面向情感变化检测的语音情感数据库
2021-11-17张会云黄鹤鸣
张会云,黄鹤鸣*,李 伟
(1.青海师范大学计算机学院,青海 西宁 810008;2.藏文信息处理教育部重点实验室 青海 西宁 810008;3.青海省藏文信息处理与机器翻译重点实验室,青海 西宁 810008)
1 引言
随着语音识别技术的迅速发展,以计算机、手机、平板等为载体的人工智能研究日新月异。各种人机交互不再局限于识别特定说话人语音中的单一音素或语句,如何识别语音中的情感已成为ASR领域的新兴研究方向。语音不仅包含说话人所要表达的语义信息,也包含说话人蕴含的情感状态,对语音情感的有效识别能够提升语音可懂度,使各种智能设备最大限度理解用户意图,达到人性化水平,从而更好地为人类服务。
语音情感识别(Speech Emotion Recognition, SER)指利用计算机分析情感,提取出情感特征值,并用这些参数进行相应建模和识别,建立特征值与情感的映射关系,最终对情感进行分类。语音情感数据库是进行SER研究的基础。优质的语音情感数据库对SER系统性能的提升具有重要作用,所谓优质是指数据库中的每条语句都能真实确切地表达出说话人的情感状态。因此,多样化、大规模、高质量的语音情感数据库是保证SER顺利进行的第一步。
2 相关工作
SER系统包括语音情感数据的获取和预处理、语音情感特征提取与选择、声学模型训练以及分类决策4个阶段[1]。语音情感数据库相关内容第3部分会详细介绍,下面着重介绍语音情感特征提取与分类算法。
特征提取:SER是一项有挑战性的任务,对情感的识别依赖于语音情感特征分类的有效性。语音情感特征可分为语言特征和声学特征[2,3]。语言特征即语音所要表达的言语信息,声学特征则包含了说话人语气、语调,蕴含感情色彩。提取关联度高的声学特征有助于确定说话人情感状态。通常以帧为单位提取声学特征,并以全局统计方式作为模型输入参与情感识别[3]。全局统计指听觉上独立的语句或单词,如极值、方差、均值、最小值、最大值、峰度等。常用的声学特征包括韵律特征[4]、谱特征[5]和音质特征[6]。为了进一步提升识别性能,研究者也将基于人耳听觉特性的特征[7]、非线性动力特征[8]引入SER,见表1。

表1 基于语音情感的声学特征分类
表1给出了语音情感特征分类及其所包含的成分。通常来说,单一特征不能完全包含语音情感的所有有用信息,为了使SER系统性能达到最优,研究者通常将不同特征融合来提高系统性能。
分类算法:要对情感状态进行判断,首先要建立SER模型。识别模型是SER系统的核心。在识别过程中,情感特征输入到识别网络,计算机通过相应算法获取识别结果。常用SER分类方法有:极限学习机(Extreme Learning Machine, ELM)[9]、动态时间规整(Dynamic Time Warping, DTW)[10]、高斯混合模型(Gaussian Mixture Model, GMM)[11]、支持向量机(Support Vertor Machine, SVM)[12,13]、隐马尔科夫模型(Hidden Markor Model, HMM)[14]及人工神经网络(Artificial Neural Network, ANN)[15]等。
3 语音情感数据库
人的情感是通过面部表情、身体姿态、声音及生理信号等多种模态表现出来的[16]。情感判断可基于这些模态中的一个或多个进行,但单模态信息不全面、易受干扰,而多模态信息能够互相印证、互相补充,从而为情感判断提供更全面、准确的信息,最终提高情感识别性能。随着SER的发展,各种单模态、多模态语音情感数据库应用而生,根据语音属性将数据库归类,见表2。
表2根据语种差异、语音自然度、情感获取方式及情感描述模型将语音情感数据库归类,通常研究者立足于情感描述模型,即将情感划分为离散型情感和维度型情感进行研究。为了更直观地区分两类情感,表3进行了详细总结。

表2 语音情感数据库归类
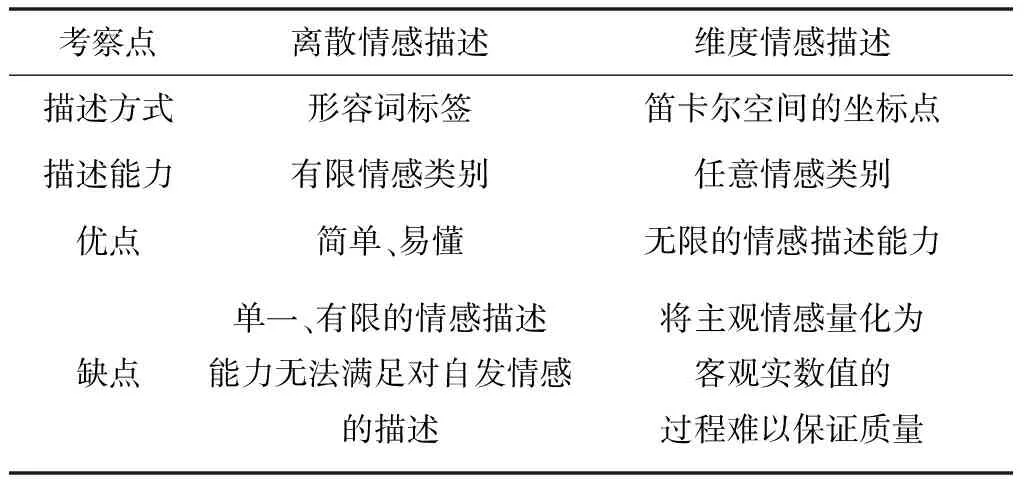
表3 两种情感描述模型的区别
由表3可知,离散型情感[17,18]指使用形容词标签将不同情感表示为相对独立的情感类别,多属于表演型或引导型,每类情感演绎逼真,能达到单一、易辨识的程度。维度型情感[18,19]通过唤醒维(Arousal)、效价维(Valence)、支配维(Dominance)等取值连续的维度将情感描述为一个多维信号,要求标注者将主观情感直接量化为客观实数值,如图1所示。其中,Arousal是对人生理活动/心理警觉水平的度量;效价维度量人的愉悦程度,情感从极度苦恼到极度开心互相转化;支配维指影响周围环境或反过来受其影响的一种感受。为了更完整地描述情感,研究者也将期望维(Expectation)、强度维(Intensity)加入维度描述模型[16,20]。期望维是对说话人情感出现的突然性度量,即说话人缺乏预料和准备程度的度量;强度维指说话人偏离冷静的程度[18]。
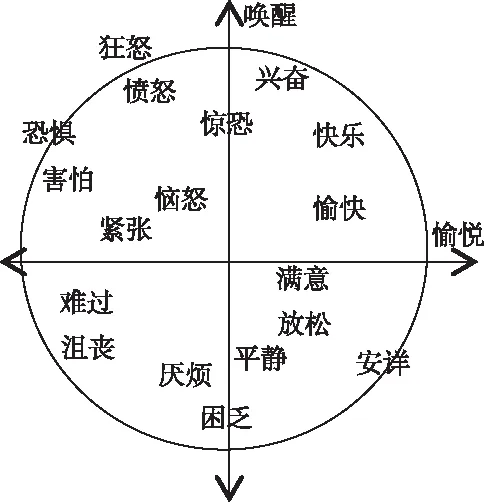
图1 愉悦-唤醒模型[8]
近年来,随着SER研究的顺利开展,研究者根据情感描述模型录制了相应的离散型语音情感数据库(见表4)和维度型语音情感数据库(见表5),所列的各类情感数据库大都公开或可以通过许可证授权得到。
由表4可见,大部分数据库都是通过表演方式采集。事实上采用自发语音情感更合理,但使用表演型情感数据库也有一定好处,可避免数据库包含过多无效标签数据。由表5可知,常用的维度型情感语料库主要有:VAM、DEAP、RECOLA、SEMAINE、IEMOCAP及CreativeIT,对于维度型情感库通常采用PAD量表进行情感信息标注。
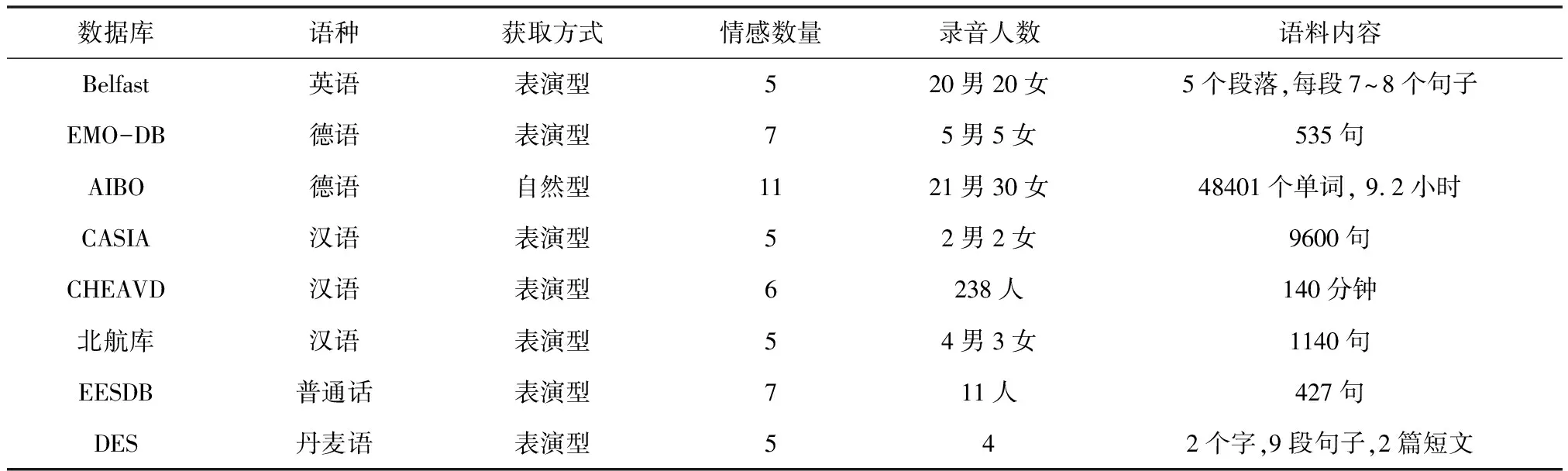
表4 常用的离散型语音情感数据库
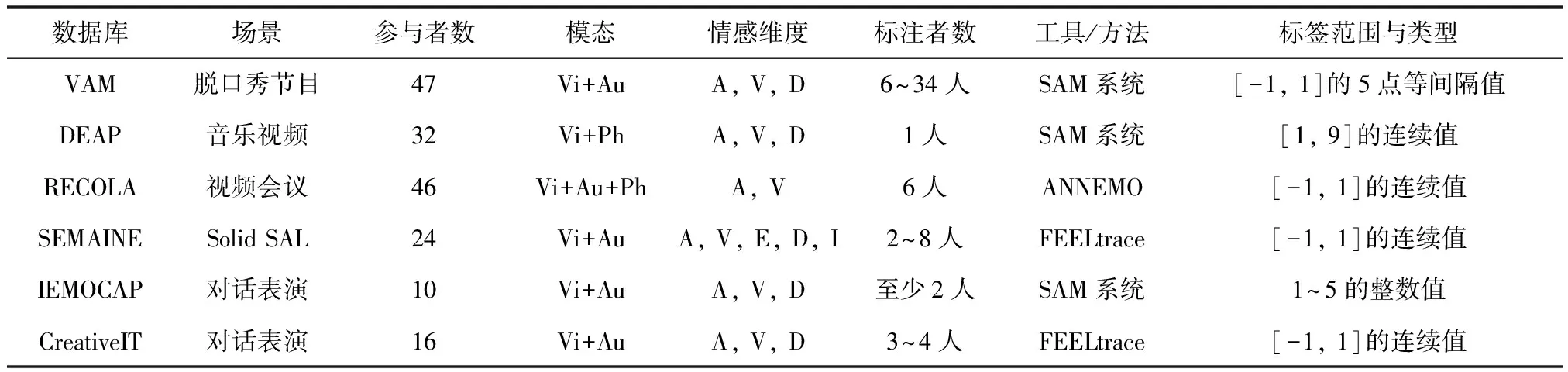
表5 常用的维度型语音情感数据库
3.1 单模态语音情感数据库
1)Belfast英语情感数据库
Belfast数据库[21,22]由Queen大学录制,包含40位说话人使用5类情感(生气/anger、悲伤/sadness、高兴/happiness、恐惧/fear和中性/neutral)演绎5个段落得到的语音。
2)EMO-DB德语情感数据库
EMO-DB数据库[23]是由柏林工业大学在专业录音室录制的,采样率为48kHz,压缩后16kHz,16bit量化。录制时从40个说话人中选取10位对10个德语语句进行情感演绎,包含中性/neutral、生气/anger、恐惧/fear、高兴/joy、悲伤/sadness、厌恶/disgust和困倦/boredom等7种情感,共800句语料,考虑到说话人语音自然度,最终选取535个样本,对应样本数量分别为79、127、69、71、62、46、81。部分文献中,研究者从535条语句中选出了494条,用于SER[24]。
3)AIBO自然语音情感数据库
AIBO数据库[25]包含了英语和德语两类语音。德语数据库[26]是由“MONT”、“OHM”两所学校录制的,对应样本数为:8258、9959。该库通过无线耳麦采集了51名(MONT 25,OHM 26)10-13岁的儿童与索尼公司电子宠物狗Aibo进行游戏交互时的语音,采样率为48kHz,压缩后16kHz,16bit量化。每条语音都有明显的情感倾向,共48401个单词,时长9.2h,数据库总样本18216条,由5位语言学专业学生通过投票方式标注情感,当3个及以上的标注者判定为同一种情感时投票通过。该库涵盖高兴/joyful、强调/emphatic、中性/neutral、溺爱/motherese、无聊/bored、惊讶/surprised、无助/helpless、易怒/touchy、愤怒/angry、谴责/reprimanding和含糊/rest等11类情感。目前关于情感标签仍无定论,最常用的标签方法有2种:5类情感,2类情感。5类情感包括:Anger(记作A,包含angry, touchy, reprimanding)、Emphatic(记作E)、Neutral(记作N)、Positive(记作P,包含motherese, joyful)、Rest(记作R),对应样本数分别为1492、3601、10967、889、1267;对于2类问题,类别为Negative(记作NEG,包含angry, touchy, reprimanding, emphatic)和Idle(记作IDL),样本数分别为5823和12393。该库33%的单词被INTERSPEECH 2009进行SER竞赛所用[27]。
英文库由30个儿童(4~14岁)录制而成,语音总共8.5个小时。
4)CASIA中文语音情感数据库
CASIA数据库[28]是由中科院自动化研究所在干净环境下录制的,包含4位专业发音人在6类情感(高兴/happiness、害怕/fear、悲哀/sadness、生气/anger、惊吓/scare和中性/neural)下演绎的9600条情感语音。采样率为16kHz,16bit量化。目前公开的CASIA库中,包含1200条语音,每类情感各200条语音。
5)丹麦DES情感语料库
DES数据库[29]包含两个单词(是,否),9句话和2个短句。情感类型有:高兴/happiness、伤心/sadness、中性/neutral、生气/anger和惊奇/surprise。通过20个年龄在18~58岁的本地人鉴定,识别率可达67%。
6)老人语音情感库EESDB
EESDB数据库[30]语音数据来自《老人的故事》。该库录制了11位说话人(6男5女)演绎的7类情感(高兴/happy、伤心/sad、中性/neutral、生气/angry、害怕/fear、惊奇/surprise、厌恶/digust),共992条语音,采样率44kHz,16bit量化。选取8位评估者对语音情感进行判定,若75%的评估者同时判定为相同情感则对其保留,最终保留了427条情感语音。
7)北京航空航天大学情感语料库
北京航空航天大学情感语料库是一个中文数据库[31],录制了7位说话人(4男3女)在20个文本下演绎的5类情感(愤怒/anger、高兴/happiness、悲伤/sadness、厌恶/disgust、惊讶/surprise),每个文本在相同情感下重复3次,经评估后,最终保留1140条情感语音。
8)Semaine数据库
Semaine[32]是一个面向AI与人机交互的数据库,可免费用于科学研究。该库是在专业录音室环境下进行人机交互录制的,录制时,20位说话人被要求与4位个性不同的(温和而智慧的/Prudence、快乐而外向的/Poppy、悲伤而抑郁的/Obadiah和怒气冲冲的/Spike)虚拟人物(由工作人员扮演)进行语音对话,该虚拟人物不仅能理解说话人表达的语义信息,与用户也有情感交流,录音长达7小时。由5个高帧频、高分辨率摄像机和4个麦克风共同釆集数据,采样率为48kHz,24bit量化。最后,在valence、activation、power、intensity和expectation等5个维度上进行标注。
9)TYUT2.0中文情感语音数据库
TYUT2.0数据库[33]是通过截取广播剧的方式获得的一种摘引型情感数据库,使用PAD(Pleasure-Arousal-Domaniance)情感量表对语音情感进行维度标注。在标注试验中,招募100名在校学生(44男56女)对3类情感(高兴/pleasure、悲伤/sadness、愤怒/anger)共161个语音样本按照范围为1~5的PAD量表进行维度标注,得到161×100维的数据样本,每个语音样本维度值取所有标注值的平均。
10)SUSAS英语情感数据库
SUSAS数据库[34,35]录制了7位说话人(4男3女)的3593条情感语音,主要用于分析压力级别,压力类别包括高压/high stress(hist)、中压/medium stress(meds)、中性/neutral(neut)、强压/screaming(scre),对应类别样本数分别为1202、1276、701和414。在Arousal维上neut为正,其它为负;在Valence上neut、scre为正,其它为负。
3.2 多模态语音情感数据库
1)IEMOCAP英语情感数据库
IEMOCAP数据库[36]是由美国南加州大学录制的,由10名演员(5男5女)在有剧本或即兴场景下诱发特定情感,包含音频、文本、面部表情以及视频。整个数据集划分为5部分,每部分均由1男1女表演组成。离散型和维度型情感标注都被应用于该数据库。离散型情感标签分为中性/neural、高兴/happiness、生气/anger和悲伤/sadness等,每类对应样本数量为:1708、1636、1103和1084,总计5531句(其中即兴表演包含2280句),时长约12小时。此外,IEMOCAP数据库也采用了valence、activation和dominance维度空间模型进行标注,维度幅值范围为[1, 5]。
2)RECOLA数据库
RECOLA数据库[37]录制了46位说话人(两人1组被分成23组,每组通过远程视频会议讨论某个灾难场景下逃生方案)的语音情感数据。数据中包含所有说话人在讨论过程中的面部视频和音频以及其中35个说话人的ECG、EDA数据。标注人员按照视频帧率逐帧给出了说话人前5分钟讨论过程中情感状态在valence和Arousal的值。
3)eNTERFACE’05英语情感数据库
eNTERFACE’05数据库[38]是基于面部表情和语音的双模态情感数据库,录制条件为办公室环境,带有一定回声,录制文本来自于故事,所有录制人员通过听取6个短片小故事,得到一种情感,通过两名专家最终确定语音是否符合要求。数据库采集了来自14个国家42位说话人(34男8女)的6类基本情感(生气/anger、厌恶/disgust、害怕/fear、开心/happy、伤心/sadness、惊讶/surprise),每类情感对应样本数量为:200、189、187、205、195和190。样本采用分辨率为80万像素的微型DV数字摄像机以25帧/秒的速度摄制,利用专用的高质量麦克风以16bit格式记录48kHz的未压缩立体音频信号,每个图片帧大小为720*576。
4)RML数据库
RML数据库[39]是基于面部表情和语音的双模态公开情感数据库,由加拿大Ryerson多媒体实验室录制,录制环境较为明亮,无嘈杂的背景音。采样率为44kHz,16bit量化。视频样本包含8位说话人表达的6类基本情感(生气/anger、厌恶/disgust、害怕/fear、开心/happy、伤心/sadness、惊讶/surprise),共720个语音和人脸情感。视频帧率为30帧/s,尺寸为720*480。每个视频持续时间为3~6s。
5)AFEW6.0数据库
AFEW6.0[40]并非是在实验室环境下建立的传统数据库,它是Emotion Recognition in the Wild(EmotiW)2016 challenge比赛提供的官方数据库,库中所有样本均为电影或电视剧剪辑片段且混有复杂的背景信息。该库中的视频样本包含7类情感,被划分为训练集(773个)、验证集(383个)和测试集(593个),训练集和验证集公开,测试集用于比赛评定,非公开。
6)GEMEP数据库
GEMEP数据库[41]包含语音样本集及其对应的视频样本集GEMEP-FERA[42],应用于INTERSPEECH 2013 Challenge[43]。数据库包含10位说话人(5男5女)的1260个样本,共18个情感类别(羡慕/admiration、愉悦/amusement、焦虑/anxiety、冷漠/cold anger、蔑视/contempt、绝望/despair、厌恶/disgust、兴高采烈/elation、暴怒/hot anger、兴趣/interest、恐慌/panic、恐惧/fear、乐意/easure、骄傲/pride、宽慰/relief、悲伤/sadness、羞愧/shame、惊讶/surprise、温柔/tenderness)。常用的情感有12类,平均每类约90个样本,共1080个样本。
7)ABC德语情感数据库
ABC双模态数据库[44]模拟了不同情境下公共交通中说话人的情感,是一个诱发数据库,含8位说话人(4男4女,25~48岁)的430条视频情感语音,时长11.5个小时,由3名专家对数据进行剪切,标定情感。其情感类别为:挑衅/aggressive、愉快/cheerful、陶醉/intoxicated、紧张/nervous、中性/neutral、疲倦/tired),对应样本数为95、105、33、93、79、25。
8)ACCorpus系列中文情感数据库
ACCorpus数据库[18]是由清华大学和中科院心理研究所合作录制,录音人数较多,是一个很全面、很系统、有代表性的数据库,采样率16kHz,16bit量化。包含5个子库,分别是:ACCorpus_MM多模态、多通道情感数据库、ACCorpus_SA汉语普通话情感分析数据库、ACCorpus_FV人脸表情视频数据库、ACCorpus_FI人脸表情图像数据库、ACCorpus_SR情感语音识别数据库。其中,ACCorpus_SR库录制了50位(25男25女)说话人在5类情感状态(中性/neural、高兴/happiness、生气/anger、恐惧/fear和悲伤/sadness)下的语音。
9)AVEC 2012数据库
AVEC 2012[45]是包含语音和视频的多模态情感数据库,来源于Semaine数据库中Solid-SAL的24条情感记录文件。曾用于2012年音/视频情感识别挑战大赛,被分为训练集、验证集和测试集。数据时长在7小时左右,标注工作由3~8个评估者借助标注工具FEELTRACE在Valence、Activation、Power和Expectation四个情感维度上标注。
10)VAM德语情感数据库
VAM数据库[46]是对德语电视谈话节目“Vera am Mittag”进行现场录制而成的,包括表情库、视频库、语音库3部分。语音库包含47位嘉宾947句语音,采样率为16kHz,16bit量化。在valence、activation和dominance维度上标注,标注值在[-1, 1]。
11)AVIC英语情感数据库
AVIC数据库[47]是一种双模态情感库,录制了21位(男11女10)产品推销员使用英语进行商业推广的语音和面部表情。样本情感类别为:无聊/boredom、中性/neutral、高兴/joyful,每类情感对应样本数量为553、2279、170,共3002个样本。
12)MOUD西班牙语情感数据库
MOUD模态数据库[48]采集了80位说话人(65男15女)的文本、语音和视频信息,共498个样本。其中样本情感标注分为3类:积极/positive、中立/neutral和消极/negative,每类样本对应数量为:182、85、231。
13)MOSI英语数据库
MOSI是2016年Zadeh团队开发出来的较大的一个多模态情感数据库[49],共采集了89位说话人(48男41女)的文本、语音和视频3个模态的信息,共2199个样本,说话人年龄主要集中在20~30岁。
14)SAVEE语音情感数据库
SAVEE模态数据库[50]是由4名演员在7种情感状态(生气/anger、厌恶/disgust、害怕/fear、高兴/happiness、中性/neutral、伤心/sadness以及惊讶/surprise)下演绎得到的表演型数据库,共480条情感,语音情感数量分布相对平衡,除中性(120条)外,其余6类情感均有60条。
15)CHEVAD中文自然情感数据库
CHEVAD数据库[51]是由中科院自动化研究所录制的,也是中科院自动化所举办的2017多模态情感识别竞赛的官方数据集,数据来自中文电影、电视剧及脱口秀节目,时长140分钟,说话人数达到238人,年龄范围从儿童到老人。由4名中国人标注数据,总共26个非原型情感状态,包含了常用的6类情感状态(愤怒/anger、恐惧/fear、高兴/happy、中性/neutral、悲伤/sad和惊讶/surprise),训练集、验证集和测试集中情感语音数量分别为:4917、707和1406。
16)DEAP数据库
DEAP数据库[52]录制了32位说话人观看音乐视频时的EEG信号、外围生理信号及其中22位说话人的正面视频。每个说话人都观看了40段音乐视频,并将自己在观看过程中所感受到的情感在唤醒维、效价维和支配维上给出了[1, 9]的连续自我评估。
4 实验
下面以SAVEE、RML、eNTERFACE05模态数据库为例,分析在不同数据库上使用不同分类方法所取得的最佳性能。
表6展示了2015~2019年在SAVEE数据库上使用不同分类方法所取得的性能。由表6可知,在SAVEE数据库上,目前结合多模态信息的SER系统最优性能可达到98.33%,这是一个非常客观的结果。

表6 SAVEE多模态库上不同方法性能比较
表7展示了2012~2019年不同研究者在RML模态数据库上的研究结果。由表7可知,目前RML数据库上各分类方法整体性能不是很好,2015年取得的最优性能为83%。
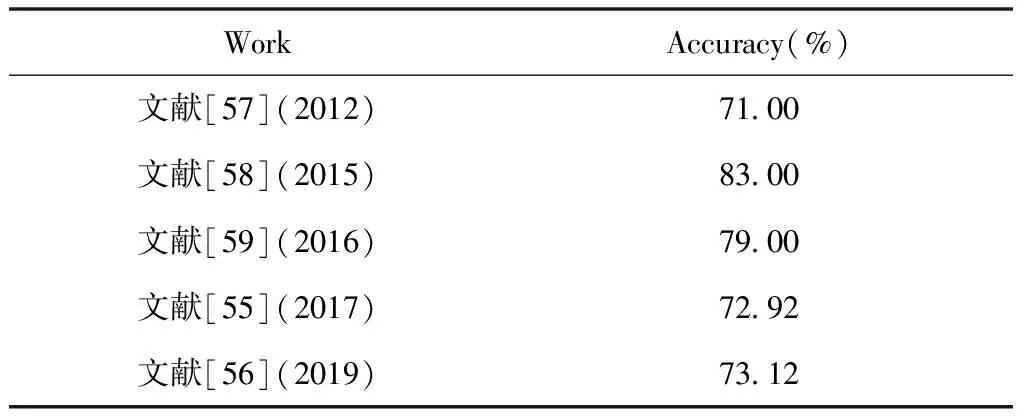
表7 RML多模态库上不同方法的性能比较
表8展示了2009~2019年部分研究者在eNTERFACE05模态数据库上的实验结果。由表8可知,文献[58]取得了最优的性能,其它各类方法的性能均较低。纵观表6、表7、表8,可以得出:在SAVEE数据库上目前各分类方法取得了最优性能,RML次之,eNTERFACE05数据库上性能最差。归因于eNTERFACE05库带有一定噪音,而RML模态数据库中的语料较为干净,SAVEE数据库是由专业演员录制的,对于每种情感的表达到位,数据库质量较好。
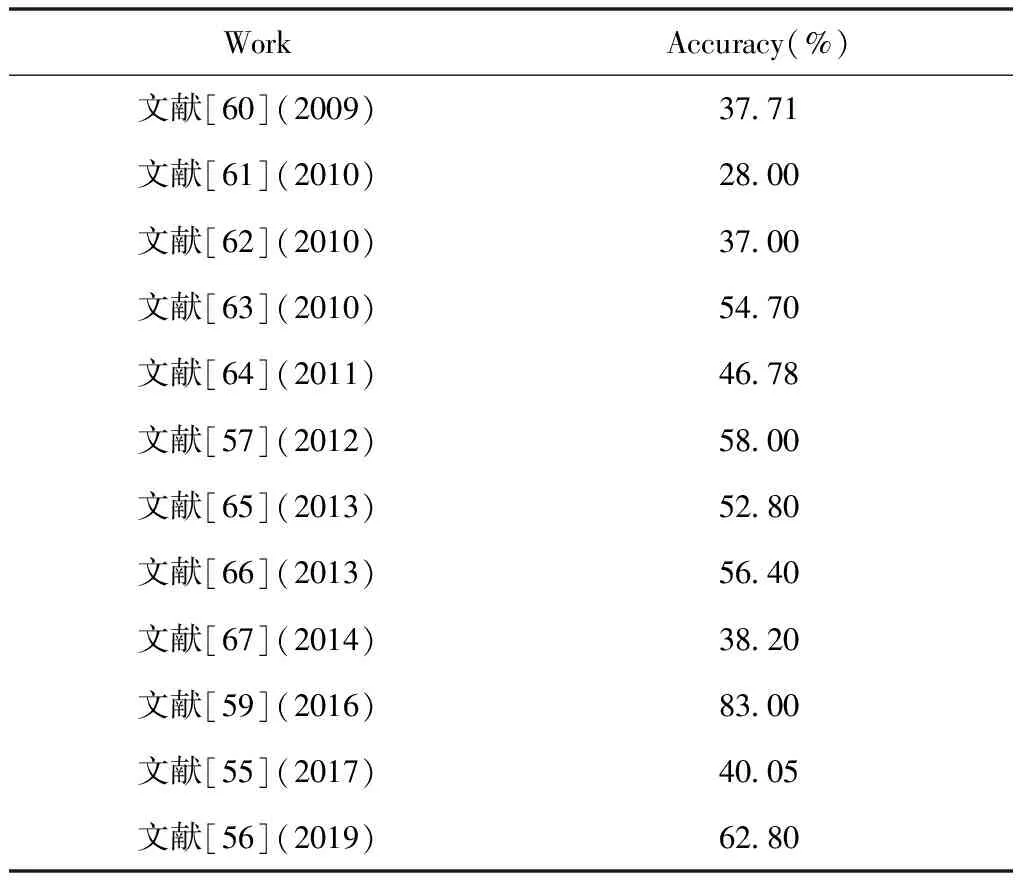
表8 eNTERFACE05多模态库上不同方法的性能比较
5 结论与展望
目前SER使用的数据库逐渐从表演型情感语料库向自然型情感语料库过渡,为了进一步提升SER的性能,研究者开始将多模态信息引入SER,通过将面部表情、文本信息、手语、生理信号等多模态信息与语音信息相结合以进一步提升性能。目前研究者聚焦在多模态数据库上进行研究,SAVEE、RML、eNTERFACE05是研究者常用的模态数据库。作者目前立足于藏语SER,为了确保其性能良好,应在干净环境下录制高质量、大规模的模态藏语情感库。
