基于联合调度优化模型的共享汽车分析
2022-01-25徐可超王涵笑霍思远谷晓彤
徐可超 王涵笑 霍思远 谷晓彤
摘 要:共享汽车行业曾在几年前广为繁荣,但由于其所具有的重模式、高成本、难以盈利等弊端,造成企业难以持续融资,行业难以持续繁荣的困境。如今,随着汽车车型更新换代日益迅速,加之疫情影响经济发展,消费者更倾向于轻便的用车模式,使得具有“分时租赁”特点的共享汽车获得很大发展机遇。本文综合利用Excel、Python软件,先以经纬度为横纵目标对附件数据进行离群值剔除与可视化展示,并将其在空间上划分成25个区域,从而更准确地研究其空间特征;其次,使用Matlab软件构建DBSCAN聚类算法模型,将不同区域共享汽车的实际密度情况以热力图形式在地图上可视展现,得出共享汽车分布主要集中在经度34.78377、纬度32.0556等区域附近,这些区域大多集中位于城市中心,人口密度相对高,共享汽车使用频率高的结论,同时编程得出不同型号车辆在整体区域信息的出现频率次数表,进行不同维度变化分析,得到共享汽车使用集中在早午晚高峰期,该时间段内人流量大,用车需求量高,汽车使用频率高的结论。
关键词:联合调度优化模型 共享汽车 DBSCAN聚类算法
Abstract:The shared car industry once prospered a few years ago, but due to its heavy model, high cost, and difficulty in profitability, it is difficult for companies to continue financing and the industry to continue to prosper. Nowadays, with the increasingly rapid replacement of car models and the impact of the epidemic on economic development, consumers are more inclined to use the light-weight car model, making shared cars with the characteristics of “time-sharing lease” a great opportunity for development. In this paper, using Excel and Python software comprehensively, outlier removal and visual display of the attachment data are first performed with the latitude and longitude as the horizontal and vertical targets, and the space is divided into 25 regions, so as to more accurately study its spatial characteristics: secondly. Using Matlab software to build the DBSCAN clustering algorithm model, the actual density of shared cars in different areas is visually displayed on the map in the form of heat maps. It is concluded that the distribution of shared cars is mainly concentrated in areas near longitude 34.78377 and latitude 32.0556. Most of these areas is concentrated in the center of the city, the population density is relatively high, and the frequency of shared cars is high. At the same time, it is programmed to draw the frequency table of the appearance frequency of different types of vehicles in the overall area, and analyze the changes in different dimensions. It is obtained that the use of shared cars is concentrated in the morning, afternoon and evening. During the peak period, the flow of people is large, the demand for cars is high, and the frequency of car use is high.
Key words:joint scheduling optimization model, car sharing, DBSCAN clustering algorithm
1 引言
共享汽車行业曾在2015年以来“百花齐放”,受到投资融资方青睐,但由于其具有重模式、高成本、难以盈利等特点,导致其难以持续繁荣,陆续有公司因为融资问题倒闭。在2019年,在共享汽车行业,中小企业不断出局,头部平台拉动了行业重新增长,增速甚至超过网约车和线上租车。
2 模型建立
2.1 数据信息可视化分析与数据处理
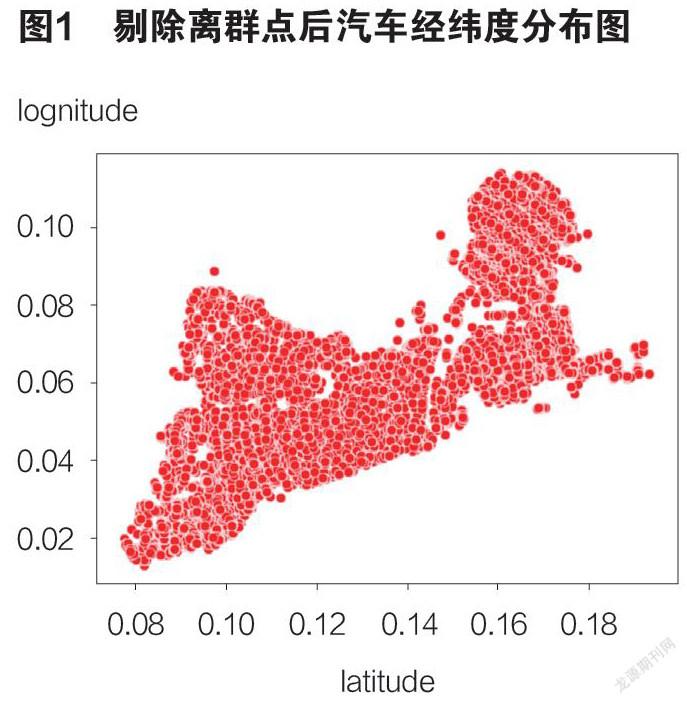
由于附件中为列表数据集信息,为方便观察特征,以经纬度为横纵坐标,利用Python软件对其进行可视化处理,共享汽车经纬度分布中部分区域出现离群点,为保证整体数据集分析的可靠性,减少模型因歧异值带来的误差,需要剔除离群点,剔除后的分布图像如图1所示。
针对分布图中整体较为密集的集中停车点,以经纬度为划分标准进行区域划分,形成一个5*5的正方形矩阵区域。为了解各区域中共享汽车数量关于时间的变化情况,了解其汽车流量的高峰期低谷期,将区域数据按时间标准转化为多列,以凌晨3;00-6;00、早上6;00-8;00、上午8;00-11;30、中午13;00-17;00、傍晚;17;00-19;00、晚上;19;00-23;00、深夜;23;00-3;00的標准划分时间段;同时,以是否为假期、周末、节假日来考虑个列,从而得到各区域在一天不同时间段内的停车数量变化。
2.2 DBSCAN空间密度聚类分析
首先定义以下概念,给定数据集D和参数ε和MinPts,有以下定义:
(1)ε-邻域:对xj∈D,其ε-邻域包含数据集D中和xj距离不大于ε的样本,即;
Nε(xj)={xj∈D∣dist(xj,xj)≤ε}
(2)核心对象:若xj的ε-邻域至少包含MinPts各样本,即∣Nε(xj)∣≥MinPts,则xj是一个核心对象;
(3)密度直达:若xj位于xi的ε-邻域内,且xi是核心对象,则称xj由xi密度直达;
(4)密度可达:对xi与xj,若存在样本序列P1,P2,…,Pn,其中P1=xi,Pn=xj,且Pi+1,由Pi密度直达,则称xj由xi密度可达;
(5)密度相连:对xi与xj,若存在xk使得xi与xj均由xk密度可达,则称xj由xi密度相连。
基于以上定义,DBSCAN聚类算法流程步骤为:
●输入数据集D={x1,x2,…,xm}及参数ε和MinPts,从数据集中随机抽取一个未被访问的对象,在其-邻域内满足阈值要求的称为核心对象;
●遍历全部数据集,找到所有从对象的密度可达对象,形成新的簇;
●利用密度相连,产生最终簇结果;
●重复步骤2与3,直到访问数据集中的所有对象为止。
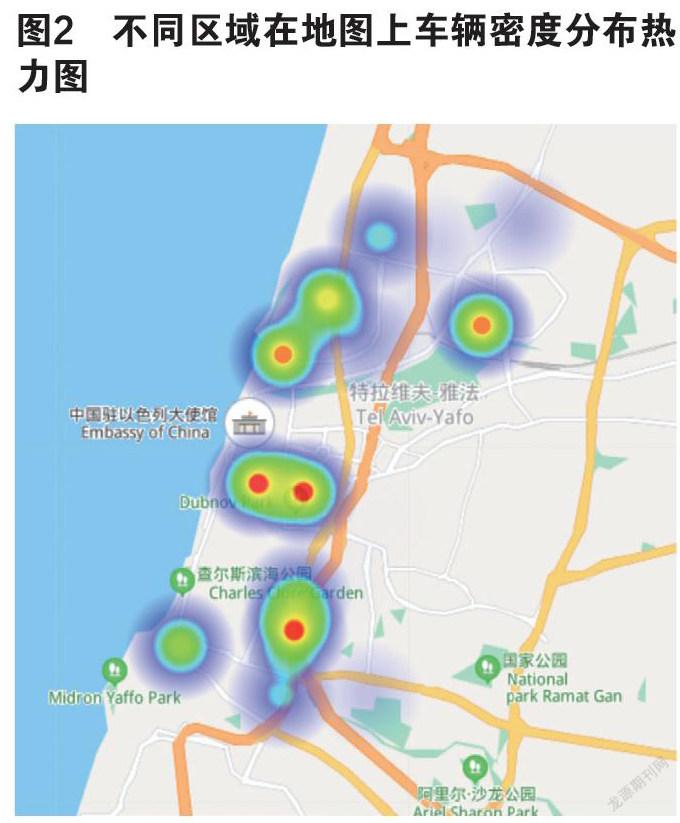
因本题聚类密度均匀且分布较为集中,将各区域停车车辆数量等相关信息作为数据集,以=0.05km和MinPts=261为参数进行DBSCAN密度聚类。[1]使用Matlab软件编程得到不同区域的在地图上的车辆密度分布热力图如图2。
3 模型求解
由聚类处理后数据可以得出:该城市共享汽车分布主要集中在城市中心,其人口密度相对较高的维度。对各天区域车辆数气泡进行分析,并结合上文中各区域一天不同时间段内的汽车数量折线图,可以得出一天中不同区域不同时间的车辆数目变化情况,进而得到按时间段划分的车辆时间变化趋势,其各区域一天中停车数目分配大致相同,在早午晚高峰期内中心区域车流量多,汽车数量多,在边缘郊区汽车数量少,而在其他时间段内汽车数量大致稳定。
可以综合得出,按天车流量在每月中旬呈上升趋势,到达峰值后持续下降,上下旬均会出现一个较为平缓的增长趋势,并呈现先增后降的趋势;同时,用车数量在年末到达高峰期,这一期间人们用车需求增长迅速,共享汽车使用数量大幅增长;在18、19年内,12月/第四季度车辆数目均要多于1月/第一季度车辆数。
在时间上集中于早午晚高峰期,在这段时间内人流量大,用车需求量高,汽车使用频率高;在共享汽车型号上,最受消费者欢迎的汽车为234号汽车,其次为199号、235号等,共享汽车使用次数在数据集中均高于2000次,受欢迎的汽车型号均高于3000次,使用频繁。
4 总结
停车点是基于经纬度定位,且数据庞大,密度集中,基于密度的聚类算法以数据集在空间分布上的稠密程度为依据进行聚类,能处理任意形状和大小的簇,方便处理多而繁琐的停车点数据[2]。利用DBSCAN聚类算法时,可在聚类的同时发现样本数据异常点,方便处理大量的影响数据有效性的异常值。[3]采用特征性分析,引入锡尔系数作为判断的依据,有利于从多个角度为调度的方案提供依据。
密度聚类算法对于输入参数和MinPts敏感,确定参数较为困难,带有一定的估算性质。特征性分析对于次要因素包含度不高,推广使用具有一定的局限性,仍需要进一步优化。而DBSCAN空间密度聚类模型本身自带的参数带有一定的主观性,可以利用遗传算法对模型进行进一步优化改进。本题所建立的模型具有较好的理论基础,得到的联合优化模型可以作为共享汽车企业的参考相关依据。联合优化模型为多模型综合使用,适应性广,其不仅仅适用于共享汽车,也能推广到共享单车等其他行业领域。
参考文献:
[1]马小宾,侯国林,李莉,杨燕.基于DBSCAN算法的民宿集群识别、分布格局及影响因素——以南京市为例[J].人文地理,2021,36(01):84-93.
[2]王倩倩,孟繁宇,曾益萍,张少标,吴国华,杨丽丽.基于DBSCAN聚类的城市区域火灾风险计算方法——以深圳市盐田区为例[J].中国安全生产科学技术,2021,17(02):177-182.
[3]Ester M,Kriegel H P,Sander J,et al.A density-based algorithm for discovering clusters in large spatial databases with noise[C]. Portland,Oregon,USA:The AAAI Press,1996:226-231.
作者简介
徐可超:(2002.01—),男,汉族,山东滨州人,在读本科。研究方向:智能开采。
