编码计算研究综述
2021-10-13郑腾飞周桐庆蔡志平吴虹佳
郑腾飞 周桐庆 蔡志平 吴虹佳
(国防科技大学计算机学院 长沙 410073)
随着机器学习和大数据分析应用的涌现,相关数据集规模不断增长,分布式地执行应用的计算任务可有效整合资源、缓解计算压力.然而,分布式计算所需的频繁数据洗牌常导致较高的通信负载,等待计算速度缓慢或发生故障节点的响应还会引入计算延迟,而节点的可信问题进一步制约着分布式计算范式的应用和发展.
近年来,研究人员将编码理论应用到分布式计算领域,提出了一种新的计算框架——编码计算(code computing, CC),旨在借助灵活多样的编码技术,降低通信负载,缓解计算延迟,并抵抗系统中的拜占庭攻击,保护数据隐私.例如,文献[1]通过对分布式计算任务的中间结果进行异或编码,减少工作节点之间需要传输的信息数量和大小,以此显著减少通信负载.在另一个例子中,文献[2]利用纠删码对工作节点的任务进行编码,使得主节点能够从部分完成任务的节点中恢复最终结果,从而减少计算延迟.
鉴于其在通信、存储和计算复杂度等方面的优势,编码计算一经提出便引起研究人员的广泛关注,逐渐成为支撑有效分布式计算的热门研究方向.当前编码计算方案种类繁多、编码形式多样,有必要对当前方案进行总结和分析,以此为分布式计算、高性能计算、安全计算以及分布式机器学习、联邦学习的研究人员提供启发和思考.我们将本文和当前相关综述文献覆盖的编码方案进行了对比,如表1所示:

Table 1 Comparison of Existing Reviews on Coded Computing表1 已有编码计算相关综述文献对比
其中,文献[3]总结了利用编码技术改进分布式机器学习性能的研究进展,缺少对基于编码计算解决通信和安全隐私问题的总结和评述.同时,除分布式机器学习之外,在其他分布式计算场景中(例如,无线分布式网络、异构分布式网络、边缘计算网络)编码计算技术面临的挑战也不尽相同,本文结合技术分析对编码计算在多场景下的使用进行挖掘分析.另一方面,文献[4]的综述内容局限于对相关领域内一部分工作的细化阐述,缺乏对编码计算相关技术进展的细粒度对比和解析,参考价值有限.为满足分布式计算研究者灵活运用编码计算技术,构建更为实用的分布式计算应用(例如联邦迁移学习),尚且需要对涉及多场景,多类问题的编码计算架构与技术予以全面综述.
本文贡献为:据作者所知,本文首次相对全面地总结了编码计算的当前研究进展.首先,对编码计算的基本原理进行介绍,并对现有编码计算方案进行分类.根据不同的应用目标,本文将编码计算方案分为面向通信瓶颈、面向计算延迟、面向安全隐私3类.进一步,分别从这3个方向对现有编码计算方案进行了综述,重点包括:1)介绍分析了Master-Worker架构下的面向通信瓶颈的编码计算方案;2)根据不同的计算任务(矩阵乘法、梯度下降等),分别对面向计算延迟的编码计算方案进行了讨论和总结;3)从对抗恶意节点和防止数据泄露2方面分析总结了编码计算在分布式计算安全和隐私方向的研究进展.
1 编码计算概述
1.1 问题分析
分布式计算相关技术和理念已经在各种应用和场景中得以运用,然而,当在大量节点上分布式执行计算任务时,分布式计算系统将面临3个挑战:
1) 数据洗牌带来的通信瓶颈.数据洗牌是分布式计算系统的核心步骤,其目的是在分布式计算节点之间交换中间值或原始数据.例如,在MapReduce架构中,数据从Mapper被传输到Reducer.通过对Facebook的Hadoop架构进行追踪分析,平均有33%的作业执行时间都花费在数据洗牌上[5].在TeraSort,WordCount,RankedInvertedIndex和SelfJoin等应用程序中,50%~70%的执行时间用于数据洗牌[6].然而,在每一次数据洗牌过程中,整个数据集都通过网络进行通信.频繁数据交互带来的通信开销造成了分布式计算系统的性能瓶颈.
2) 掉队节点带来的计算延迟.分布式计算系统由大量计算节点执行计算任务,其中一部分工作节点的计算速度可能比平均速度慢5~8倍,甚至会出现未知故障[7],这类节点被称为“掉队节点(straggler)”.等待掉队节点的反馈会给整个计算任务造成不可预测的延迟[8],降低系统性能.
3) 安全和隐私.计算分布引入的另一个重要问题是计算/工作节点存在不可控,不可靠等问题.与传统集中式计算不同,分布式计算中的工作节点很可能是多个所有人的资产,这就使得数据输入到系统后访问面被动增加,导致数据的隐私受到威胁.例如,将涉及到用户个人健康情况的医疗数据分发到多个节点可能会造成隐私泄露.与此同时,拜占庭攻击是分布式系统面临的一个传统的安全威胁,节点提交错误信息将误导最终的计算结果,极大地影响系统可用性.
1.2 编码计算方案分类
由1.1分析可知分布式计算系统主要面临3个方面的挑战:1)数据洗牌带来的通信瓶颈;2)掉队节点造成的不可预测的延迟;3)系统安全和数据隐私.这三者严重制约着系统的扩展性和服务性能.为应对上述挑战,研究人员提出了一系列编码计算方案.根据各方案的主要功能和目标,可以相应地将编码计算方案分为3类:
1) 优化通信负载编码.以降低分布式计算系统的通信开销.优化通信负载编码方案通过增加额外的计算操作,创建编码机会,从而减少数据洗牌所需的通信负载.文献[1]是该方向的第一篇研究,其在分布式计算负载和通信负载之间实现了逆线性平衡——将计算负载增加r倍(即在r个节点上计算每个任务),则可以将通信负载降低r倍.随后,文献[9-12]将文献[1]方案分别扩展到无线分布式网络,多阶段数据流应用程序,计算任务密集型分布式系统和异构分布式网络中,有效降低了不同分布式计算场景下的通信负载.Attia等人[13]提出了一种用于分布式机器学习的近乎最佳的编码数据洗牌方案,得到工作节点不同存储方式下通信开销的最优下界.Li等人[14]提出了一种压缩编码分布式计算方案,相比于文献[1]方案进一步降低了分布式计算系统中的通信负载.Song等人[15]对索引编码方案[11]进行修改,并在此基础上提出了一种用于分布式计算系统的半随机柔韧性索引编码数据洗牌方案,该方案平均能节省87%的传输开销.
2) 最小化计算延迟编码.以减轻分布式计算系统的掉队节点导致的延迟弊端.最小化计算延迟编码计算方案能够在计算负载和计算延迟(即整个作业响应时间)之间进行逆线性平衡.换言之,该方向的编码计算方案利用编码来有效地注入冗余计算,以此来减轻掉队节点的影响,并通过注入与冗余量成比例的乘法因子来加速计算.Lee等人[2]利用最大距离可分码(maximum distance separable code, MDS码)首次解决分布式矩阵-向量乘法中的延迟问题,并且降低了分布式机器学习算法中数据洗牌的通信成本.和文献[2]目标一致,文献[16-18]分别提出了不同的编码计算方案,以降低分布式矩阵-向量乘法中的计算延迟.除此之外,针对其他分布式计算任务如矩阵-矩阵乘法[19-23]、梯度下降[24-29]、卷积计算、傅里叶转换[30-31]和非线性计算[32]等中的计算延迟,研究人员也提出了相应的编码计算方案.
为了处理异构分布式计算系统中的掉队节点,必须考虑到为异构节点设计负载平衡策略[33-38],以最大程度地减少总体作业执行时间.考虑到分布式计算系统中掉队节点的动态性,如何有效地利用掉队节点所做的计算结果优化计算延迟也引起了研究人员的广泛关注[39-43].
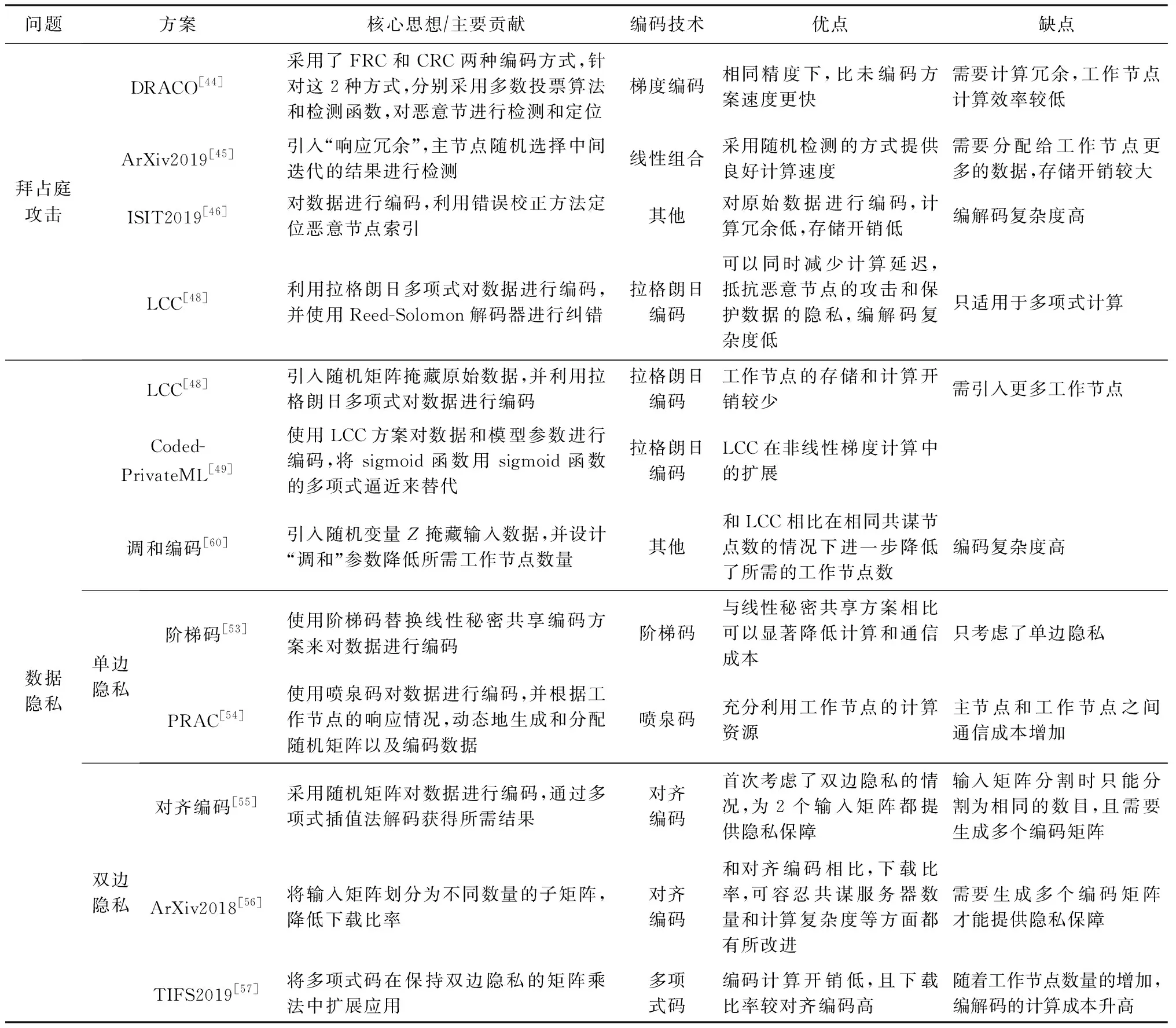
3) 安全和隐私编码.为分布式计算系统提供安全的计算过程.为抵抗梯度下降中的拜占庭攻击,Chen等人[44]利用编码理论的思想提出了DRACO编码计算方案.Gupta等人[45]利用“响应冗余”,可在梯度聚合时检测出计算错误的节点.Data等人[46]通过对数据进行编码,基于错误校正[47]设计了一种抗拜占庭攻击的分布式优化算法.Yu等人[48]提出一种拉格朗日编码计算(Lagrange coded computing, LCC)方案,该方案对输入数据进行编码,不仅可以减少计算延迟,而且可以抵抗恶意节点的攻击,保护数据隐私.作为LCC的扩展,So等人[49]提出了一种快速且具有隐私保护功能的分布式机器学习框架——CodedPrivateML. Nodehi等人[50]将多项式码与BGW方案[51]结合在一起,提出了一种多项式共享方案.随后,针对矩阵乘法,研究人员分别提出了单边隐私[52-54]和双边隐私[55-58]的编码计算方案.文献[59]针对边缘计算架构中源节点、工作节点、主节点不同的隐私需求设计了相应的编码计算方案.
表2按照分类思路列出了代表性工作,将在第3~5节详细介绍,分析各分类的典型工作.

Table 2 Classification of Coded Computing Schemes表2 编码计算方案分类
1.3 编码计算定义
编码计算目前还未有一个严格的统一的定义,为简要说明编码计算的思想,列举2个示例:
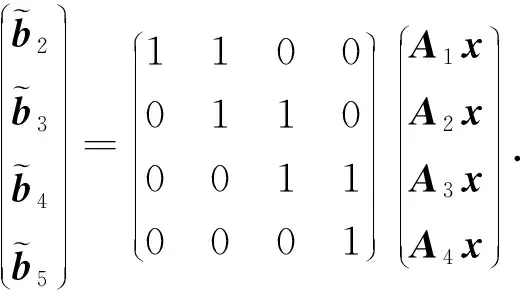
示例1.降低通信负载编码[2].假设一个分布式计算系统具有2个工作节点和1个主节点,现有一个大数据矩阵被分为4个子矩阵,即A1,A2,A3,A4,分别存储在节点W1和W2中,如图1(a)所示.其目标是主节点将A3传输至W1,并将A2传输至W2.可以设计这样一种编码,使主节点发送多播编码信息A2+A3到2个工作节点,后者使用本地已存储的数据便可解码获得所需的数据.显然,与未编码的数据洗牌方案相比,编码方案可降低50%的通信开销.
示例2.减少计算延迟编码[2].接下来考虑另一个简单例子,图1(b)展示一个具有3个工作节点和1个主节点的分布式计算系统,其目标是计算矩阵乘法AX,其中A∈q×r,X∈q×r.数据矩阵A被划分为A1和A2两个子矩阵.可以这样设计编码,在进行计算任务分配前,由主节点对子矩阵进行编码生成数据A3=A1+A2.而后,主节点将A1,A2,A3分别分配给W1,W2,W3.当工作节点接收到矩阵X时,每个节点将X与存储的数据相乘,并将计算结果返回给主节点.通过观察可知,主节点在接收到任意2个工作节点的结果时都可以恢复最终结果AX,而不用等待最慢的节点(掉队节点)响应.

Fig. 1 Simple example of coded computing图1 编码计算简单示例
值得注意的是,示例1为了在传输数据时可以进行编码,引入了冗余,即节点W1和W2分别额外存储了数据A2和A4.示例2同样引入了冗余——给W3分配了额外的计算任务(A1+A2)X,以此使得分布式计算系统可以容忍1个掉队节点的存在.由此可见,编码计算的核心思想是注入并充分利用分布式计算系统中的数据或计算冗余.本文将编码计算定义如下:编码计算是利用编码理论注入冗余,通过对存储-通信-计算的权衡,从而解决或缓解分布式计算系统中通信瓶颈,计算延迟,安全和隐私等问题的一系列技术手段.
2 面向通信瓶颈的编码计算
近年来,研究人员对Master-Worker分布式计算架构下的数据洗牌问题进行了大量研究.其中根据主节点是否参与运算及存储数据,Master-Worker架构可分为Map-Reduce和典型Master-Worker两种略有区别的分布式计算架构.而在这2种不同分布式计算架构下的数据洗牌编码方案也不尽相同.因此,在第2.1和2.2节,将分别对基于Map-Reduce和典型Master-Worker的数据洗牌编码计算方案进行介绍和分析.
2.1 基于Map-Reduce的数据洗牌编码计算
MapReduce是一种编程范式,可以并行处理海量数据集.在MapReduce架构中,主节点不参与运算,且不存储数据,只为各工作节点协调分配不同的输入数据.更具体地说,在MapReduce中整个计算被分解为“Map”,“Shuffle”和“Reduce”3个阶段.在Map阶段,工作节点根据设计的Map函数使用输入数据来计算中间值的一部分;在Shuffle阶段,工作节点相互交换一组中间值;在Reduce阶段,工作节点计算并输出最终结果.针对Map-Reduce架构,研究人员通过将子数据集映射到多个工作节点,并仔细设计放置策略,以创建编码机会.编码计算利用该机会将各工作节点计算的中间值进行异或编码,然后将编码信息广播给其他工作节点,以此降低通信负载.
2.1.1 通用数据洗牌编码方案
针对Map-Reduce架构,Li等人[1]提出了编码分布式计算(coded distributed computing, CDC)方案,并在后续工作中将CDC方案扩展到无线分布式计算系统[9]、多级数据流[10]和TeraSort排序算法[61]等.这里结合图2所示计算用例概述CDC方案的基本思路.
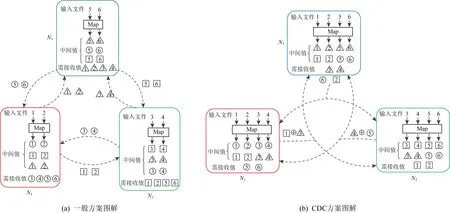
Fig. 2 Data shuffling between general scheme and CDC图2 一般方案和CDC方案数据洗牌对比
假设客户端需从6个输入文件中计算3个输出函数,分别用圆形、正方形和三角形表示,计算任务由节点N1,N2和N3协同完成.每个节点计算唯一的输出函数,例如N1计算圆形函数,N2计算方形函数,N3计算三角形函数.
在计算上不加冗余时,如图2(a)所示,如果每个节点在本地存储2个输入文件,这样便可在本地生成6个所需的中间值中的2个.因此,每个节点需要从其他节点接收另外4个中间值,产生的通信负载为4×3=12.
如图2(b)所示,CDC使每个输入文件映射到2个节点.显然,由于执行了更多的本地计算任务,因此每个节点现在仅需要2个其他中间值,此时的通信负载为2×3=6.由于每个节点计算出了更多的中间值,因此在数据洗牌时便有了编码的机会.CDC将每个节点处生成的2个中间值进行异或编码,并多播到另外2个节点,此时的通信负载为3.因此,CDC产生的通信负载比没有计算冗余的情况下的通信负载降低了4倍,比未编码的数据洗牌方案低2倍.可见,这样以计算换通信的方式可有效降低洗牌时的传输开销.随后,文献[1]从数据映射、计算、数据洗牌和归约4个阶段对CDC的一般化过程进行了形式化定义.
CDC关注的是由MapReduce驱动的通用框架中的通信流,并且适用于任意数量的输出结果、输入数据文件和计算节点,不要求计算函数具备任何特殊性质(如线性).
2.1.2 有领域知识的数据洗牌编码方案
Li等人[9]将CDC方案推广到无线分布式计算系统,设计了一种无线分布式编码计算(coded wireless distributed computing, CWDC)的框架.CWDC由上行链路和下行链路2部分组成,每个用户在上行链路发送2个中间值的异或值至接入点,如图3(a)所示.然后接入点无需解码任何单独的值,只需生成接收到的消息的2个随机线性组合C1(·,·,·)和C2(·,·,·),并将它们广播给用户,即可同时满足所有的数据请求,如图3(b)所示.图示编码方法中上行链路通信负载为3,下行链路通信负载为2.
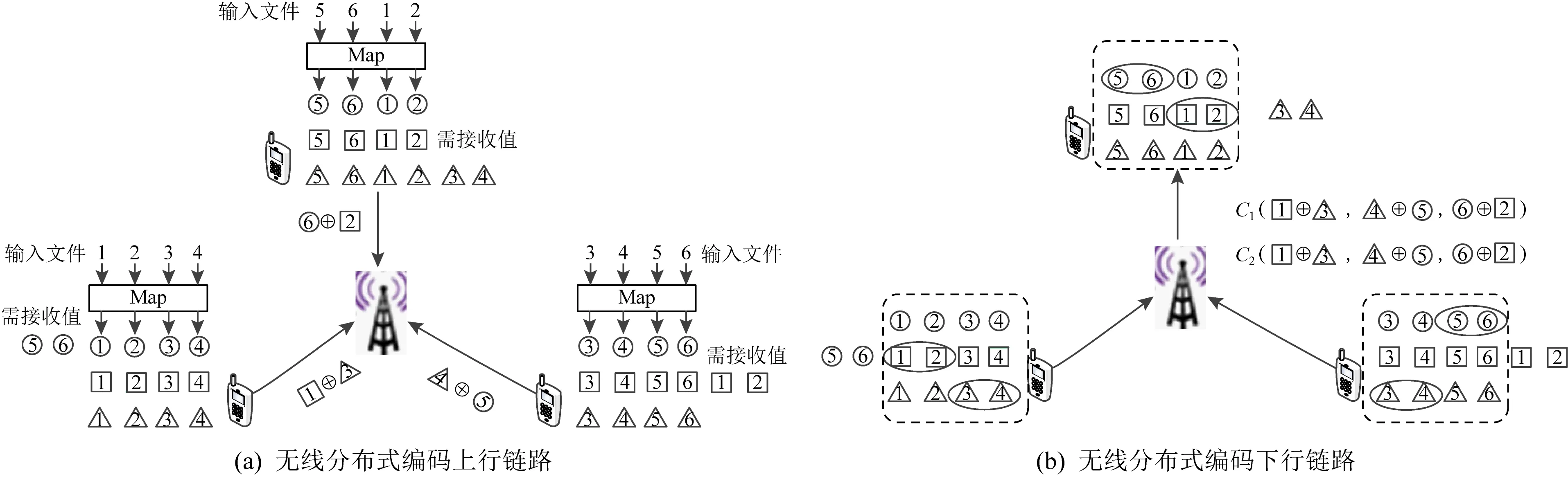
Fig. 3 The diagram of data shuffling in CWDC coded scheme图3 CWDC编码方案数据洗牌图解
对于具有K个用户的无线分布式计算应用程序,假设每个工作节点可以存储整个数据集的μ(0<μ≤1)倍,所提出的CWDC方案的通信负载为

(1)
与未编码方案相比,CWDC可将通信负载降低μK倍,并且其通信负载是固定的和工作节点数量无关.
许多分布式计算应用程序包含多个MapReduce阶段.例如机器学习算法[62]、数据库SQL查询[63-64]和数据分析[65].基于此,Li等人[10]为多阶段数据流应用程序形式化定义了分布式计算模型.其将多级数据流表示为一个分层的有向无环图(directed acyclic graph, DAG),在这个DAG中,每个顶点代表一个MapReduce类型计算,方案通过对每个顶点实施CDC编码策略,有效降低通信负载.
CDC中的一个隐含假设是每个服务器对存储在其内存中的所有文件执行所有可能的计算.然而,当工作节点需要执行计算密集型任务时,可能没有足够的时间来执行所有计算.针对这种情况,Ezzeldin等人[11]在CDC方案的基础上提出了一种分割编码计算(spilt coded distributed computing, S-CDC)方案.作者通过给定节点的计算能力阈值,从而得出相关通信负载的下限,并基于CDC提出一种启发式方案,以达到该通信下限.
在文献[61]中,作者将CDC的思路应用于Tera-Sort排序算法,并设计了一种名为CodedTeraSort的新分布式排序算法,该算法在数据中施加结构化冗余,以在数据洗牌阶段创造有效的编码机会.作者通过实验评估了CodedTeraSort算法在Amazon EC2集群上的性能,与传统的TeraSort相比,Coded-TeraSort速率高1.97~3.39倍.
2.1.3 线性假设下的数据洗牌编码方案
在没有进一步假设的情况下,CDC[1]实现了最优的计算和通信负载之间的平衡.然而,工作节点计算的函数通常有一些结构,利用这些结构可以进一步降低通信负载.
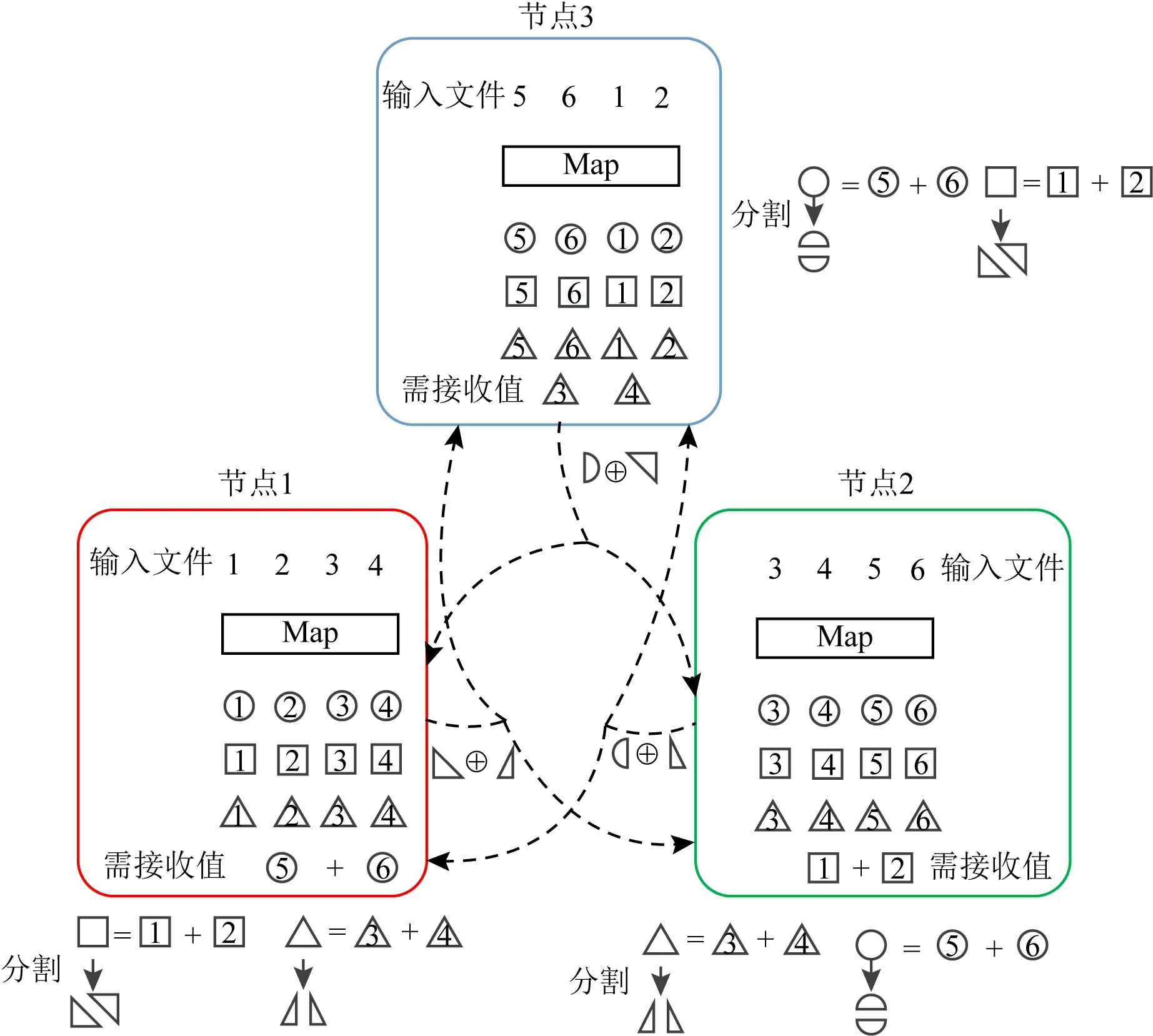
Fig. 4 The diagram of data shuffling in CCDC图4 CCDC编码方案数据洗牌图解
在Reduce阶段是线性聚合的假设下,Li等人[14]将压缩技术和CDC相结合提出了一种压缩编码分布式计算(compressed coded distributed computing, CCDC)方案.考虑如图4所示的分布式计算场景,假设最终计算结果是计算各中间值之和,则可以在发送节点上预先组合相同函数的中间值以减少通信.
例如,节点1将两对中间值相加以生成2个分组,然后将每个分组(正方形和三角形)分割为2段,并取各自的一段逐位进行异或,以生成大小为中间值一半的编码数据.最后,节点1将该编码数据多播到节点2和3.节点2和3处执行类似的操作.
最后,每个节点可以利用本地已有的中间值来解码获得所需的数据.该编码方案可用于需在最后阶段对中间结果线性聚合的分布式机器学习中.
Horii等人[66]指出在Map阶段计算的中间值可以看作是2中的向量.假设工作节点发送的向量数为r,由这些向量构造的线性子空间的维数可能小于r.例如,在计算大量文档中的单词数时,工作节点计算的许多中间值是相同的,并且中间值的一些线性组合也是相同的.Horii等人基于这个观点和假设,在编码时让工作节点发送中间值的线性子空间的基和线性组合系数,从而进一步降低通信负载.
2.2 基于典型Master-Worker的数据洗牌编码计算
与Map-Reduce架构不同,在典型Master-Worker计算框架中,主节点可以访问整个数据库,并且只有主节点可以发送数据,而各工作节点之间无法进行通信.主节点在每次迭代中将整个数据集排列划分为多个子数据集,并将每个子数据集传输到相应的工作节点,以便工作节点执行本地计算任务.工作节点在完成计算后将结果返回给主节点.典型Master-Worker架构下的编码计算方案可分为数据洗牌和存储更新2个阶段.在数据洗牌阶段,主节点将整体数据分为大小相同的子数据集,并将子数据集的编码信息广播发送给工作节点,每个工作节点从主节点广播的编码信息和本地存储的数据中恢复出下次迭代所需的数据.在存储更新阶段,每个工作节点存储新分配的数据单元并更新存储结构以实现下次迭代的数据洗牌.值得注意的是,在编码计算方案中工作节点需额外存储一些关于其他数据单元的信息.编码计算将此类附加数据进行仔细设计,以帮助在下次迭代时从编码信息中解码所需数据.
Lee等人[2]首次提出了典型Master-Worker分布式计算架构下的编码数据洗牌方案,旨在提高分布式机器学习算法的训练速率.假设数据集一共有q个数据行,工作节点数为n,每次迭代时将数据集随机均匀的分配给各个工作节点,则每个工作节点需要处理q/n个数据行.假设每个工作节点的内存大小为s(s>q/n)个数据行,由此可知工作节点在每次算法迭代时除了存储计算任务所需的q/n个数据行外,还有额外s-q/n个数据行的存储空间.文献[2]充分利用这部分存储空间,让每个工作节点从剩余的数据行中随机均匀的选择s-q/n个数据行进行存储,形成“侧信息”.在数据洗牌时,主节点利用异或编码的方式将数据集编码,并将编码信息广播至各工作节点.各工作节点利用“侧信息”完成解码,获取下次迭代所需数据.Lee等人通过实验表明在n=50,q=1 000,s/q=0.1时,用于数据洗牌的通信开销减少了81%.因此,在缓存的存储开销非常低的情况下,与未编码方案相比可以显著地降低分布式系统的通信开销.
在给定一组数(K,N,S)(K为节点数,N为文件总数,S为每个节点的存储大小)的情况下,Attia等人[67-68]刻画了每个工作节点存储容量与最大通信负载之间的关系.具体来说,在文献[67]中,针对工作节点数K={2,3}的情况,Attia等人将最大通信负载描述为一个关于可用存储的函数.在文献[68]中,Attia等考虑了无多余存储的情况(即,S=N/K),表明即使对于最小存储值,编码机会仍然存在.然而,该方案的参数不能取任意值.
随后,Attia等人[13]在编码缓存方案[69-70]的启发下,提出了一种新颖的编码数据洗牌方案,该方案基于一种保持存储结构不变的存储/更新过程,称为“结构不变的放置和更新(structural invariant placement and update, SIP/SIU)”.
SIP/SIU和文献[2]类似,工作节点除了存储必要的处理数据外,需额外存储一些附加数据,如图5所示.和文献[2]中随机存储分配不同,SIP/SIU以一种确定性和系统化的存储更新策略创造了更多的编码机会.
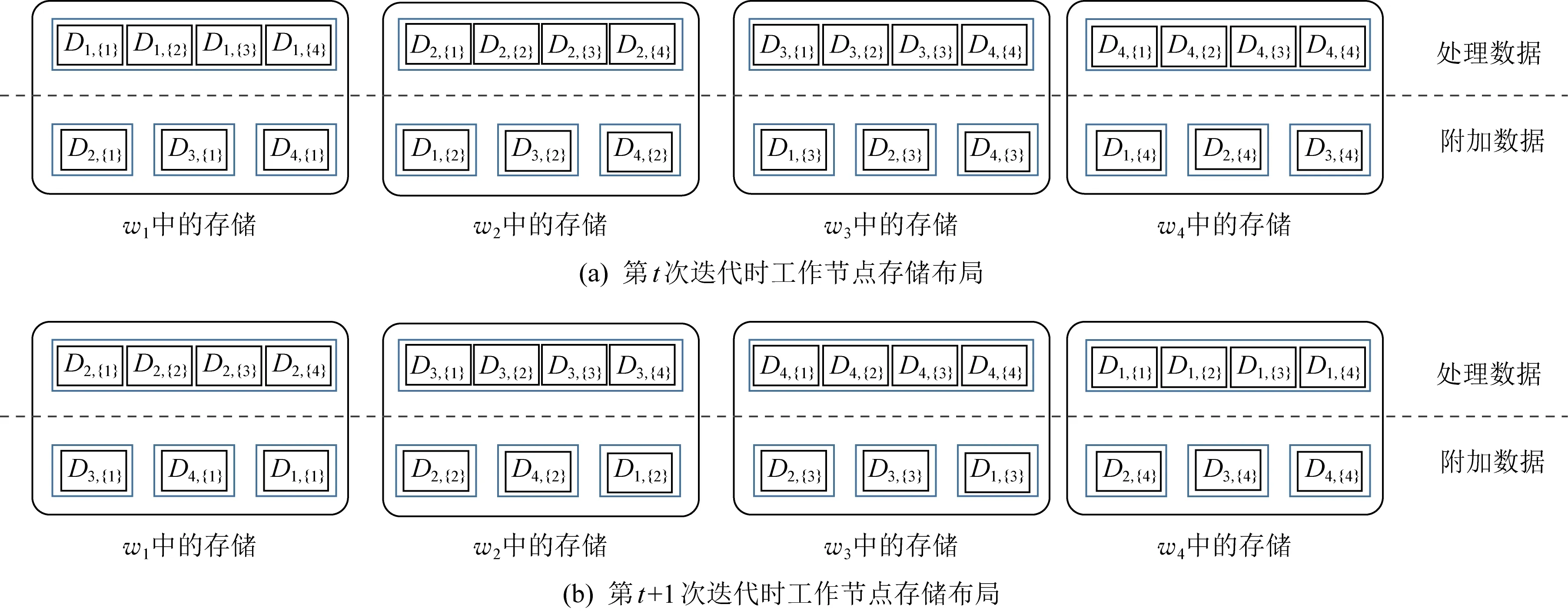
Fig. 5 Storage of work nodes in SIP/SIU图5 SIP/SIU方案中工作节点的存储布局
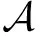

(2)

Fig. 6 Storage of work nodes and the processes of storage update in [71]图6 文献[71]中工作节点存储布局及更新过程
Attia等人通过数值模拟实验表明,对于具有较大存储容量工作节点的分布式计算系统,文献[13]要优于文献[2]中的编码方案,并且具有较低的计算复杂度.
Elmahdy等人[71]基于SIP/SIU方案提出了一种不同的编码洗牌方案,并证明了当文件数等于工作节点数时,其编码数据洗牌方案是最优的.以K=4(w1,w2,w3,w4)个工作节点的分布式计算系统为例,简要说明该方案.设有4个输入文件N=4,分别命名为A,B,C,D,每个工作节点的内存大小为S=2个文件.不失一般性,假设w1,w2,w3,w4在第t次迭代时正在处理的文件分别为A,B,C,D.
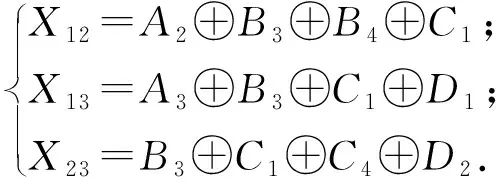
(3)
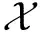
由分析可知,每次迭代时主节点需发送3个子消息,假设每个子消息的大小为1/3,则文献[71]所提出方案的通信负载为1.在相同的内存布局策略下,非编码洗牌方案需发送8个子消息,最终的通信负载为8/3.因此,在该场景下,与非编码洗牌方案相比,Elmahdy等人所提出的编码洗牌方案可节省约62%的通信负载.
“好”的数据洗牌方案需要缓存的数据在各工作节点之间和算法迭代过程中具有足够的差异[72-74],受这一想法的激励,Li等人[15]提出了一种受约束的柔韧性索引编码数据洗牌方案,该方案在通信成本和计算性能之间取得了平衡.
为了达到该目的,Li等人在索引编码方案的基础上做了2项修改:1)添加一条约束,即一条消息最多可以发送给c个工作节点,以确保只有一小部分工作节点可以缓存同一条消息.该约束旨在降低工作节点间消息的相关性,确保工作节点间缓存内容的差异足够大.2)设计了一个分层结构,即将消息分成组,在迭代过程中,每个工作节点只缓存特定的消息.该修改旨在降低迭代过程中消息的相关性,以确保迭代过程中各工作节点缓存内容的差异足够大.通过在一个真实数据集上进行实验,与基于索引编码的替换式随机洗牌方案[2]相比,文献[15]提出的方案平均能减少87%的传输消耗.
2.3 小 结
本节我们总结了Master-Worker架构下2种不同分布式计算框架中优化通信负载的编码计算方案.首先我们对此类方案进行总结和回顾,如表3所示:
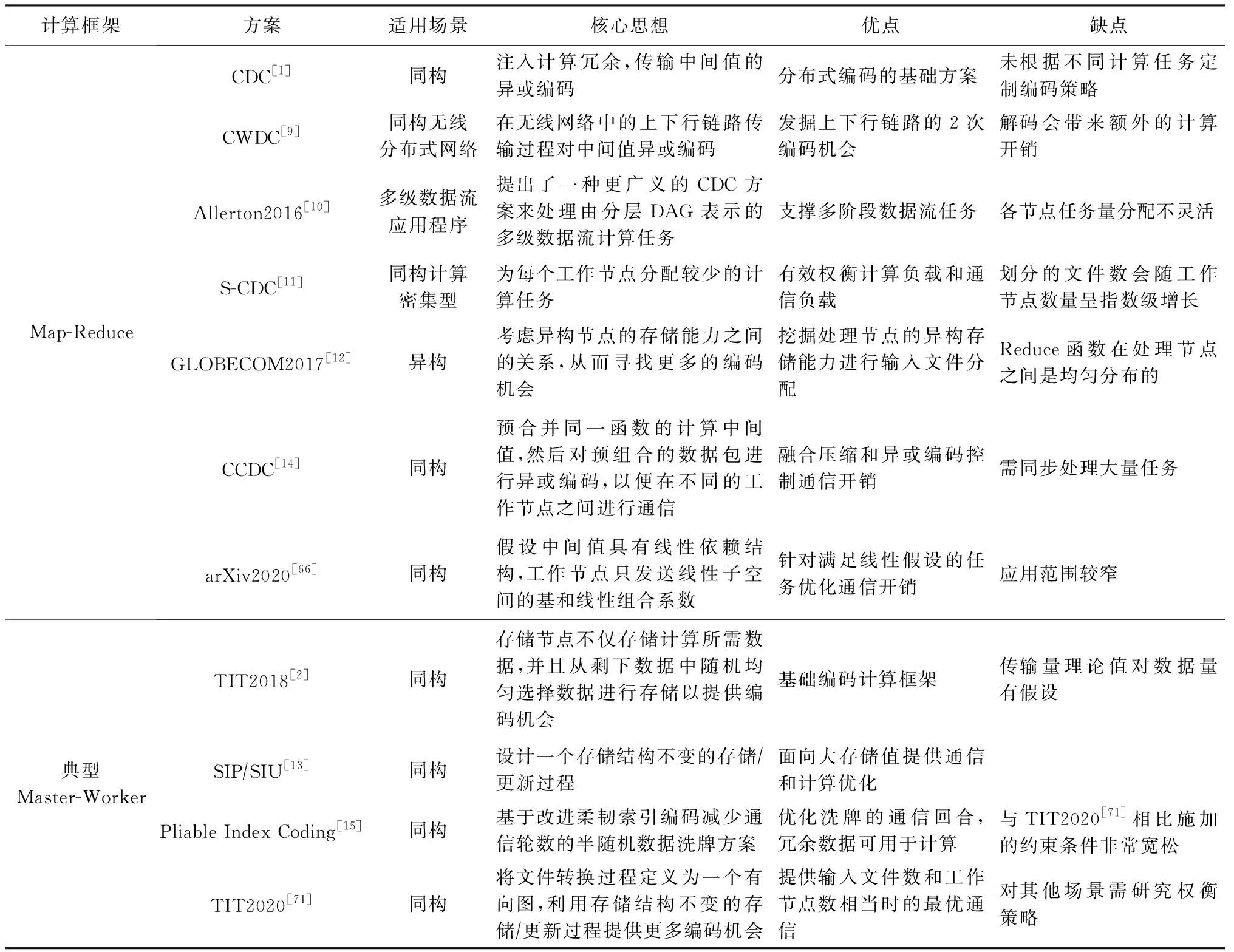
Table 3 Summary and Review of Coded Computing Schemes for Communication Bottleneck表3 面向通信瓶颈的编码计算方案总结与回顾
在Map-Reduce架构下的编码计算方案通过将输入数据映射到多个工作节点,并精心设计分配策略,从而创造编码机会.而在不注入计算冗余的情况下,工作节点交换中间值时,由于没有解码所需的信息,所以不能对中间值进行编码.通过注入冗余,CDC[1],CodedTeraSort[61]可以将中间值进行异或编码;CWDC[9]可以在无线分布式网络上下行链路分别将中间值异或编码和线性组合编码;CCDC[14]在Reduce函数是线性相关的假设下,可以对中间值进行压缩,然后异或编码;文献[66]则在中间值具有线性相关性假设下,可以只交换编码信息的线性子空间的基和线性组合系数,但其在编码阶段需要更多的计算开销;文献[11-12]则分别是CDC方案在多级数据流应用和异构分布式系统下的推广,其考虑了更多的约束条件,但编码思想和方式与CDC方案相同.
与Map-Reduce架构在数据洗牌阶段传输计算结果信息不同,在典型的Master-Worker架构中数据洗牌阶段需传输原始数据.对此类方案分析可知,典型Master-Worker架构中工作节点存储计算任务所需的数据外,还需存储一些“冗余数据”.正是因为引入了存储冗余,所以数据洗牌阶段才有编码机会.因此典型Master-Worker架构中编码洗牌方案的通信负载和各节点多余存储空间大小相关.一个极端的情况是,当所有的工作节点都有足够的存储空间来存储整个数据集时,数据洗牌阶段不需要通信.而另一个极端情况,当所有工作节点的存储空间刚好足以存储任务所需的数据时(称为无多余存储空间的情况),则通信量将达到最大.文献[2,13,71]考虑了无替换的数据洗牌,即附加数据用于提高通信效率,而不用于计算.然而,当额外的存储数据用于计算时,可以获得潜在的计算增益.例如,为了训练分类器模型,额外存储的数据样本也有助于模型训练.
通过对面向通信瓶颈的编码计算方案的分析可知,编码计算可以有效降低数据洗牌阶段的通信负载.然而,通信负载的降低通常以更大的计算负载和更大的存储为代价.因此,需要权衡计算-存储-通信三者之间的关系,才能更好地评估方案的性能.
3 面向计算延迟的编码计算
面向计算延迟的编码计算方案的核心思想是通过使用编码技术,创建任务冗余,即在更多的工作节点上分配计算任务,使得主节点在不接收掉队节点结果的情况下依然可以恢复最终结果.在面向计算延迟的编码计算方案中,一个重要的性能指标是恢复阈值,它是指在最坏情况下,主节点解码最终结果需要等待的工作节点的数量[2].一般来说恢复阈值越小,完成最终任务需等待完成计算的工作节点的个数越少,计算延迟越短.面向计算延迟的编码计算方案的目标是降低恢复阈值,以便通过等待较少的工作节点来恢复最终结果,从而减少计算延迟.
为了降低不同分布式计算任务的计算延迟,可以利用具体运算的代数结构来设计编码方案.在随后章节,本文将介绍分析当前编码计算方案在不同计算任务中的应用.除此之外,本文还将简单讨论研究人员在异构场景和利用掉队节点结果等方面所提出的编码计算方案.
3.1 面向矩阵乘法运算的编码计算
3.1.1 矩阵-向量乘法
分布式矩阵-向量乘法是线性变换的组成部分,是机器学习和信号处理应用中的一个重要步骤.为方便方案描述,首先定义分布式计算矩阵-向量乘法系统,该系统具有1个主节点和P个工作节点,其目标是分布式计算大小为m×n的矩阵A和n×1的向量x的积:b=Ax.如无特殊说明外,本节编码计算方案的计算场景和目标遵循该定义.我们将对不同的编码方案进行简要介绍和分析.
1) MDS编码方案.与简单的将同一个计算任务分配给多个工作节点(重复编码)不同,Lee等人[2]利用MDS码来克服矩阵-向量乘法中的计算延迟问题.基于MDS码的方案的编码策略是首先将矩阵A按列划分为k个子矩阵,每个子矩阵的大小为m×n/k.随后使用(P,k)MDS码对k个子矩阵进行编码,从而生成P个编码子矩阵.随后将编码子矩阵发送至工作节点,工作节点计算编码子矩阵与向量x的积,并返回主节点.则主节点可以根据最快的k个计算节点恢复出最终结果b.如1.3节图1(b)所示,为一个使用(3,2)MDS码的编码计算方案实例.
2) Short-Dot.在基于重复编码或者MDS码的编码计算方案中,每个工作节点需计算长度为n的点积,而Dutta等人[16]认为通过缩短点积的长度,可以减少工作节点的计算时间.因此Dutta等人提出了一种“短点积”(short-dot)的编码计算方案,该方案通过对子矩阵施加稀疏性以使工作节点计算较短的点积.然而,工作节点计算点积的长度越短,该方案的恢复阈值越高.
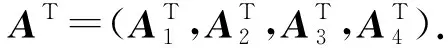
(4)
由式(4)可知,系数组成的矩阵为上三角矩阵,由于主对角线中的元素是非0的,所以它是可逆的.因此可以通过求系数矩阵的逆来恢复最终结果.利用对角线结构,s-对角线编码方案不仅降低了计算负载,并且可以实现和文献[2]相同的恢复阈值.
4) 无码率编码.LT码[75]是一类用于从有限的源符号集生成无限多个编码符号的纠删码.Mallick等人[18]通过将矩阵A的m行视为源符号,将LT码用于矩阵-向量乘法.该方案首先根据Robust Soliton度分布选择参数d,随后从A中随机均匀的选择d个数据行并将它们随机相加生成编码行.即d决定了每个编码行中的原始数据行的数量.原数据行与编码数据行之间的映射对于成功解码至关重要,因此,此映射需存储在主节点上.
假设对m个原始数据行进行编码生成了αm个编码行,则主节点将αm个编码行平均分配给P个工作节点.工作节点计算编码行和向量x的乘积,并将结果返回给主节点.如果一个工作节点在主节点能够解码b之前完成了分配给它的所有向量积,则它将保持空闲状态,主节点继续从其他工作节点收集更多的行向量积.一旦主节点获得了足够的结果可以解码b=Ax,则它将向所有工作节点发送完成信号以停止计算.和其他方案相比,无码率编码方案可以实现理想的负载平衡并且具有较低的解码复杂度.
3.1.2 矩阵-矩阵乘法
矩阵乘法是许多数据分析应用程序中关键操作之一.此类应用程序需要处理TB级甚至PB级的数据,这需要大量计算和存储资源,而单台计算机通常无法满足.因此,在大型分布式系统上部署矩阵乘法计算任务已经引起了广泛的研究[76-77].
本文首先定义分布式矩阵乘法计算场景.该分布式计算系统有一个主节点和N个工作节点(w1,w2,…,wN)组成,其目标是计算大矩阵乘法C=ATB.其中A∈r×q,B∈r×s.为了分布式计算该矩阵乘法,首先将2个输入矩阵分别(任意)划分为p×m和p×n个子矩阵块,其中同一输入矩阵内的所有子矩阵大小相等.然后将A,B中每个子矩阵分配给各工作节点,工作节点完成计算任务后,将计算结果返回给主节点.主节点恢复最终结果输出C=ATB.如无特殊说明外,本节编码计算方案的计算场景和目标遵循该定义.我们将对不同的编码方案进行简要介绍和分析.
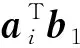
2) 乘积码.随后Lee等人基于乘积码[78],在文献[19]中提出了另一种新颖的编码矩阵乘法方案,该方案较1D-MDS编码方案具有更低的恢复阈值.乘积码是用小编码块作为构建块构建较大编码块的一种方法.以N=9,m=n=2,p=1为例,简要说明乘积码的编码解码过程.由于m=n=2,因此有:
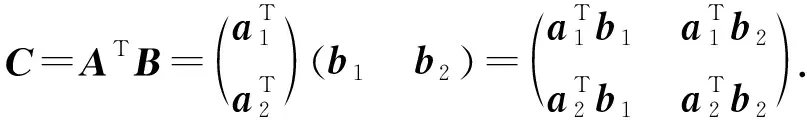
(5)
(6)
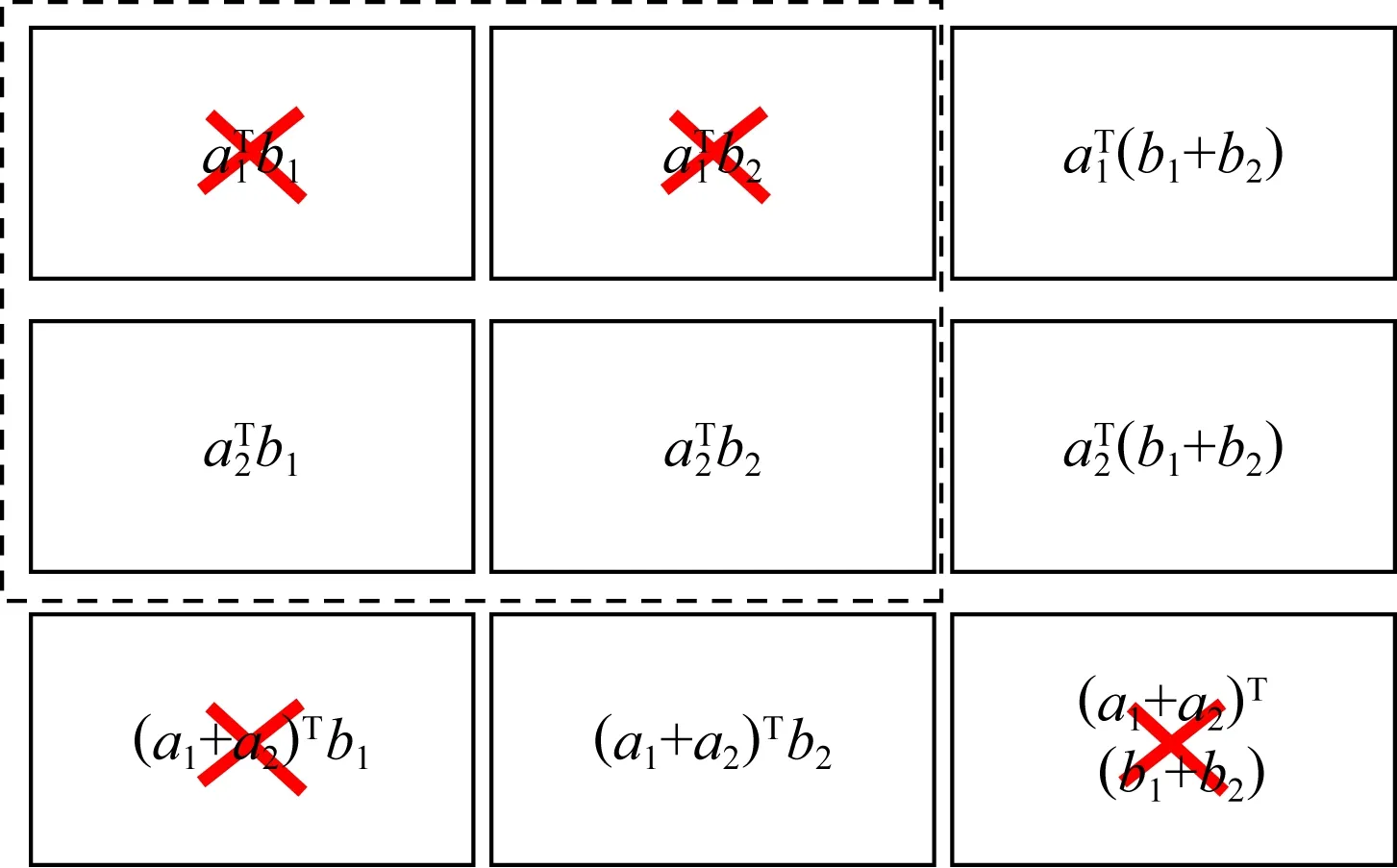
Fig. 7 An example of computing tasks assignment图7 计算任务分配示例
介绍一类以多项式码为基础的编码计算方案[20-22],这类方案的共同特征是为每个工作节点分配不同的随机数,并使用该随机数对输入矩阵进行编码,从而使得最后解码过程可视为多项式插值问题,不同之处在于各方案对输入矩阵的切割方式不同.基于多项式码的编码计算方案的主要优点是可实现最佳恢复阈值,且恢复阈值不随工作节点的数量的变化而变化.
3) 多项式码.为了寻找最佳恢复阈值,Yu等人[20]提出了一种基于多项式码的编码计算方案,该方案的恢复阈值与工作节点数量无关,且远小于MDS码和乘积码方案中的恢复阈值.为构造多项式编码计算方案,Yu等人首先将输入矩阵A和B沿垂直方向分别划分为m和n个子矩阵,即A=(A0,A1,…,Am-1),B=(B0,B1,…,Bn-1).随后随机分配给每个工作节点wi一个互不相同的数,记为xi∈q(q为一个足够大的有限域).对于给定的参数α,β∈,Yu等人定义如下(α,β)-多项式码:对∀i∈{0,1,…,N-1},计算:
(7)
(8)
(9)
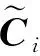
(10)
4) MatDot.由文献[20]可知,当m=n时,多项式码方案的恢复阈值为m2.针对m=n的情况,Fahim等人[21]提出了一种恢复阈值更低的编码计算方案,称为“MatDot”.MatDot假设矩阵A和B都为P×P的方阵,并将两矩阵分别在垂直和水平方向划分为m个大小相等子矩阵.其编码思想和多项式编码[20]相似,在m=n时,MatDot方案的恢复阈值为KMatDot=2m-1,其远远小于多项式编码的恢复阈值m2.
5) PolyDot.虽然MatDot的恢复阈值比多项式码方案[20]低,但在通信成本方面,MatDot中每个工作节点的通信成本为O(N2),要比多项式码方案的通信成本O(N2/m2)高.因此Fahim等人[21]针对矩阵A和B都是方阵的情况,在MatDot的基础上提出了一种名为“PolyDot”的编码方案.该方案权衡了恢复阈值和通信成本之间的关系,是MatDot和多项式码[20]方案的折中.一般而言,PolyDot的恢复阈值为KPolyDot=t2(2s-1)(st=m),通信成本为O(N2/t2).
6) 纠缠多项式码.与只允许将矩阵按列划分的多项式码方案不同,Yu等人[22]在多项式码方案的基础上提出了一种名为纠缠多项式码的编码计算方案.该方案允许对输入矩阵进行任意划分.在纠缠多项式编码方案中,矩阵A和B分别被分割为p×m和p×n个子矩阵块,其中同一矩阵内的所有子矩阵大小相等.换句话说,多项式码方案[20]是p=1的特殊情况.
通过选择参数p,m和n不同的值,纠缠多项式码可以实现系统资源的不同利用,从而平衡存储和通信成本.该方案的恢复阈值为KEntangled polynomial=pmn+p-1.此外,纠缠多项式码启发了通用多项式计算[48]、安全/私有计算[79]和区块链系统[80]中编码计算方案的发展.
7) 稀疏编码.大规模机器学习中许多问题都表现出极大规模的稀疏性,编码方案可能会破坏这种稀疏结构,并且导致更高的计算开销.Wang等人[23]通过实验证明,在稀疏矩阵乘法中,多项式编码方案的最终完成时间与未编码方案相比显著增加.针对稀疏矩阵乘法问题,Wang等人[23]提出了一种“稀疏编码”方案,其在编码过程中充分利用了稀疏矩阵的特性,其恢复阈值可以以较高的概率达到mn,并且可以降低工作节点计算量.实验结果表明,与未编码方案、MDS码[2]、乘积码[19]、多项式编码[20]和LT码[81]相比,在不同稀疏矩阵乘法中,稀疏编码方案都具有较快的计算速度,且对真实数据集的影响更为明显.
我们在表4中对编码计算方案的恢复阈值进行了总结和对比.其中工作节点个数为N,输入矩阵A,B分别被划分为p×m和p×n个子矩阵块.

Table 4 Summary of Recovery Threshold in Coded Computing Schemes for Matrix-matrix Multiplication表4 矩阵-矩阵乘法编码计算方案恢复阈值总结
3.2 面向机器学习典型运算的编码计算
3.2.1 梯度下降算法编码方案
Tandon等人[24]首次提出了梯度编码(gradient coding, GC)这一概念,通过有效利用工作节点额外的计算和存储,使得主节点能够容忍部分随机掉队节点.基于GC思想有一系列研究方案[24-28],这些方案的共同特征是对梯度进行编码.具体来说,对于一个由n个工作节点组成的分布式系统,GC的核心思想是首先将训练数据集划分n个不同的批次,随后将r(1≤r≤n)个数据批分配给每个工作节点,接下来工作节点根据分配的数据集计算出r个部分梯度,并返回r个梯度的线性组合.这些线性组合使得主节点可以从任意n-r+1个工作节点的结果中恢复出全梯度(即,所有部分梯度的和).换句话说,基于GC的编码方案的恢复阈值为K=n-r+1.
基于这种思想Tandon等人在文献[24]中构造了2种梯度编码方案:1)部分重复编码(fractional repetition coding, FRC);2)循环重复编码(cyclic repetition coding, CRC).分别对2种方案作简要介绍.
1) FRC.假设系统中有s个掉队节点,该方案首先将n个工作节点平均分为(s+1)个组,则每组有(n/s+1)个工作节点.随后将训练数据均等划分为n个数据批,并分配给每个工作节点r=(s+1)个不相交的数据批,所有小组彼此互为副本.完成计算后,每个工作节点将其部分梯度的总和传输给工作节点.然而,这种构造只在n为s+1的倍数时适用.
2) CRC.与FRC构造不同,CRC编码方案不需要n被(s+1)整除.在CRC中,不是分配不相交的数据批,而是考虑将(s+1)个数据批循环分配给工作节点.如图8所示,为n=3,s=1的数据分配示例.假设每个数据批对应的梯度向量分别为g1,g2,g3,各个工作节点分别发送梯度的线性组合,例如g1/2+g2,g2-g3,g1/2+g3.主节点可以从任意2个向量中恢复g1+g2+g3:
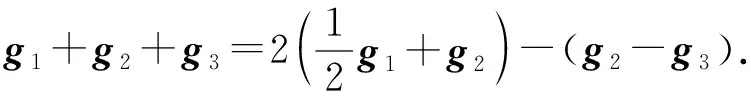
(11)
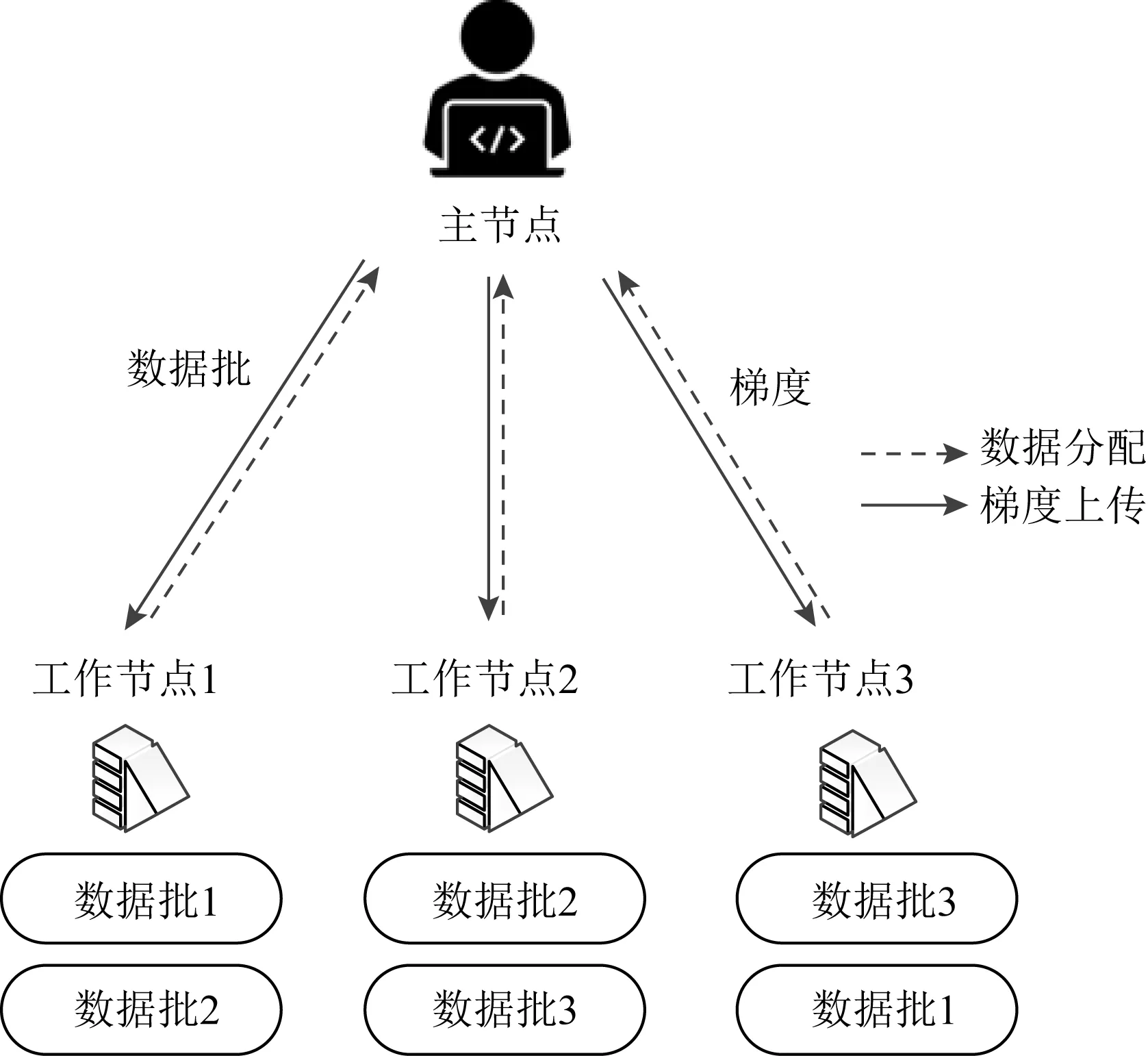
Fig. 8 Example of CRC when n=3,s=1图8 n=3,s=1 CRC编码示例
特别地,文献[24]通过构造一个随机编码矩阵,从而指定数据分配以及局部梯度的线性组合的系数.以图8为例,构造的编码矩阵B应为

B中每一行的非零项的索引决定了分配给每个工作节点的数据批次,而每一行的值是每个工作节点对梯度进行线性组合编码时的系数.在此基础上文献[26-27]分别使用循环(n,n-s)MDS码[82]和Reed-Solomon码[83]构造了相同功能的编码矩阵,并达到了相同的性能,两者的恢复阈值都为K=n-r+1.
3) BCC编码方案.BCC方案[27]的核心思想是在主节点处获得部分梯度的“覆盖率”.简单来说,将训练样本分成若干批,每个工作节点独立地随机选择其中一个数据批进行梯度计算,随后工作节点将计算的部分梯度的和返回给主节点.如果主节点之前已经接收到同一数据批的梯度,那么主节点将丢弃该消息,否则保留该消息.在接收到所有数据批的处理结果之前,主节点一直收集消息.最后,主节点通过简单地计算保留的消息的总和恢复出最终结果.

4) 通信-恢复阈值平衡方案.除了恢复阈值外,通信成本也是影响分布式梯度下降算法的重要因素之一.然而上述文献的重点在于实现最佳恢复阈值,并没有考虑通信成本的问题.Ye等人[28]通过将梯度记为一个l维矢量,并对其中的元素进行线性编码,从而用更大的恢复阈值来换取每个工作节点更少的通信量.
虽然文献[28]同时权衡了恢复阈值和通信开销,但该方案存在解码复杂度高和数值稳定性差的问题.为了恢复梯度和,主节点需要计算一个大小为n-s(n为总节点数,s为掉队节点数)的矩阵的逆矩阵,这导致文献[28]的解码复杂度为O(n3).Kadhe等人[84]针对该问题,设计一个允许使用任意线性代码来实现编解码功能的系统框架.该框架使用FRC[24]方案在工作节点之间分配训练数据.当在这个框架中使用特定的码时,它的块长度决定了计算负载、维度决定了通信开销、最小距离决定了恢复阈值.文献[84]作者使用MSD码在Amazon EC2上评估了该框架的性能,与文献[28]相比,其平均迭代时间减少了16%.
6) AGC.与针对固定数目的掉队节点方案不同,Cao等人[87]提出了一种具有灵活容忍度的自适应梯度编码(adaptive gradient coding, AGC)方案.通过让工作节点按轮次向主节点发送信号,该方案在计算负载,通信开销和恢复阈值之间实现了最佳折中.在AGC中,假如系统中没有掉队节点,则主节点在接收到所有工作节点在第一轮返回的编码梯度后即可解码获得总梯度;假如系统中有掉队节点,则正常工作节点需要继续返回编码梯度,直至主节点可以解码总梯度.因此,该方案适用于掉队节点数量未知并且随着算法迭代而变化的实际应用.表5对编码梯度下降方案进行了分类,并总结了各方案的恢复阈值.
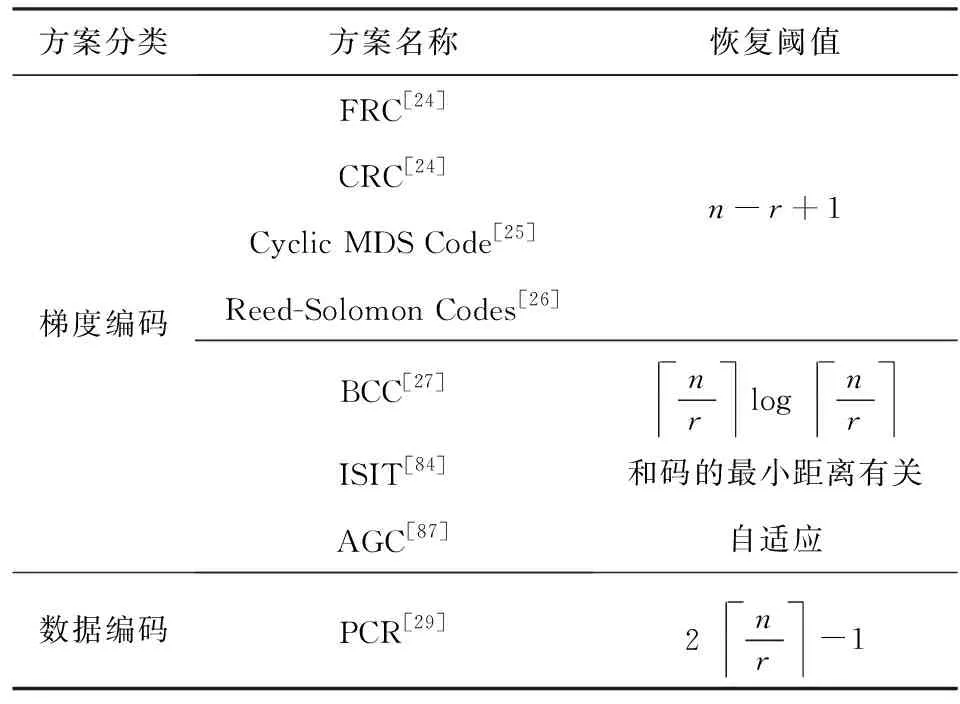
Table 5 Classification and Summary of Coded Computing Schemes for Gradient表5 编码梯度下降方案分类和总结
3.2.2 卷积计算和傅里叶变换
1) 卷积计算.卷积运算在数学、物理、统计和信号处理中具有广泛的应用.特别是对于卷积神经网络来说,卷积常被用于过滤或提取特征.Dutta等人[30]针对受掉队节点影响的分布式卷积计算系统,提出了一种新颖的编码卷积策略.该编码策略首先将输入向量分割为长度一定的短向量,并使用MDS码对预先指定的向量进行编码,从而可以在目标时间内快速可靠地完成计算.
2) 离散傅里叶变换.离散傅里叶变换是包括信号处理,数据分析和机器学习算法等在内的许多应用程序的基础操作之一.Yu等人[31]为了减少分布式离散傅里叶变换算法的计算延迟,提出了一种编码傅里叶变换方案.该方案利用离散傅里叶变换的递归结构,首先将其分解为多个短向量上的离散傅里叶变换操作,其次利用傅里叶变换的线性特性,对输入数据进行线性编码,使工作节点的输出具有一定的MDS码特性,从而减少分布式计算的计算延迟.
3.2.3 非线性计算
由于神经网络的某些层,如激活层是非线性的,所以算法的整体计算是非线性的.然而,本文讨论的编码计算方案并不适用于具有非线性计算的神经网络.但这些网络的性能也受到掉队节点的限制.Dutra等人[88]提出的一种用于矩阵-向量乘法的Generalized PolyDot编码方案,是可以扩展到深度神经网络(deep neural network, DNN)的方法之一.Generalized PolyDot通过对DNN中每一层的线性运算进行编码,从而允许每一层的训练中出现错误.换句话说,在错误量不超过最大错误容忍度的情况下,解码仍然可以正确执行.Hadidi等人[89]指出编码技术可以有效降低IoT系统中不同神经网络架构如AlexNet[90]中的计算延迟.但是,这种统一编码DNN的策略可能不适用于其他具有大量非线性函数的神经网络.现有的编码计算方法侧重于手工设计新的编码方法,大多都不适合预测服务系统.
因此,Kosaian等人[32]在CNN和多层感知器的基础上,提出了一种用来学习编码和解码功能的神经网络结构和训练方法.在没有掉队节点的情况下,解码函数返回的预测结果与其他预测服务系统的结果相同.当出现掉队节点时,解码函数的输出是对缓慢或失败预测的近似重建.通过使用ResNet-18分类器在数据集MNIST,Fashion-MNIST和CIFAR-10上进行实验,结果显示该方案重建不可用,输出结果的正确率分别为95.71%,82.77%和60.74%.
3.3 其他面向计算延迟的编码计算方案
就适用场景而言,第3.1~3.2节所介绍的编码计算方案中工作节点皆是同构的,而分布式计算中另一个常见特性是工作节点的异构性.因此,研究如何减少异构分布式计算场景下的计算延迟也是非常必要的.
1) 异构场景下编码计算方案.为了更好地处理异构分布式计算系统中的掉队节点,必须考虑设计有效的负载分配策略,以最大程度地减少总体作业执行时间.在给定计算时间参数,即每个工作节点计算时间服从一个移位的指数分布时,异构编码矩阵乘法(heterogeneous coded matrix multiplication, HCMM)算法[33]解决了最优负载分配问题.HCMM方案利用编码技术和计算负载分配策略,最大程度地减少了平均计算时间.仿真结果表明,相比于未编码方案,未编码负载平衡方案和统一的负载分配编码方案,HCMM分别将平均计算时间分别减少了71%,53%和39%.
虽然HCMM显著降低了计算延迟,但其解码复杂度很高.在实际的分布式计算系统中,某些处理节点具有相同的计算能力分布,因此可以将它们组合在一起,形成一个群.通过利用这种群结构和不同群之间的异构性[34-35],并结合最优负载分配策略,不仅可以实现接近基于MDS码的编码方案的最佳计算时间,而且可以降低解码复杂度.
除了工作节点的异构能力之外,工作节点的可用资源也可能随时间而变化.为了最大化工作节点的资源利用率,研究人员提出了适应工作节点时变特性的动态负载分配算法[36-38].Keshtkarjahromi等人[36]提出了一种编码协同计算协议(coded cooperative computation protocol, C3P).在C3P中,主节点基于工作节点的响应来确定编码数据包的传输间隔.对于不能在给定的传输间隔内完成任务的工作节点,它们等待下一个编码数据包的时间更长.与不考虑工作节点动态资源异构性的HCMM[33]相比,C3P协议的计算延迟降低了30%.
为了避免网络中掉队节点造成的延迟,大多数编码计算方案都将掉队节点视为“纠删节点”,这意味着它们的计算结果将被完全忽略.然而很少有工作节点是完全不活动的,因此,掉队节点,特别是非持久性掉队节点所完成的计算结果是不可忽略的,需要更好地利用[91].
2) 利用掉队节点的编码计算方案.为了利用这些掉队节点的计算能力,Ozfatura等人[39]使用了多信息通信(multi-message communication, MMC),其允许工作节点在完成分配任务的一部分时传输其计算结果.Ozfatura等人将MMC和拉格朗日编码计算方案[48]相结合,以最大程度地缩短作业执行时间,但由于工作节点传输到主节点的消息数量增加而导致通信负载增加.Kiani等人[40]将分配给工作节点的任务进一步分为较小的部分,并且允许工作节点之间交流其各自计算结果,这使得掉队节点所做的工作可以被充分利用.
Ferdinand等人[41]提出一种分层编码计算方案,以利用所有工作节点的计算结果.在该方案中,每个工作节点将分配的计算任务按层划分为多个子计算,然后按顺序进行处理,即在下一层计算开始之前,需要将已完成层的子计算的结果传输到主节点.Ferdinand等人使用MDS码对每层任务进行编码,以使工作节点完成每层任务的计算时间大致相同.随后该分层编码计算方案被Kiani等人[42]扩展到分布式矩阵-矩阵乘法和矩阵-向量乘法中.对于这2种类型的乘法,Kiani等人通过实验表明,虽然解码时间有所减少,但是分层编码的计算时间要比文献[39]中的方案长.
虽然编码计算方案可以降低通信负载并减少作业执行时间,但未编码的计算方案具有其自身的优势,即不需解码并允许部分梯度更新.为了结合2种方案的优点,Ozfatura等人[43]提出了编码部分梯度计算(coded partial gradient computation, CPGC)方案.因为每个工作节点都有很高的概率完成第一次分配的任务,所以CPGC首先分配给工作节点未编码的子矩阵,在工作节点完成计算后,再分配给其编码子矩阵.主节点能够使用一部分工作节点的全部计算结果和掉队节点的部分计算结果来更新梯度参数,从而减少任务执行的平均时间.
3.4 小 结
本节我们探讨编码技术在不同分布式计算任务中的应用.首先对3.3节方案进行总结回顾,如表6所示:
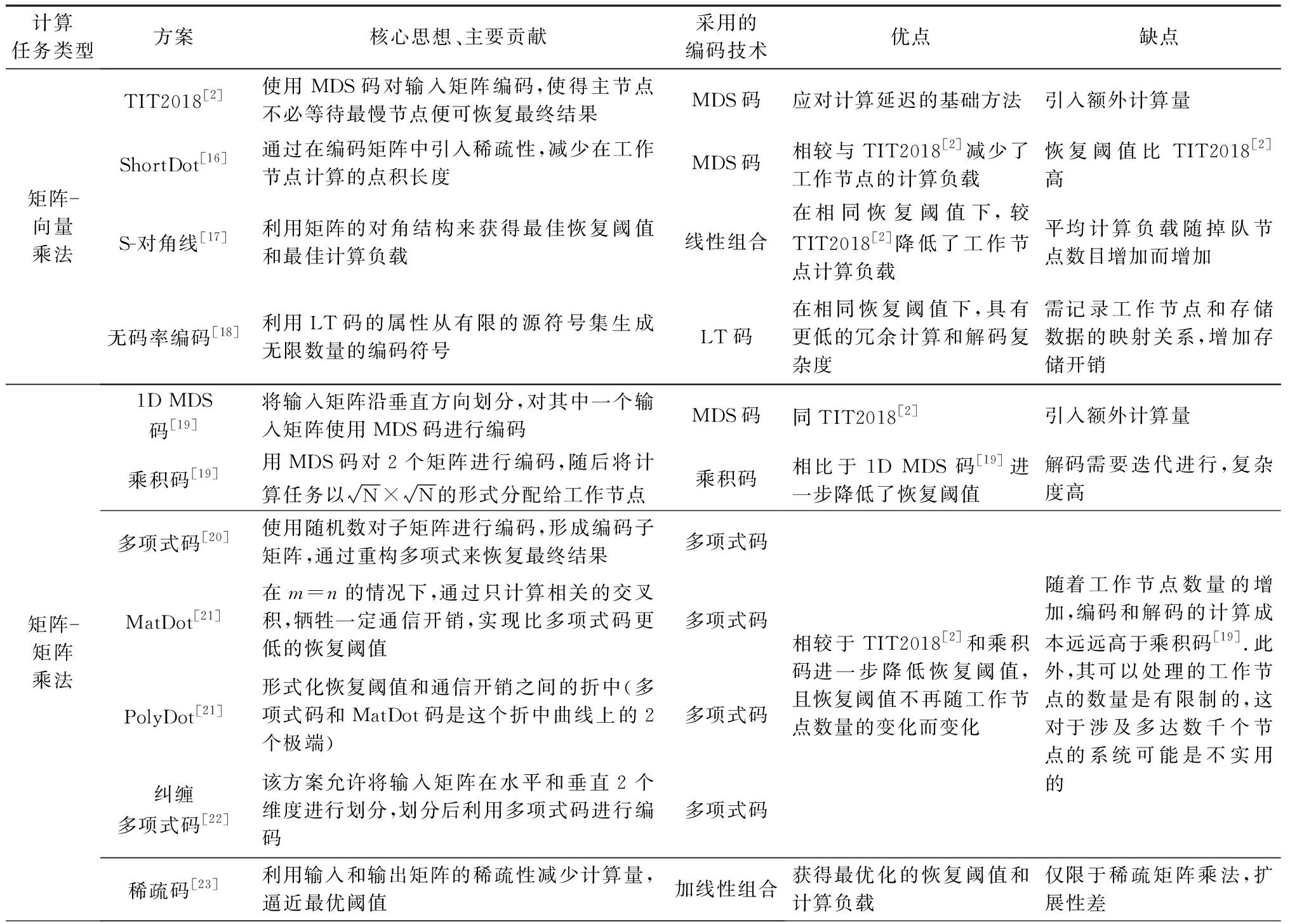
Table 6 Summary and Review of Coded Computing Schemes for Computing Delay表6 面向计算延迟的编码计算方案总结与回顾
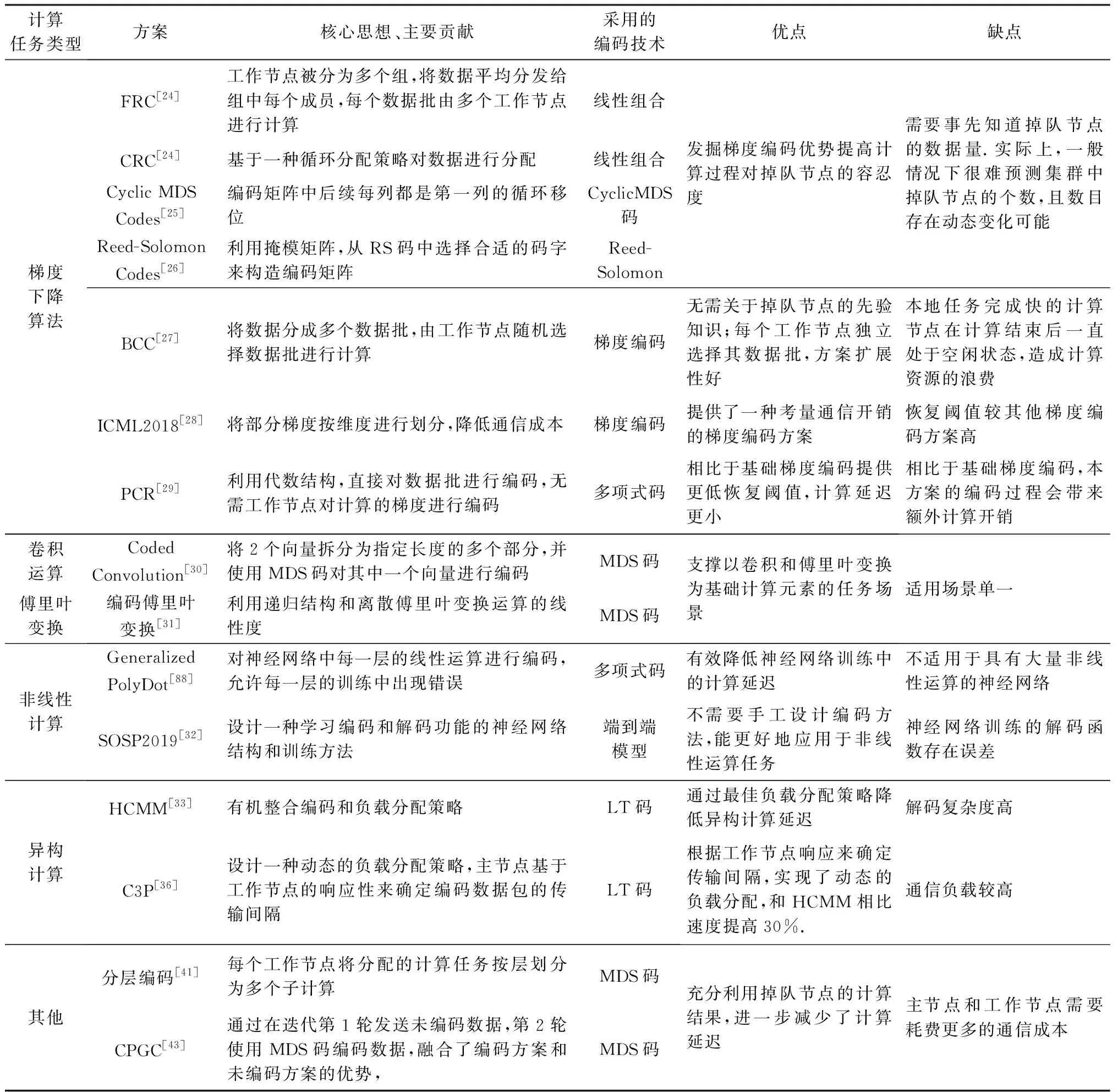
续表6
在矩阵-向量乘法任务中,研究人员不仅考虑如何使得恢复阈值最小,而且考虑了如何降低工作节点处的计算负载,以从整体上降低计算时间.特别地,无码率编码[18]可以有效利用掉队节点所做的工作,但该方案工作节点和主节点通信轮次增高,带来较大的通信开销.在矩阵-矩阵乘法中,现有研究方案都先将输入矩阵划分为较小的子矩阵,然后对子矩阵进行编码,生成编码矩阵.乘积码[19]使用MDS码在2个维度上对矩阵进行编码,多项式码[20]、MatDot[21]、PolyDot[21]、纠缠多项式码[22]则使用随机数对子矩阵进行编码,只不过在矩阵分割形式上有所不同.文献[20-22]解码最终结果的方法都可看成多项式插值问题.但这些方案都未考虑矩阵的稀疏性,因此研究人员提出了稀疏码方案[23],在计算速度上较其他方案有较大优势.梯度下降编码方案则大致可分为2类:1)基于GC的编码方案[24-27],这些方案中工作节点返回局部梯度的线性组合;2)对数据进行编码的方案,虽然该方案的恢复阈值比GC编码方案低,但其对数据进行编码带来了额外的计算开销.
虽然大多数的研究都集中在编码的设计上,但是译码复杂度和工作节点的计算负载也会对计算时间产生很大的影响.因此面向计算延迟的编码计算方案不应仅以降低恢复阈值为目标,而应权衡恢复阈值,计算负载和译码复杂度三者之间的关系,从而使整体计算时间最短.除了Reed-Solomon码[81]和LDPC码[85],更有效的低复杂度解码方式需要进一步探索.
4 面向安全隐私的编码计算
在分布式计算系统中,好奇的工作节点可能串通起来以获取原始数据的信息,而受到拜占庭攻击的恶意工作节点可能故意提供错误的结果[92],从而误导最终结果.抗恶意节点的编码计算方案往往通过设计具有纠错能力的解码方式以定位恶意节点,从而获取正确结果.防隐私泄露的编码计算方案则通过引入一个随机均匀矩阵对输入数据进行编码,从而达到掩藏真实数据的目的.
面向安全隐私的编码计算方案的目标是通过利用编码技术,在系统中存在M个恶意节点和T个共谋节点时,依然可以获得正确结果,并且不泄露原始数据的任何信息.我们将分别从抗恶意节点和防隐私泄露2方面对当前编码计算方案进行分析.
4.1 抗恶意节点的编码计算
在分布式计算的应用场景中,如战场物联网[93]、联邦学习[94]等,工作节点的计算可能是不可信的.因此,一个重要的问题是是否能够在拜占庭敌手的存在下可靠地执行分布式计算,并且该问题由来已久[95].最近,编码技术被应用到分布式计算系统中,以抵抗分布式计算系统中的拜占庭攻击问题.
1) DRACO.在分布式梯度下降算法中,Chen等人分别利用FRC和CRC[24]对数据进行编码(具体编码方法见4.3节),并针对2种不同的编码方法,设计了2种不同的解码方案.
具体来说,利用FRC对数据进行编码时,DRACO[44]让每一组中的节点来计算相同的梯度的和.为了解码同一组中的计算节点返回的输出,主节点使用多数投票算法来选择其中一个值.这保证了只要每组中少于一半的节点是恶意的,主节点将选择到正确的结果.由此,主节点可以获得所有组的正确的结果.利用CRC对数据进行编码时,DRACO利用离散傅里叶逆变换矩阵构造一个函数φ(·).函数φ(·)可以利用文件分配矩阵来计算恶意工作节点的索引.因此,DRACO可以利用非恶意节点返回的值来解码最终结果.仿真结果表明,DRACO算法在MNIST数据集上实现90%的测试精度时,比中值聚合方案[96]快3倍以上.随后,Rajput等人[97]使用梯度滤波器进一步提高了DRACO的计算效率.
2) 响应冗余.Gupta等人[45]提出“响应冗余”的概念,并利用随机检测的方法来提高系统的工作效率.其核心思想是让工作节点响应2次,且在每次响应中,为同一个工作节点分配不同的子数据集.通过对比2次响应的结果,主节点可以确定系统中恶意节点的索引.
然而,引入响应冗余使得工作节点的计算成本比DRACO[44]高2倍.为了降低计算成本,Gupta等人提出了随机方案,即主节点随机选择中间迭代的结果进行检测,或者,在每一次迭代中,主节点以概率p(0 4) LCC.针对任意多元多项式的计算任务,Yu等人[48]提出一种拉格朗日编码计算方案,该方案对输入数据进行编码,不仅可以降低计算延迟,而且可以抵抗恶意节点的攻击,同时保护数据的隐私. 考虑一个具有N个工作节点的分布式计算系统,其目标是对大型数据集X=(X1,X2,…,XK)中每一个Xi,计算f(Xi)(f是给定的阶为deg(f)的多元多项式).如果通过利用合适的编码方法可以在系统中存在S个掉队节点,A个恶意节点,T个合谋节点时仍然获得正确结果且不暴露数据隐私,则认为该方案可以实现三元组(S,A,T). 如果N≥(K+T-1)deg(f)+S+2A+1,则LCC可以实现三元组(S,A,T).该结果的意义在于,增加一个工作节点(即N增加1),LCC可以使掉队节点的弹性增加1,或者使恶意节点的鲁棒性提高1/2,同时保持数据的隐私. (12) LCC可以应用于计算任务是多元多项式的任何计算场景,因此涵盖了机器学习中许多计算任务,例如,线性计算、双线性计算、一般张量代数和梯度下降. 在分布式计算模型中,要计算的输入数据可能包含大量敏感信息,如个人位置信息和医疗信息.但是主节点有时需要利用可疑但有用的工作节点.因此保护输入数据的敏感信息不被泄露变得至关重要. 4.2.1 面向多项式运算的隐私编码方案 作为LCC的扩展,So等人[49]提出了一种快速且具有隐私保护功能的分布式机器学习框架——CodedPrivateML.该框架在每一轮训练中分2步秘密共享数据集和模型参数.首先,采用随机量化方法将数据集和每轮的权重向量转换为有限域.然后,CodedPrivateML使用LCC编码技术将量化值进行编码,并将编码数据分发给各工作节点,以保证数据隐私.CodedPrivateML面临的挑战是:LCC只能用于多项式求值形式的计算.因此,CodedPrivateML利用多项式逼近来处理涉及到sigmoid函数时的非线性计算,从而可以对LCC编码的数据进行Logistic回归.在Amazon EC2集群上的实验表明:CodedPrivateML比基于BGW[51]的安全多方计算方法快34倍,并且可以保护数据的隐私. 针对梯度类型的计算,Yu等人[60]提出了一种新颖的编码计算方案,称为“调和编码”,该方案适用于任何类型的梯度计算,同时可以保护输入数据的隐私.和LCC不同的是,调和编码使用一个随机变量Z来构造具有递归结构的中间值P,然后使用P对数据进行编码.由于Z是随机的,因此原始数据被掩藏,数据隐私得到保护.又由于中间值P的特殊结构,所以使得该方案相比于Shamir秘密共享方案[98]和LCC[48]方案,在计算梯度型函数时需要更少的工作节点.表7总结了3种方案在保护数据隐私时所需的最少工作节点数. Table 7 Comparison of the Minimum Number of Working Nodes表7 最少工作节点数对比 利用多项式码[20]可以有效降低分布式计算系统中的计算延迟,且恢复阈值与工作节点的数量无关.在此基础上,Nodehi等人[50]将多项式码与BGW方案[51]结合在一起,提出了一种多项式共享方案.在该方案中,数据源自外部资源,因此必须对工作节点和主节点同时保持私有.与BGW方案不同,Nodehi等人使用多项式码对数据集进行编码.文献[50]可用于执行加法、乘法和多项式函数等多种计算过程,同时可以减少完成任务所需的工作节点数. 在文献[50]中,执行计算的数据集被分成多个子数据集,每个子数据集被编码并分配给工作节点.在这种情况下,较快完成任务的工作节点将在等待掉队节点时处于空闲状态.为了进一步减少计算延迟,Kim等人[99]利用计算冗余提出了一种私有异步多项式编码方案,该方案将一个计算任务分成几个相对较小的子任务,并将子任务分配给每个工作节点.除了保留多项式共享方案的隐私保护特性外,该方案有2个优点:1)计算能力有限的掉队节点可以成功地完成较小的子任务;2)计算速度较快的工作节点被分配更多的任务,在整个任务计算期间持续工作,从而减少了整个任务的执行时间. 然而,文献[50,99]主要利用多项式码来保护数据隐私,这在某些方面是有限制的,例如,它只允许将矩阵按列划分.因此,Nodehi等人[100]利用纠缠多项式码[22]提出了一种纠缠多项式码共享方案,该方案作为多项式共享的扩展,进一步减少了数据共享阶段的限制,从而在满足隐私约束的同时减少执行相同计算任务所需的工作节点的数量. 4.2.2 面向矩阵乘法运算的隐私编码方案 针对矩阵乘法的特点研究人员考虑了2种隐私情况: 1) 单边隐私.输入数据中只有一个是私有的,另一个输入对工作节点是公开的. 2) 双边隐私.2个输入数据都是私有的,工作节点无法获得所有输入的有关信息. 分别对2种隐私情况下的编码计算方案进行介绍和分析. 单边隐私.Bitar等人[52-53]提出使用阶梯码替换线性秘密共享方案[101]来对数据进行编码.作为说明,考虑一个有3个工作节点的分布式计算场景,其目标是分布式计算矩阵-向量乘法Ax,并保护输入数据A的隐私(单边隐私).为保护数据隐私,主节点生成一个与A具有相同维数的随机矩阵R.当使用线性秘密共享方案时,数据和随机矩阵不被分割,作为一个整体进行编码和传输,如表8所示: Table 8 Transmission Contents of Two Different Schemes表8 2种不同共享方案的传输内容 因此,主节点必须等待其中任意2个工作节点的完整结果,才能解码最终结果,如Ax=S2x-S1x.当使用阶梯码时,数据和随机矩阵在传输给工作节点之前被分割成子矩阵.随后主节点发送给工作节点2组编码数据,如表8所示.因此,每个工作节点有2个子任务.每个工作节点按顺序执行计算任务,并将计算结果返回给主节点.当工作节点完成了足够多的子任务后,主节点可以通知工作节点停止计算.例如,当主节点接收到所有工作节点的第一个子任务的计算结果,或者主节点接收到任意2个工作节点的所有任务的结果时,可以从中解码获得最终的结果.在有4个工作节点的分布式计算场景下,Bitar等人在Amazon EC2集群上进行实验,结果表明使用阶梯码的平均等待时间比线性秘密共享方案减少了59%. Bitar等人[54]考虑到战场物联网(internet of battlefield things, IoBT)应用和设备的隐私要求,以及战场边缘设备资源的异构和时变性,提出了一种私密无速率自适应(private and rateless adaptive coded computation, PRAC)编码计算方案.和阶梯码相同,PRAC也引入随机矩阵来掩藏原始数据,但不同的是PRAC考虑了工作节点的异构性,使用喷泉码[81]对数据进行编码,并根据工作节点的响应情况,动态地生成和分配随机矩阵和编码数据. 双边隐私.Chang等人[55]首次考虑了矩阵乘法中双边隐私的情况,并设计了一个可行性方案.具体来说,输入矩阵被分割成子矩阵并用随机矩阵编码.以工作节点数为8、共谋节点数为1,来说明文献[55]的编码过程. 主节点首先将输入矩阵A,B进行划分 (13) 其中,A1,A2∈m/2×n,B1,B2∈n×p/2.然后,分别为A,B各生成一个随机矩阵KA∈m/2×n,KB∈n×p/2.主节点为每个工作节点i选择不同的参数xi,生成编码数据为 (14) (15) h(x)=A1B1+A2B1x+KAB1x2+A1B2x3+A2B2x4+(KAB2+A1KB)x5+A2KBx6+KAKBx7. (16) 由式(16)可知,多项式h(x)中4项A1B1,A2B1x,A1B2x,A2B2x的系数可组成最终结果.因此,主节点可以采取多项式插值法确定该多项式,从而获得所需的系数. 在该编码思想的基础上,Kakar等人[56]针对双边隐私提出了一种新的任意矩阵划分下的对齐秘密共享方案,以优化下载比率和恢复阈值.与文献[55]将2个输入矩阵划分为相同数量的子矩阵不同,Kakar等人[56]将输入矩阵划分为不同数量的子矩阵.与文献[55]相比,文献[56]在下载比率、可容忍共谋服务器数量和计算复杂度等方面都有所改进. 受多项式码[20]的启发,Yang等人[57]将多项式码扩展到保护双边隐私的矩阵乘法中.和文献[55-56]不同,该方案仅需为每个输入矩阵生成1个随机矩阵便可完成编码.主节点的解码过程与多项式码方案相似,都可视为多项式插值问题.和文献[56]相比,该方案的编码复杂度要低,并且在下载比率相似的情况下,可实现更低的恢复阈值. 本节我们讨论了编码计算在分布式计算系统中对抗恶意节点以及保护数据隐私方面的应用和研究.首先我们对4.1~4.2节方案进行总结和回顾,如表9所示. 抗恶意节点的编码计算方案往往通过设计具有纠错能力的解码方式以获取正确结果.DRACO[44]采用文献[24]中FRC和CRC两种编码方式,但在解码阶段分别引入了多数投票算法和检测函数.Gupta等人[45]采用基于GC的编码方式对梯度进行编码,但解码阶段则引入响应冗余,用以检测恶意节点.Data等人[46]在编码阶段设计具有错误校正能力的编码矩阵,利用该矩阵对输入数据进行编码,以在解码阶段可以对恶意节点进行定位.LCC[48]通过构造多项式的方式对数据进行编码,并在解码阶段利用具有纠错能力的Reed-Solomon解码器进行解码.防隐私泄露的编码计算方案在对数据进行编码时,额外引入一个随机矩阵,以此对原数据进行掩藏.特别是,针对矩阵乘法任务,本节讨论了单、双边隐私2种情况.一般来说,利用特定运算的代数结构,例如卷积任务或梯度计算,实现编码和解码的方案通常表现更高效. Table 9 Summary and Review of Coded Computing Schemes for Security and Privacy表9 面向安全和隐私的编码计算方案总结和回顾 目前,关于编码计算在学术界的研究才刚刚起步,存在许多问题需要解决,提供一系列研究机遇,本文从3个方面对未来可能的研究方向进行阐述. 1) 通信与计算的松耦合.在将编码应用于数据洗牌的相关工作中,通信和计算是松耦合的.即,其只关心通信目标:主节点希望以最小的通信负载使得每个工作节点都能获得执行计算任务所需要的数据.为了实现最小化通信负载,往往需要计算节点额外存储大量数据(存储冗余),而这些冗余数据只帮助传输并不用于计算[15]. 未来一个可能的工作方向是提高通信与计算的耦合性.如果多余的存储数据用于计算,则可以获得潜在的计算增益.例如,在训练一个分类器模型时,多余的数据样本也有助于模型训练.设计一个计算和通信耦合度较高的方案,并研究其中通信与计算两者之间的折中是必要的. 2) 掉队节点的利用和通信负载的平衡.虽然掉队节点的运行速度比平均速度慢,但其完成的计算结果对仍然有助于实现最终计算任务.例如,在文献[58]中,为了使线性逆求解器在截止期约束下的均方误差最小,掉队节点的结果被视为软误差.然而,当前利用掉队节点计算结果的方案中,往往需要执行更多的通信轮次.而高通信成本是分布式计算系统的另一个瓶颈.未来一个可能的研究方向是在利用掉队节点的计算结果时,探索使主节点和工作节点之间通信成本最小化的优化方法. 3) 安全隐私中的异构.由于掉队节点是分布式计算中的一个基本问题,因此面向计算延迟的编码计算方案考虑了异构场景.然而,在编码计算相关工作中,其他方面的异构网络问题还没有得到充分的研究[57].例如,工作节点可能有不同程度的声誉[102].保护数据隐私的手段可以只针对新工作节点或声誉低的工作节点进行,而对于受信任的工作节点则可能不需要.因此,未来一个可能的研究方向是考虑工作节点在声誉上的异构性,从而采取不同的隐私保护策略,以此降低可信节点的计算复杂度. 几十年来,编码理论在抗噪声方面的作用得以深入研究,并被广泛应用于多种场景中,成为日常基础设施(如智能手机、笔记本电脑、WiFi和蜂窝系统等)的一部分.编码计算将编码理论和分布式计算系统相结合,旨在通过注入计算冗余创造编码机会,实现降低通信成本、提高计算速度和保护数据安全等目标.本文通过区分研究目标将已有编码计算方案分为3类,对相应范畴下的研究现状进行了详细阐述,对比分析了典型方案,总结归纳了编码计算面临的挑战及研究方向,预期为分布式计算的研究人员带来启发和参考. 作者贡献声明:蔡志平是本项目的构思者及负责人,指导论文写作;周桐庆对本文关键性理论和知识性内容进行批评性审阅;郑腾飞是综述的主要撰写人;吴虹佳完成相关资料的收集和分析.周桐庆和蔡志平贡献等同,同为本文通信作者.
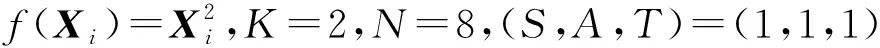
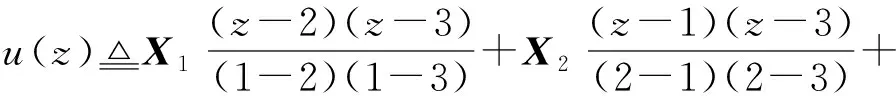
4.2 防隐私泄露的编码计算


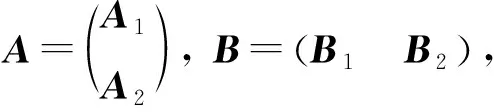

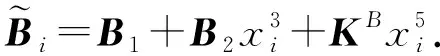
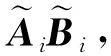
4.3 小 结
6 研究展望
7 结束语
