改进FP-Growth算法下云服务器故障诊断研究
2022-02-09王大勇
张 衡,王大勇,宋 朋
(辽宁大学,辽宁 沈阳 110036)
1 引言
计算机技术的应用领域日益广泛,对计算机的可靠性要求也越来越高。尤其在一些特殊的应用领域,例如在实验室方面,对服务器的应用性能要求更高。现阶段,计算机硬件已经得到了很大程度的提升,但是软件设计日益复杂,带来了很多的潜在隐患。尤其是在比较特殊的环境下,都容易导致实验室服务器出现故障[1,2],同时还会产生比较大的经济损失。
为了有效解决上述问题,国内相关专家针对服务器故障诊断方面的内容展开了大量研究,例如李奎等人[3]对声音信号和振动信号经验模态分解处理,提取不同类型信号的IMF(固有模态函数,Intrinsic Mode Function)包络能量熵,将其设定为特征向量输入,同时使用D-S(登普斯特-谢弗,Dempster-Shafer)证据理论对声振信号加权概率分配完成决策层融合处理,最终获取故障诊断结果。于斌等人[4]提出了一种基于并行运行时验证的DoS(拒绝服务,Denial of Service)攻击检测方法。描述边缘服务器预期行为和DoS攻击特征。采用并行运行时验证框架,充分利用边缘服务器的计算与存储资源,对服务器程序运行状态进行异常检测和误用检测。在以上几种方法的基础上,提出一种基于改进FP-Growth算法的云服务器故障诊断方法。经实验测试结果表明,所提方法能够得到更加精准的服务器故障诊断结果。
2 云服务器故障诊断
2.1 改进FP-Growth算法
FP-Growth算法的基本思想就是将事务数据库中的事务开展剪枝以及排序等相关操作,有效保留各个数据项之间的关系[5]。以下给出FP-Growth算法的详细操作步骤:
1)获取频繁项列表
对事务数据库遍历处理,主要负责完成数据库中全部项数据统计工作,将小于最小尺度计数的数据项删除,同时根据频数递减对数据项排序处理,进而获取频繁项列表。
2)建立FP-tree
以Null(零器)为根节点构建FP-tree,通过Flist对数据库中的全部数据项排序处理,将不满足最小支持度的数据项删除。将完成排序的事务插入到FP-tree中,判断路径是否可以分享,假设可以分享,则需要记录节点数量。
3)挖掘FP-tree
设定后缀模式以及初始值,采用FP-tree算法挖掘FP-tree;假设FP-tree为单分支,则删除小于最小支持度的节点,将剩余节点组成任务集合,经过对比分析获取对应的频繁项集。
经典的FP-Growth算法[6,7]主要通过FP树作为数据存储结构,将数据库事务集全部压缩处理,同时存储至FP-tree中,确保各个频繁项之间的关系不会被打破。在实际操作过程中,并不会形成候选集,所以需要两次扫描事务数据库,有效避免时间浪费。将频繁项集中出现的最小数据项设定为后缀,降低搜索时间。
由于传统的FP-Growth算法挖掘数据规模比较小,而在实际应用中的实验室服务器数据存储规模比较大,并且还在持续增加。如果超过单一架构以及分布环境可以处理的数据规模,则各个节点之间的通信能耗和时间会大幅度增加。在上述分析基础上,提出PL-FPGrowth(程序语言频繁模式增长,Procedural Language-Frequent Pattern Growth)算法。用于统计数据项的频数,如式(1)所示

(1)
式中,count-I(i,j)代表频数;lm,n代表节点上数据项出现的总数;i和j代表第i个和第j个节点。
4)在不同的节点上,通过频繁项列表,需要对本地数据集中的事务排序处理,构建对应的局部FP-tree。
5)将局部的频繁项集整合处理,假设频繁项集相同,则增加频数;反之,则删除支持度和置信度的频繁项集,通过整合形成全局最大频繁项集的集合。
2.2 基于改进FP-Growth算法的云服务器故障诊断
针对实验室服务器数据的特殊性,需要给出基于改进FP-Growth算法的云服务器故障诊断流程。分析实验室服务器的实际工作情况,为了确保故障诊断结果的准确性,在故障诊断前期,需要满足以下几方面的约束条件,如下所示:
1)确保数据结构属于非线性的;
2)确保数据的概率分布满足指数型分布;
3)确保向量的方差大小和变量之间的重要性呈正相关;
4)主元相互正交。
由于实验服务器是复杂多变的,具有复杂多变以及非线性等特点,主要涉及多个不同的实验设备,所以需要在事务数据库中分别添加关键数据,将其存放于关键项表中,将其设定为最终所挖掘的关联规则输出。
针对任何含有n个类别的分类问题而言,所以可以将其转换为两个类别的分类问题[8,9]。在频繁项头中主要包含两个不同的域,通过图1可知,FP-tree是利用两次扫描数据库得到的。
1)记录全部频繁项集的支持度和两种类别的相对支持度。
2)输入FP-tree,获取各个子路径上对应节点集合的支持度和置信度,详细的计算式如下
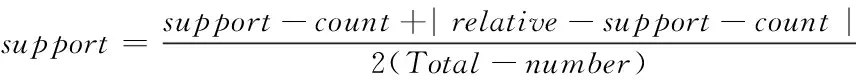
(2)

(3)
式中,support代表支持度;confidence代表置信度;count和relative分别代表不同的子路径。
3)二次扫描,同时构建相对支持树,将项头表按照从小到大的顺序排序处理,进而构建频繁模式基。
利用图1给出基于改进FP-Growth算法的云服务器故障诊断流程图。

图1 基于改进FP-Growth算法的云服务器故障诊断流程
由于经典的FP-Growth算法[10,11]在挖掘关联规则的过程中,和数据排列方式存在十分密切的关联。为了得到全局最大频繁项集,对局部事务排序仍然无法满足局部频繁项集,进而获取目标频繁项集。设定参与计算的节点数量为m,最小支持度为min-sup,则各个节点对应的局部支持度计数可以表示为式(4)所示
sup-local=min-sup ·qi
(4)
上式中,sup-local代表局部支持度计数;qi代表节点事务集总数。
在完成剪枝操作之后,会降低构建局部FP-tree和局部挖掘频繁项集的工作量。在删除不满足最小支持度计数的频繁项之后,在挖掘全局最大频繁项集时[12,13],会有效降低通信开销。
为了准确评估不同节点对应参考时间,可以采用式(5)计算
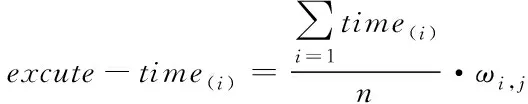
(5)
式中,excute-time(i)代表第i个节点对应的执行参考时间[14,15];time(i)代表节点i的运行时间;n代表测试样本数量;ωi,j代表不同节点的权重取值。
计算服务器故障比例如式(5)所示:

(6)
上式中,date-proportion代表节点数据的分配比例。
在以上分析的基础上,还需要设定参数阈值规则,进而提取实验室中不同服务器的故障向量变量的子集,以此为依据组建不同故障变量的条件FP-tree,将各个数据子集挖掘出的频繁项集求并集,得到包含全部故障诊断信息的频繁项集,最终达到服务器故障诊断的目的。
3 仿真研究
为了验证所提方法的有效性,采用文献[3]的基于多信息融合的故障诊断方法和文献[4]的基于运行时验证的边缘服务器DoS攻击检测方法作为实验对照组,将其与研究方法的测试结果对比,以突出提出方法的指标优势。
选取4核8G5M带宽的云服务器为实验测试对象,该服务器具备双IP,设置云服务器的故障发生在运行时间为5s~10s和15s~20s两个时间段,当服务器出现故障时,其数据通信量会发生较大幅度的变化。分别利用三种不同方法诊断该服务区的故障,所得结果如图2所示。

图2 不同方法下服务器故障输出结果
根据图2的实验结果可知,基于多信息融合的故障诊断方法和基于运行时验证的边缘服务器DoS攻击检测方法的服务器故障诊断存在较为明显的延时问题。研究方法能够精准的获取云服务器的故障,且在故障发生阶段,服务器的通信量下降,且幅度较大,符合实际情况。
基于上述实验,选取故障诊断耗时和诊断正确性作为测试指标。不同方法的云服务器故障诊断耗时测试结果如图3所示。
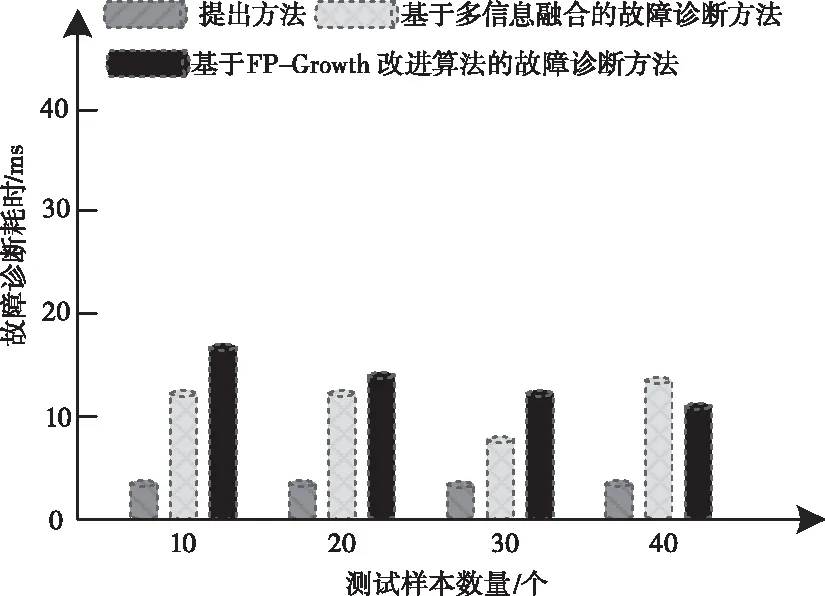
图3 不同方法的故障诊断耗时对比
分析图3中的实验数据可知,所提方法的云服务器故障诊断准确率明显优于文献方法,说明所提方法可以获取更加满意的故障诊断结果。
基于云服务器故障诊断的耗时指标测试结果,进一步分析三种不同方法的故障诊断性能结果,设置4个故障类型,分别为服务暂停、服务停止、进程异常、指令执行异常。利用基于多信息融合的故障诊断方法、基于运行时验证的边缘服务器DoS攻击检测方法以及研究方法对40个服务器样本完成故障诊断,具体结果如图4所示。
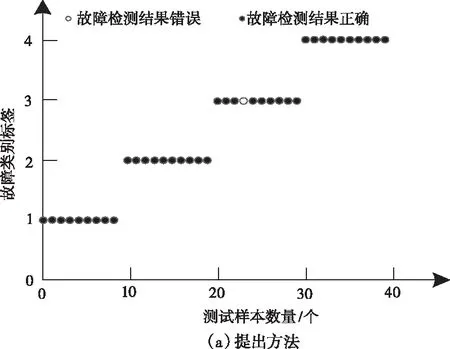

图4 不同方法的云服务器故障诊断结果
分析图4所得的实验结果可知,在对4个类别的云服务器故障进行诊断时,基于多信息融合的故障诊断方法和基于运行时验证的边缘服务器DoS攻击检测方法在每一个类别的服务器故障诊断中均出现了错误诊断结果,说明文献方法的故障诊断精度不够理想。研究方法在对40个服务器样本的不同类型故障诊断中,仅出现一次错误诊断。
为了更直观对比不同方法故障诊断结果的精度,对以上方法的准确率数值进行计算,公式如下所示
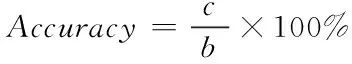
(7)
式中,c代表正确判断的故障类型数量;b代表实际故障数量。
根据图4的实验结果,计算不同方法的故障诊断精度,具体精度数据如图5所示。

图5 不同方法的故障诊断精度计算结果
根据图5的不同方法的故障诊断精度对比可以明显看出,对于不同类型的云服务器故障,研究方法的精度始终保持在90%~100%,基于多信息融合的故障诊断方法和基于运行时验证的边缘服务器DoS攻击检测方法的故障诊断精度波动范围在80%~90%,明显低于研究方法。该实验结果验证了所提方法具有更高的服务器故障诊断结果准确性,可以准确识别各个类型的故障,进一步证明了所提方法的优越性。
4 结束语
提出一种基于改进FP-Growth算法的云服务器故障诊断方法。经实验测试证明,所提方法可以准确诊断实验室中各个类型的服务器故障,为服务器故障的研究和应用提供了全新的方法,确保系统的稳定运行。
