基于聚类分析的磨煤机断煤过渡状态识别
2021-11-25问姝雅卓旭升吴尔夫
问姝雅,卓旭升,吴尔夫
(1.武汉工程大学 电气信息学院,武汉430205;2.国家能源集团汉川发电有限公司,汉川431614)
由于原煤中常含有石块、铁块等杂质以及恶劣的工作环境,导致磨煤机在运行期间易发生故障[1]。磨煤机断煤是磨煤机常发的故障之一,其会增大磨辊的磨损,影响设备使用寿命,不利于机组的经济运行。
磨煤机故障的发生不是一蹴而就的,从正常运行状态到故障发生的中间往往要经历一段“故障累积”的过渡过程,即过渡状态。准确判断出磨煤机断煤故障过渡状态,对保证机组安全经济地运行具有重要意义。
目前对于磨煤机正常运行状态到故障状态中过渡状态的识别研究较少。文献[2]利用小波分析和D-S 证据理论辨识出磨煤机的临界堵塞状态。但是在构造某一证据对某一目标模式的折扣加权系数时,需要由海量的历史数据统计得出,在数据样本不足的情况下,得出的结果可能会略有偏差,从而影响到诊断结果。
聚类分析特别适用于无法获得故障数据样本或故障数据样本获取相对困难情况下的故障模式识别问题[3]。此类算法实现简单,运行速度快,能够有效辨识出磨煤机断煤故障的过渡状态,在生产过程中可有效提高安全性和生产效率。
模糊C 均值(fuzzy c-means,FCM)聚类算法是聚类分析的一种。在模糊C 均值聚类的迭代过程中,被分类的每一个样本被认为以不同的隶属度属于某一类[4]。本文基于模糊C 均值聚类分析方法,开展对磨煤机断煤故障过渡状态识别方式的探索研究,旨在为磨煤机断煤故障诊断提供技术支撑。
1 磨煤机故障特性分析
1.1 磨煤机工作流程
制粉系统可分为中间储仓式和直吹式两种。在直吹式制粉系统中,给煤机以一定的速率将原煤斗中的煤供给磨煤机,原煤从中央的落煤管进入落在磨环上,在离心力的作用下,原煤运动至碾磨滚道上,在磨环上形成一层煤床,通过磨辊进行碾磨,一次风经一次风管向磨煤机提供适量温度的热风,以干燥研磨过程中的燃煤,并将磨制好的煤粉带出磨煤机,经粗细粉分离器分离后,合格的煤粉被送至煤粉仓或炉膛中,未合格的粗粉则被分离出来返回磨环重磨,直至合格为止。
1.2 磨煤机断煤故障
落煤管、给煤机堵塞,给煤机故障断煤,一次风管堵塞,磨入口一次风量小是磨煤机断煤的主要原因[5]。磨煤机断煤状态下,内存煤量小,磨电流降低,磨碗压差降低,此时给煤量可能很高,但实际进煤不多,而一次风流量接受给煤量的信号而变大,内存煤量无法消耗一次风中过量的热,磨出口温度升高,出口风混合物压力降低。
2 模糊C 均值算法
FCM 算法在迭代寻优的过程中,不断更新各类的中心及隶属度矩阵各元素的值,直到逼近下列准则函数的最小值:
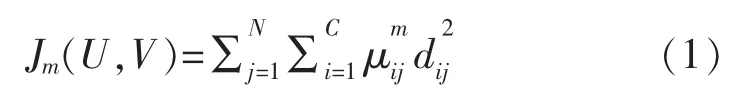
式中:模糊性加权指数m(m>1)是用来控制聚类结果模糊程度的常数,通常取A(xj-vi)为样本xj到ωi类中心向量的距离平方,A为正定对称矩阵,通常A 取单位矩阵,此时dij为欧氏距离,即。
FCM 算法步骤如下:
步骤1已知待分类的样本数据集X={x1,x2,…,xN},其中xm=[x1,x2,…,xd],为d 维特征向量,m=1,2,…,N;确定分类数C(2≤C≤N)、模糊性加权指数m、矩阵A 和一个适当小的迭代停止阈值ε;
步骤2设置初始模糊分类矩阵U(s),令迭代次数s=0;
步骤3按式(2)计算U(s)时的聚类中心vi(s):
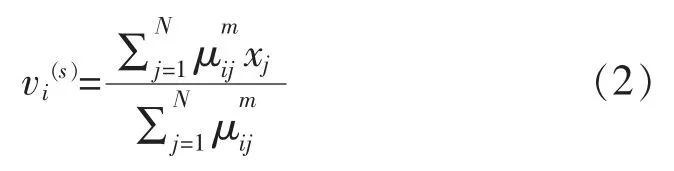
式中:i=1,2,…,C。
步骤4将U(s)更新为U(s+1);
(1)计算Ij和Ij′,其中j=1,2,…,N。
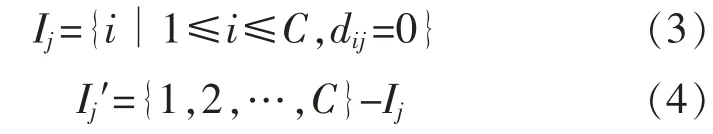
(2)计算样本xj的新隶属度。若Ij=φ,则:

若Ij≠φ,则令μij=0,∀i∈Ij′,并使Σi∈Ijμij=1。
步骤5判断迭代是否结束。若‖U(s)-U(s+1)‖<ε,则停止;否则,s=s+1,返回至步骤3。
3 诊断方案
在数据分析前先根据磨煤机故障机理对磨煤机的运行参数进行筛选,然后采集各特征参数在正常运行阶段、过渡阶段、故障阶段的数据,归一化后进行模糊C 均值聚类分析,得到故障状态识别模型,如图1 所示。
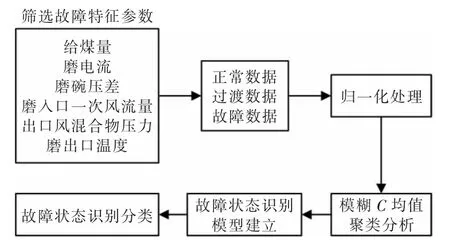
图1 诊断方案流程Fig.1 Flow chart of diagnosis plan
3.1 筛选故障特征参数
在实际运行过程中,为了监测磨煤机的运行状态,会在各部分安置传感器采集数据,若将这些参数都作为聚类分析的输入参数则不仅会严重影响计算速度,还会影响数据分析结果。所以在进行统计分析前,应先基于故障机理分析或者采用粗糙集理论[6]等方法对这些参数进行属性约简,筛选出对磨煤机断煤故障敏感的特征参数,本文采用的筛选方法是磨煤机断煤故障机理分析。
根据对磨煤机断煤故障机理的分析,选择给煤量、磨煤机电流、磨碗压差、磨入口一次风流量、出口风混合物压力、磨煤机出口温度这6 个特征参数作为聚类分析的输入参数。
3.2 数据归一化
为消除各特征参数之间的量纲影响,避免聚类分析时特性指标间的排斥现象[7],也为了在后续聚类分析中计算能够更快速便捷,将原始数据集按式(7)归一化至[0,1]。

式中:x′为归一化后的数据;x 为原始数据;xmin为原始数据中的最小值;xmax为原始数据中的最大值。
3.3 FCM 聚类分析
设定C=3,对其进行模糊C 均值聚类计算分析,得到各个样本对于各个类的隶属度,最后根据最大隶属原则,将各样本归属到对应类别,即对哪一个类的隶属度最大,就将其归到哪一类。由此可将数据硬分类为3 类,当各个聚类无重叠或重叠部分较少时则认为建立了良好的故障状态识别模型。
4 实例分析
4.1 模型训练
现有汉川电厂5 号机组C 磨煤机从正常运行到磨煤机发生断煤故障并关机的数据共287 组,时间为2020年7月7日9 时57 分18 秒至10 时21分08 秒,采样间隔为5 s。其中正常状态数据224组,过渡状态数据30 组,故障状态数据33 组。
将总样本按照训练样本: 测试样本≈3∶1 的标准进行划分,这样既能保证有足够的数据用于模型训练,又能客观验证模型的诊断效果[8]。现从总样本中随机抽取72 组数据作为测试样本,其中正常状态数据58 组,过渡状态数据6 组,断煤故障数据8组,其余数据作为训练样本,如表1 所示。

表1 数据样本划分Tab.1 Data sample division
根据故障机理分析,选取给煤量,磨煤机电流、磨碗压差、磨入口一次风流量、出口风混合物压力、磨煤机出口温度作为输入参数,设定C=3,归一化后经模糊C 均值聚类后分出了3 个类别,即正常类、过渡类和故障类。
各类别类心坐标如表2 所示,第一类为正常类,类心坐标为A(0.5607,0.4767,0.9029,0.1308,0.7393,0.0241);第二类为过渡类,类心坐标为B(0.6364,0.4189,0.4653,0.2753,0.4660,0.2390);第三类为故障类,类心坐标为C(0.2452,0.2482,0.1792,0.7538,0.2015,0.9223)。
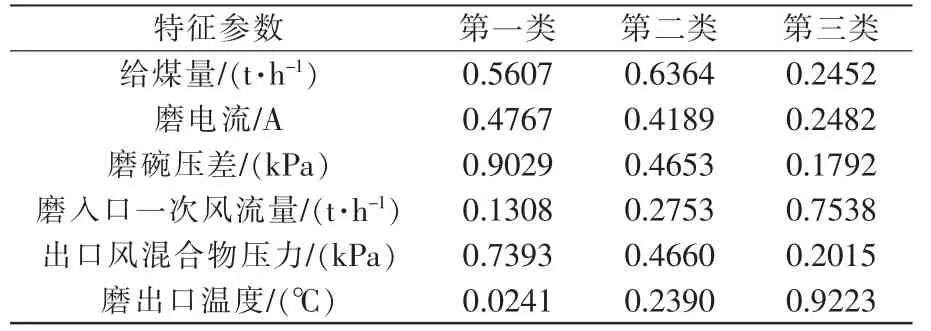
表2 各类心坐标Tab.2 Various types of center coordinates
如图2 所示,训练样本中166 组正常数据全部划分到了正常类中,24 组过渡数据全部划分到了过渡类中,25 组故障数据全部分到了故障类中。结果表明,采用模糊C 均值聚类可以将磨煤机正常、断煤过渡状态和断煤故障完全区分开来。
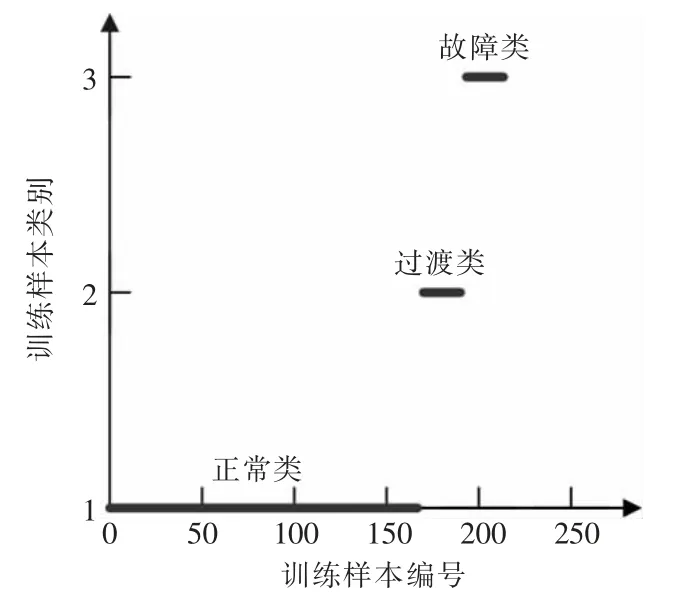
图2 训练样本聚类结果Fig.2 Clustering results of training samples
4.2 模型验证
将72 组测试样本并入训练样本中进行归一化处理,按照式(8)计算归一化后的特征参量坐标到各类心坐标的欧氏距离。
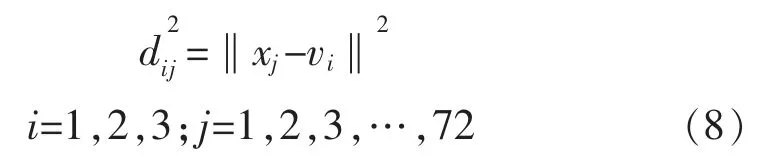
式中:测试样本xj=[x1,x2,x3,x4,x5,x6]为六维特征参量;v1,v2,v3分别为类心坐标A,B,C。
根据择近原则,距离哪类聚类中心近,验证组数据就自动划分到哪个聚类中。测试样本距各类心距离如表3 所示。

表3 测试样本距各类心距离Tab.3 Distance between test samples and various types of centers
统计结果如表4 所示,测试数据一共72 组,其中58 组正常数据,6 组过渡数据,8 组故障数据。58组正常数据全部划分到正常类;6 组过渡数据中,2组被划分到正常类,4 组被划分到过渡类;8 组故障数据全部被划分到断煤故障类。准确率97.2%。

表4 测试样本验证结果Tab.4 Verification results of test samples
5 结语
模糊C 均值作为无监督的学习方法,对训练样本依赖性较低,运行速度快,比较适用于工程应用,通过该方法可快速又准确地识别出磨煤机的故障状态的模式识别,准确率可达97.2%,对于故障的发生和预防具有重要意义。
