基于自适应选择的多策略粒子群算法
2021-11-17蔡铭,李响
蔡 铭,李 响
(北京理工大学宇航学院,北京,100081)
1 引言
粒子群优化算法是一种基于种群智能的优化算法,其结构简单且收敛速度快。近几年,粒子群算法仍然被广泛应用于各个领域,如轨迹优化[1],数据辨识[2]和特征选择[3]等。但是相比与其它进化算法,粒子群算法在解决复杂的多峰问题容易陷入局部最优[4]。针对该缺点,不少学者提出了很多改进的粒子群算法。最为典型的便是CLPSO算法[5],该算法通过提高粒子的多样性来提高算法对于多峰问题的解决能力,但是与此同时其收敛速度也随之降低。为了提高算法对不同类型问题的适用性,本文提出了,基于自适应选择的多策略粒子群算法。试验表明:与其它4种改进的粒子群算法相比,本文所提的算法具备更高的全局收敛精度与更快的收敛速度。
2 粒子群优化算法
粒子群算法是由Kennedy和Eberhart于1995年提出[6,7]。与遗传算法和差分进化算法类似,粒子群算法是一种基于种群的智能进化算法。粒子群算法模拟自然界中鸟类觅食与迁徙行为对问题的解空间进行搜索。每个粒子具有位置矢量与速度矢量,其位置矢量对应解空间中的一个解。粒子的位置矢量通过速度矢量进行更新,而速度矢量则根据粒子自身的历史最优位置pbest与种群的历史最优位置gbest进行更新。通过多次迭代得到的种群历史最优位置即为粒子群算法对该问题求解所得的最优解。对于粒子i而言,其速度矢量vi和位置矢量xi的更新可表示为
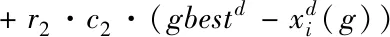
(1)
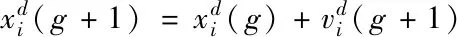
(2)
3 基于自适应选择的多策略粒子群
3.1 策略池的建立
传统的粒子群算法以及大多的粒子群改进算法的速度更新策略仅有一种,即式(1)或对式(1)进行改进。单策略的速度更新往往无法兼顾算法解决不同类型问题的能力,如CLPSO[5]增强了算法对复杂多峰问题的解决能力,但其对单峰问题的收敛速度有所降低;PSO-cf[8]提高了算法对单峰问题的收敛性能,但在解决复杂多峰问题时算法容易陷入局部最优。单策略型粒子群算法能否解决问题取决于其策略是否适合,但问题的类型可能不明确,逐个尝试的方法来寻找合适的策略其工作量过大。多策略型粒子群算法其包含多种速度更新策略,因此对不同类型问题的优化求解有更好的适用性。
受SLPSO启发,本文建立了包含以下4种不同策略的策略池[9]:
1)探索
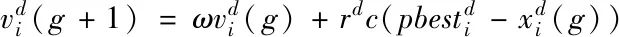
(3)
2)开发
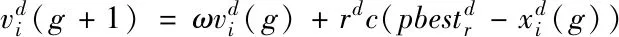
(4)
3)跳跃
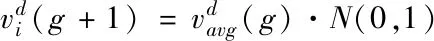
(5)
4)收敛
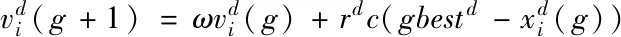
(6)

3.2 自适应选择机制
对于多策略型粒子群算法,在建立了包含多种速度更新策略后,还需要为算法制定自适应选择机制,让粒子在更新迭代的过程中能够根据自己的自身情况选择适合的策略。在介绍自适应选择机制前,不妨对四种策略的性质与功能进行表述:
1)探索策略:仅包含“自我认知”部分,采用该策略的粒子仅向其自身的历史最优位置学习,对于处在“坡”处的粒子,该策略效果最佳[9]
2)开发策略:赋予粒子向其它粒子的历史最优位置学习的能力,相比于探索策略该策略对多峰问题的处理更有效
3)跳跃策略:通过种群的平均速度与正态分布的随机数,使得粒子能够在陷入局部最优时具备一定的逃逸能力
4)收敛策略:仅包含“社会认知”部分,该策略能让粒子向种群的历史最优位置靠拢。当搜索环境较为简单时,其效果最佳。但当种群的历史最优位置为局部最优,过多粒子使用该策略可能使得算法出现早熟。
理论上,自适应选择机制可以让种群中的粒子根据其自身情况选择出最佳的策略来更新自己的速度与位置。SaDE[10]与SaLPSO[11]的自适应选择机制是基于种群的机制,其每个粒子是根据之前整个种群的反馈进行选择策略,这种做法可能使得一些粒子被迫选择不适合自己的策略。为了避免出现这种状况,本文的自适应选择机制其实施对象为种群中的每个个体,而非是整个种群。也就是说,每个粒子的速度更新策略的选择是根据自身的反馈而并非整个种群的反馈。
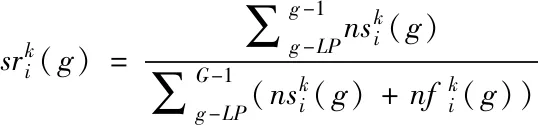
(7)
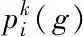
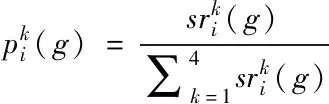
(8)
不妨把长度为LP的反馈结果记录在成功表格与失败表格中。随着粒子的迭代,其成功与失败表格也随之更新。表格更新主要是将最旧的信息(即代数最低的数据)替换为最新的信息。如图1所示为第i个粒子从g代进化到g+1代,其成功表格的更新,在更新后g-LP代的信息被抹除,取而代之的是g代的信息。
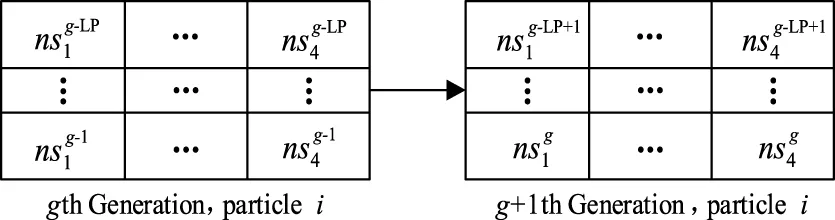
图1 第i个粒子g代到g+1代的成功表格更新
至此,自适应选择机制便完成建立。但仍有一些情况需要说明:
1)学习周期LP为预先给定的一个整数。当代数g小于等于LP时,由于各个粒子成功与失败的表格并没完全建成,因此每个粒子4种策略被选中的概率均相等即0.25,当代数g大于LP时,各个粒子的成功与失败表格便开始更新,各粒子4种策略被选中的概率便可通过式(7)和式(8)进行计算求解。
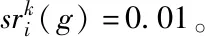
3)自适应机制对粒子自身情况的变化响应要足够较快。对于复杂的多峰函数而言,各个粒子需要在迭代过程中,根据自身的情况尽早的舍弃原有的策略而选择出合适的策略。例如,对于粒子i,可能在某个阶段最佳策略均为探索策略,因此其策略被选中的概率趋近于1,而其它策略被选中的概率趋近于0,但随着局部搜索情况的变化,最佳的策略变为跳跃策略。而跳跃策略若以极低的被选概率被选中且成功了,则其被选中概率便会迅速上升,相应的探索策略被选中的概率随之降低。
3.3 基于自适应选择的多策略粒子群算法的整体框架
基于自适应选择的多策略粒子群算法的整体框架如下所示。
Algorithm 3 MPSO-AS Algorithm
1) initialize the position and velocity of particles in the swarm randomly;
2) set the nfe=0,generation number g=0;
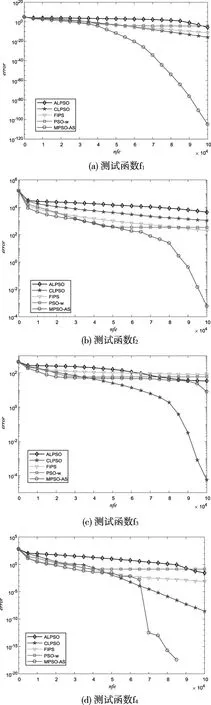
3) while nfe 4) if g>LP then 5) update probability of 4 strategies for each particle according to (8) 6) end if 7) for each particle i do 8) select the strategy k by roulette wheel selection; 9) update the position and velocity of particle i; 10) if f(xi(g)) 12) else 14) end if 15) if f(xi(g)) 16) pbesti=xi(g); 17) if f(xi(g)) 18) gbest=xi(g); 19) end if 20) end if 21) end for 22) g=g+1; 23) end while 与标准粒子群算法相比,基于自适应选择的多策略粒子群算法的额外计算量主要在于自适应选择机制中各个粒子4种策略选中概率的计算。而在选中概率的计算过程中,没有额外的适应值计算。 总体来说,若算法共进行Ite次迭代,则基于自适应选择的多策略粒子群算法的总计算复杂度为O(PS)。 为了测试基于自适应选择的多策略粒子群算法的性能,本次试验采用8个标准测试函数,可将其分为三组。 1)第一组为4个标准测试函数,其中包括: 2个单峰函数(f1,f2) 2个多峰函数(f3,f4) 2)第二组为病态条件下的标准测试函数,其是在标准测试函数的基础上加入噪声、平移和旋转的操作,从而提高测试函数的复杂。 其中,平移函数为Shifted Schwefeil 1.2函数,具体可以表示为: o为平移量,也是全局最优的解;fbias为函数值偏移量,此处fbias=-450。 旋转操作的方法参考CLPSO中的方法,具体可以表示为 M为正交矩阵。 噪声操作可表示为: 8个测试函数的搜索范围,以及全局最优如表1所示。 表1 测试函数的搜索范围与全局最优 本次试验,通过与其它4种改进的粒子群算法进行对比来测试基于自适应选择的多策略粒子群算法的性能,这些算法的参数设置如表2所示。 表2 算法参数参数设置 PSO-w是最典型的一种粒子群改进算法,其惯性权重w是随迭代次数线性减小。CLPSO通过提高种群中的粒子多样性来提高算法对多峰问题的解决能力。ALPSO采用基于候选代的自适应学习策略与基于预测的竞争学习策略来平衡算法的探索与开发能力。 为了保证在对各个算法试验结果进行对比的公平,对试验的基本参数进行统一设置,如种群大小(PS)和最大适应值计算次数nfemax。在本次实验中,设置维度D=30,其对应的种群大小PS=20,最大适应值计算次数nfemax=100000。所有算法分别独立对测试函数进行30计算。 5种算法均独立对测试函数进行30次计算。对于每个测试函数,记录其30次计算的最优值f(xtest)与函数真正的全局最优值f(x*)差(即误差)的绝对值。5种算法对8个测试算法30次独立计算的误差平均值与方差如表4所示。表4数据括号内的值为误差的方差,括号外的值为误差的平均值。此外,在5个算法中,最优的值以加粗的形式来体现。 由表3可得,对于单峰测试函数(f1-f2),MPSO-AS的求解结果明显优于其它算法。第3个测试函数(f3)为复杂的多峰函数,虽然MPSO-AS的误差平均值要大于CLPSO,但是其方差较大,这个原因在于,MPSO-AS在30次求解第3个函数时,有21次找到了全局最优解0,但其它9次求解并未找到。CLPSO虽然误差均值要小,但在30次重复运行中,没有一次找到全局最优。同时,MPSO-AS对于另外一个多峰测试函数(f4)的均值方差均为零,这表明MPSO-AS在30次独立的求解后,每次都能在给定的计算量内找到全局最优。对于病态的测试函数(f5-f8)的测试结果可以看出,平移f5和噪声的操作对所有算法的求解精度都有所影响,但MPSO-AS求解结果依然优于其它算法。相比于其它算法,旋转操作的加入对MPSO-AS算法的求解影响较小。由于第6个函数(f6)和第7个函数(f7)分别是在第3个函数(f3)和第4个函数(f4)的基础上加入正交矩阵。可以从表4看出,MPSO-AS算法对第7个函数(f7)的求解结果和其对第4个函数(f4)的求解结果一样。相比于未加入旋转操作的第3个测试函数(f3)结果而言,对于第6个函数(f6),MPSO-AS的求解结果优于CLPSO的求解结果。 表3 12个测试函数的平均值与方差 在试验过程中,对于每个测试函数,每个算法在每次独立运算过程中随着适应值计算次数nfe的增加其最小的误差值均被记录。故可以根据误差值求得平均最小误差值error(nfe),通过平均最小误差值则可画出每个算法对于每个测试函数的收敛图。具体地,平均最小误差值error(nfe)可表示为 (9) 式(12)中xbest(nfe)为一次独立运行过程中适应值计算次数为nfe时算法求得的历史最优位置。f(x*)为该测试函数的全局最优解。 本次试验中,5种算法对8个函数求解的收敛图如图2所示。 图2 测试函数收敛图 由图2.(a)和图2.(b)可以看出,对于2个单峰测试函数,MPSO-AS的收敛速度随着迭代的进行不断加快,相比于其它4种算法,MPSO-AS的收敛速度有着显著的优势。对于f4多峰测试函数,MPSO-AS均在一半的适应值计算次数之后其收敛速度迅速变快,且在给定的适应值计算次数内收敛到全局最优。对于f3多峰测试函数,MPSO-AS收敛速度在中后期趋于平缓的原因如上文所述,在30次的求解中有几次并未找到全局最优。对于病态的测试函数 (f5,f6,f7,f8),MPSO-AS的搜索速度受平移、旋转和噪声的干扰并不大,其它算法如PSO-w在迭代中期进入阻滞状态,MPSO-AS算法在中后期仍保持较高的收敛速度。 本文通过建立策略池以及自适应选择机制,实现粒子在不同情况下能根据自身情况选择最佳的速度更新策略。试验表明,对于8个标准测试函数,MPSO-AS的收敛性能(收敛精度与收敛速度)比其它四种粒子群改进算法更好。3.4 算法复杂度
4 试验结果与分析
4.1 测试函数
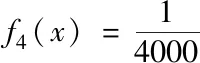
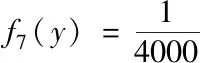

4.2 相关算法的参数设置

4.3 基于平均值与方差的对比
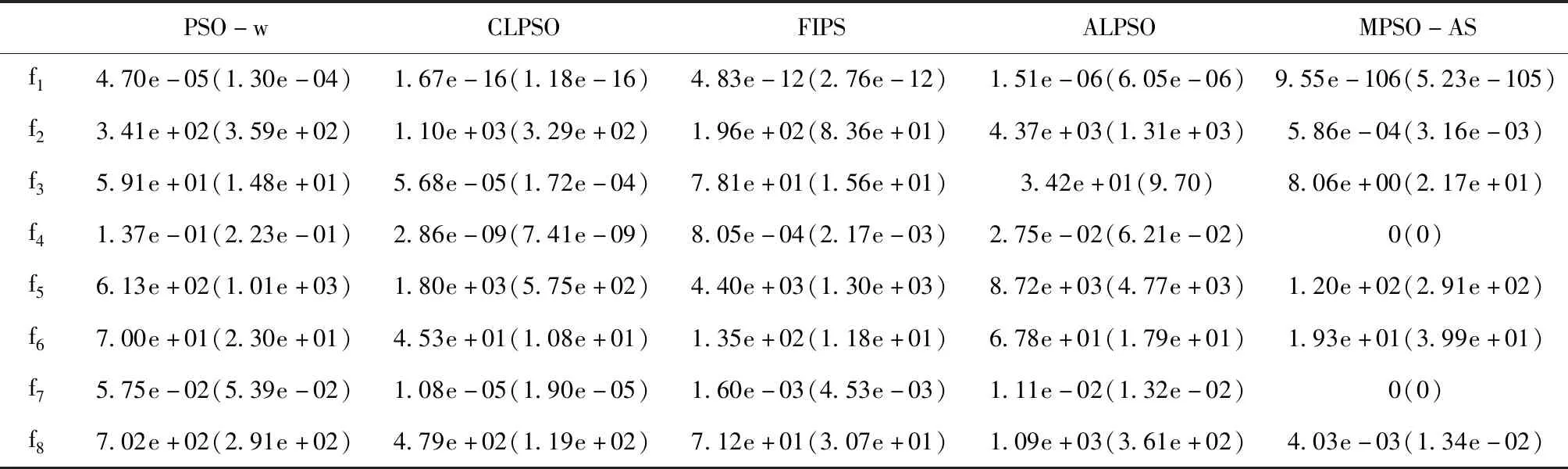
4.4 基于收敛速度的对比
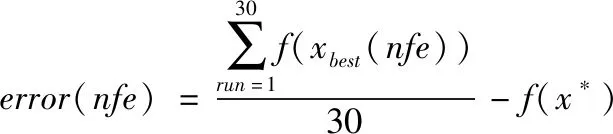
5 结论
