三方多策略式博弈系统的长期演化稳定均衡特性研究
2021-11-20程乐峰王晓刚
程乐峰 ,杨 汝 ,王晓刚 ,余 涛
(1.广州大学机械与电气工程学院,广东广州 510006;2.华南理工大学电力学院,广东广州 510641)
1 引言
面对复杂的多主体行为决策问题,博弈论(game theory)逐渐成为非常实用的数学工具[1–2].作为博弈论的新兴分支,演化博弈论(evolutionary game theory,EGT)[3]立足于“有限理性(bounded rationality)”和“有限信息(limited information)”假设,通过个体间模仿、学习和交流等动态交互决策过程能够很好描绘群体行为的变化趋势并准确预测个体的群体行为,因而在经济[4]和管理[5]等领域得到了迅速应用,并在工程领域[6–8]得到了初步发展.
目前,EGT在众多领域内的理论与应用研究多偏向于两群体两策略行为决策问题,例如文献[9]探讨了供应商与零售商之间的演化博弈模型,文献[10]则分析了政府补贴机制下的两级供应链绿色投资演化博弈.而在理论研究方面,EGT则取得了长足的发展,尤其是在合作演化博弈、随机演化博弈及演化博弈规则机制研究方面.在合作演化博弈方面,文献[11]探索了时间尺度与选择倾向性协同作用下的演化博弈模型,表明个体的非理性行为能够促进合作涌现,文献[12–15]针对复杂网络中的合作涌现问题进行了理论分析与动态仿真,文献[16]则对共演化博弈中的一种反馈机制进行了系统性研究,文献[17]对复杂网络上的两类典型演化博弈(囚徒困境博弈和公共品博弈)中的合作策略的演化及策略与其他属性的共同演化问题进行了深入研究.在随机演化博弈方面,Kaniovski和Young[18]探索了随机演化博弈中的学习机制,文献[19]则提出了基于随机演化博弈模型的网络防御策略选取方法,文献[20]系统性探讨了随机演化博弈动力学并对其应用进行了研究,文献[21]则研究了随机演化博弈在发电市场中的应用,文献[22]基于拟生灭过程对一类2×2的随机演化博弈模型进行了深入研究,Zhou和Qian[23]对随机演化博弈动力学中的固定原理、瞬态场景和扩散困境进行了深入理论分析,文献[24]研究了随机演化博弈动力学中的演化稳定性和准平稳策略,文献[25]则提出了一种双矩阵博弈的随机演化动力学方法.在演化博弈规则及机制研究方面,文献[26]研究了EGT 中的若干合作演化机制,包括随机性与多样性机制、共演化中的断边与重连机制、结构群体间接互惠机制、部分最佳响应机制和结构种群中的迁移机制,文献[27]则对基于策略更新机制的合作演化问题进行了深入研究,文献[28]则研究了一种行为识别声誉更新机制下的演化博弈特征.总的来说,近年来,EGT在理论研究方面取得了较为颇丰的成果.
在理论研究基础上,近年来,演化博弈在应用方面也相继在不同领域取得了较丰富的研究进展.其中,相关学者针对三方多策略式演化博弈问题的研究,初步取得了一些成果.例如,文献[29]使用主从博弈对智能电网中分布式能源资源的三方能源管理模式进行了深入研究;文献[30]运用EGT对外卖废品回收产业链中“政府–顾客–企业”三个利益相关者群体的协同进化进行了模拟研究;文献[31–32]将EGT用于高校产学研三方的协同创新路径选择和演化博弈模拟;文献[33]提出了一种三方动态博弈模型用于研究我国能源市场改革对天然气发电的促进作用;文献[34]搭建了一个考虑电能质量的“国家电网–发电公司–市场买卖人员”三方电价博弈模型.此外,近年来通过搭建复杂的三方博弈网络模型,文献[35]研究了基于社区结构的“用户–助手–服务器”三方主从博弈隐私保护问题;文献[36]对基于“政府–公交企业–乘客”三方博弈的城市公交定价调整方案进行了评价分析,为研究城市交通价格调整方案的可行性提供了一种研究方案;文献[37]从一种利益攸关方博弈视角对“地方政府–承包商–回收厂”三方参与的推进拆建垃圾回收市场的可持续发展问题进行了深入研究;类似地,文献[38]建立了“政府机构–废物回收者–废物生产者”三方多主体演化博弈树;文献[39]通过搭建三方演化博弈的系统动力学模型,深入研究了可再生能源组合标准对电力零售市场的影响;文献[40]对电商平台合作监管中“欺骗熟人”行为进行了“消费者–电商市场–政府”三方演化博弈分析,其结果可以指导参与者更好地对电子商务市场进行决策;文献[41]则搭建了一个“生产者–回收者–政府”三方演化博弈模型用于研究推动生产者延伸责任制在中国的实施机制及其影响因素.
总的来说,上述研究多注重于均衡点稳定性的分析,而忽视了基于复制者动态(replicator dynamics,RD,也可翻译为“复制动力学”或“复制子动态”,本文统一采用“复制者动态”这一说法)方程建立的雅克比矩阵的行列式和迹(trace)表达式中各参数的物理含义或经济含义,也较少考虑这些参数的变化对系统长期演化稳定均衡状态的影响机制以及博弈方之间决策行为的动态交互影响,也并未对其中的长期演化规律做详细深入的总结分析与动态仿真验证.此外,对于这些领域复杂系统的多群体非对称演化博弈行为决策问题的研究也鲜有涉及.总的来说,通过上述综述,三方多策略式演化博弈模型在现实社会中越来越常见,吸引了众多学者对这一场景进行深入研究,目前已成为EGT领域中的一个研究热点.
基于此,本文重点关注一类三方多策略式演化博弈类型,尤其是三方两策略式演化博弈(three-party two-strategy evolutionary game,3P2SEG)系统.目前,基于3P2SEG系统的一些应用研究成果包括:政产学研协同创新机制三方演化博弈研究[42]、食品质量安全监管三方演化博弈研究[43]、电力市场售电商–电网公司–用户三方非对称演化博弈研究[44]、旅游市场中政府–旅行社–消费者三方演化博弈行为研究[45]、基于政府管理部门–运营企业–出行者三方演化博弈的汽车共享产业推广模型研究[46]、基于企业–政府–公众三方演化博弈的雾霾协同治理研究[47]、基于寻租者–代理人–人民三方演化博弈的腐败问题研究[48]、基于平台–所有者–分享者三方演化博弈并考虑平台网络外部性的分享经济研究[49]、基于网民–网络媒体–政府三方演化博弈的网络舆情问题研究[50]、风–火–网三方参与新能源交易的非对称演化博弈问题研究[51]等.上述研究极大丰富了三方多策略演化博弈的应用领域,但其中大多数研究只是对系统稳定性进行了简单分析,并未全面总结影响系统动态稳定性的各种因素,也未对这些因素的影响做理论分析与动态仿真验证.基于此,本文关注这样一类一般情形下的三方多策略对称与非对称演化博弈模型,尝试通过理论分析与动态仿真总结和验证其行为决策过程中的长期演化稳定均衡(evolutionarily stable equilibrium,ESE)特性,以期为相关领域内非完全理性群体参与的三方多策略式演化博弈决策问题提供一些思路与理论参考.
本文的创新点在于:通过理论分析与动态仿真系统性地总结和验证了通用三方多策略演化博弈的长期均衡特性,包括三方两策略对称演化博弈类型(three-party two-strategy symmetric evolutionary game,3P2S–SEG)、三方两策略非对称演化博弈类型(threeparty two-strategy asymmetric evolutionary game,3P 2S–AEG)、以及更复杂的三方三策略非对称演化博弈类型(three-party three-strategy asymmetric evolutionary game,3P3S–AEG).在上述研究过程中,本文详细定义了各类演化博弈模型的相对净支付(relative net payoff,RNP)参数,因而根据RNP参数总结分析和仿真了各类演化博弈模型完整行为决策特性包含的所有博弈场景及这些场景下系统所有的演化状态,并对一般情形下的三方n-策略(n >1)策略非对称演化博弈(three-partyn-strategy asymmetric evolutionary game,3PnS–AEG)的建模思路和收敛迭代计算方法进行了详细阐述.最后,以供给侧发电市场中新能源发电企业群体、传统能源发电企业群体和电网企业群体参与的发电量上网竞价博弈为例,对本文在研究过程中所提出的模型和方法进行了有效的仿真验证.总的来说,本文模型、方法和所得结论具有一定普适性和实用性,旨在丰富演化博弈论的理论与应用研究.
本文结构安排如下:第2章介绍EGT中几个核心概念作为预备知识;第3章通过理论和仿真分析总结和验证3P2S–SEG,3P2S–AEG,3P3S–AEG 等通用三方多策略演化博弈的长期演化均衡特性,阐述了一般情形下3PnS–AEG 的建模思路和收敛迭代方法,并对各类多方多策略式演化博弈系统的长期演化均衡规律进行了详细总结.第4章给出一个具体的三方多策略演化博弈实例,用于验证本文研究模型和方法的有效性和实用性.第5章为结论.
2 预备知识
2.1 演化博弈基本架构
一个典型的演化博弈(用G表示)的基本架构包括种群参与者集合、种群策略集合和种群支付矩阵[7–8],如下所示:

其中:N为种群参与者集合,如G含n个种群,则N={1,2,···,i,···,n},i ∈N;Φ为种群策略集合,Φ={S1,S2,···,Si,···,Sn},Si为种i的策略集;U为种群支付集合,U={U1,U2,···,Ui,···,Un},Ui为种群i的支付集.基于此,可从多个方面比较演化博弈论与经典博弈论的区别[8],如表1所示.

表1 演化博弈论与经典博弈论之间的比较Table 1 Comparison between EGT and classical game theory
2.2 对称与非对称演化博弈
基于式(1),对于通用的三方n-策略演化博弈(three-partyn-strategy evolutionary game,3PnSEG),当其支付参数对称时,该博弈为对称演化博弈,此时该博弈中所有参与者都知道彼此的偏好[52];反之,若支付参数不对称,则为非对称演化博弈,此时各种群对彼此信息的掌握程度将不对称.
2.3 演化稳定策略与演化稳定均衡
演化稳定策略(evolutionarily stable strategy,ESS)用于表征演化博弈系统在某一均衡点(即策略选择)下的稳定状态[53].当系统的某个纯策略为ESS 时,可抵御任意含突变策略小群体的入侵,即拥有ESS的群体在已定义的策略集Φ中具有更高的稳定性.假设系统的两个纯策略s1,s2∈Φ,且s1s2,若总存在κ ∈(0,1)使得下式成立,则s1为系统的ESS.
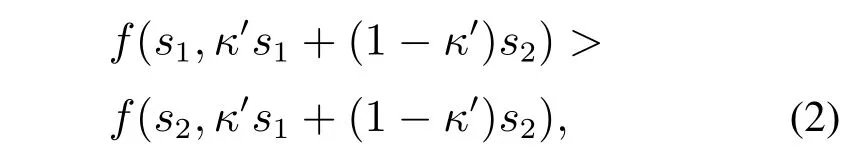
其中∀κ′ ∈(0,κ).f(·)表示为式(2)中所示的系统在某一策略选择情形下的适应度函数,其刻画了策略与适应度的映射关系,类似于经典博弈论中的支付函数,而其计算结果表示具体的适应度值(可简单理解为繁殖率).在下文针对具体演化博弈类型的分析过程中,将这一适应度值表示为系统在某一策略选择情形下的支付,从而形成系统的支付分布参数矩阵.至于f(·)函数的具体表达形式则需要根据实际演化博弈场景中给定的支付函数来确定.进一步,系统在纯策略处取得的ESS称为系统的演化稳定均衡(ESE).非对称演化博弈只能在纯策略处取得ESE.
2.4 复制者动态模型
复制者动态模型(即RD模型)是演化博弈理论中的一种核心动力学机制,可很好地用于描述有限理性个体的群体行为的变化趋势[53–54].若种群i在每轮次重复演化博弈中对策略集Si中某策略s的选择概率或个体比例为xi(t),相应的期望支付为fi(s;x;t),且此时种群i的平均期望支付为fave(s;t),则选择策略s的RD模型为
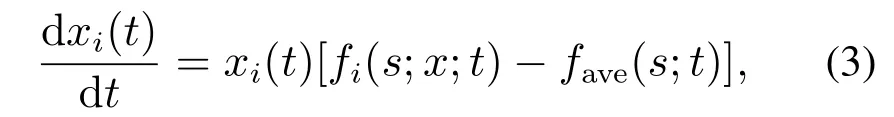
由式(3)可见种群内选择某策略的概率(或个体比例)的微分正比于该概率值,以及选择该策略的期望支付与种群此时的平均期望支付之间的差值.因此,当等式右边等于0时,意味着策略s在种群中的比例维持不变,将成为系统长期演化后自发形成的ESS.需要说明的是,式(3)针对的是某一纯策略si在每次博弈过程中被选择的概率(或个体比例)的变化规博弈过程中被选择的概率或个体比例的变化规律,即xi(t)的演化规律.式(3)表明若个体选择纯策略si的支付(或收益)少于群体平均支付(或收益),则选择该纯策略si的个体数(或概率)的增长率为负;反之则为正.若二者相等,则表明选择该纯策略si的个体比例(或概率)保持不变,维持在稳定水平,并在系统中导致一种动态平衡.在该平衡状态中,任何个体不会愿意单方面改变自身选择的策略.事实上,若对于一个混合策略,根据研究表明[3–4]:其不可能成为一个非对称多群体演化博弈系统的ESS,即系统在混合策略处不可能自发地达到一种长期的演化稳定均衡状态.
2.5 演化稳定性判据
判定系统在某策略处的渐进稳定性(演化稳定性)可利用李雅普诺夫稳定性判据[55–56].当式(3)所示的系统RD模型(即系统的复制者动态方程组)所对应的雅克比矩阵(通常为一个方阵)在系统的某一内部均衡点处的所有特征值的实部均为负数时,则系统在该均衡点处达到渐进稳定状态,并取得ESS.反之,若所有特征值实部中至少有一个为零或正数,则系统在该均衡点处处于演化不稳定均衡状态.还存在一种特殊情况:若所有特征值的实部有正有负,则该均衡点称为系统的鞍点,此时系统在该点处于临界均衡状态,仍称为演化不稳定的均衡状态.
3 三方多策略式演化博弈系统的长期演化均衡特性
基于第2章,在文献[55]基础上,本章通过理论分析与仿真验证详细讨论一般三方多策略式演化博弈模型的长期均衡特性,包括三方两策略对称演化博弈(3P2S–SEG)、三方两策略非对称演化博弈(3P2S–SEG)、三方三策略非对称演化博弈(3P3S–AEG)和通用三方n-策略非对称演化博弈(3PnS–AEG).首先建立模型并定义其完整的RNP参数,然后进行长期ESE理论分析与动态仿真验证,最后进行总结.
3.1 三方两策略式对称演化博弈(3P2S–SEG)
3.1.1 模型建立
对于通用的三群体两策略演化博弈(3P2SEG),其中的三方分别用群体A,B和C表示.这3个群体的策略集都包含一对互斥的纯策略,即群体A,B和C的策略集分别假设为
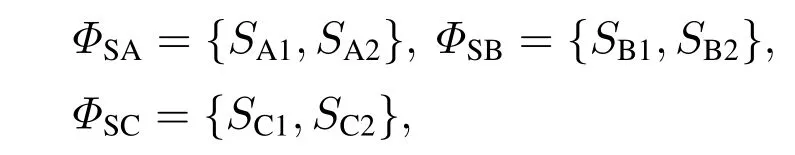
其中:SA1与SA2,SB1与SB2,SC1与SC2分别表示一对互为相反的策略(即一对互斥策略,且是一对互斥的纯策略).例如,SA1表示群体A中的个体做出某一决策时,则SA2表示群体A中的个体做出这一决策的相反决定(即对应的反策略,本文中均指纯策略).由群体A,B和C构成的演化博弈系统在每轮次重复博弈中,互为相反的策略对SA1与SA2,SB1与SB2,SC1与SC2分别在群体A,B和C中被选择的概率(或个体比例)为x和1-x,y和1-y,z和1-z,其中x,y,z ∈[0,1].因此,该类通用的三方两策略式演化博弈系统的决策空间可定义为Ψ=[0,1]×[0,1]×[0,1],其表示xyz坐标系中单位立方体空间内的某一区域,该区域内任意一点的各个坐标值均为非负数,即Ψ={(x,y,z)|x ∈[0,1],y ∈[0,1],z ∈[0,1]}.进一步可知,群体A,B 和C在上述情形下将总共形成8个纯策略组合(本文只讨论通用演化博弈模型在纯策略处的长期均衡特性,因为模型只有在纯策略处才能取得严格精炼的NE,而在混合策略处一般都是不稳定或临界稳定的[3–4],可不予讨论),即

假设第i个策略对Φi对应的支付组合为(ai,bi,ci),其中:i=1,2,···,8,ai,bi,ci为本文定义的可全文通用的支付(或收益)分布参数.因此,该类通用3P2SEG系统的支付(或收益)矩阵(payoff matrix)可表示为

对于式(4),根据3P2S–SEG 中的博弈对称性要求,其支付参数需同时满足
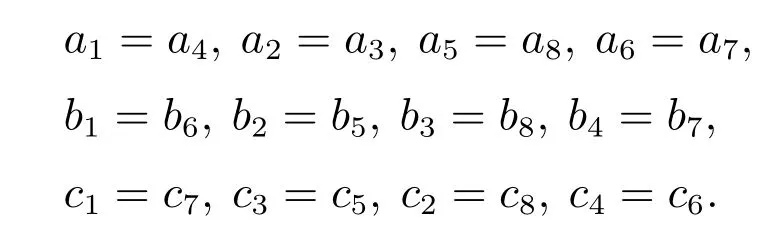
基于此,不妨假设


此处的a,b,c,d,e,f,g,h,k,l,p和q为本文定义的可全文通用的支付分布参数.因此,该3P2S–SEG 系统的支付矩阵可转变为如式(5)所示的形式.
3.1.2 系统RNP参数定义
对于通用根据3P2S–SEG的支付矩阵,本文对其完整的RNP参数进行定义,共6组,如表2所示.以“RNP参数1”为例,即(a-c),其定义为当群体B选择策略SB1、群体C始终选择策略SC1时,群体A选择策略SA1时的相对净支付(其物理含义或实际意义为:此时群体A中个体选择策略SA1时获得的期望支付与其选择策略集中另一策略SA2时获得的期望支付之间的差值,即(a-c)),或当群体B选择策略SB2、群体C始终选择策略SC2时,群体A选择策略SA1时的相对净支付(其含义同上,即群体A中个体在此情形下选择策略SA1时获得的期望支付与其选择策略集中另一策略SA2时获得的期望支付之间的差值,仍等于(a-c)).如表2所示,其他组RNP参数的含义也可参照该表类似得到,此处不再赘述.当然,若将这6组RNP参数分别取它们的相反数,则可得到另外6组RNP参数,其含义分别表示群体A,B和C选择其策略集中第2个纯策略时的相对净支付.
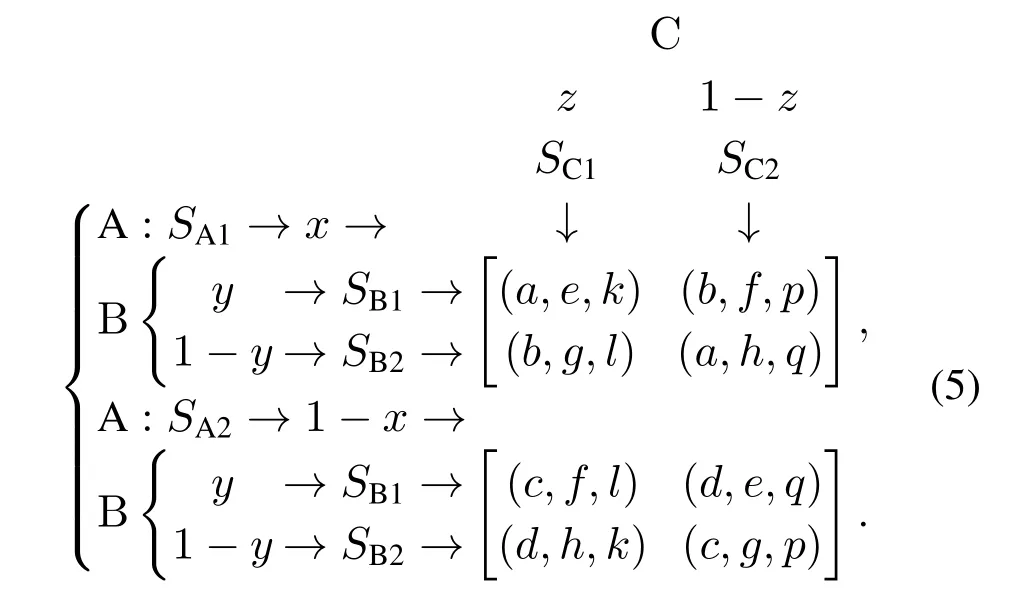

表2 一般情形下的通用3P2S–SEG 系统中定义的6组相对净支付参数Table 2 Six RNP parameters defined in the general 3P2S–SEG system
3.1.3 长期均衡理论分析与动态仿真验证
基于第2 章,并根据前文式(5)所示的系统支付(或收益)矩阵,该通用3P2S–SEG 系统的RD 模型(多元偏微分方程组)可表示为
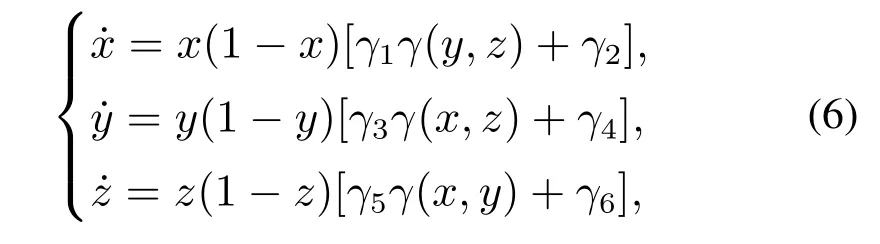
其中:

相应地,该系统RD 方程对应的雅克比矩阵J3P2S–SEG为
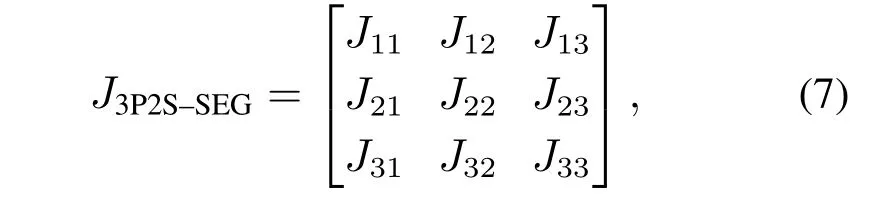
其中:

为更加直观观察系统长期均衡自发形成过程中各策略的演化动态性与稳定性,不妨对系统RD 模型进行动态仿真,取(a,b,c,d,e,f,g,h,k,l,p,q)=(8,6,3,9,7,4,3,9,9,7,5,12),并分别以1/4,1/5,1/6,1/7,1/8和1/9为间隔,在该演化博弈系统的决策空间Ψ=[0,1]×[0,1]×[0,1]内对x,y和z的初始值从0至1进行取值,即分别进行125,216,343,512,729和1000 轮次的动态仿真验证,并依次记为Case 1至Case 6,并分别如图1(a)至(f)所示.各情形下分别展示了(x,y),(y,z)和(x,y,z)的相轨迹图,图中红色实心圆点为系统长期演化后自发形成的ESS,该表示方式在全文通用.


图1 通用3P2S–SEG系统在(a,b,c,d,e,f,g,h,k,l,p,q)=(8,6,3,9,7,4,3,9,9,7,5,12)下的长期演化均衡仿真结果Fig.1 Dynamic simulation results of long-term evolutionary equilibrium in the general 3P2S–SEG system when taking(a,b,c,d,e,f,g,h,k,l,p,q)=(8,6,3,9,7,4,3,9,9,7,5,12)
由图1可知系统在给定支付参数下最终自发形成4组ESS,即(0,0,1),(0,1,0),(1,0,0)和(1,1,1),它们都是纯策略ESE.根据文献[3–4],以及式(2)所示的ESS的定义,当多群体演化博弈系统在其纯策略处达到均衡状态时,则在该均衡状态下任意种群中的任何个体不会愿意单方面改变其现有策略,而其他任意突变策略也无法入侵(invade)这个种群,此时系统在这些纯策略均衡点处都将取得NE均衡(但反过来,系统取得的NE均衡不一定是ESS),且是严格精炼的NE.具体的证明过程可参考文献[3–4].基于此,该3P2S–SEG系统在一般支付参数下的长期ESE又将如何?详细讨论如下.
首先,根据系统的RD模型进行求解,可知其内部均衡点共8个,且都是纯策略内部均衡点,即

为直观观察系统在这些纯策略处的长期均衡特性,不妨以1/8为间隔,对(x,y,z)的初始值从0至1进行取值,即进行729 轮次重复演化博弈,对12种情形(依次记为Case 1 至Case 12)下(x,y,z)的相轨迹进行动态仿真,结果如图2所示.其中,仿真时间t∈[0,10],Case 1至Case 8则依次详细展示了当Υ3P2S–SEG内每个纯策略为系统唯一ESS时的情形,Case 9至Case 11分别展示了系统长期演化过程中只有1组、2 组和4组ESS的情形,Case 12展示了系统不存在任何长期ESE的情形.图中红色、绿色和蓝色实心圆点分别表示系统长期演化后自发形成的ESE点、不稳定均衡点和鞍点(或中心).
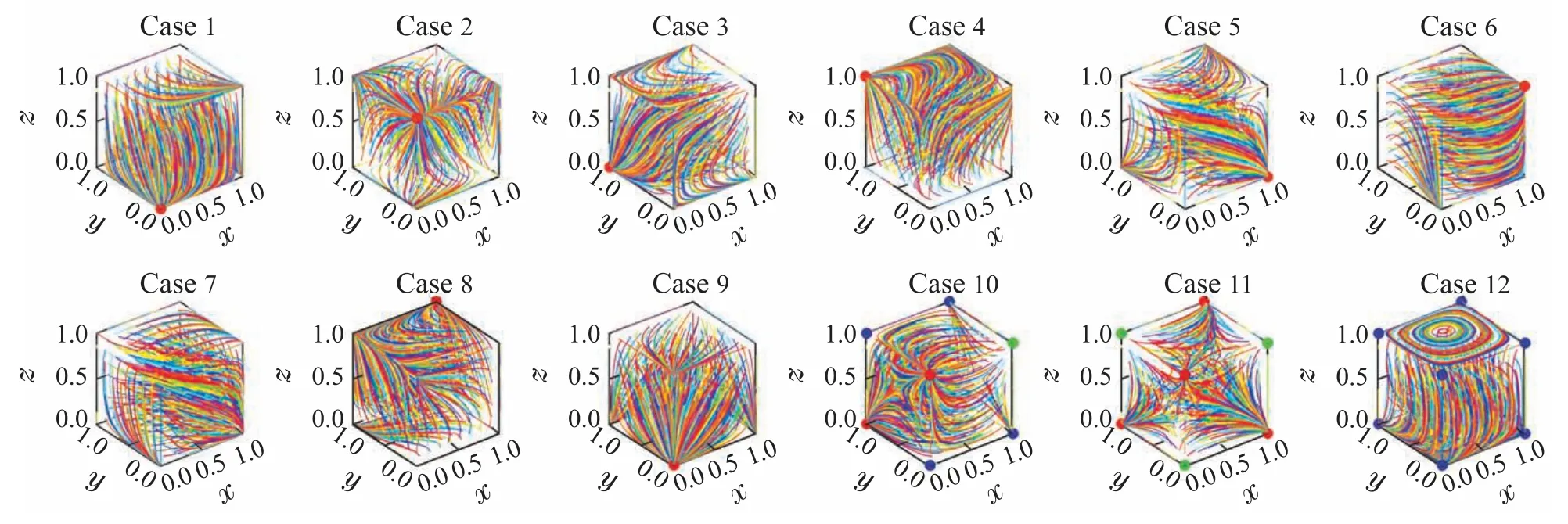
图2 通用3P2S–SEG 系统在12种典型博弈态势下的长期演化稳定均衡动态仿真结果Fig.2 Dynamic simulation results of long-term ESE of the general 3P2S–SEG system in 12 representative game situations
进一步,将Υ3P2S–SEG中每组均衡点依次代入系统雅克比矩阵J3P2S–SEG中,通过计算可依次得出该矩阵在每组纯策略内部均衡点处的特征值.具体而言,在(0,0,0)处,其3个特征值依次为a-c,e-g,k-p;在(0,0,1)处,其3个特征值依次为b-d,f-h,p-k;在(0,1,0)处,其3个特征值依次为b-d,g-e,l-q;在(0,1,1)处,其3个特征值依次为a-c,h-f,q-l;在(1,0,0)处,其3个特征值依次为c-a,f -h,l-q;在(1,0,1)处,其3个特征值依次为d-b,e-g,q-l;在(1,1,0)处,其3个特征值依次为d-b,h-f,k-p;在(1,1,1)处,其3个特征值则为c-a,g-e,p-k.由此可知,J3P2S–SEG的特征值实部由表2中定义的6组系统RNP参数(或其相反数)唯一决定.
因此,对这6组RNP参数的正负取值进行排列组合可知系统长期演化均衡特性共包含64(=26)种博弈态势.如表3所示,全文中分别用“×”、“○”和“⋆”表示系统在相应内部均衡点处处于不稳定均衡状态、临界均衡状态和演化稳定均衡状态,并分别用N1,N2和N3表示相应场景下系统在其8个纯策略内部均衡点处取得的演化稳定均衡状态数、演化不稳定均衡状态数和临界均衡状态数.
如表3所示,每种博弈态势依次由前文定义的6组RNP参数所唯一决定的,它们分别是:a-c,e-g,k-p,b-d,f-h和l-q.基于此,不妨用“+”和“-”分别表示它们取正和取负的情形,例如“++++++”表示上述6组RNP参数依次取正,即a-c >0,e-g >0,k-p >0,b-d >0,f -h >0以及l-q >0.由表3可知:该类通用3P2S–SEG系统在长期演化过程中总计存在64种ESE状态,以及64种演化不稳定均衡状态和384种临界状态(即鞍点或中心).
此外,由表3可知系统在一种博弈态势下最多可同时获得4组长期ESE,且都是纯策略的精炼NE,对此进行动态仿真验证.不妨以1/6为间隔在系统决策空间Ψ内对(x,y,z)的初始值从0至1进行取值,即对表3中所有博弈态势(即博弈场景,将其依次记为Scenario 1至Scenario 64)都进行343轮次演化博弈动态仿真,如图3所示.图中红色、绿色和蓝色实心圆点含义同上图.由图3可知:该系统在各博弈态势下的长期均衡特性仿真结果与表3中的理论分析结果完全一致,从而对理论分析结果进行了有效验证.

表3 一般情形下的通用3P2S–SEG 系统长期演化均衡特性的完整理论分析结果Table 3 Complete theoretical analysis results of long-term equilibrium for the general 3P2S–SEG system
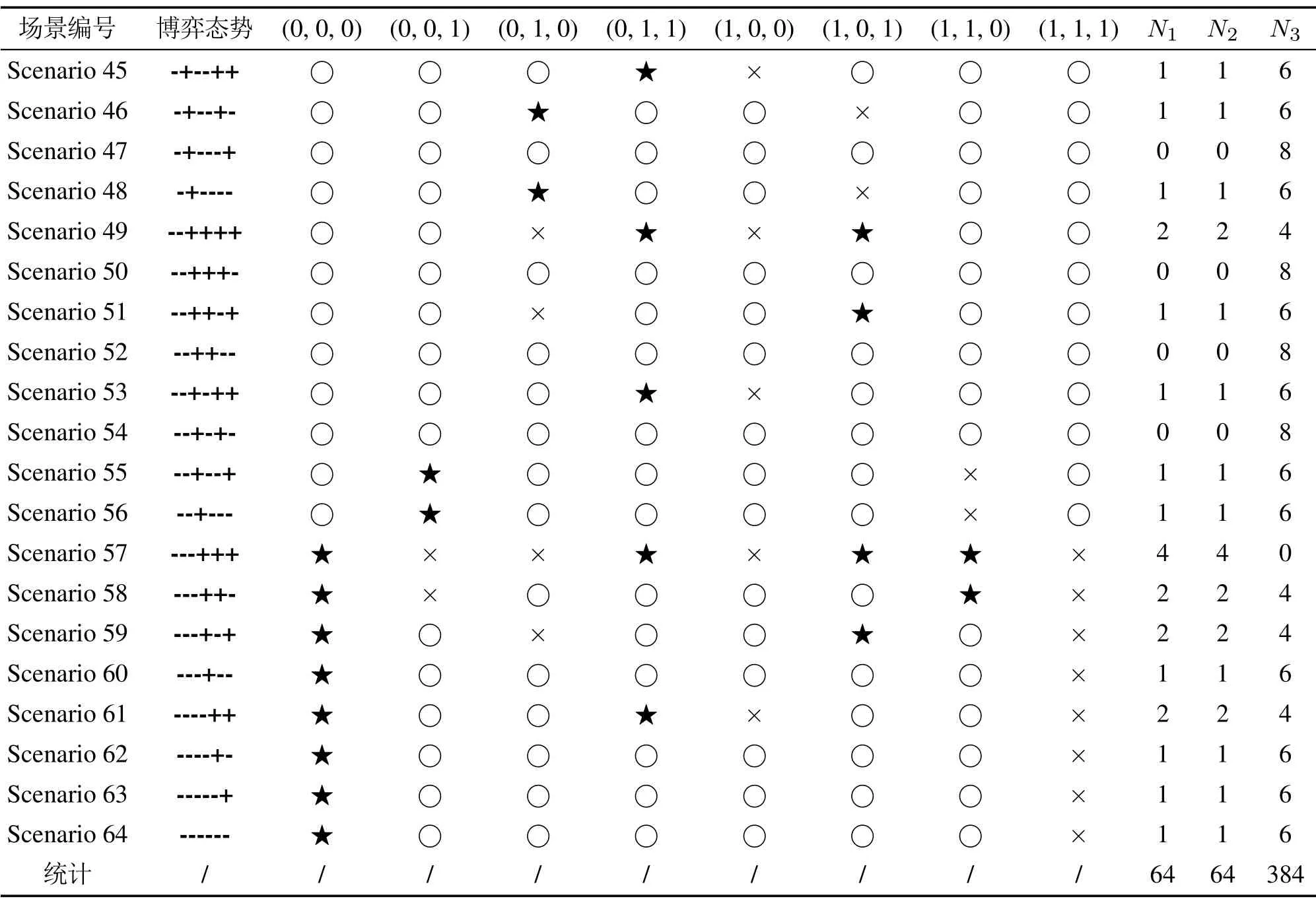

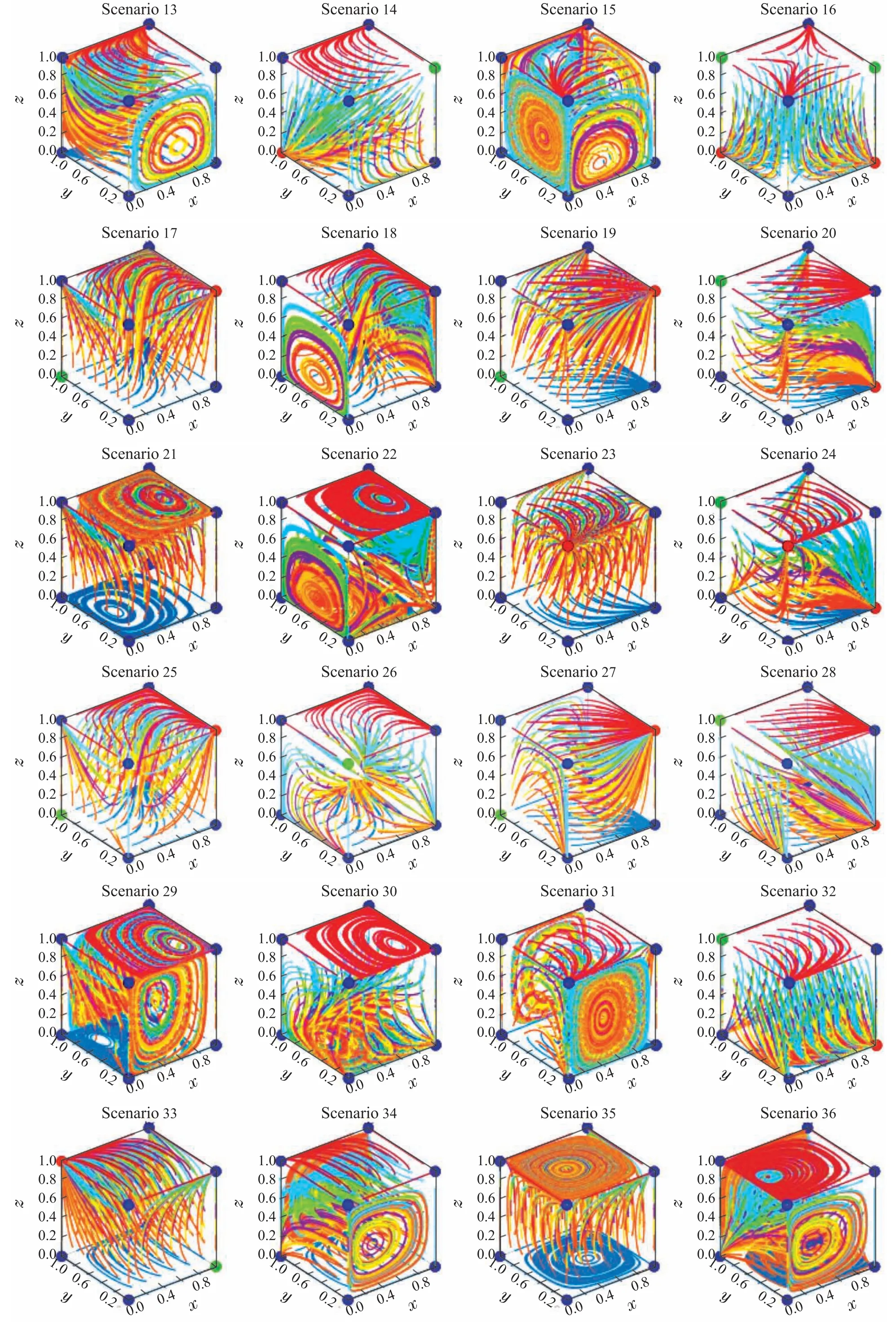


图3 通用3P2S–SEG 系统在所有博弈态势下的长期均衡特性完整动态仿真结果结果Fig.3 Complete dynamic simulation results of long-term equilibrium for the general 3P2S–SEG system in all game situations
总的来说,通过第3.1节对3P2S–SEG 系统的长期ESE 特性的理论分析与动态仿真研究表明:i)该系统仅存在8组纯策略内部均衡点,且最多同时在其中4 组均衡点处取得ESS,即达到ESE状态;ii) 系统最终自发形成的演化状态将由表2 中定义的6 组RNP参数唯一决定,因而可通过改变这些RNP参数使得系统朝着期望的ESE状态处发展;iii)系统完整的长期均衡特性总共包含64种博弈态势,且在这些态势下系统总计可获得64次ESE,以及64次演化不稳定均衡和384次临界演化均衡;iv)系统长期均衡演化过程中,自发形成的ESE 与不稳定均衡数相同,其原因在于系统演化博弈是对称的(支付参数严格对称),而该过程中系统出现次数最多的还是临界演化均衡状态.
3.2 三方两策略式非对称演化博弈(3P2S–SEG)
3.2.1 模型建立
对于3P2S–SEG 系统,其支付矩阵如式(4)所示.基于此,相应的RD模型表示如下:

进一步,通过计算可得到该RD模型对应的雅克比矩阵J3P2S–AEG为

其中:

此外,式(8)所对应的系统策略空间为边长均为1的三维立方体空间,即[0,1]×[0,1]×[0,1].
3.2.2 系统RNP参数定义
基于式(4),本文定义该通用3P2S–SEG系统完整的RNP参数,总计12组,如表4所示.以表4中的前2组RNP参数为例,即(a1-a5)和(a3-a7),其定义为当群体B分别选择其策略集中的策略SB1和SB2,而群体C始终选择策略SC1时,群体A选择策略SA1时的相对净支付.剩余10组RNP参数的含义参照表4可类似得到,不再赘述.显然,若将这12组RNP参数都取负,则成为另外12组RNP参数,分别表示群体A,B和C选择其策略集中的第2个策略时的相对净支付集合.
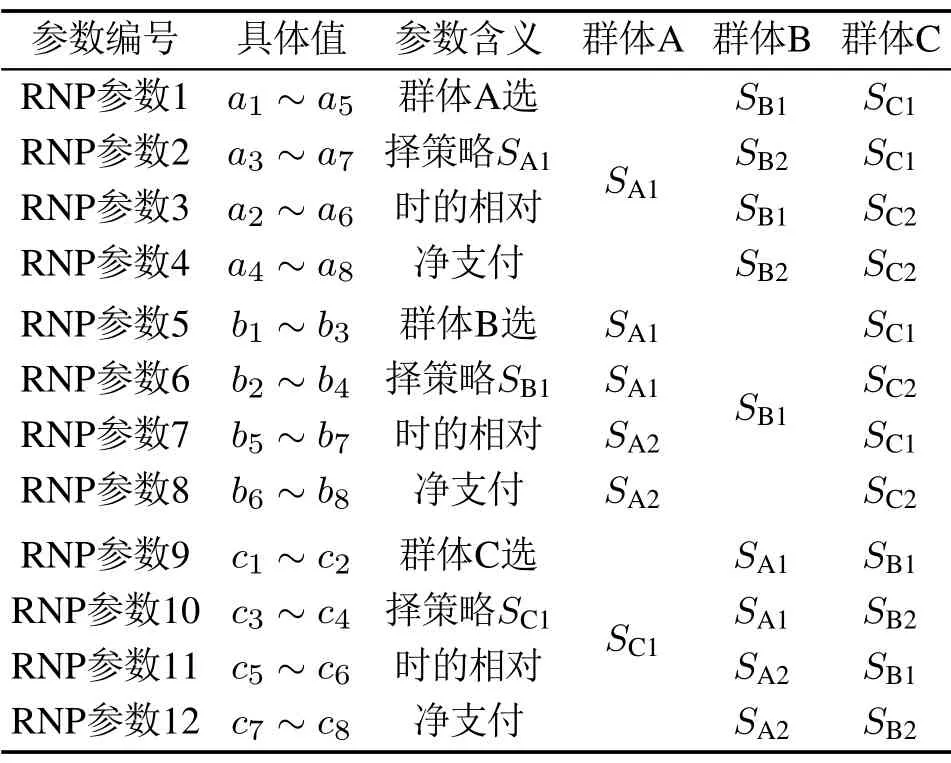
表4 一般情形下3P2S–SEG系统中定义的12组RNP参数Table 4 12 RNP parameters defined in the general 3P2S–SEG system
3.2.3 长期均衡理论分析与动态仿真验证
为更直观观察式(8)所示3P2S–SEG系统的长期均衡演化特性,即各群体策略集中策略SA1,SB1和SC1在演化过程中的动态性与稳定性,不妨取


并分别以1/5,1/6,1/7和1/8为间隔,在系统决策空间[0,1]×[0,1]×[0,1]内对(x,y,z)的初始值(即系统初始博弈态势)从0至1进行取值,即分别进行216,343,512和729轮次演化博弈动态仿真,并分别记住为Case1至Case4,结果如图4所示.其中仿真时间t ∈[0,10].各仿真下分别展示了(x,y,z),(x,y),(x,z)和(y,z)的相轨迹图.由图可见:系统长期ESE在给定支付参数下,将在内部均衡点(0,0,0)处取得唯一的ESS,如各图中红色实心圆点所示.
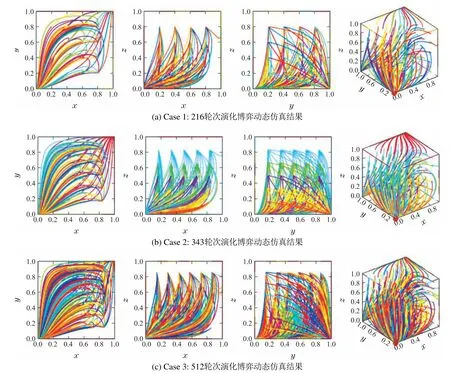
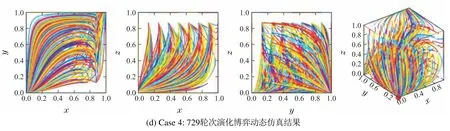
图4 通用3P2S–SEG 系统在给定χ1=15,χ2=-27,χ3=6,χ4=10,χ5=-50,χ6=30,χ7=27,χ8=-22,χ9=-47,χ10=46,χ11=34,χ12=-45时的长期演化稳定均衡动态仿真结果Fig.4 Dynamic simulation results of long-term ESE for the general 3P2S–SEG system when taking χ1=15, χ2=-27,χ3=6,χ4=10,χ5=-50,χ6=30,χ7=27,χ8=-22,χ9=-47,χ10=46,χ11=34,χ12=-45
事实上,对式(8)分析知:系统RD方程不存在其他任何混合策略演化稳定均衡点,而仅存在8组纯策略内部均衡点(都是严格精炼的NE 点),即Φ3P2S–AEG={(x,y,z)|x,y,z ∈[0,1]}={(0,0,0),(0,0,1),(0,1,0),(0,1,1),(1,0,0),(1,0,1),(1,1,0),(1,1,1)},它们刚好位于系统决策空间立方体的8个顶点.基于此,对该通用3P2S–SEG的长期ESE特性讨论如下.
基于上述分析,将Φ3P2S–AEG中各内部均衡点(记为E1~E8)依次代入式(9)所示雅克比矩阵J3P2S–AEG中,可得到其行列式det(J3P2S–AEG)、迹tr(J3P2S–AEG)、以及特征值(λ1,λ2,λ3)的计算统计结果,如表5所示.

表5 通用3P2S–SEG 系统在其纯策略内部均衡点处的雅克比矩阵的特征值、行列式和迹的统计情况Table 5 Eigenvalues,determinants and traces of J3P2S–AEG for the general 3P2S–SEG system at all internal equilibrium points
由表5知,该类3P2S–SEG系统在每个均衡点处的3 个特征值(λ1,λ2,λ3)均为上节定义的RNP参数.这表明系统在E1~E8处的长期ESE 状态取决于3组RNP参数的数学符号.对于表5中均衡点Ei(i=1,2,···,8)而言,假设与之对应的3组RNP参数分别为RNPi,1,RNPi,2和RNPi,3.例如,E1=(0,0,0)的3 组RNP参数分别为:RNP1,1=a4-a8,RNP1,2=b6-b8,RNP1,3=c7-c8.由 此 知,当RNPi,1,RNPi,2和RNPi,3均不为0时,则系统在纯策略内部均衡点Ei处的长期ESE特性的数学描述如式(10)所示:

因此,可知该类通用3P2S–SEG系统最终自发形成的长期演化均衡状态仅仅取决于表4中定义的12组RNP参数,即


它们决定了该类3P2S–SEG系统最终的演化均衡状态.基于此,不妨对上述RNP参数的正负进行排列组合,则可知系统的长期均衡特性总计存在4096(=212)种博弈态势.在这些博弈场景下,3P2S–SEG系统在各纯策略内部均衡点Ei处的长期均衡演化稳定条件及互斥奇点的统计情况如表6所示.
由表6可知系统最多可同时在4组内部均衡点处达到长期ESE状态,且都是严格的精炼NE状态;而每个纯策略均衡点达到演化稳定时均存在与之互斥的3组内部均衡点存在.为更直观观察系统在表6中各纯策略均衡点处的长期ESE特性,不妨进行如下12组动态仿真验证,并分别记为Case 1至Case 12.其中,Case 1至Case 8按顺序依次动态仿真了Φ3P2S–AEG中每个纯策略内部均衡点成为全系统唯一ESS的情形;Case 9至Case 11分别仿真了系统长期演化后仅获得1组、2组和4组ESE的情形;Case 12则仿真了系统不存在任何长期ESE的情形.仿真结果如图5所示,其中决策时间t ∈[0,20],各个博弈情景下分别展示了该演化博弈系统在(x,y),(x,z),(y,z)和(x,y,z)处的相轨迹图.

表6 通用3P2S–SEG系统在各纯策略内部均衡点处的渐进稳定性条件及互斥奇点情况Table 6 Asymptotic stability conditions and corresponding mutually exclusive equilibrium points of the general 3P2S–SEG system at all of its pure-strategy internal equilibrium point



图5 通用3P2S–SEG系统在12代表性博弈态势下的长期演化稳定均衡特性动态仿真结果Fig.5 Dynamic simulation results of long-term ESE characteristics for the general 3P2S–SEG system in 12 representative game situations
由图5可知,所得系统长期ESE特性的仿真结果与表5中的理论分析结果完全一致,从而验证了理论分析所得结果的正确性与有效性.
总的来说,通过第3.2节对通用3P2S–SEG系统的理论分析和动态仿真研究表明:i)该系统的RD方程仅存在8个内部均衡点,如Φ3P2S–AEG所示;ii)在这些均衡点处,系统均可能取得ESS并最终达到长期ESE状态,且是严格的纯策略NE状态;iii) 系统不存在任何混合策略,即使存在,系统在这些策略处也始终无法达到长期ESE状态;iv)系统每组均衡点均存在与之互斥的另外3组均衡点,且任意一组均衡点是否为系统的长期ESE仅取决于3组RNP参数(即初始博弈态势),且系统的RNP参数总共包含12组,因而系统总计存在4096(=212)种演化状态;v)通过适当调整系统的支付参数(ai,bi,ci,i=1,2,3)以改变系统的RNP参数取值,可使系统的长期均衡朝着期望的ESE 处发展,并使期望的ESS在系统长期演化过程中的动态性和稳定性得到有效保证;vi)系统在某一博弈态势下最多可同时获得4组长期ESE状态,此外系统还可能只能获得1组或2组ESE状态,甚至还包括不存在任何ESE状态的情形;vii)当系统达到长期演化稳定时,其中任意一个群体的RD方程恒等于0,且其策略集中的任意策略都将处于稳定水平,且任意策略都可在8种博弈态势下成为该群体的ESS,因而任意群体总计存在16种博弈态势可达到长期ESE状态.
3.3 三方三策略式非对称演化博弈(3P3S–AEG)
进一步将第3.2节中的三方两策略非对称演化博弈(3P2S–SEG)扩展为更复杂的通用三方三策略非对称演化博弈,即3P3S–AEG系统,并探究一般情形下三方多策略式非对称演化博弈系统的长期演化均衡特征.
3.3.1 模型建立
类似于式(4),此时该演化博弈系统的支付矩阵如式(11)所示:
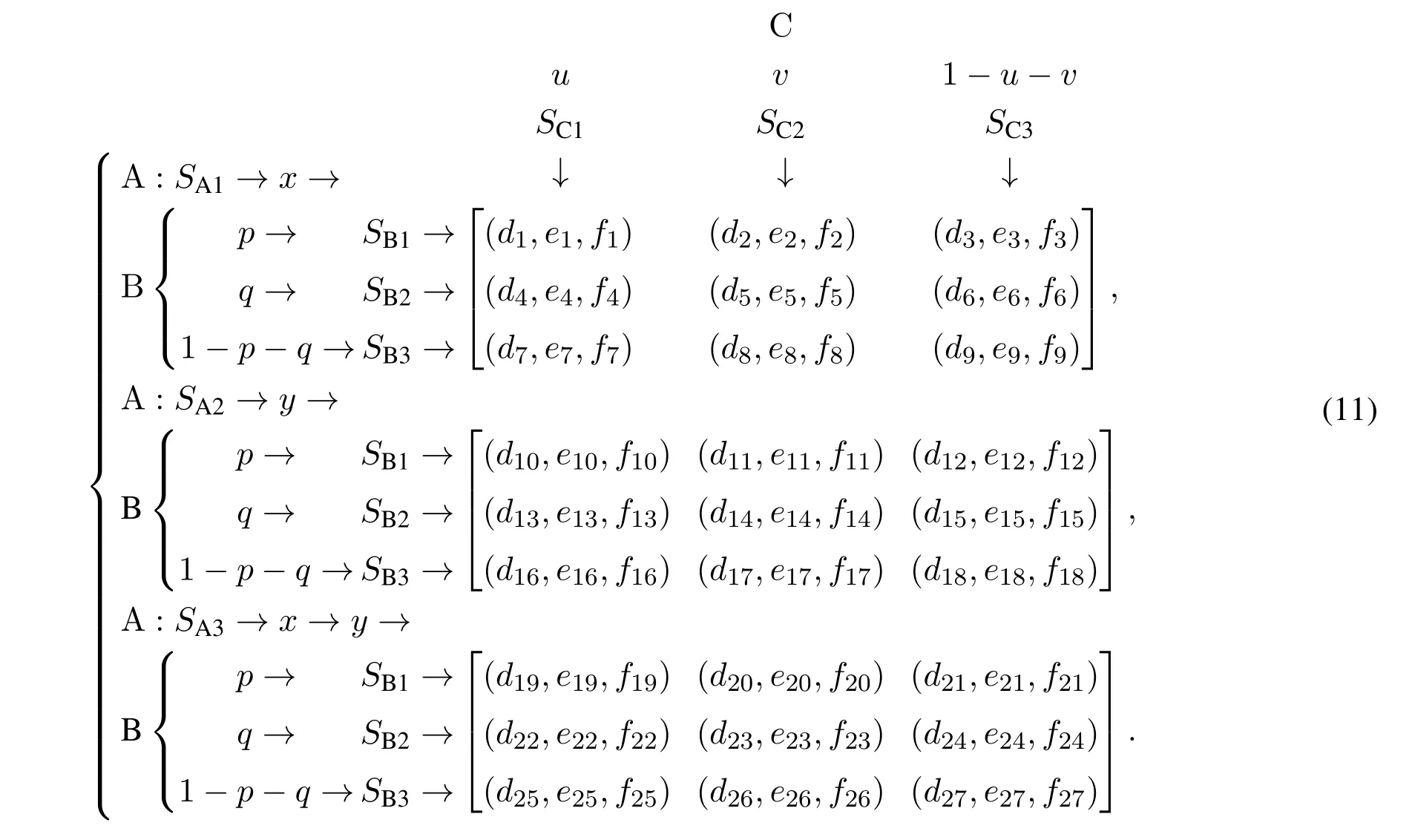
其中,群体A,B和C的策略集各包含3个纯策略,即ΦSA={SA1,SA2,SA3},且每轮次演化博弈过程中,上述各策略在群体A中被选择的概率(或个体比例)分别为x,y和(1-x-y);ΦSB={SB1,SB2,SB3},且各策略在群体B中被选择的概率分别为p,q和(1-pq);ΦSC={SC1,SC2,SC3},且各策略在群体C中被选择的概率分别为u,v和(1-u-v).其中,x,y,p,q,u,v ∈[0,1];di,ei和fi为定义在该通用3P3S–AEG系统中的支付分布参数,其中(i=1,2,···,27).由此可见,系统的决策空间为一个六维空间.假设群体A中个体依次选择其策略集中SA1,SA2和SA3的期望支付分别为l1,l2和l3,而A的群体平均期望支付则为la;同理,群体B中个体依次选择SB1,SB2和SB3的期望支付分别为g1,g2和g3,B的群体平均期望支付为ga;群体C中个体依次选择SC1,SC2和SC3的期望支付分别为h1,h2和h3,C的群体平均期望支付为ha.基于此,根据第2章可得上述各期望支付的值,以群体A为例,经计算可得该群体在各纯策略下的期望支付以及总的种群平均期望支付,如下所示:
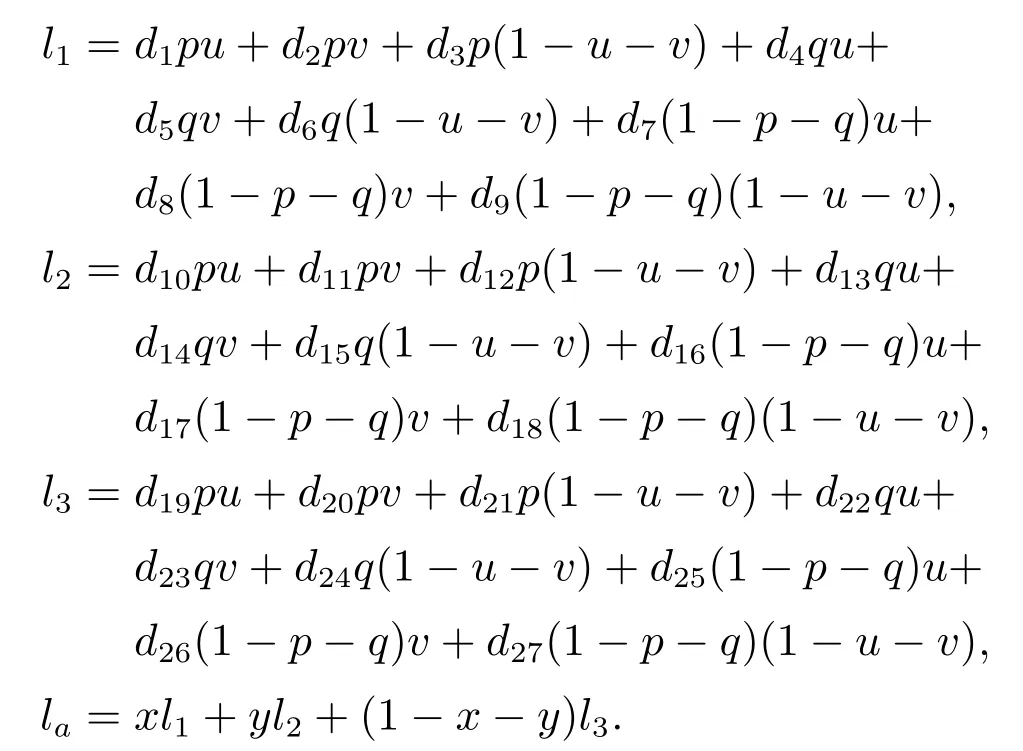
同理,可计算群体B和C的上述期望值,不再赘述.基于此,可得该系统的RD模型(多元偏微分方程组)如式(12)所示:


进一步,根据式(12),经计算可得其雅克比矩阵J3P3S–AEG如式(13)所示.其中,表示f1(x)对x的导数,为f1(x)对y的偏导数,式(13)中其他表达式含义类似.
3.3.2 系统RNP参数定义
同理,可定义该类系统的RNP参数.首先,计算该演化博弈系统的纯策略内部均衡点集合Φ3P3S–AEG.由于x和y(或p和q、u和v)不能同时为1,因此根据式(12)计算可知系统纯策略内部均衡点总计3×3×3=27组,分别记为E1~E27,如表7所示.将E1~E27依次代入式(13)所示雅克比矩阵,可得其相应的特征值,经计算统计后如表7所示.基于此,本文将系统每组纯策略内部均衡点所对应的雅克比矩阵的6组特征值定义为系统的RNP参数.因此,系统此时总计存在81组不重复RNP参数(本文定义绝对值相同的都算重复的RNP参数),如表7第3列所示.由此可知系统在每组纯策略内部均衡点处的长期演化特性将由6组RNP参数所唯一决定.因此,系统完整的长期演化均衡特性总计包含281(≈2.42×1024)种博弈场景,由此可见该类3P3S–AEG系统包含的博弈场景总数目非常大且异常复杂.
3.3.3 长期均衡理论分析与动态仿真验证
通过第3.3.2节理论分析,可知该通用3P3S–AEG系统总计存在多达281种博弈场景,不可能对每种场景进行动态仿真验证.不妨对系统同时存在最多数ESE状态的情形进行仿真验证.由表7可知,在上述E1~E27个纯策略内部均衡点处,系统最多可同时在其中7个均衡点处取得长期ESE,且是严格的精炼的NE(纳什均衡).基于此,通过适当调整3P3S–AEG 系统的RNP 参数,可使系统在E1,E5,E9,E11,E13,E21和E25这7个纯策略内部均衡点处同时取得ESE,其仿真结果如图6所示.其中,以1/2为间隔,在系统的六维决策空间内对(x,y,p,q,u,v)的初始值分别从0至1进行取值,即进行729轮次重复演化博弈动态仿真,图中分别展示了

表7 通用3P3S–AEG 系统的RNP 参数及纯策略内部均衡点统计Table 7 Statistics of RNP parameters and pure-strategy equilibrium points for the general 3P3S–AEG system

的相轨迹图,共20组,并分别用“相轨迹1”至“相轨迹20”表示.此外,各图中红色、绿色和蓝色实心圆点分别表示演化稳定均衡点(汇)、演化不稳定均衡点(源)和演化临界均衡点(即鞍点或中心).由各图可看出系统最终同时在上述E1~E27中的7组纯策略内部均衡点处达到长期ESE状态,从而验证了理论分析结果的有效性.
3.4 一般三方N策略式非对称演化博弈(general 3PnS–AEG)
3.4.1 建模思路
基于前面章节对具体三方多策略演化博弈模型的理论分析与动态仿真验证,本节对通用的三方N策略非对称演化博弈(即3PnS–AEG)的建模思路进行阐述.该思路适用于不同领域内任意复杂的多方多策略演化博弈场景的建模过程,可为模型的长期ESE特性分析与仿真验证提供很好的借鉴.
基于此,系统中的三方A,B 和C各自策略集中均包含有N个策略,分别表示如下.群体A的策略集为ΦAN={SA,1,SA,2,···,SA,N},且每轮次重复博弈过程中各策略被选择的概率(或个体比例)分别为xA,1,xA,2,···,xA,N,其中xA,1+xA,2+···+xA,N=1.同理,群体B的策略集为ΦB,N={SB,1,SB,2,···,SB,N},且策略集中的各策略在每次博弈时被选择的概率(或个体比例)分别假设为yB,1,yB,2,···,yB,N,其中yB,1+yB,2+···+yB,N=1.群体C的策略集为ΦC,N={SC,1,SC,2,···,SC,N},且各策略被选择的概率(或个体比例)分别为zC,1,zC,2,···,zC,N,其中zC,1+zC,2+···+zC,N=1.此外,假设群体A中个体依次选择其策略集中的各策略的期望支付分别为UA,1,UA,2,···,UA,N.相应地,群体B的期望支付分别为UB,1,UB,2,···,UB,N,群体C的期望支付分别为UC,1,UC,2,···,UC,N.基于此,UA,k,UB,k和UC,k(k=1,2,···,N)分别表示如下:

其中:uA,k,i,j为群体B和群体C中个体分别选择其策略集中的第i个策略和第j个策略时,群体A中个体选择第k个策略时的支付;同理,uB,k,i,j为群体A和群体C中个体分别选择其策略集中的第i个策略和第j个策略时,群体B中个体选择第k个策略时的支付;uC,k,i,j为群体A和群体B中个体分别选择其策略集中的第i个策略和第j个策略时,群体C中个体选择第k个策略时的支付.基于此,群体A,B和C各自平均期望支付UA_ave,UB_ave和UC_ave表示如下:

式(16)反映了通用3PnS–AEG 中各群体内个体选择某一纯策略的个体比例(或选择概率)的增长率正比于该个体比例值,也正比于使用该策略所得到的网络期望支付(或收益)与该种群的平均网络期望支付(或收益)之间的差值,因而很好地刻画了有限理性个体的群体行为变化趋势.
3.4.2 算法设计
在实际仿真过程中,需将式(16)作离散化处理以方便系统在重复演化博弈过程中的迭代运算.因此,仿真进行到第m步迭代时,其收敛迭代计算方法为

其中:σm,k,ρm,k和τm,k分别为群体A,B和C中第k个策略的选择概率(或个体比例)在第m次迭代时设置的步长,通常为一个非常小的正数.通过式(17)设计的步长保证了每次迭代过程中各策略选择的概率(或个体比例)不会超出范围[0,1].进一步,为了使迭代过程收敛到预期的精度,通常还需要设置一个非常小的正数用于判断群体A,B和C三方的迭代计算是否达到收敛条件,而一旦达到预期精度即可终止各种群的迭代计算,如下所示.

其中:o1,k,o2,k和o3,k分别为群体A,B和C迭代计算过程中设置的非常小的正数,用于判断各群体长期演化后是否以预期收敛精度达到期望的ESE状态.
3.5 一般两方和三方多策略式演化博弈比较
根据本章研究思路,可进一步研究两方多策略演化博弈系统的长期ESE特性,此处不再赘述.总的来说,本文就两方两策略对称与非对称演化博弈(分别记为2P2S–SEG和2P2S–AEG)、两方三策略对称演化博弈(记为2P3S–SEG)、三方两策略对称与非对称演化博弈(分别记为3P2S–SEG和3P2S–SEG)、以及三方三策略非对称演化博弈(3P3S–AEG)等通用演化博弈系统进行多方面的对比分析和总结,如表8所示.由表8可知,系统涵盖的博弈场景总数等于以2为底、系统的RNP参数总数目为幂的指数,而随着系统各方数目及各方采取的策略数目的增加,系统总的演化状态数量将急剧增加.以3P3S–AEG系统为例,其相比3P2S–SEG,各方策略集中的策略数量仅增加了1个,但系统的RNP参数总数量增加至81个,相应的博弈场景总数增加至281,约等于2.42×1024,这是一个极大的数目.可见,随着系统维度(参与方数量维度或采取的策略数量维度)的增加,其博弈态势将越来越复杂,相应的博弈场景数也急剧增加,使得问题的复杂性和分析难度越来越高.

表8 一般情形下的通用两方和三方多策略式演化博弈系统的演化均衡特性比较Table 8 Comparison of evolutionary equilibrium characteristics between general two-party and three-party multi-strategy evolutionary game systems
通过对对称和非对称三方两策略演化博弈(即3P2S–SEG和3P2S–SEG)的长期演化均衡特性的理论分析与动态仿真验证,笔者发现它们最终在RD方程内部均衡点处可取得的演化状态取决于系统的若干组RNP参数.具体而言,3P2S–SEG取决于6组RNP参数,因而其演化动力学行为决策特性总共包含64(=26)种博弈场景,且每个内部均衡点演化过程中的动态性和渐进稳定性仅取决于2组RNP参数;3P2S–SEG则取决于12组RNP参数,因而其完整的演化动力学行为决策特性总共包含4096(=212)种博弈场景,且每个内部均衡点演化过程中的动态性和稳定性取决于3组RNP参数;对于3P2S–SEG和3P2S–SEG系统而言,前者可在纯策略和混合策略处取得ESS并最终达到演化稳定均衡状态,后者则只能在纯策略处取得ESS并最终达到演化稳定均衡状态,而在混合策略处则始终处于不稳定均衡状态或演化临界均衡状态;此外,二者的RD系统方程最多都只有8个解,因而二者最多具有8个内部均衡点,且都是纯策略均衡点;在这些均衡点处,二者最多都只能同时获得4组ESS使它们达到演化稳定均衡状态,当然系统还可同时获得1组和2组ESS,但无法同时获得3组ESS.这是由于每组内部均衡点成为ESS时必然存在与之互斥的另外3组内部均衡点.最后,对于二者而言,通过改变一些外部因素(如市场监督、政府管控、政策发布等)适当调整某些RNP参数将可使得系统朝着期望的稳定均衡状态处演化,从而使系统演化过程中策略选择的稳定性和动态性得到有效保证,有利于系统的长期演化发展.
相较之下,通过对扩展后的通用三方三策略非对称演化博弈(即3P3S–AEG)的长期演化均衡特性的理论分析与动态仿真研究发现:通用3P3S–AEG总计存在27组纯策略内部均衡点,且每组均衡点能否成为系统的长期ESE由6组RNP参数唯一决定;系统总计存在81组RNP参数,因而其完整的长期演化特性总计包含281种博弈场景,数目非常大而且很复杂;此外,系统的每组纯策略内部均衡点达到演化稳定时,都存在与之互斥的6组其他纯策略内部均衡点,即这6组均衡点要么处于不稳定演化状态,要么处于临界演化状态(鞍点或中心).例如,E1达到演化稳定时,E2,E3,E4,E7,E10和E19则必然为演化不稳定的均衡点或鞍点(或中心).此外,通过适当调整系统的RNP参数可使其朝着期望的长期ESE状态处发展.
4 三方多策略演化博弈举例分析
本章探讨三方多策略演化博弈的应用,以三方两策略非对称演化博弈(3P2S–SEG)为例,通过动态仿真分析,描述这一更为常见的三方两策略式演化博弈类型在工程技术领域中的使用场景.
4.1 新能源发电企业参与的发电侧EM竞价模型
针对新能源企业参与的发电市场多方竞价博弈情形,文献[51]对此进行了简要的理论分析,对RD系统平衡状态的渐进稳定性的讨论并不十严格,未涉及实际三方收益,且并未开展动态仿真验证.基于此,选择文献[51]的研究对象为例,对其中的三方之间的利益联系进行动态仿真验证.因此,基于文献[51],以新能源和传统能源两大类发电企业参与供给侧发电市场长期竞价电量上网为例,讨论新能源发电企业(记作群体A)、传统能源发电企业(记作群体B)和电网公司企业(记作群体C)三方在上述发电市场竞价电量演化博弈过程中的长期均衡特性.为此,本章的算例仿真分析对建立的雅克比矩阵的行列式和迹表达式中各参数的物理或经济含义进行了详细说明,定义了该博弈场景的RNP参数,考虑了这些RNP参数的政策性调整对整个三方演化博弈系统的长期ESE状态的影响机制以及对博弈方之间决策行为的交互影响,并进行了总结与仿真验证.相较之下,文献[51]只是部分开展了上述研究工作,并未对三方演化博弈系统的长期演化稳定均衡规律进行详细的总结分析与动态仿真验证.
基于此,在上述实际演化博弈场景中,假设参与博弈决策的三方(即群体A,B,C)的策略集中各实施2个纯报价策略参与供给侧发电市场的长期发电量竞价上网博弈,该策略集不妨分别记作SA={SA1,SA2},SB={SB1,SB2}和SC={SC1,SC2},由此可得支付矩阵为

其中li,mi,ni(i=1,2,···,8)为该例中设定的用于表示不同策略组合下的收益的通用分布参数.此外,纯策略SA1和SA2在每轮电量博弈中被A内企业个体选择的概率(或比例)分别为α和1-α,并分别表示新能源发电企业选择与传统能源发电企业合作(即A选择与B合作)并送出新能源上网交易电量为W1、新能源发电企业选择不与传统能源发电企业合作(即A选择不与B合作)并送出新能源上网交易电量为W2;纯策略SB1和SB2在每轮博弈中被B内企业个体选择的概率(或比例)分别为β和1-β,并分别表示传统能源发电企业选择与新能源发电企业合作(即B选择与A合作)并送出传统能源上网交易电量为T1、传统能源发电企业选择不与新能源发电企业合作(即B选择不与A合作)并送出传统能源上网交易电量为T2;纯策略SC1和SC2在每轮博弈中被C内企业个体选择的概率(或比例)分别为γ和1-γ,并分别表示电网公司企业选择积极参与消纳新能源并且消纳新能源发电量为G1、电网公司企业选择消极消纳新能源并且消纳新能源发电量为G2.其中,α,β,γ ∈[0,1].
显然,这是一个由新能源发电企业群体A、传统能源发电企业群体B和电网公司企业群体C构成的三方两策略参与的发电侧电力市场竞价上网电量演化博弈,是一个典型的三方两策略非对称演化博弈,即3P2S–SEG.此时,A是否倾向于选择与B合作、B是否倾向于选择与A合作、政府相关部门是否对新能源参与发电市场交易进行监督和管控、C是否倾向于选择积极参与新能源消纳等因素关乎发电市场能否长期健康稳定的运行,这个上网电量竞价博弈过程显然是一个在有限信息系统内进行的市场长期均衡演化过程,因而非常适合利用EGT 进行分析.根据第3章分析,显然该3P2S–SEG的系统RD方程有且仅有8个纯策略内部均衡点(x,y,z),即Φ3P2S–AEG={(x,y,z)|x,y,z ∈[0,1]}={(0,0,0),(0,0,1),(0,1,0),(0,1,1),(1,0,0),(1,0,1),(1,1,0),(1,1,1)}.基于此,该系统的RD方程为


4.2 仿真分析
将上述Φ3P2S–AEG中的8个纯策略内部均衡点依次代入到式(21)中,可得到JABC在这8个均衡点处的特征值、行列式和迹的计算统计结果,如表9所示.由表9可得:每个内部均衡点均存在对应的3组互斥均衡点存在,且系统在每组均衡点处是否获得长期ESE取决于对应的3组RNP参数.因此,系统最多可在1,2和4组内部均衡点处取得长期ESE,即新能源发电企业参与的发电侧电力市场三群体两策略非对称上网电量竞价演化博弈最多存在4组竞价电量ESS.当然,这种情况需要建立在市场无任何监督的条件下才能发生.事实上,当政府对市场不进行任何监督时,即发电侧电力市场没有制定有效的上网电量交易规则时,该市场经长期发展最终将会自发形成如下演化稳定的博弈态势.
情形i) 无论电网企业群体C是否选择积极或是消极消纳新能源,以及无论传统能源发电企业群体B是否选择与新能源发电企业群体A合作,对于A而言,显然其选择不与B合作,相较于其选择与B合作能获得更多的竞价上网电量,从而获得更高的收益.此时根据式(19),存在如下两种情形:a)当电网企业群体C选择积极消纳新能源时,而当B始终选择合作时,A选择不与B合作相较于与B合作能获得更高收益,即l5>l1,此时由表9知E8(1,1,1)为演化不稳定的纯策略内部均衡点,系统无法在该点处取得长期ESE;当B始终选择不合作时,A也选择不与B合作相较于与B合作能获得更高收益,即l7>l3,此时由表9知E6(1,0,1)将为演化不稳定的纯策略内部均衡点,系统在该点处无法取得长期ESE;同理,无论A是否选择与B合作,B始终选择不与A合作相较于其选择与A合作能获得更多的上网电量,即获得的收益更高,此时可得m3>m1(A始终选择与B合作时),以及m7>m5(A始终选择不与B合作时).由此可知E8(1,1,1)和E4(0,1,1)都将成为演化不稳定的纯策略内部均衡点,系统在这两点处无法取得长期ESE;b)当电网企业群体C选择消极消纳新能源时,无论A是否与B合作,B始终选择不合作可获得更多上网电量,即发电收益更高,可得m4>m2(A 始终选择与B 合作时),以及m8>m6(A始终选择不与B合作时),由表9知E7(1,1,0)和E3(0,1,0)都将成为演化不稳定的内部均衡点,系统在这两点处无法取得长期ESE;同理,无论B是否与A 合作,A始终选择不与B合作相较于其选择与B合作能获得更多的上网电量和收益,则有l6>l2(B始终选择与A合作时),l8>l4(B始终选择不与A合作时),由表9知E7(1,1,0)和E5(1,0,0)都将成为演化不稳定的纯策略内部均衡点,系统在这两点处无法取得长期ESE.因此,当政府在市场发展初期对该发电市场暂不进行有效的竞价交易监督时,在情形i)下可知E3(0,1,0),E4(0,1,1),E5(1,0,0),E6(1,0,1),E7(1,1,0)和E8(1,1,1)最终都无法自发演化形成为该市场的长期ESE状态.

表9 A,B和C三方参与的发电侧电力市场竞价上网电量博弈的内部均衡点稳定性统计Table 9 Evolutionary stability statistics of internal equilibrium points of the generation-side pricing game for online electricity involving three parties of A,B and C
情形ii) 无论新能源发电企业群体A与传统能源发电企业群体B之间是否合作,电网企业群体C在政府对市场无监督情况下选择消极消纳新能源相较于其选择积极消纳新能源能降低更多的运营成本(此时无需额外投资建设电网用于消纳新能源),因而获得的效益也更高.此时,基于式(19),依然存在如下两种情形:a)当A选择与B合作时,C始终选择消极消纳新能源能获得更高的收益,可得n2>n1(B选择与A合作时),以及n4>n3(B选择不与A合作时),此时由表9知E6(1,0,1)和E8(1,1,1)都将成为演化不稳定的纯策略内部均衡点,系统在这两点处无法取得长期ESE;b)当A选择不与B合作时,C始终选择消极消纳新能源获得的收益将更高,可得n6>n5(B选择与A合作时),以及n8>n7(B选择不与A合作时),此时由表9可知:E2(0,0,1)和E4(0,1,1)都将成为演化不稳定的纯策略内部均衡点,系统在这两点处无法取得长期ESE.因此,当政府对市场无有效监督时,在情形ii)下可知E2(0,0,1),E4(0,1,1),E6(1,0,1)和E8(1,1,1)最终都无法自发演化成为该市场的长期ESE状态.
综合上述情形i)和情形ii)可知,在政府相关部门未对该发电侧市场的企业电量竞价上网做出有效监督时,即市场尚未制定有效的上网电量交易规则时,该市场长期演化过程中,其仅有的8个纯策略内部均衡点中将有7 个成为演化不稳定的纯策略均衡点,即E2,E3,E4,E5,E6,E7和E8.在这些均衡点处系统无法取得ESS,即含这些电量竞价策略的企业小群体将无法入侵到达到长期ESE状态的群体中来,从而在发电市场的演化过程中逐渐消失掉.此时,可知系统仅存在唯一的一个演化稳定的纯策略内部均衡点,即E1(0,0,0),其含义为新能源发电企业群体A与传统能源发电企业群体B之间互相采取不合作策略,同时电网企业群体C采取消极消纳新能源策略.
由此可见,在政府无有效监督下,群体A,B和C都将采取其策略集中第2个策略以争取更多上网交易电量或降低更多电网运营成本,实现自身利益最大化.此时,新能源与传统能源发电企业间互不合作,电网企业群体针对由于消纳新能源带来的电网投资成本升高这一状况,选择消极消纳新能源企业的发电量,由此造成的后果是:新能源发电企业群体无法有效参与到发电市场交易,市场中存在大量的新能源发电量被弃用,即弃风弃光现象非常严重,这不利于可再生能源的持续发展,容易造成发电市场动荡以及长期不健康运行,对此进行动态仿真验证.
在满足上述情形i)和ii)的条件下,在三维决策空间[0,1]×[0,1]×[0,1]内对α,β和γ的初始值以1/8为间隔从0到1进行取值,即进行多达729轮次的发电市场上网电量重复竞价博弈动态仿真,观察电量竞争策略(α,β,γ)在市场长期演化发展过程中的相轨迹,仿真时间取t=10(单位:年),仿真结果如图7所示.图7中,红色、绿色和蓝色实心圆点分别表示系统取得的唯一电量竞争ESS(即长期ESE状态)、演化不稳定均衡状态和演化临界状态(即鞍点).

图7 政府无监督情况下新能源发电企业群体参与的发电侧电力市场上网电量博弈的动态仿真:在729 次动态仿真下(α,β,γ)的相轨迹图Fig.7 Dynamic simulation results of the generation-side ongrid power generation amount competition game involving participants of new energy corporation groups when the government conducts no supervision on the power generation market:the phase trajectory of (α,β,γ)based on 729 times of simulations
由图7可知:经过不同轮次的动态仿真,系统最终都只在E1(0,0,0)处取得唯一的长期竞价ESS,在E2,E3,E4,E5,E6和E7处处于临界状态,在E8处则处于演化不稳定状态.因此,通过理论分析与动态仿真验证可见:在政府对发电市场不进行有效监督的情况下,新能源发电企业群体、传统能源发电企业群体和电网公司企业群体三方将经过多轮次的上网电量降价长期博弈,最终使该发电市场在均衡点E1 处自发形成唯一的竞价ESS,即达到唯一的长期ESE状态.在该状态下,新能源与传统能源发电企业群体间采取互不合作的策略,与此同时电网企业群体消极消纳新能源,以争取自身经济利润最大化.
显然,在上述唯一ESE状态下,市场无法良性发展,对于促进新能源发电企业参与电力市场交易和促进新能源消纳都是极为不利的.因此,有必要结合表9对该市场的相关纯策略内部均衡点的RNP参数进行适当调整,而这可通过政府制定有效的发电侧电力市场电量上网竞价交易规则来实现.此时,需要通过政府有效监督和引导新能源发电企业与传统能源发电企业互相合作,并使电网公司企业群体积极参与到新能源消纳中来,而其他上网电量竞价策略都将在市场长期演化发展过程中逐渐消失掉.因此,通过政府积极制定交易规则引导电力市场良性发展,将使得E8(1,1,1)成为全系统唯一的ESS.而要实现这一点,则需要系统的RNP参数同时满足如下5个条件:i)l5<l1,m3<m1,n2<n1,该条件可使得E8(1,1,1)逐渐演化成为长期ESS,相应地,E4(0,1,1),E6(1,0,1)和E7(1,1,0)将成为不稳定的演化均衡点;ii)l4>l8,m6>m8,n7>n8中至少有一个满足,这将使得E1(0,0,0)成为演化不稳定的均衡点;iii)l3>l7,m5>m7,n8>n7中至少有一个满足,这将使得E0(0,0,1)成为演化不稳定的均衡点;iv)l2>l6,m8>m6,n5>n6中至少有一个满足,这将使得E3(0,1,0)成为演化不稳定的均衡点;v)l8>l4,m2>m4,n3>n4中至少有一个满足,这将使得E5(1,0,0)成为演化不稳定的均衡点.
基于此,系统中除E8(1,1,1)外,其余7个纯策略内部均衡点都将成为系统的不稳定均衡点或鞍点,从而系统在这些均衡点处无法取得ESS,即无法达到长期ESE状态.此时,E8(1,1,1)成为全系统唯一的ESS,发电市场在该均衡点处将达到长期ESE状态.在该均衡点处,新能源发电企业群体与传统能源发电企业群体选择互相合作,促进新能源发电企业积极参与发电侧电力市场发电量交易,同时电网企业群体在一定精度负荷预测基础上选择积极参与到新能源消纳中来,进一步促进新能源发电量上网,并尽量减少弃风弃光等新能源浪费现象发生.这对于电网削峰填谷和安全稳定运行都具有重要意义.
因此,在完成对上述RNP参数调整的前提下,对“E8(1,1,1)成为发电市场唯一的长期竞价ESS”这种情况进行动态仿真验证.在该发电市场的三维决策空间[0,1]×[0,1]×[0,1]内对α,β和γ的初始值以1/9为间隔从0 到1进行取值,即进行1000轮次的上网电量竞价博弈动态仿真,观察电量竞争策略(α,β,γ)在市场长期演化发展过程中的演化趋势(即相轨迹),仿真时间取t=10(单位:年),仿真结果如图8所示.其中,各图中红色、绿色和蓝色实心圆点含义同图7.
图8表明:在满足上述i)–v)所示的RNP参数条件下,市场将在E8(1,1,1)处取得唯一的ESS,即发电市场将在该点处达到唯一的长期ESE状态.此时新能源发电企业群体A选择与传统能源发电企业群体B互相合作,而电网企业群体C则选择积极参与新能源消纳.除此之外,系统其它的7个纯策略均衡点都将成为演化不稳定的均衡点,系统在这些均衡点处将处于不稳定均衡状态(绿色圆点)和临界均衡状态(蓝色圆点),而选择这些演化不稳定均衡点处策略的企业小群体最终将无法入侵到达到演化稳定均衡状态的企业群体中来,从而在发电侧电力市场长期的演化发展过程中逐渐消失,并成为市场中不稳定的发电量上网竞价策略组合.

图8 政府有监督情况下新能源发电企业群体参与的发电侧电力市场上网电量博弈的动态仿真:在1000次动态仿真下(α,β,γ)的相轨迹图Fig.8 Dynamic simulation results of the generation-side ongrid power generation amount competition game involving participants of new energy corporation groups when the government conducts some supervision on the power generation market:the phase trajectory of(α,β,γ)based on 1000 times of simulations
总的来说,上述算例仿真分析充分验证了本文关于三方两策略演化博弈行为决策特性的理论研究结论,这也表明通过对具体算例的演化博弈模型进行完整的演化动力学行为决策特性的理论分析与动态仿真验证,可充分发掘系统在所有内部均衡点处的长期演化稳定均衡状态,并确定系统所有的RNP 参数,并进一步获得这些参数的实际物理含义或经济含义.此外,通过算例仿真分析表明:通过一些外部因素(比如算例中提到制定市场竞价交易政策进行引导与监督)来适当调整复杂多方演化博弈系统的这些RNP参数将会使得全系统的长期演化稳定均衡状态朝着期望的均衡点处收敛.这对于研究工程或其他领域内更复杂、具体的多群体多策略式对称与非对称演化博弈问题具有重要的理论指导和借鉴意义.
5 总结
演化博弈论(EGT)建立在有限理性和有限信息假设基础上,相比经典博弈论更加符合实际博弈情形,因而EGT目前在很多领域得到了初步发展.为此,立足于EGT中的RD,ESS和ESE等几个核心概念,本文探索了较为常见的通用三方多策略对称与非对称演化博弈的行为决策特性,通过详细的理论分析与动态仿真总结和验证了诸如3P2S–SEG,3P2S–SEG,3P3S–AEG等常见三方两策略和三策略演化博弈模型的长期ESE 特性.在研究过程中,本文详细定义了各类演化博弈模型的RNP参数.
研究表明这些RNP参数决定了各演化博弈最终的长期ESE状态的获取,因而通过某些外部因素适当调整这些RNP参数可使各类三方多策略演化博弈模型朝着期望的长期ESE状态处演化发展.此外,通过定义模型的RNP参数,可以完整揭示模型所有的演化博弈场景,其总数等于以2为底、定义的系统RNP参数总数目为幂的一个指数,而进一步将系统所有的内部均衡点依次代入到每种博弈场景中即可得到系统完整的演化状态分布,即演化动力学行为决策特性分布.这为研究实际的三方多策略(甚至更多方多策略场景)演化博弈行为决策问题提供了一种很好的求解思路.
此外,本文对各类通用两方和三方多策略演化博弈模型的长期ESE特性进行了详细总结,并对一般情形下的三方任意策略非对称演化博弈的建模思路和收敛迭代计算方法进行了详细阐述,可为研究更多方参与的实际多策略演化博弈问题提供一些理论参考.最后,本文提供了一个供给侧发电市场中三方参与上网电量竞争的长期演化博弈的算例,对本文研究模型和方法的有效性进行了充分验证.
总的来说,本文研究模型、方法和所得结论具有一定普适性、有效性和实用性,可适用于研究各类实际的三方多策略对称与非对称行为决策问题,并可进一步拓展用于更复杂的多方多策略行为决策问题分析.本文抛砖引玉,从理论研究与动态仿真验证出发详细探索了非完全理性群体参与的三方多群体对称与非对称演化博弈行为决策问题的解决方案,旨在丰富演化博弈论的理论与应用研究内容,期待为相关领域内非完全理性参与人的多方多策略演化博弈,尤其是三方多策略演化博弈行为决策问题提供一些思路与理论参考.
