基于改进SSD的道路交通标志检测
2021-11-01胡绍林张彩霞
黄 桥,胡绍林,张彩霞
(1.佛山科学技术学院 机电工程与自动化学院,广东 佛山 528000;2.广东石油化工学院 自动化学院,广东 茂名 525000;
0 引言
交通标志是自动驾驶和导航等领域的重要研究对象,其中交通标志检测是目标检测领域一个重要的方向,在无人驾驶和自主导航等领域有重要应用。应用最广的交通标志检测方法是基于视觉的方法。
交通标志种类繁多,我国常见的交通标志主要分为提示、禁止、警告等3种类型,本文以这3类交通标志为研究对象,进行自动检测。由于这3种类型的交通标志外观上有一定的差异,指示标志和禁令标志虽然大多都是圆形,但颜色有所不同;警告标志外观和颜色二者都不同。因此,可以根据这些共同特征,进行简单的分类。
传统的目标检测算法通常是先进行候选框的提取,候选框的提取通常采用滑动窗口的方法进行,然后是对每个窗口中的局部信息进行特征提取,最后对候选区域提取出的特征进行分类判定[3]。其中分类器包括Adaboost[4]、SVM[5]、Decision Tree[6]和DPM[7]特征等。对候选区域提取的特征进行训练分类操作需要人为设计,人工设计特征描述的方法需要巨大的工作量,比如DPM算法用来检测人的激励模板不能拿去检测小猫或者小狗,所以在每做一种物件的探测的时候,都需要人工来设计激励模板,为了获得比较好的探测效果,需要花大量时间去做一些设计。
综合上述分析,传统的目标检测方法更加适用于有明显特征,背景简单等理想的目标,且由于该方法是基于滑动窗口的区域选择策略,因此传统的目标检测方法针对性不足、算法耗时长、算法计算过程产生的冗余窗口太多、难以普及和对多样性变化的鲁棒性弱[5]等缺点。
在目标检测领域中,当前应用较广的交通标志检测是基于深度学习的方法,该方法的优点是获取的信息量大、成本低、容易普及[8]。相比传统的目标检测方法,深度学习目标检测算法适合对复杂多变下的抽象特征目标的检测[9]。目前,主流的深度学习目标检测算法主要分为两类:一类是two stage的方法,即先通过算法产生候选区域(region proposals),然后通过卷积神经网络对候选区域分类;另一类是one stage的方法[10],该方法不需要先产生候选区域再分类,它只需要一步就可以预测出目标的边界框,从而直接给出检测结果[11]。
1 SSD检测算法
1.1 SSD特征网络
SSD(single shot mulitbox detector)是Wei Liu[12]在ECCV2016上提出的一种基于卷积神经网络的目标检测算法。SSD算法相比Faster RCNN有明显的速度优势,相比YOLO又有明显的mAP(mean average precision)优势[13]。SSD作为one-stage类目标检测算法之一,它只用一个全卷积网络就完成了目标分类和定位任务[14]。其结构如图1所示。从图1中可以看出,SSD使用6个不同特征图检测不同尺度的目标。低层预测小目标,高层预测大目标。
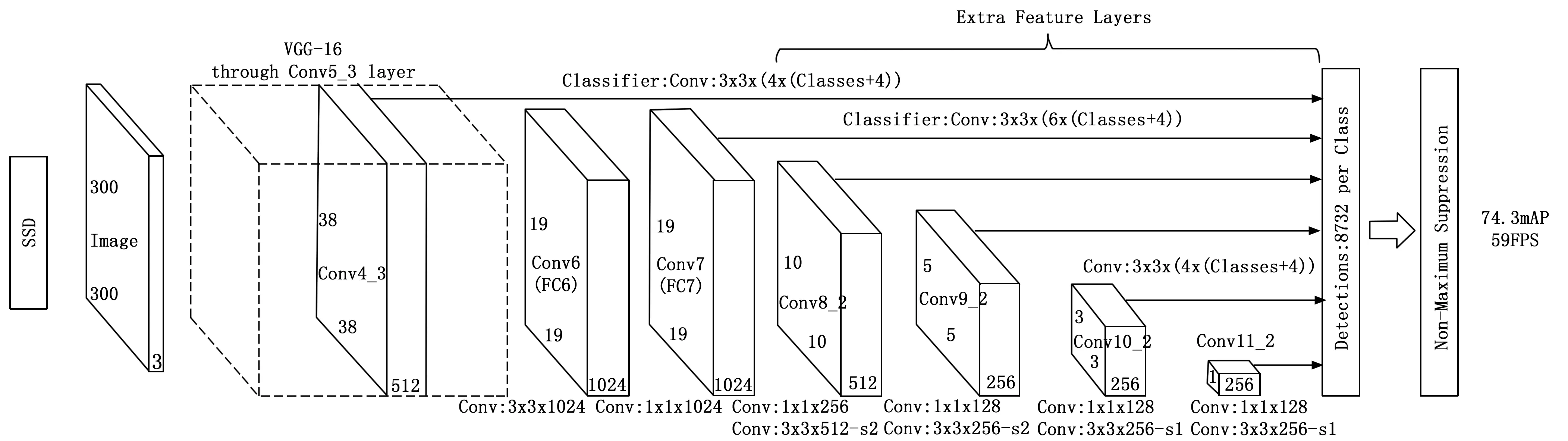
图1 SSD网络结构
目标检测算法中常见的特征提取网络有VGG16、DarkNet、MobileNet和ResNet。SSD采用了VGG16中的前5层网络,并把VGG16网络结构的两个全连接层FC6和FC7分别改成3×3和1×1的两个卷积层,这增加了新的卷积层来获取更多的特征图[15]。输入图像经过特征提取网络进行特征提取,并在各个卷积层中进行卷积和下采样等处理。最后通过非极大值抑制(NMS)得到算法的检测结果。SSD算法将输出设为300×300和512×512两种,用于不同尺寸图像的输入。本文讨论300×300为输入的情况。其中输入图像大小的规格应是长宽比例应为1∶1,若使用其他尺寸的图像训练模型,会引起图片畸变,模型自动缩放,影响精度。
1.2 SSD的Anchor机制
SSD结合多尺度特征图共同检测,其中大尺度特征图用来检测小目标,小尺度特征图用来检测大目标,尽量能够保证大小不一的目标都能够被检测到。因此SSD检测算法的结果理论上能达到较好的效果,主要有两个原因:第一是多尺度;第二是设置多种宽高比的锚框(anchor),即在特征图的每个像素点处,生成不同宽高比的anchor,根据具体情况设置宽高比[16]。假设每个像素点有k个anchor,需要对每个anchor进行分类和回归,其中用于分类的卷积核个数为ck(c表示类别数),回归的卷积核个数为4k。设置anchor机制的原因是每一层实际响应的区域其实是有效感受野区域,但在训练过程中并不知道有效感受野的大小,为了解决这个问题,提出了anchor技术。
1.1.1 入组标准 ①血清总胆红素水平≥342 μmol/L;②胎龄37~42周;③日龄1~28 d;④无明确严重的围生期高危因素;⑤出生时无窒息复苏抢救史;⑥本研究的实施已取得医院伦理委员会同意批准。
2 改进的SSD目标检测模型
SSD目标检测算法中,虽然理论上它的检测精度会随着网络的深度增加而提高,但在反向传播时梯度爆炸会导致简单堆叠的卷积层不能很好地训练网络[17]。换而言之,随着卷积神经网络层数的增加,训练集上的目标检测的准确率反而下降。交通标志复杂多变,存在不同环境下的背景,且采集的图像距离交通标志远近不一,当较远处的目标检测时,SSD算法并不一定能够检测出来。
2.1 特征提取网络的改进
为了提高对输入图像的特征提取能力,本文将残差网络引入到SSD模型中,将VGG16部分替换成ResNet50,构建SSD-ResNet网络结构,用50层网络拟合一个残差映射可以解决深层网络精度退化问题。用多个累积的非线性层拟合一个映射F(X),H(X)是目标最优解的映射,关系如式(2)所示:
F(X)∶=H(X)+X
(2)
此时,最优解映射H(X)与F(X)+X是等价的,图2所示为一个残差学习模块,根据该方式能将快捷连接实现。
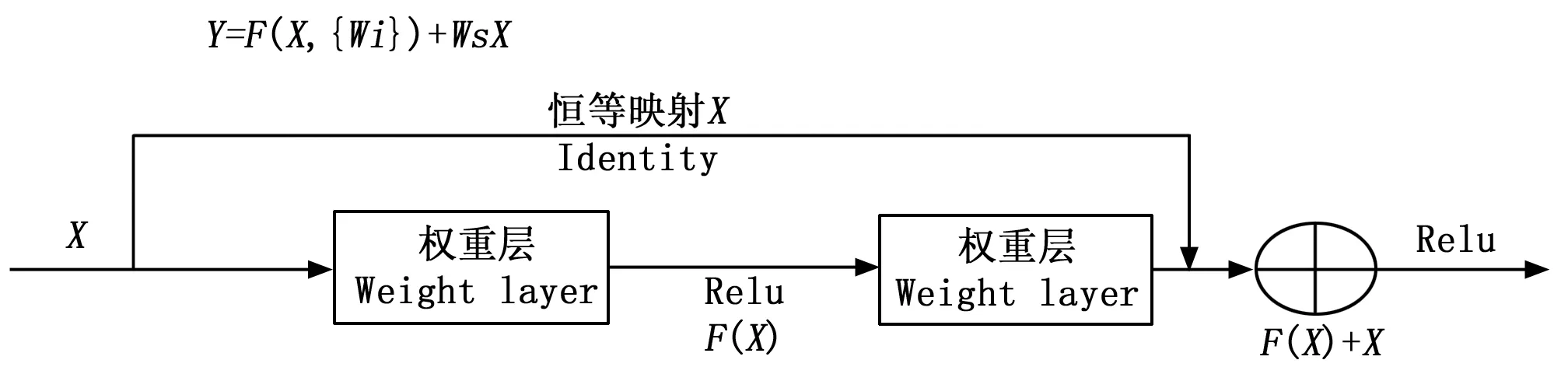
图2 残差学习模块
图2中的X代表模块的输入向量,Y代表模块的输出向量,Wi代表权重层参数,当输入和输出维度一致时,需要增加一个线性投影WS来匹配维度[18]。
残差学习模块往往需要两层以上,在实际计算中,为了考虑计算成本,对残差学习模块做了计算优化,即将残差学习模块中的两个权重层替换为3个不同的权重层。这两种不同的残差学习模块如图3所示。ResNet网络采用图3中这种跳跃结构来作为基本的网络结构,该跳跃结构又被称作Bottleneck,其中,图3(a)是使用于小网络的残差模块,图3(b)结构的1×1卷积用于降维,该形式的跳跃结构是适用于大网络的残差模块,本文采用的ResNet50网络属于大网络。

图3 两种残差学习模块
ResNet50总共有16个Bottleneck,每个Bottleneck包含3个卷积层,最后加上输入层的卷积层和最后的全连接层构成了50层的残差网络。添加深度残差网络的目的,是克服传统CNN网络随着层数加深到一定程度之后越深的网络反而效果更差的缺陷,避免因过深的网络引起分类准确率下降。如图4为残差网络替换VGG16后的网络结构图。
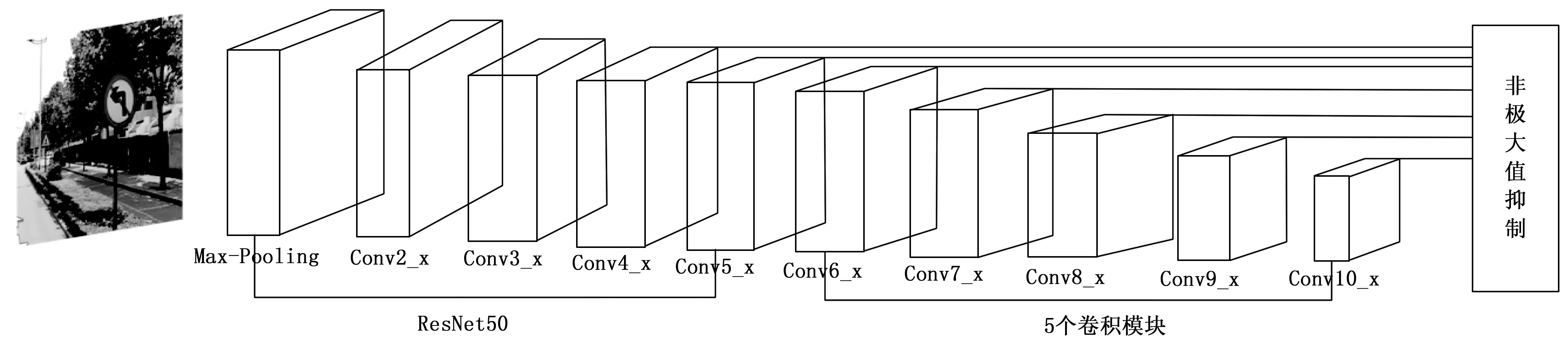
图4 SSD-ResNet50网络模型
以ResNet50作为提取网络,删除掉ResNet50后面的全连接层,再增添几层额外的卷积层提取特征,得到不同尺度的特征图,然后我们让这些不同层次的特征图分别预测不同大小的目标,浅层卷积层提取到的是比较细小的特征,越深层的卷积提取到的信息会越丰富,因此我们让浅层的卷积特征图去检测小的目标,让深层的卷积特征图去检测大的目标。该网络总共有65层,包括59个卷积层和5个池化层,每个经过池化层后输出的特征层,它的大小都会减小为上层输入大小的一半,最后的特征层输出为1×1。选择模型中Conv4_6、Conv5_3、Conv6_2、Conv7_2、Conv8_2、Conv9_2、Conv10_2,将这7种不同尺度的特征层用于预测交通标志,输出交通标志类别置信度和检测框偏移量,本文使用Jaccard Overlap策略匹配目标框,其中Jaccard Overlap的阈值设置为0.5,最后使用非极大值抑制[19]去除多余的预测框。
2.2 先验框的设计
原SSD算法对每一张特征图,按照不同大小和长宽比生成多个默认框,是基于多尺度的方法得到目标检测结果。对于不同尺度特征图,就会设置不同大小和宽高比的先验框,其计算见式(3):
(3)
其中:k的取值范围为[1,m],m为特征层数,Smin和Smax分别代表最小和最大特征层尺度,对应的默认值一般为0.2和0.9。中间特征层尺度均匀分布。
SSD算法默认的anchor的宽高比设定为:ar∈{1,2,3,1/2,1/3}。先验框的宽、高见式(4)和(5):
(4)
(5)
先验框生成之后,把不同尺度的特征输入到预测网络,然后进行预测计算,最后将输出的预测结果分为两部分。一部分是预测框的修正值,另一部分就是框内目标的概率。
在实际训练中,Smin和Smax的值往往需要多次尝试,本质上是盲目搜索的,这样会导致检测效率变差。为了更符合交通标志数据的特点,本文使用K-means++方法对目标框统计数据进行聚类,代替原SSD中生成的默认框基准大小Sk。
K-means++算法是随机从当前数据中选取一个样本作为初始聚类中心,然后计算每个样本与当前已有聚类中心之间的最短距离。本文先获取训练集样本,然后按照轮盘法选择总共K个聚类中心,针对目标框中每个样本,计算该样本到K个聚类中心的距离并将其分到距离最小的聚类中心对对应的类中,最后针对每个类别重新计算它的聚类中心直到位置不再改变。本文采用曼哈顿距离[20]来衡量相似度,依次选出它能更快地找到合理的先验框长宽比,对先验框重新设计,提高检测精度。
先验框的设置从尺度和长宽比等方面来考虑。先验框的尺寸有一个线性增加规律:随着特征图尺寸的减小,先验框尺度线性增加。图5为交通标志数据集的真实宽和高的聚类,交通标志的宽、高聚类中心大多聚集在[62, 86],[108, 150],[174,243]附近,宽高比大多在0.72左右,因此本文将特征图上每个滑动窗口的尺度生成宽高比为18∶25,在各个卷积层使用该比例大小的尺寸作为先验框的固定尺度,第一个先验框单独设置,为第二个先验框尺度的一半。另外,对先验框重新设计后产生数量比原来的先验框数量更少,提高了检测精度。

图5 真实框宽高聚类结果图
3 模型训练及结果对比分析
本文的交通标志数据集来源于现有的中国交通标志检测数据集(CCTSDB),图像的分辨率为600×600。用labelImg工具对其进行标注,生成PASCAL VOC数据格式。根据实际需求划分训练集、验证集和测试集,将数据集的60%作为训练集,剩下的数据集分为测试集和验证集,且两者的比例相同,因此测试集和验证集是相互独立的,这样可以确保后面的评价标准是可信的。利用验证集评估模型,找到训练过程中模型的最佳参数,然后采用该参数在测试集上进行测试。
为了提高关于目标大小和形状的鲁棒性,SSD采用了数据增强的随机采样策略。数据增强是为了在不降低检测精度的情况下提高算法的鲁棒性,不同数据集用到的数据增强的方法不同, 特定场景和实际应用中,一般很难收集满足各种条件的数据用于训练和测试, 因此许多目标检测算法都采用数据增强的方式来评估所设计的算法泛化能力,常用的数据增强方法包括水平翻转、平移、裁剪和颜色抖动等。本文对采集的自然环境下的图像数据进行数据增强操作以验证模型的泛化能力。
3.1 实验环境
本文使用PyCharm软件训练网络和测试模型,配置运行环境,计算机的配置为:Windows10 64位操作系统,处理器(CPU)型号为Intel i7,内存(RAM)为8 GB,显卡(GPU)是NVIDIA GeForce GTX。开发环境的软件配置及版本:Anaconda3、CUDA10.0、cuDNN7.6.3、Python3.7.6、TensorFlow-GPU1.14.0。
3.2 模型训练
为验证本文方法的有效性,训练改进前后的算法,并对比其模型评价指标结果。准备好交通标志数据集,为了提高模型的性能,对数据集进行数据增强和尺寸调整等预处理。然后利用labelImg图像标注工具,对图像中的目标画矩形框,得到xml格式文件,最后利用得到的文件制作所需要的数据集进行训练。经过反复训练,迭代次数达到10 000次左右,总损失值能达到最小并收敛,因此本文将训练次数设定为10 000次,初始学习率设为0.001。在训练前,加载VGG16或ResNet50的预训练模型,训练模型参数初始化,加载预训练模型是因为防止数据量过小出现过拟合现象[21],因为模型参数在开始都分布在一个性能强的范围之内,所以可以缓解过拟合,能够加快模型的收敛速度。
通过Tensorboard观察训练过程中每个类别的平均准确率(mAP, mean average precision)的变化,如图6所示,改进SSD算法的mAP值上升较快,且mAP值较高,都在0.9附近。
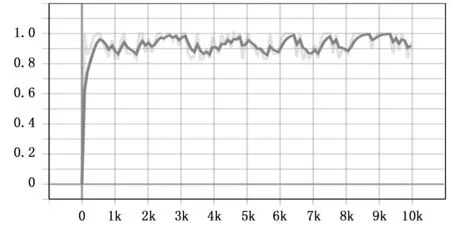
图6 改进算法mAP值变化图
3.3 检测结果对比
测试改进的SSD算法与原SSD算法可以比较它们的检测效果,其中有三组交通标志检测图像,分别是SSD算法检测结果,改进的SSD算法与原算法对比和改进算法的小目标测试效果。
图7为采用SSD算法训练模型检测到的结果,可以看出,直接采用SSD算法训练交通标志数据集得到的交通标志检测模型,各类别的交通标志图像检测的准确率较低。

图7 SSD检测示例图像
由图8可见,改进后的交通标志检测效果相较于未改进的算法定位更加准确。原算法中的定位与目标位置相差较大,而改进后的算法与目标位置吻合度较高。

图8 改进的SSD算法与原算法效果对比
图9为改进算法对较小的交通标志的检测,从图中的检测案例可以看出,较远距离的交通标志比较模糊且目标很小,原算法几乎不能检测出来,改进的SSD算法能够将小目标检测出来,且在准确率方面取得了较好的效果。

图9 小目标检测实例图像
上述实验结果显示,改进的SSD算法在检测精度和对小目标检测方面相比原算法效果更优。
3.4 检测精度对比
目标检测任务中,需要对模型进行评估,性能评估使用各种统计量如准确率(accuracy),精确率(precision),召回率(recall)等,其计算方法如式(6)和(7):
(6)
(7)
准确率即正确预测的目标数量除以总的目标数量;精确率是指在所有预测结果中,预测正确的数量和总的预测数量之间的比值;召回率则是测试集中所有的正样本被正确识别为正样本的比例。其中:TP(true positive)为算法预测的为真的正样本;FP(false positive)为算法预测为真的负样本;FN(false negative)为算法预测为假的正样本。
本文使用每个类别的平均准确率mAP作为算法性能的评价指标,mAP可以用来度量模型预测框类别和位置是否准确的指标。表1为改进SSD算法与其他算法的mAP值对比。其中SSD*表示改进的SSD算法。

表1 改进算法与其他算法的mAP值对比
从表1可知,改进的SSD检测算法的精度和速度均高于其他算法,因此可以说明提出的改进方案是有效的,且改进的算法适合对自然场景下交通标志的检测。
4 结束语
本文针对道路交通标志检测精度较低的问题,提出了一种改进的SSD目标检测方法,将原SSD算法中的VGG16特征网络替换为特征表达能力更强的ResNet50,并采用K-means++确定先验框大小,解决了原SSD模型随机确立先验框大小的缺点。
实验结果表明,本文改进的SSD算法训练的交通标志检测模型,在检测精度方面有所提高,弥补了原SSD算法在自然环境下对道路交通牌目标检测准确率低的缺点,提高了对远距离交通牌等小目标检测的识别率。本文所建立的道路场景下的交通标志检测方法具有理论参考和实际应用价值。
