动态视频多帧连续图像形变特征重构方法研究
2022-02-09王华东
韩 丽,王华东
(1. 郑州轻工业大学计算机与通信工程学院,河南 郑州 450000;2. 郑州轻工业大学信息化管理中心,河南 郑州 450000)
1 引言
随着时代的发展,数据的形式发生了沧海桑田般的变化,传统的图像已满足不了人们的日常需求[1,2]。与此同时,随着视频的兴盛,视频图像中含有的运动信息和画面信息等复杂特征,在图像发生形变后使图像的识别更加困难,因此需要结合图像的时间和空间等相关显著目标才能更好的重构视频的连续图像[3,4]。
近年来,动态视频成为计算机视觉领域研究的热点问题之一,引起广大研究者的关注。文献[5]将图像中冗余的信息剔除,对图像进行预处理,同时对连续形变的图像采取参照原本图像信息与灰度相融合的方式实现图像变光背景的更新,通过对图像特征矩阵的计算,完成矩阵相似信息的自适应识别,该方法对连续形变图像信息的识别率较高,适应性较好。文献[6]通过分数阶微分函数增加图像的高频分量,使图像细节增强,采用高斯平滑滤波算子对拉格朗日梯度算子进行更新,去除影响图像重构的高斯白噪声增量,该方法使图像重构的质量有了明显地提高,并增加了图像的纹理细节。文献[7]利用BRISK特征检测方法对视频中的特征点进行提取,确定图像跟踪的目标模板和特征集合,利用FLANN方法对特征点子集进行匹配,确定视频图像中的可靠特征点子集,若有三帧连续的目标发生形变,对目标模板和特征点集进行更新,该方法对形变严重的视频图像具有较好的跟踪效果,跟踪精度较高。
基于以上研究,本文提出动态视频多帧连续图像形变特征重构方法。使用卷积网络对视频图像的特征进行提取,有利于实现图像的重构效果,利用改进的残差结构进行时间-空间特征融合,重构出细节更加丰富的视频图像。
2 动态视频帧的计算
对于动态视频流中特征的处理主要有帧间差分和光流两种方法。光流法主要是通过目标速度与背景的不同将两者区分开,但算法较为复杂,计算效率低。而帧差法执行速度相对更快,因此这里对视频信息的处理采用改进的帧差法。视频是由若干帧组成的视频序列,具有连续性。如果视频中没有运动目标,那么连续帧变化不明显;如果视频中存在运动目标,那么连续帧变化明显。因此目标的运动使图像帧的位置不同,各个像素点间存在像素差。帧差法对连续帧进行差分运算,将RGB图像转化为灰度图像后对灰度差的绝对值进行判断。若绝对值比阈值低,则判定该点为背景点;若绝对值比阈值高,则判定该点为运动目标,公式可表示为
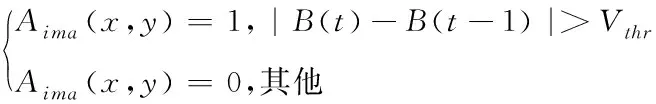
(1)
其中,Aima(x,y)=1表示前景;Aima(x,y)=0表示背景;B(t)表示t时刻的图像;B(t-1)表示t-1时刻的图像;Vthr表示差分图像的阈值。由于运动目标的内部灰度值较为接近,使检测的运动目标存在“空洞”现象,因此只能提取运动目标的轮廓信息,使图片信息不完整。基于此对帧差法进行改进,将图像的当前帧和后一帧作为输入,分别对当前帧图像的RGB三个通道做差分运算,并进行加权求和处理,公式可表示为
(2)
其中,BR(t)、BG(t)和BB(t)分别表示t时刻R、G和B三个通道的图像;BR(t+1)、BG(t+1)和BB(t+1)分别表示t+1时刻R、G和B三个通道的图像。改进后的帧差法不仅改善了图像的“空洞”现象,还明显增强了目标的运行痕迹。图1 为改进后帧差法与传统帧差法的计算对比结果。
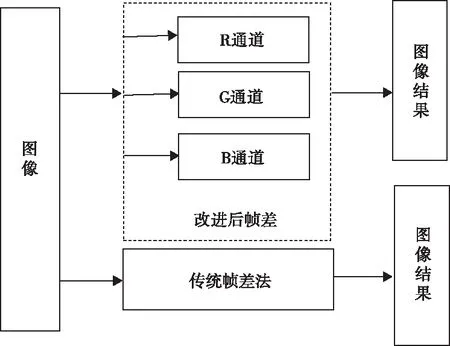
图1 改进帧差法与传统帧差法的对比图
对视频的显著性进行检测,不仅要考虑时间上的运动特征,还要对当前视频帧的空间特征进行分析,本文采用卷积神经网络对视频的显著性进行检测。采用卷积对输入的视频图像进行特征提取,然后对提取的多特征进行时间与空间特征的融合处理,公式表示为

(3)

特征提取主要是对输入视频的初步特征进行提取,由于固定大小的卷积核只能提取一种尺度的特征,而不同大小的卷积核可以提取不同尺度的特征信息,因此采用大小不同的卷积核对图像特征进行提取,获得更加丰富的图像信息,有利于图像特征的重构。在特征提取模块中分别使用大小为3和5的卷积核对图像的两种尺度进行特征提取,同时为了减少网络中的参数,将各个卷积层输入到一个卷积核大小为1的卷积层中,并将输出合并到一起,公式表示为
Dout_img=E1([E3(X),E5(X)])
(4)
其中,Dout_img表示图像的输出特征;E表示进行的卷积操作;X表示图像的输入信息。进行特征提取后,需要对图像的特征进行时间-空间的融合处理,采用卷积残差块的方法进行特征融合。其中包含3个卷积层,前2个卷积层使用卷积核的大小为3;同时将第1个卷积层的输出分成Dout_img1和Dout_img2两部分,第2个卷积层只对Dout_img2作处理,最后使用卷积核大小为1的卷积层将两部分特征融合起来,公式表示为

(5)
其中,F表示分离操作;Dout_img_in表示残差块的输入;Dout_img表示图像的特征输出。通过残差块对时间-空间的融合可以对视频帧间的运动进行较好的补偿,不仅可以降低网路的复杂度,还可以使图像的重构结果更加准确。
3 特征重构方法模型
当动态视频连续多帧变化时,会使视频中目标姿态发生剧烈的改变,如果不对形变的图像进行重构,会导致对提取的特征点出现误判,因此需要对图像特征进行重构。重构方法模型可表示为

(6)
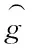

(7)
其中,δ表示正常数;x表示辅助变量;l表示拉格朗日常数。为了进一步解决低秩矩阵极小化问题,对式(6)进行迭代求解,公式表示为

(8)
其中,t表示迭代次数。综上所述图像的重构问题可转换成对Li、g和x求解的问题。
3.1 低秩矩阵Li求解
首先假定g和x为固定值,Li优化后通过加权范数处理,用公式可表示为
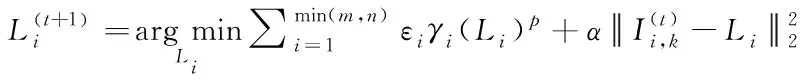
(9)


(10)


(11)


(12)
其中,μ为利普希茨常量,于是Li的求解问题可转换为求解加权核范数的最小化问题,通过迭代权重加权核就可以方便的计算出其数值。
3.2 特征信号g求解
假定Li和x为固定值,原始图像的特征信号g的优化处理公式可表示为

(13)
由上式可知,g优化处理后是一个凸二次优化问题,将其进行封闭求解,公式可表示为

(14)
其中,I表示单位矩阵。因图像中含有大量信息,采用共轭梯度法进行求解,可以大大提高运算的速率。
3.3 辅助变量x求解
假定Li和g为固定值,辅助变量x的优化处理公式可表示为

(15)
由上式可知,x优化处理后也是一个凸二次函数的极小化问题,为了得到x的封闭解,对其进行求导,得

(16)
4 实验结果与分析
为了验证动态视频多帧连续图像形变特征重构方法的有效性和适用性,本文选择VideoSal数据集,其中包含不同场景的视频序列7万个,每个视频序列由7帧连续的视频帧组成,较为全面的覆盖了目标的高速运动和角度变化等场景,能够对视频显著性进行有效地验证。本文通过平均绝对误差(MEA)和精确率与召回率的加权平均(F-Measure)两个指标对实验结果进行评价。
MEA表示原始图像与其在像素层的真值之间的绝对误差平均值,公式表示为

(17)
其中,U表示原始图像;V表示原始图像在像素层的真值;Wima表示图像的宽度;Hima表示图像的高度;(x,y)表示像素点与中心像素点的坐标。
F-Measure表示精度与召回率加权后的平均值,用公式可表示为

(18)
其中,ζ表示权重,J表示精确率;Z表示召回率。
4.1 特征融合的验证
为了验证特征融合对视频的作用,使用普通的残差块与本文提出改进的残差块对网络进行训练,分别用方法1和方法2表示,并在VideoSal数据集上测试。对比结果如表1所示。

表1 两种方法的性能评价指标
从表中可以看出,采用普通残差块方法对视频融合时,MEA和F-Measure这两种性能评价指标明显没有本文改进后的方法好,而且网络参数量比本文方法略高。为了验证视频融合过程的有效性,将本文方法与文献[5]、文献[6]和文献[7]的方法进行对比,同时对图像进行2倍和4倍的放大处理,不同方法在VideoSal数据集上的评价指标如表2所示。

表2 不同放大倍数下性能评价指标
从表中可以看出,本文提出的方法与其它方法相比,评价指标均有一定的提升,证明了本文方法的有效性。在进行图像的2倍放大时,与效果较好的文献[6]和文献[7]方法相比,本文方法在MEA指标上分别提高了0.025和0.021;在F-Measure指标上分别提高了0.207和0.146。在进行图像的4倍放大时,本文方法较文献[6]和文献[7]方法在MEA指标上分别提高了0.03和0.026;在F-Measure指标上分别提高了0.209和0.147。虽然在网络参数量上本文方法比文献[7]方法略高,但获得的重建性能较好。
4.2 重构性能评估
为了对视频中某帧图像的检测效果进行验证,随机选择3张VideoSal数据集中的某帧图像作为目标图像,并将本文方法与文献[5]、文献[6]和文献[7]的方法进行对比。各个重构算法的图像对比图如图2所示。

图2 不同方法重构图像对比结果
从图中可以看出,采用文献[5]和文献[6]的方法重构出的图像边缘等细节较为模糊,重构的效果比较差;利用文献[7]的方法,当采样率较低时,重构图像相对有改善,但边缘等细节仍不能取得较好的效果;而本文的重构方法,充分利用了函数求解和图像本身的特性,即使在低秩矩阵中,图像的重构效果也较好,与原始图像最为接近,视觉效果比其它方法相对较好,通过图像的局部放大可以看出本文方法对图像的细节保护性能更佳。
5 结束语
本文提出动态视频多帧连续图像形变重构方法,利用改进后的帧间差分法对视频帧的RGB三通道上的差分值进行计算,提取图像在时间上的运动特性,再通过卷积神经网络对视频的每帧图像进行空间特征的提取,并采用改进的残差块对RGB通道分离出的图像特征进行融合,对形变的图像通过改进后的方法进行重构。在VideoSal数据集上将本文方法与其它文献方法进行对比,并选择MEA和F-Measure这两个值作为性能评价指标。实验结果表明,本文方法与采用普通残差块方法对视频融合时,MEA和F-Measure性能评价指标较好,且网络参数量较少,图像的重构效果与原始图像最为接近,对图像的细节保护性能更佳。
