基于小波包的回放语音检测算法*
2022-03-17张二华唐振民
汤 爽 张二华 唐振民
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
声纹识别作为语音识别的一个重要分支,因其自身安全性能较高、使用方便、成本低廉等优点,已经在金融交易、司法取证、门禁系统等领域得到了广泛的使用。
随着声纹技术的发展,语音技术的不断提高,各种高保真录音及播放设备的普及化,以及各种音频处理软件的广泛推广和使用,使得说话人识别系统面临严峻的挑战。说话人识别系统主要面临以下三个方面的挑战;1)模仿攻击[1],假冒者通过模仿合法说话人的声音特征来进行攻击;2)回放语音攻击[2],假冒者利用高保真设备通过获取合法说话人的回放语音进行攻击;3)合成手段攻击[3],通过音频处理软件,并利用专业手段来合成合法说话人的语音进行攻击。对于模仿攻击手段,需要模仿者高超的模仿手段,且攻击效率并不高。而语音合成则需要较高的专业手段,实现难度较大。回放语音攻击,实现起来较为方便,并且有较高的攻击性。本文主要针对于回放语音攻击的方法进行研究。
目前,国内外关于回放语音的检测还处于研究阶段。张利鹏等[4]提出使用MFCC作为信道信息的特征进行建模,提出了一种基于语音静音段的回放语音检测算法。但静音段较易受到噪声干扰,因此具有一定的局限性。王茂蓉等[5]通过改进的MFCC的特征进行语音静音段进行建模,此方法有效提高了回放语音的检测效果。此外,国外的研究如Shang 等[6]利用语音产生的随机性提出一种检测待测语音和合法语音在峰值图上的相似度的算法,但此方法只能够应用于文本相关的声纹认证系统。Todisco 等[7]在2016 年提出一种基于常Q 变换的常Q 倒谱系数(Constant Q Cepstral Coefficients,CQCC)特征。CQCC使用常Q变换代替传统的傅里叶变换,相比传统傅里叶变换,常Q 变换在低频处有更高的频率分辨率,在高频部分有更高的时间分辨率的,对回放语音的检测具有较高的精度。
语音信号属于一种非平稳信号,通过传统的傅里叶变换来获取和分析语音信号的有关特性并不能得到较好的效果。首先本文使用小波包分解及重构获取语音信号各子频带的分量信号;然后通过傅里叶变换来估计该频带的主频率;最后利用各子频带的主频率分布量来分析原始语音和回放语音在频域中的差别。结果表明,回放语音与真实语音相比在低频带和高频带都在有很明显的衰减,同时中频带的主频率分布量会增高。基于此,本文利用小波包分解及重构提取的多频带语音特征作为鉴别特征,实验表明,该方法对回放语音有较好的检测效果。
2 小波包分解与重构的频率幅值估计
2.1 小波包分解与重构
小波包分解,将频率进行多层次的划分,使小波变换中没有细分的高频部分进行进一步分解,根据语音信号的实际情况,自动调节时频窗口,从而提高了时频分辨率[8]。小波包分解过程,以一个五层小波包的分解为例,可用图1表示。

图1 信号的五层小波包分解
由图1 可知,信号经过小波包的五层分解得到32个节点,其中S0,0为原始的语音信号,S1,0和S1,1分别是原始语音信号经过一层小波包分解后低频部分和高频部分的子频带信号,类似的S1,0进一步分解成S2,0和S2,1,后面逐层分解。语音信号S0,0经过M层分解后可表示成:

2.2 单分量信号的主频率幅值估计
语音信号可看作是短时平稳的多分量信号[11],因此利用小波包的分解及重构后,将信号分解成多个单分量信号。图2 是语音波形图及单帧频谱曲线,图2(a)是语音波形图,图2(b)表示该语音第32帧的频谱曲线。图3 是第32 帧语音信号经过小波包分解及重构后32 个频带中部分频带的频谱曲线,每个频带的带宽大约为250Hz,图3(a)、图3(b)、图3(c)分别表示第32 帧第2、3、4 频带频谱曲线,对应的频带范围分别为250Hz~500Hz、500Hz~750Hz、750Hz~1000Hz。根据图3 可以看出,在一帧中任一频带只有一个较明显的波峰,故在一帧中不同频带的主频率幅值可通过此频带波峰的峰值进行估计。

图2 语音波形图及单帧频谱曲线

图3 小波包重构后频谱曲线图
对于单分量信号来说,其主频率靠近或重合于时频峰值[12]。所以单分量信号的主频率幅值可以通过下面方式获取:

其中,短时傅里叶变换:

其中j,i分别为帧号和频带号。
将得到频率分布量绘制成灰度图,如图4 所示,图4(a)是ASVspoof 2017[13~14]数据集中“我的声音就是我的密码”英文原始语音的频率分布图,图4(b)、图4(c)、图4(d)分别是同一个人同一段话不同情况下的回放语音,图中浅色部分表示频率分布量高,深色部分则相反。相比较于真实现场说话语音,回放语音在低频部分(图中白色标记处)和高频部分(图中灰色标记处)都有较为明显的损失,在高频部分损失尤为突出,在文献[15]中也提出语音的高频区域在语音的重放检测中至关重要,所以在本文的检测方法中同时利用语音的各个频段,包括高频部分进行特征提取。

图4 真实语音及回放语音频率分布图
3 特征提取
本文利用小波包分解及重构后各频带的频谱来进行进一步的特征提取,特征提取的过程如图5所示。
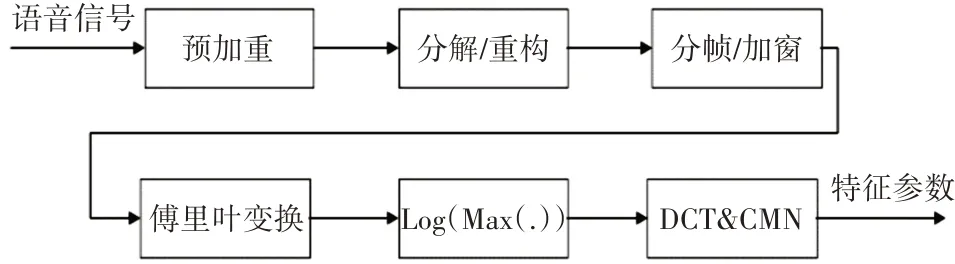
图5 特征提取流程图
算法流程如下:
1)输入的语音信号通过一个预加重滤波器进行滤波,该滤波器平衡低频和高频信号,平坦幅度谱[16]。预加重传递函数:
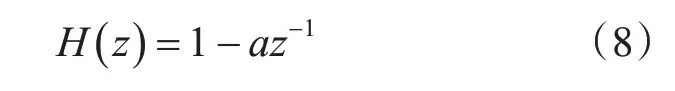
其中a 为预加重系数,取值范围为0.9<a<1.0,一般取值为0.98。
2)利用小波包对预加重后的语音进行分解和重构,小波包分解是利用低通滤波器以及高通滤波器进行多层分解,将分解后的小波系数进行重构,得到重构后的信号Sj,i(u),j,i分别表示第j层和第i个节点,u为原始语音长度。
3)将重构后每一个频带的信号进行分帧加窗,然后对每一帧信号Sn( )m作短时离散傅里叶变换来计算此帧的频谱Xn(k)。

由于所求的静态特征没有反映出帧间信息,因此通过求取特征的一阶差分来代表帧间的动态变化信息,并且在最终测试的时候利用静态特征加上动态特征共64维组成。
4 检测算法
利用训练集训练鉴别模型时,首先提取语音特征,然后训练GMM 模型作为鉴别模型。训练数据分两个子集,一个原始语音集,一个回放语音集。分别利用这两个子集进行原始语音模型和回放语音模型的建立,其中原始语音模型记作λt,回放语音模型记作λf。利用测试集进行测试的时候,分别提取测试集中每条未知语音的特征,然后计算他们在λt和λf中的后验概率。最终判断该语音是真实语音还是回放语音是基于Log-Likelihood Ratio(LLR)[17]来进行判断的。
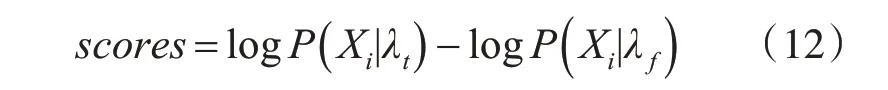
其中P(X|λt)和P(X|λf)分别是特征向量X 在真实模型下和回放模型下的得分。从式(12)中可知,最终得分是特征向量在原始语音模型下的后验概率与在回放模型下的后验概率的似然比,如果scores>θ则代表真实语音,反之则为回放语音。整个回放语音检测过程可用图6表示。
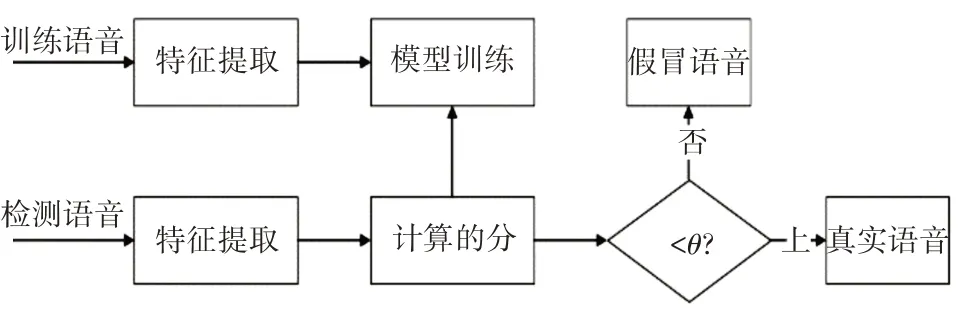
图6 回放语音检测流程图
5 实验对比
5.1 数据集介绍
为了检验本文算法的有效性,在回放语音检测的数据集方面采用了ASVspoof 2017[13~14]提供的V2数据集。数据集中使用的是RedDots 语料库中的10 个短语,通过不同的设备进行偷录和回放,语音库详情见表1所示。
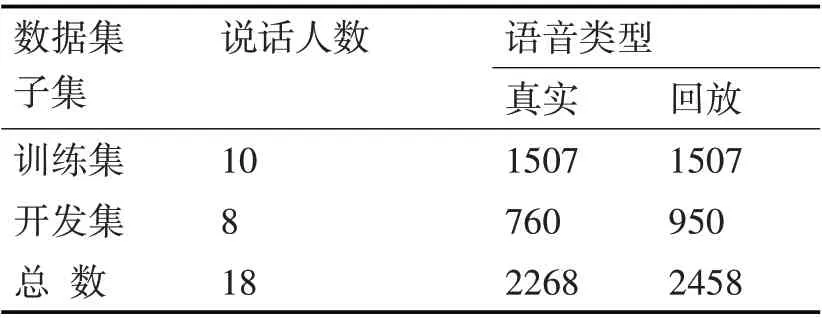
表1 ASVspoof 2017_V2语音库详情表
另外,此数据集是使用多种设备和环境进行语料收集。在训练集中有2 种不同的录音环境,1 种录音设备,3种回放设备;在开发集种有4种不同的录音环境,7 种录音设备,6 种回放设备。本文算法将利用训练集进行模型训练,用开发集作为测试数据集。
5.2 在不同小波基下的实验对比
傅里叶分析方法是将信号利用一系列不同频率的正弦函数进行叠加,而小波则是利用一系列不同的小波基函数进行分析,因此应用不同的小波基函数得到的结果也是不一样的,所以利用小波包对语音信号进行分解和重构,小波基函数的选取对提取特征的效果有直接的影响。在本文实验中选取了几种常见的小波基函数来进行前期的语音信号处理。表2 列出在使用不同的小波基函数后所提取的特征在开发集上的效果,且在分解时都采用的是6层分解。
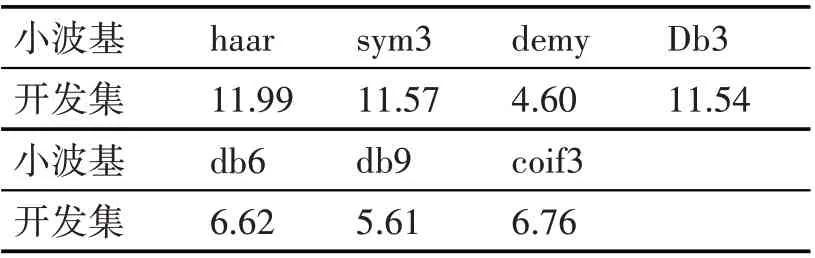
表2 不同小波基下的EER%对比
由表2 可以看出,在使用不同的小波基函数情况下,得到的特征在鉴别效果上也有所不同,其中Demy 小波基效果最好,因此在本文的特征提取中也以此作为最优小波基的选取。
5.3 在不同的分解层数下的对比
在小波包分解过程中,需要考虑到小波包分解的层数对结果的影响。层数选取过小,会导致分解后的波形有多分量信号的干扰,最后提取的特征将会造成信息遗漏,导致最后的整体效果不佳;层数选取过大,则会导致特征维度的增加,以及部分层数的信息冗余。所以需选取合适层数,这样既能保证特征对语音信号中信息的保留,也避免了特征维度的过大情况。下面通过几组不同的特征层数的对比来查看小波分解过程中分解层数对最终效果的影响。
由表3 可以看出,不同阶数的高斯混合模型以及不同的分解层数都会影响最终结果。另外,阶数越高需要对比计算的次数也就越多,分解层数越多特征的维度也就越高,所以在一定阶数和分解层数下保持特征的有效性尤为重要。由表3 可知当高斯函数为256,分解层数为5 层时,效果最好,所以本文采用256 个高斯函数,5 层小波包分解作为最终的参数选择。
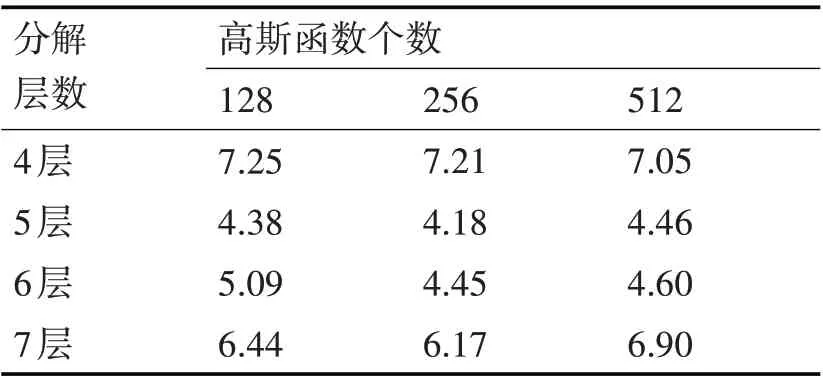
表3 不同分解层数提取特征的EER%
5.4 不同特征的对比实验结果
由于本次使用的检测模型与基线模型GMM模型保持一致,那么在本文的对比实验中,GMM 模型的阶数为256,利用不同的特征进行对比,观察不同特征在相同数据集下的表现力。
在本文的不同特征的对比实验中,采用文献[6]提出的CQCC 算法,以及MFCC 和LFCC 算法与本文所介绍的算法进行对比。CQCC 算法是一种基于常量Q变换的倒谱特征,该特征是先将语音信号进行常量Q 变换,得到语音信号的能量谱后取对数,然后进行均匀重采样后经过离散余弦变换得到CQCC特征。得到的实验结果如表4所示。

表4 不同特征在不同特征集下的EER%
6 结语
本文通过小波包的分解和重构,将语音信号分为多个频带进行分析,通过提取每个频带的频谱分布量来观察真实说话人语音和假冒说话人语音之间的区别,说明真实说话人语音和假冒说话人语音之间在高频和低频部分的分布量有明显的区别,并基于此提取的假冒语音鉴别特征。通过在ASVspoof 2017 数据库上与常用的语音特征进行对比,发现有一定程度上的提高。然而,科技的发展以及音频设备的不断更新,使得回放语音检测在声纹识别领域仍然有很大的挑战,因此在如何在多环境,多设备下能更有效地检测出回放语音需要进一步的研究。
