基于级联网络人脸五特征点检测及其应用
2022-02-09郭克友贺云霞
郭克友,贺云霞,胡 巍
(北京工商大学,北京 100048)
1 引言
以据统计,疲劳驾驶、酒驾等人为因素是引发交通事故的主要原因,这都与驾驶员的精神状态和注意力集中程度密切相关,因此对驾驶员驾驶状态进行有效检测有利于防止交通事故的发生。对于驾驶员的注意力检测大致可以分为三类:一是根据驾驶员的生理参数判断,比如通过眼睛闭合时间占特定时间的百分率作为疲劳程度的衡量指标[1,2];二是根据车辆行驶的状态[3];三是根据驾驶员面部姿态估计[4],精确的人脸特征点定位可以估计出人脸偏转的角度,遮挡、光照的明暗、较大的头部旋转和夸张的表情变化等因素都会影响特征点定位的准确性。人脸特征点检测的主流方法是先进行人脸检测,检测出人脸的边界框,再预测出眼睛、鼻子、轮廓等关键点。
人脸特征点检测方法大致分为三类。一是ASM[5](Active Shape Model)和AAM[6](Active Appearnce Model)基于模型的方法;二是2010年,Dollar提出CPR[7](Cascaded Pose Regression)基于回归的方法;三是基于深度学习[8]的方法:2013年,Sun等人[9]首次将卷积神经网络应用到人脸关键点检测;2016年,Zhang等人[10]提出一种多任务级联卷积神经网络MTCNN(Multi-task Cascaded Convolutional Networks)用以同时处理人脸检测和人脸关键点定位问题。香港中文大学的汤晓鸥教授团队提出TCDCN[11],同时进行多任务学习,通过性别、是否戴眼镜和脸部姿态辅助定位特征点。
特征点提取这块由于目前是基于深度神经网络的,计算量特别大,因此考虑对五特征点检测的网络进行简化,达到节约时间的目的。针对DCNN三级预测比较复杂的问题,提出了一种优化方式,将原来的检测模型改为两级检测模型。选取五个固定点即眼角、鼻子、嘴角作为特征点进行预测,选用级联卷积网络,将上一级的输出作为下一级的输入,在不同层选用不同大小的卷积滤波器,有效提高速度与精度,更快的检测出人脸的特征点。然后运用检测出的人脸特征点像素坐标输入线性方程,计算得出单应性矩阵,从而求出面部转过的角度。通过实验证明了提出的方法在简化网络的同时精度还有略微的提升,并且检测出的特征点能进行注意力检测。
下面首先简要介绍原始的DCNN网络,然后重点介绍优化和改进方式。实验从两方面展开,第一部分介绍优化方式相比于原始DCNN的提升效果,接着用提出方法检测出的特征点去计算面部转角来证明所提出的方法可以用于注意力检测。
2 基于级联网络人脸五特征点检测
2.1 DCNN
DCNN的总体思想是有粗到细实现人脸关键点的定位,整个网络结构分为三层:level1、level2、level3,每层都包含多个神经网络模型。level1是粗略定位,分三层负责部分或全部关键点定位,每个关键点至少被预测两次,取结果的平均值得到第一层粗定位的结果。Level2是将第一层的输出五个特征点截成五张小图像,分别输入到level2中的十层网络组,每个特征点被训练两次,输出两次平均定位,以获得准确的定位。将level2输出的五特征点,裁剪成更小的五张图像,输入到level3中,level3的结构与作用与level2一致,以获得更精确的五特征点定位。
2.2 DCNN结构改进
改进过的五特征点检测网络是由两个小网络组成级联网络,完成人脸边界框内的五个特征点回归的任务,五个特征点分别为左眼角(LE)、右眼的右眼角(RE)、鼻尖(N)、左嘴角(LM)和右嘴角(M)。具体流程如图1所示:首先输入已知人脸框图的图像输入第一级网络,第一级网络有1F、1EN和1NM三层深度神经网络,将人脸边界框resize到39×39尺寸后输入1F网络,预测人脸出五个特征点,再将人脸边界框裁剪至31×39尺寸,图像包括眼角和鼻尖输入1EN,预测出三个特征点,最后一层网络1NM的输入图像包括鼻尖和嘴角,预测出鼻尖和嘴角三个特征点,将三个深度卷积网络预测出的特征点做均值处理,输出人脸五个特征点的粗定位。第二级网络包括十个浅层卷积神经网络,分别表示为2LE1、2LE2、2RE1、2RE2、2N1、2N2、2LM1、2LM2、2RM1以及2RM2,由第一级网络得到五个特征点的粗定位,以预测特征点位置为中心的局部位置裁剪至15×15的图像作为第二级网络各个浅层神经网络的输入,2LE1表示第二级中预测左眼角的第一个卷积网络,以此类推,每个特征点会被训练两次,对两次训练输出的特征点位置进行平均处理,得出较精确的定位,第二级网络是对第一级网络预测的结果进行微小的修改。
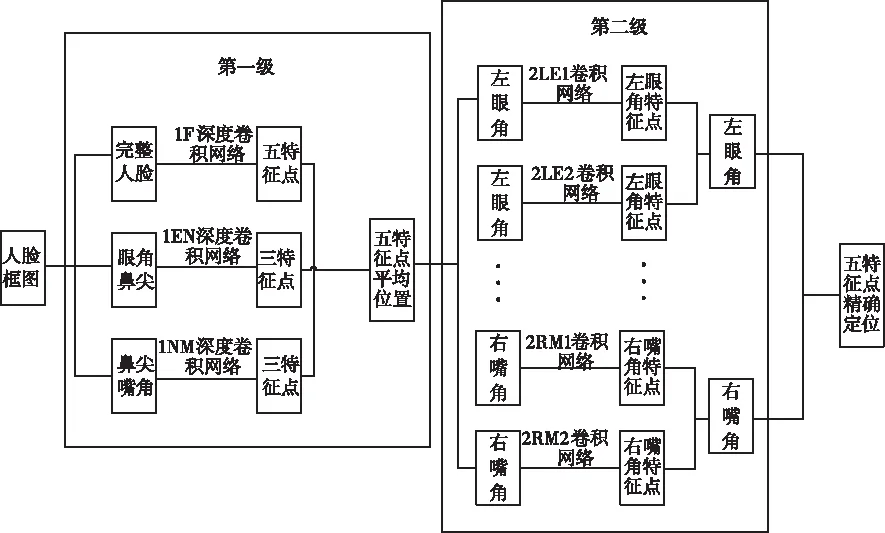
图1 级联DCNN结构图
2.3 卷积神经网络结构改进
第一级网络需要从输入的人脸框图中直接检测出五个特诊点,这是比较困难并且难以训练的任务,卷积神经网络需要足够的深度才能从全局出发,形成更高层次的特征。通过结合低层提取的空间邻近特征,高层神经元可以从较大区域提取特征。除此之外,高层次的特征通常是高非线性的,可以通过在卷积层后添加激活函数用于增加从输入到输出的非线性。第一级深度神经网络选用vanilla CNN,其网络结构如图2所示,深度卷积神经网络由一个卷积核为5×5的卷积层,两个卷积核为3×3的卷积层以及一个卷积核为2×2的卷积层和两个全连接层组成,选择最大池化。vanilla CNN是用来训练面部的特征点,这是一个基于回归面部特征点网络的松散网络,选择此模型是因其简单性。该网络应从输入的人脸框图中预测出五个特征点,1F深度神经网络的检测窗口大小为39×39,1EN和1NM的检测窗口大小为39×31,将1F、1EN和1NM三张图像分别输入速度卷积神经网络,经过四个卷积层和两个全连接层后进行损失计算,四层卷积层使用的卷积核逐层递减,即感受野逐层减少,池化层选用最大池化。经过三个深度卷积网络的训练,眼角和嘴角会被训练两次,鼻尖会被训练三次,将训练输出的特征点做均值处理即可得到五个特征点的粗定位。对于卷积层中的神经元选用双曲正切激活函数后的绝对值校正,此激活函数可以有效地提高性能。实践研究表明,该方法在实际应用中也是有效的。

图2 第一级深度卷积神经网络结构图
第二级是在局部位置精确特征点的位置,只需浅层的神经网络即可达到目的,所有卷积神经网络都共享一个较浅的网络结构,如图3所示。以2LE卷积神经网络为例,将第一级网络所预测的左眼粗定位为中心,裁剪检测窗口至15×15,经过两个卷积层和两个全连接层后进行损失计算,两个卷积层选用的卷积核大小分别为4×4和3×3,池化层依旧为最大池化层。每一个特征点会经过两个浅层神经网络训练,最后对两次训练输出的特征点位置进行平均处理,得出局部位置较精确的定位。对于卷积层中选用ReLU激活函数。

图3 第二级浅层卷积神经网络结构图
在同一特征图上局部共享神经元的权重可以提高网络性能。传统的卷积网络基于两个考虑共享同一特征图上所有神经元的权值。首先,假设相同的特征可能出现在图像的任何地方。因此,能应用于某一地方的过滤器,也能应用于其它地方。其次,权值共享有助于防止梯度扩散,由于共享权值的梯度是聚集的,这使得深层结构的监督学习更加容易。然而,全局共享权重在固定空间布局的图像上效果并不好。比如在人脸检测时,虽然眼睛和嘴巴可能有像边缘这样的共同低级特征,但它们在高层次上是非常不同的。因此,对于输入包含不同语义区域的网络,在高层上局部共享权值对于学习不同的高层特征更有效。
2.4 网络训练
第一级的三个网络依次训练,先训练1F深度卷积神经网络,再训练1EN深度卷积神经网络,最后训练1NM深度卷积神经网络。卷积神经网络的训练流程是输入图像I(h,w),h和w分别为图像的高和宽,C(s,n,p,q)定义为有n个特征图、卷积核边长为s的卷积层,p、q为权值共享参数。卷积层的计算为式(1)。P(s)定义为池化区域边长为s的最大池化层,如式(2),进行正切非线性处理和绝对值修正。经过多层卷积与池化,最后进入全连接层F(n),如式(3)

(1)

(2)

(3)
第二级是以第一级人脸特征点的预测位置为中心的局部位置作为输入,只是对特征点的位置进行微调,输入大小为15×15,提取低层特征,神经网络只有两次卷积,为浅层的神经网络,迭代次数不宜过大。第二级网络与第一级网络类似,十个浅层卷积神经网络依次训练,每个网络迭代100,000 次。ω权重的学习率为0.01,b常数向量的学习率为0.02,通过随机梯度下降进行学习。学习率的更新策略为Poly,即每次反向传播以后使用式(4)更新每次的学习率

(4)
其中base_lr为基础学习率,iter为当前迭代次数,maxiter为迭代次数,学习率曲线主要由power值控制。
3 实验
3.1 实验设置
首先用改进的算法进行五特征点检测,然后再用检测出的特征点计算面部转角来证明所提出的方法能用于注意力检测。本实验用到的环境:Ubuntu16.04,caffe深度学习框架,opencv4.1.0。
本实验的训练集包含5590张LFW图像和7876张来自网络的图像,所有的图片都被标记为5个面部标记。将图片中眼珠的标记,改成眼角的标记。删除侧脸与严重遮挡的图像,剩下的面孔被随机分割,其中8000张用于训练,1856张用于验证。测试集包括1521张BioID图像、781张LFPW图像和249张LFPW测试图像。
3.2 五特征检测实验
针对人脸特征点检测,对测试集1856张图片进行测试,得到失败率以及平均误差,如表1所示。误差为预测值与真实值间的横向像素距离占输入人脸框图宽度的比例,当误差大于0.05时,被定义为无效预测即预测失败,失败率为预测无效的图片占测试集图片的比例。平均误差为所有测试集误差的平均值。
与未改进的DCNN[12]相比,只运用了两级网络便达到了使用三级网络的效果,甚至得到了更高的准确率,改进后的DCNN只需要训练两级网络,大大缩短了训练的时间,并用相同的数据在MTCNN上进行实验。结果对比如表2所示。

表1 人脸特征点检测准确率

表2 实验结果对比
3.3 人脸转角实验
在检测出五个人脸特征点的基础上,使用单应性矩阵[13]计算人脸偏转角度。面部转向一般绕头部中心轴转动,此转角与相机绕相机中心轴转过的角度相同,因此可以转化为两个不同位置的相机对同一物体拍摄,运用单应性矩阵求两个相机相对位置的问题。单应性矩阵用于描述物体在世界坐标系和像素坐标系之间的位置映射关系,如式(5)。

(5)
其中M为相机的内参矩阵,T为相机的外参矩阵,由旋转矩阵的前两列r1、r2和平移矩阵t组合而成。
本课题组对人脸偏转角度误差进行实验,实验结果表明运用单应性矩阵计算出的角度与实际偏转角度相差1-5°。本实验在计算角度误差的基础上,验证人脸偏转角度的大小对单应性矩阵计算角度准确率的影响。
首先在正对驾驶员的位置固定相机,用相机拍摄出驾驶员左右偏转10°、20°、30°时的姿态;其次用级联卷积神经网络检测出人脸五特征点;然后选用眼角和嘴角四个特征点,将八个点的像素坐标带入式(6)、(7),计算出单应性矩阵H;最后鼻尖特征点用于验证单应性矩阵的像素误差,人脸检测出的实际鼻子坐标与单应性矩阵计算出的坐标点的误差。

(6)

(7)

针对人脸转角计算,实验以Y轴为中心轴做转向实验,在左右偏转10°、20°、30°以及正视时定格,拍摄7张照片,照片的像素为1280×720。图4为每偏转10°拍摄的图像,图5为每偏转20°拍摄的图像,图6为每偏转30°拍摄的图像,五角星代表根据单应性矩阵计算出的鼻子像素点,点代表级联卷积神经网络测试的鼻子特征点,两点之间存在一定的误差。表3列出了偏转10°、20°、30°时单应性矩阵计算出的鼻子像素点和改进后DCNN的鼻子特征点之间的平均像素误差,误差率为平均像素误差占输入人脸框图宽度的比例。针对人脸特征点的选择对偏转角度的影响,选择利用眼角和眼珠分别作为特征点带入单应性矩阵计算人脸偏转角度,对比偏转误差,如表4所示。

图4 偏转10°像素误差图

图5 偏转20°像素误差图

图6 偏转30°像素误差图

表3 像素误差结果对比

表4 眼珠与眼角偏转误差结果对比
结果表明偏转角度越大,由单应性矩阵计算得出的鼻子像素点与人脸定位得出的鼻子特征点之间的误差越大。由此可得,在驾驶员偏转较小的角度时,计算得出的误差较小,当驾驶员瞬时偏转较大角度时,根据单应性矩阵求出的偏转角度可能会存在较大误差。相比于眼珠作为特征点,眼角作为特征点所得的人脸偏转角度误差较小。
4 结论
文中对传统的级联深度卷积神经网络检测人脸五特征点做出了改进,将原先的三级级联神经网络缩减为两级级联神经网络,在缩短训练时间的同时,略提高了检测的准确率。将检测出的特征点运用在单应性矩阵计算人脸偏转上也取得了较好的成果。基于级联网络人脸五特征点的检测的输入是已检测出人脸的图像,后期可加入人脸框的检测。若当驾驶员瞬时偏转的角度过大时,会导致计算的角度偏差较大。
