得到加强,从而加强了对大目标的检测,在这个级联结构中SIEM将语义信息传递至浅层特征,通过LIEM将浅层中的定位信息反向传递至深层特征中,弥补了深层特征中定位信息不够的缺陷,从而提升了对大小目标的检测能力。
2.3 分裂融合增强模块
SIEM和LIEM中的特征金字塔结构都是顺序构造结构,分别针对底层特征语义信息不足和高层特征定位信息不足的问题进行优化。而从深层和浅层特征图直接的关系出发,设计了融合分裂增强模块(FSEM)分别融合主干网上深层的特征和浅层的特征,之后把这两组特征进行累加混合,再分裂至不同尺寸的特征层上,如图4所示。
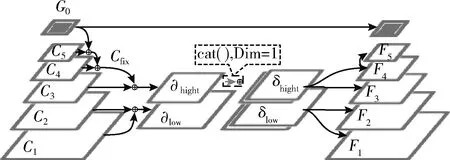
图4 FSEM结构
在SSD主干网提取到的六层特征中,使用前四层 {C1,C2,C3,C4} 来构建中型目标任务分支,其尺寸分别是(38,38)、(19,19)、(10,10)、(5,5),后两层特征图(3,3)、(1,1)尺寸过小,位置信息较差,但有着较为丰富的语义信息。首先将G0通过双线性插值上采样到C5特征图大小,随后将它们融合,把融合后的特征图再次通过双线性插值到C4特征图大小并与C4特征图融合,这样将后两层分辨率较低的特征层所包含的语义信息融合到下面的特征层当中,记融合过后的特征图为Cfix。
在前四层特征图中, {C1,C2} 为浅层高分辨率特征,通过池化将C1的尺寸减小到(19,19),之后与C2进行融合得到一个具有丰富位置信息的特征图∂low
∂low=M(C1)+C2
(3)
之后利用融合后的特征层Cfix与C3进行深层特征的融合,得到一个尺寸为(10,10)并具有丰富语义信息的特征图∂hight
∂hight=S(Cfix)+C3
(4)
在分别对深层和浅层特征进行融合之后,得到大小为(10,10)和大小为(19,19)的两个特征图∂hight和∂low, 其通道数都为256,之后将∂hight和∂low进行合并得到两个具有全面信息的特征图δlow和δhight
δlow=Klow⊗cat(∂low,S(∂hight))δhight=Khight⊗cat(M(∂low),∂hight)
(5)
式中:Klow和Khight为两个3×3卷积操作, cat(·) 代表沿通道维数的Concat操作,在此之后,特征图δlow和δhight同时融合了来自主干网深层特征和浅层特征的信息,最后对δlow和δhight分别进行双线性插值和池化操作得到各个尺度的特征图
F1=S(δlow),F2=δlowF3=δhight,F4=M(δhight)
(6)
另外将F4通过最大池化操作得到特征金字塔中的第五层:F5=M(F4)。 通过上述对深层和浅层特征的融合和分裂,中间大小的特征层(F2和F3)包含了来自主干网中浅层的位置信息和深层的语义信息,加强了对中型目标需要的位置和语义信息的提取。
2.4 多尺度通道聚合
在经过两个分支对不同尺度中所包含的信息融合之后,输出了两个特征金字塔,一个特征金字塔中的深浅层包含了定位和语义信息,另一个特征金字塔中的中间层包含了定位和语义信息,本文通过一个MSCA模块将这两组特征金字塔进行整合。在近期的研究中表明,通过求和组合特征图是一种常见的从多个特征中收集上下文信息的方法[19],然而,Huang等[20]认为求和会削弱网络中的信息流。此外每一个尺度中不同的通道表示了不同的特征,而这些特征之间缺乏关联,以至于重要的特征不能够显著的表示。
因此本文设计了一个多尺度通道聚合模块(MSCA)如图5所示,第一步沿着通道维将同等大小尺度的特征串联在一起,最后聚合的特征金字塔可以表示为P=[P1,P2,…,Pi], 其中每一个P表示为Pi=cat(Bi,Fi), 这样聚合金字塔中的每个尺度都包含多层次深度的特征,然而,简单的连接操作不能够表征通道之间的关系。第二步,和SE Block[21]相似,引入了一组通道权重,针对不同尺度特征中的关系进行加权,显著表征网络更感兴趣的特征,同时抑制其它的特征。先对每个尺度聚合的特征在通道维度上采用全局平均池化(GAP),对每个尺度的特征进行压缩获取权重系数z, 通道数目为C, 之后为了捕获通道之间的依赖关系,使用了两个全连接层对权重系数进行激活
S=fex(z,W)=σ(W2φ(W1,z))
(7)
式中:σ为Relu激活函数,φ为sigmoid激活函数,W1为第一个全连接层FC1参数,其尺寸为C/r×C,W2为第二个全连接层FC2参数,其尺寸为C×C/r,r是一个缩放比例,在本实验中采用r=16, 最终将得到的权重系数S与原始特征图Pi在同一通道Ci上相乘
(8)
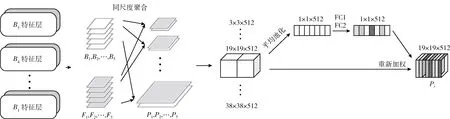
图5 MSCA结构
2.5 损失函数
本文算法目的为对图中目标的检测,需要进行定位与分类,本次实验使用的损失函数为位置回归损失函数与分类损失函数之和。其公式如下
(9)
式中:N为预测框匹配到目标框的数量,如果N为0,那么损失函数值为0;x为预测框与真实目标框关于每一个类别的指示器,其取值为0或1;c为网络对样本的输出的概率值;l为预测框的位置信息,g为真实目标框的位置信息;α为一个权重系数因子,在训练过程中设置为1。对于分类损失函数,采用交叉熵损失函数,其公式如下
(10)
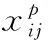
(11)
(12)
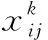
3 实验与分析
3.1 评价标准
本文使用MAP(mean average precision)作为指标来对算法的性能进行衡量,其公式如下
(13)
MAP为在所有图片上对所有类别的目标识别的精确程度,其中N(Classes) 为数据集中共有物体的类别数, ∑AveragePrecisionC则是对所有类别物体的平均精度求和。AveragePrecisionC表示C这类物体的平均精度,其公式如下
(14)
式中:N(TotalImages)C则表示所有包含C这一类的目标的图像的数量,PrecisionC为在测试集的所有图像当中C这一类的精度,其计算方式如下
(15)
N(TotalObjects)C表示测试图像当中含有C这一类目标的数量,N(TruePositives)C为C这一类目标被正确预测的数量。
3.2 实验环境与实验数据
本实验的软件环境为Ubuntu 16.04.6 LTS,深度学习框架为PyTorch。硬件环境使用CPU型号为Intel(R) Xeon(R) CPU E5-2628 v3,GPU型号为NVIDIA GeForceRTX2080,8 G显存。
本次实验所使用的数据集为PASCAL VOC 07+12 trai-nval和PASCAL VOC 2007 test,其中训练集PASCAL VOC 07+12 trainval一共包含16 551幅图像,49 653个目标对象,PASCAL VOC 2007 test作为测试集一共包含4952幅图像,14 856个目标对象,其中共有20个类别的目标对象。
3.3 实验结果对比
在本次实验过程中,使用300*300的分辨率作为网络的输入,训练过程中采用的BatchSize大小为16,总训练次数为120 000次,使用SGD优化器,初始学习率为0.001,优化器动量设置为0.9,学习率衰减率为0.1,分别在训练到第80 000次,第100 000次进行学习率的变更。在训练过程中,每1000次进行保存一次模型权重结果,整体训练损失值结果如图6所示,平均精度曲线如图7所示。
图6中,本次实验使用了预训练的VGG16权重,前期loss下降的较快,然后在不断的振荡,最终大概在80 000次左右收敛。
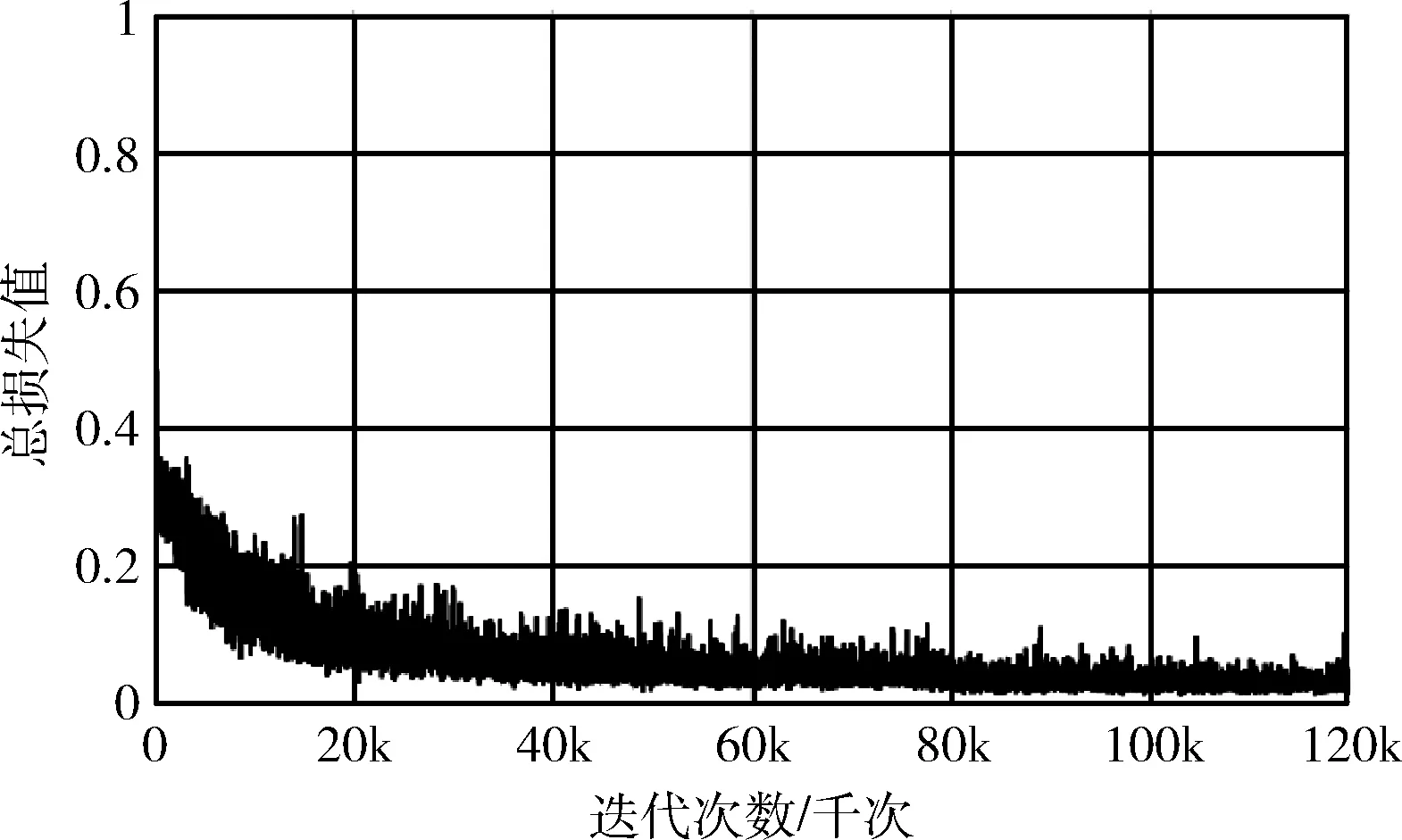
图6 损失函数收敛曲线
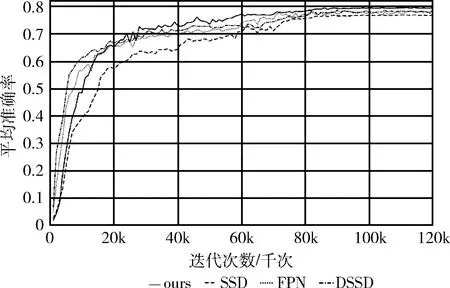
图7 平均精度收敛曲线
图7中,利用训练过程中保存的权重模型在VOC2007test数据集上进行测试,一共120次测试,其中实线为本文算法的平均精度曲线,短横虚线为SSD算法的平均精度曲线,点虚线为FPN算法,点加横虚线为DSSD算法,可以看出在前期存在一些振荡,在60 000次左右逐渐稳定,最后收敛的结果比其它算法要高。
为了验证本文算法的检测效果,将与原始SSD算法、其改进算法DSSD和基于特征金字塔的算法FPN算法进行实验对比。对比结果见表1,其中MAP为算法的整体检测精度,Fps为每秒检测的图像数量,单位为帧/秒,Backbone为算法采用的基础特征提取网络,our表示本文算法的实验结果。
如表1所示,原始SSD算法整体检测精度MAP为77.1,本文算法的整体检测精度为79.6,较原始SSD算法增加了2.5个百分点,而DSSD和FPN算法分别采用了resnet-101和resnet-50作为基础特征提取网络,其网络较深导致了检测速度慢,但加入了自顶向下的特征金字塔,对船只、飞机等小目标检测比原始SSD较好,本文算法采用VGG16,网络层数相对较浅,相对于DSSD算法和FPN算法在这些类别目标上检测精度相近,而对于其它类别的目标,本文算法有了一定的提升,总体上也较DSSD算法和FPN算法相比增加了1.0和1.3个百分点,同时保证了检测速度。从其中选取了部分检测结果,如图8所示,图8(a)为原始SSD,图8(b)为DSSD算法,图8(c)为FPN算法,图8(d)为本文算法。可以看出,本文对一些小目标的检测有所加强,例如火车旁边的行人,原始SSD只检测出了尺度较大的3个人,FPN则检测出了重复的人,而本文能够检测出右侧较为明显的人和左侧的一个小尺度的人。对于中型和大型目标的检测,本文也能够进行有效的检测,例如中等尺度大小的鹦鹉,SSD、DSSD和FPN都出现了漏检的情况,本文算法能够较为全面地检测出所有的鹦鹉。

图8 各个算法检测对比
为了进一步验证本文提出的4种模块对不同尺度下目标检测的效果,对PASCAL VOC 2007 test进行分析处理,得到14 856个目标对象中最大目标所占像素掩码为245 000,而最小的目标所占的像素掩码为44,根据测试集中所有目标的尺度范围将14 856个目标划分为L、M、S这3组,分别对应大、中、小3种尺度。对本文设计的4种模块(SIEM、LIEM、FSEM、MSCA)分别进行实验并与SSD算法进行对比。如表2所示,SSD+SIEM(S)表示在SSD算法上只使用了SIEM,SSD+SIEM+LIEM(S+L)表示将SIEM与LIEM级联加入网络,SSD+FSEM(F)表示只使用了FSEM,SSD+SIEM+LIEM+FSEM(S+L+F)表示,同时采用这3种模块,但没有使用MSCA,Our表示在使用前面3种模块的基础上加入了特征融合模块MSCA,其结果见表2。
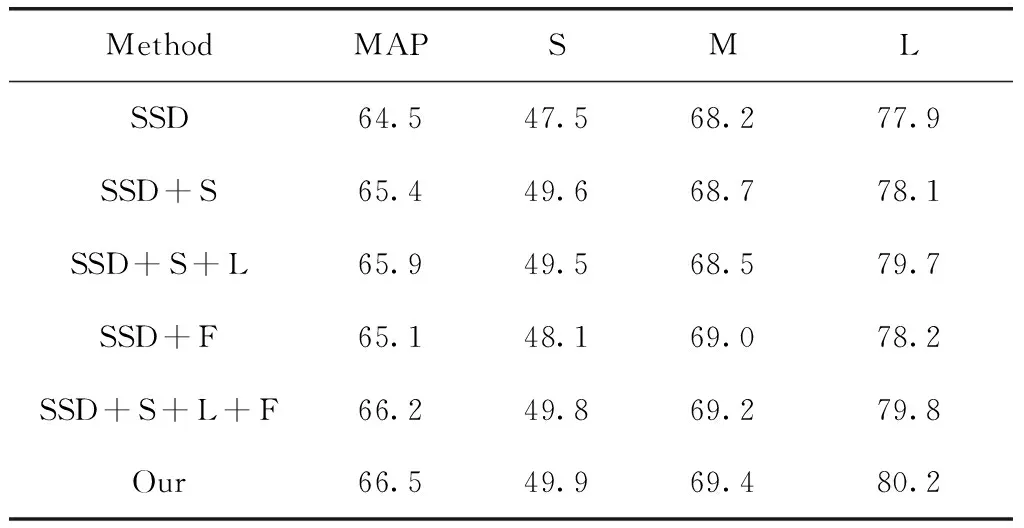
表2 对不同尺度目标的检测结果
从表2可以看出,原始SSD算法以不同尺度目标划分时检测的整体精度为64.5,本文提出的3种模块对不同尺度目标的贡献程度不同,语义信息增强模块(SIEM)更好利用了高层语义信息,将小尺度目标的检测精度提升了2.1;而级联语义信息增强模块(SIEM)和定位信息增强模块(LIEM)之后可以看到在保证小目标检测能力的同时提升大目标检测效果,将大尺度目标检测精度提升了1.8;而分裂融合增强模块(FSEM)将语义和位置信息融入到中间大小特征层,将中等尺度目标检测精度提升了0.8,在第五行(SSD+S+L+F)和第六行(Our)可以看出,在使用了前面3种模块后,加入多尺度通道聚合(MSCA)模块对网络整体效果有0.1~0.4的提升。最后本文算法对以不同尺度目标划分时检测整体精度为66.5,较原始SSD算法提升了2.0。可以验证针对不同尺度目标,本文改进的SSD算法都有所加强。
4 结束语
本文提出了一种多任务分支SSD的目标检测算法,针对检测时目标的不同尺度,采用FPN的思想和深层和浅层特征的关系设计了3种不同模块(SIEM、LIEM、FSEM),分别是自顶向下的结构、自底向上的结构和深层浅层向中间层融合的结构,SIEM加强对语义信息的传递,LIEM加强对位置信息的传递,FSEM将语义信息和定位信息引入中间层针对中等尺度目标检测,之后将SIEM与LIEM进行级联得到一组适合对大小尺度目标检测的特征金字塔。
在此基础上,将FSEM与级联结构采用并行架构组装为两个分支进行,更好的对不同尺度目标进行学习训练,在得到两个分支的特征金字塔后,使用多尺度通道聚合模块(MSCA)将两组特征金字塔聚合,并且训练了一组通道权重寻找同一尺度特征之间的依赖关系,加强对当前检测任务贡献程度大的特征的利用,同时抑制不重要的特征,让网络更注重感兴趣的特征进行学习,最后通过实验对比,可以看出本文算法相对于SSD、DSSD、FPN有更好的整体检测效果。未来可以采用更深一些的基础特征提取主干网加强对基础特征的提取,获取更好的特征,以提升检测的效果。
