基于通路分析的遗传交互网络方法:BGTA方法及应用*
2021-10-09任志强皮路程刘桂炎程金群郜艳晖
任志强 皮路程 刘桂炎 刘 晴 程金群 郜艳晖△
【提 要】 目的 采用BGTA(backward genotype-trait association)算法结合通路分析策略探索全基因组关联研究中广泛的遗传交互作用。方法 采用GAW19(genetic analysis workshop 19)中无相关人群外显子测序数据及真实高血压表型数据,在KEGG(kyoto encyclopedia of genes and genomes)中选择高血压相关肾素-血管紧张素-醛固酮系统(renin-angiotensin-aldosterone system,RAAS)通路中的遗传变异作为候选变异,采用两阶段的 BGTA 算法进行基因交互作用分析并构建交互网络图,并与随机森林联合决策树方法结果比较。结果 BGTA两阶段分别筛选出76个(含61个低频)和56个(含44个低频)高血压相关遗传变异(P<0.10)。logistic回归验证有16对无主效应的变异间交互作用(P<0.05)。第一阶段随机森林基于MDG(mean decrease Gini)和MDA(mean decrease accuracy)分别筛选出35个(含0个低频)和69个(含30个低频)遗传变异,第二阶段决策树基于MDG和MDA分别筛选出5个和7个遗传变异,未发现低频变异。logistic回归验证了7对无主效应交互(P<0.05)。结论 两阶段BGTA在探索RAAS通路遗传变异交互作用与高血压关联时,比随机森林联合决策树方法发现更多无主效应交互作用。将BGTA算法和生物学通路分析方法结合应用于复杂疾病的全基因组关联研究中,可提高关联变异的识别能力,为了解复杂疾病的遗传结构提供线索。
近年来,GWAS(genome-wide association study)和二代测序技术(next-generation sequencing )为了解复杂疾病机制提供了许多新线索[1-2]。识别低频或稀有遗传变异的主效应及无主效应的交互作用(也称上位效应)被认为是解释复杂疾病“遗传缺失”的重要原因[3-5]。随机森林(random forest,RF)算法[6]通过构建多个决策树对每个变异进行综合评分,可以识别无强主效应的交互作用,但是其检测交互作用的能力本质上仍取决于主效应[7]。BGTA(backward genotype-trait association),也称反向遗传关联算法[8],通过考虑遗传变异联合效应来发现无主效应但存在交互作用的变异。近年来,随着生物信息学技术迅猛发展,基于生物通路进行遗传关联分析在解决维度困扰、提高效能以及提高生物学解释等方面具有显著优势[9]。本文利用GAW19(genetic analysis workshop 19)数据库[10],先基于通路分析策略筛选高血压相关通路,再运用两阶段BGTA算法构建包括低频遗传变异的遗传交互网络,探索常见疾病低频变异间交互作用,并与随机森林联合决策树方法比较,为多遗传变异交互作用研究提供方法学支持。
资料和方法
1.数据来源和预处理
(1)GAW19数据库简介
本研究利用GAW19中1851个无关联糖尿病个体的外显子测序数据和真实表型数据,其中外显子测序数据包括奇数染色体上经质量控制后符合要求的约169万个单碱基变异(single nucleotide variants,SNVs),表型数据包括收缩压、舒张压、年龄和性别等。本研究将真实高血压表型作为结局,定义为收缩压>140mmHg或舒张压>90mmHg,包括高血压427例,非高血压1424例。
(2)候选SNVs筛选
KEGG是整合基因、酶和化合物及代谢网络信息的综合性数据库[11-12]。本文利用其通路子数据库检索出高血压相关肾素-血管紧张素通路;基于疾病子数据库检索出原发性高血压相关基因,并定位到醛固酮合成与分泌通路及醛固酮调节钠吸收通路;最后将三条通路整合成RAAS(renin-angiotensin-aldosterone system),也称肾素-血管紧张素-醛固酮系统通路,共包含96个高血压相关基因,其中53个位于奇数染色体,编码26个蛋白或基因产物。
其后在ensembl(http://grch37.ensembl.org/index.html)中提取奇数染色体上53个基因的位置信息,并与GAW19数据库中的SNVs位置匹配,共获得12251个SNVs。进一步根据条件(1)哈迪温伯格平衡检验P≥0.05;(2)最小等位基因(minimum allele frequency,MAF)>1%;(3)在连锁不平衡r2>0.8的连锁域采用标签策略选择标签SNVs;共筛选出248个SNVs纳入分析,其中包含110个低频变异(MAF在1~5%)。为便于表达,本研究对所有SNVs按1,2,…,248顺序编号,重要SNVs的位置及基因信息见表1。
2.BGTA 算法原理
(1)GTD(genotype-trait distortion)和GTA(genotype-trait association)得分
假设有k个SNVs,每个SNV有三种基因型,则共有3k个多变异组合形式。设nD和nU分别表示病例组和对照组人数,nD,s和nU,s分别表示病例组和对照组中k个变异集的联合基因型频数,可计算病例组和对照组的联合基因型频率差异即GTD得分(式(1)),表示多个变异集与疾病相关的程度。
(1)
计算k个变异集{M1,M2,…,Mk}的GTDk得分与无Mr的k-1个变异集{M1,M2,…,Mr-1,Mr+1,…,Mk}的GTDk-1得分差异,可反映单变异Mr与疾病关联的程度,即GTA得分(式(2))。

(2)
(2)基于随机子集的BGTA筛选
为将交互作用SNVs同时选出,Lo等人[13-14]采用重复性地随机选取变异子集的方式筛选,最大化地利用数据信息。具体流程如下:
①从K个SNVs的数据集中随机选择k个变异,一般k为2~10。
②计算每个变异Mr的GTA得分,若得分<0,则Mr保留;若得分≥0,则剔除GTA得分最大的SNV,保留k-1个SNVs。
③重复②,直至子集中GTA得分均为负,定义为关联子集,并计算关联子集的GTD得分。
④重复①到③B次。
⑤计算B个随机子集中保留SNVs的出现频次及关联子集的GTD得分并排序。
可以看到,BGTA算法考虑随机子集的联合效应,无主效应时联合效应考虑为交互效应。对较为重要的SNVs(有主效应或交互效应),BGTA算法有较高的保留频次。
(3)随机子集变异数k和重复次数B的确定
考虑样本量和计算量,k一般取2~10。k越大,同时分析的变异越多[8]。重复次数B主要取决于变异总数K及交互作用。假设k个变异集中的某变异Mr与疾病存在关联,其保留频率为p1;若与疾病不存在关联,其保留频率为p2。则重复抽取次数B满足[14]:
(3)
式(3)中,无关联变异保留频率p2≈1/K,若Mr无主效应或弱主效应,但存在交互作用,则Mr保留频率p1为:
(4)
实际应用中,重复值B比理论上小得多,因为Mr可能与多个SNVs存在交互作用或边际效应,将增加p1的概率。
(4)二阶段BGTA筛选,并构建遗传交互网络及验证
考虑到运算速度及探索低阶交互作用更具解释性,本文采用二阶段BGTA算法筛选SNVs。第一阶段定义k=10,选择GTD得分前100的关联子集变异。第二阶段在第一阶段基础上,定义k=2,筛选一阶交互作用变异,再根据各变异对子集的GTD得分进行置换检验,并采用FDR(false discovery rate)进行校正,检验水准为0.10。用最终筛选出的SNV对构建遗传变异交互网络,并映射成基因交互网络。本研究对筛选的一阶交互作用采用logistic回归验证(检验水准为0.05),并与随机森林(random forest,RF)联合决策树方法比较。
3.随机森林联合决策树方法
本研究同时采用RF联合决策树方法,根据RF重要性评分和袋外估计误差进行第一阶段筛选。重要性评分基于MDG(mean decrease Gini)和MDA(mean decrease accuracy)两个指标[6];接着基于CHISQ分类规则构建决策树进行第二阶段低阶交互筛选,检验水准为0.10,并应用logistic回归模型进行验证(检验水准为0.05)。
4.统计分析软件
在SAS 9.4软件中编程实现数据清洗和统计检验,以及基因交互作用信息计算和置换检验。使用BGTA软件包(http://statgene.stat.columbia.edu/)完成BGTA算法。变异对映射遗传交互网络采用R软件的ggplot2包和igraph包[15]。RF采用R软件中的Randomforest包,决策树采用SPSS 17.0实现。
结 果
1.两阶段BGTA算法筛选变异及构建遗传交互网络
(1)BGTA第一阶段筛选
第一阶段设置k=10、B=150万,采用BGTA算法对248个候选SNVs进行筛选,结果显示GTD得分前100位的关联子集共包含76个遗传变异(含61个低频变异),分属于36个基因,编码22个蛋白。计算各SNV的保留频次,其中大于分位数阈值Q3+1.8×(Q3~Q1)的有6个(图1)。χ2检验主效应结果显示其中4个(26,49,101和184)SNVs的P<0.05,FDR校正后均无统计学关联(表2),推测这些SNVs的作用可能为与其他SNVs的交互作用。
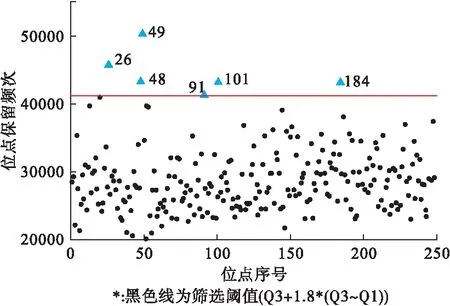
图1 BGTA算法第一阶段SNVs保留频次
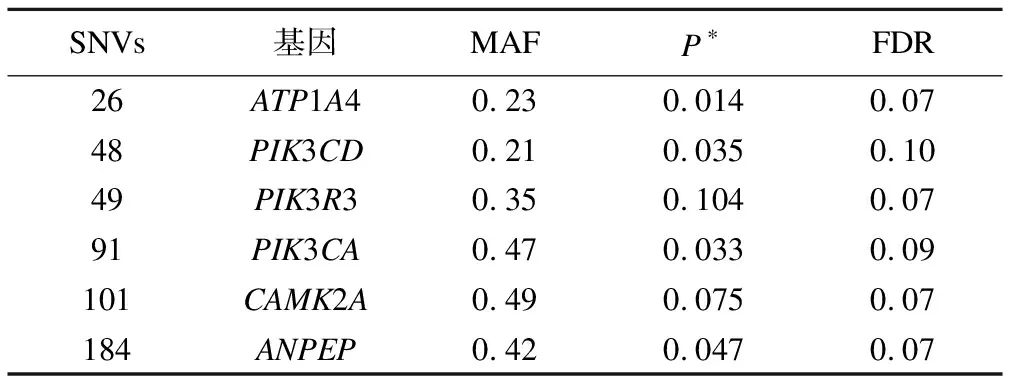
SNVs基因MAFP∗FDR26ATP1A40.230.0140.0748PIK3CD0.210.0350.1049PIK3R30.350.1040.0791PIK3CA0.470.0330.09101CAMK2A0.490.0750.07184ANPEP0.420.0470.07
(2)第二阶段交互作用分析
第二阶段设置k=2、B=50万,对第一阶段筛选的76个变异分析,结果保留了1102对不可约子集。随后的1000次置换检验和FDR校正后共得到82对SNVs,包含56个遗传变异(含44个低频变异)。进一步构建遗传交互网络,可以看到,26(ATP1A4)、49(PIK3R3)、52(REN)、184(ANPEP)和247(THOP1)与其他SNVs存在较多的连线(图2),作为可能的枢纽变异,值得重点关注。进一步将SNVs交互网络映射到基因交互网络见图3。
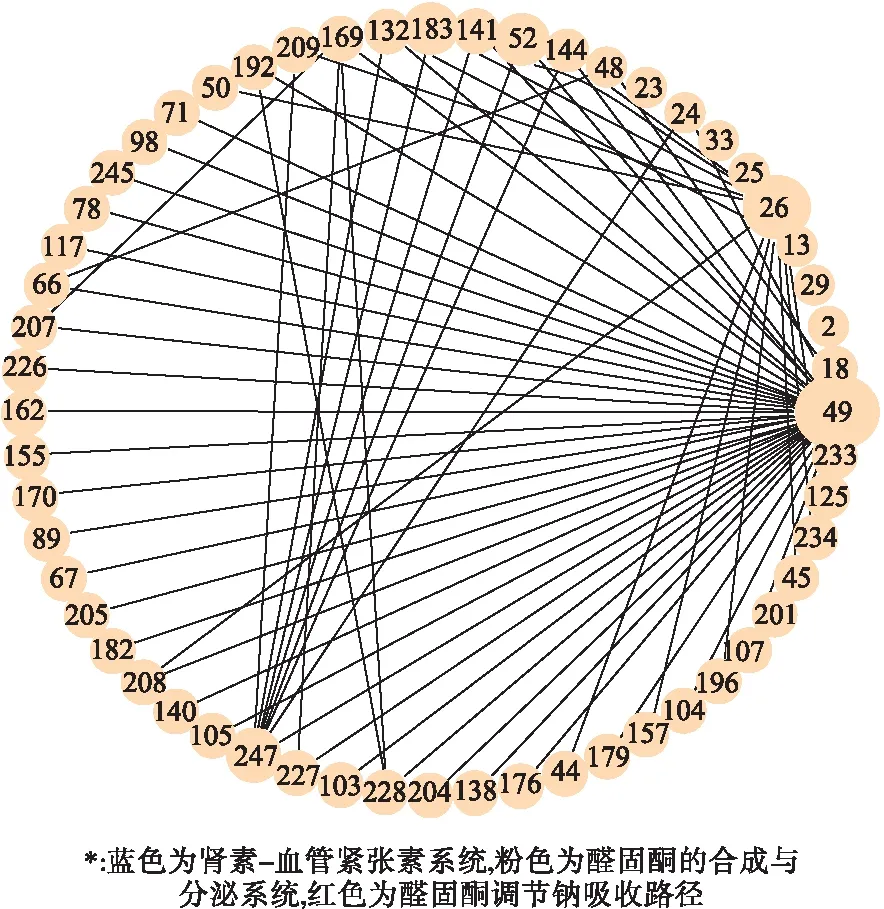
图2 高血压遗传变异交互网络
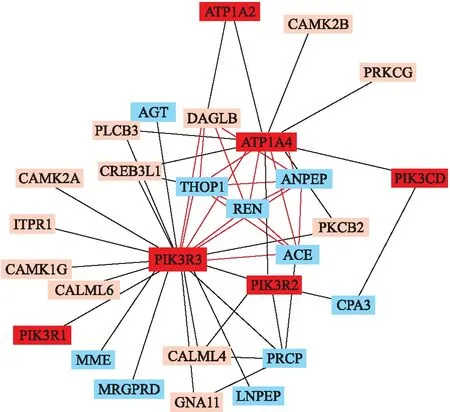
图3 遗传变异网络映射到基因交互网络
(3)logistic验证
采用logistic回归验证82对SNVs的相乘和相加交互作用。如表3所示,共有16对(21个)SNVs存在相乘或相加交互,其中相乘交互12对,相加交互10对;21个SNVs中含低频变异15个,其中26、49和169与其他SNVs的交互作用对分别为6、3和3对。
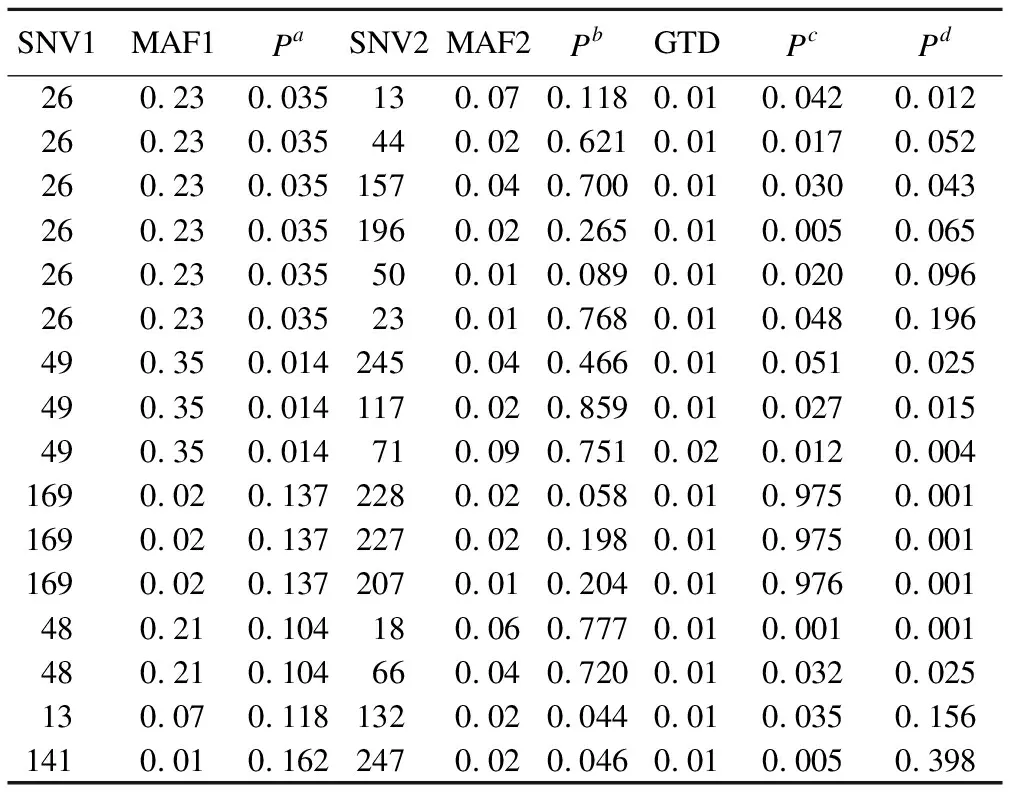
表3 BGTA的logistic交互作用验证结果
2.随机森林联合决策树分析
(1)第一阶段RF筛选
利用RF基于MDG共筛选出35个SNVs(无低频变异)。χ2检验显示其中7个(20、83、49、101、184、186、75)与高血压关联有统计学意义(P<0.05)。基于MDA共筛选出69个SNVs(含30个低频变异)。χ2检验显示9个(83、92、75、192、101、154、247、148、183)与高血压关联有统计学意义(P<0.05),但经FDR校正后均无统计学意义(见表4)。
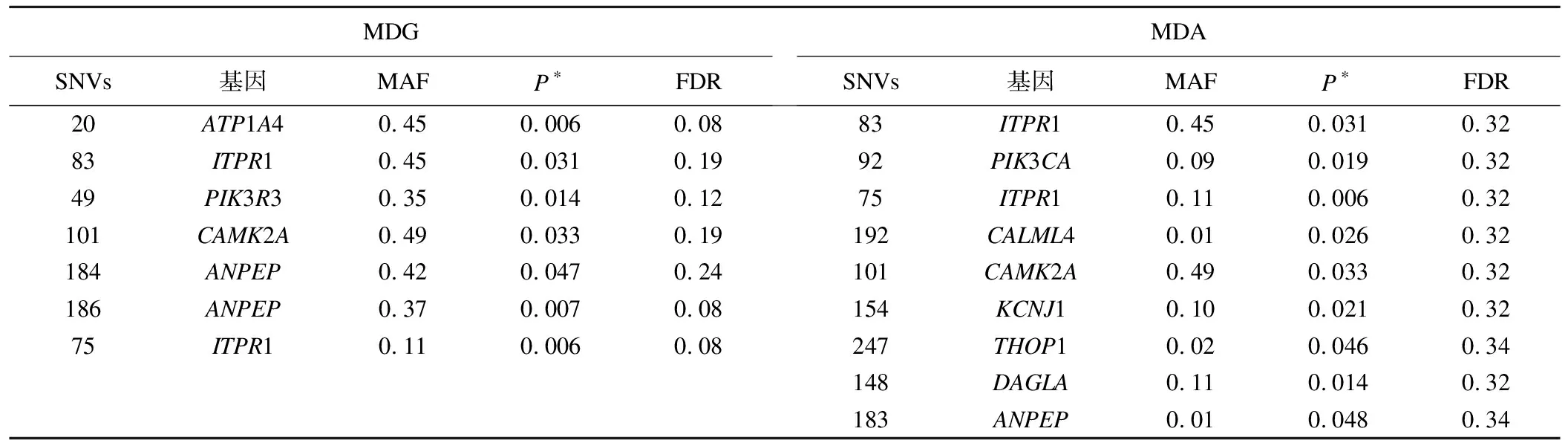
表4 采用RF第一阶段筛选卡方检验有统计学意义SNVs信息
(2)第二阶段决策树分析低阶交互
采用CHISQ分类规则构建决策树。基于MDG筛选结果,修剪后保留3层,筛选出5个SNVs(186、20、206、101和123),其中206和123无主效应,186和206,20、206和101可能存在交互作用。基于MDA筛选结果,修剪后保留3层,筛选出7个SNVs(83、101、48、177、206、144和1),除83和101外其他SNVs无主效应,83和48,48、144和1,101和177可能存在交互作用。
(3)logistic验证结果
采用logistic回归验证决策树结果。基于MDG,有2对变异186和206、20和123存在无主效应的相乘交互,同时也可能存在相加交互。基于MDA,有2对相乘交互和3对相加交互(见表5)。
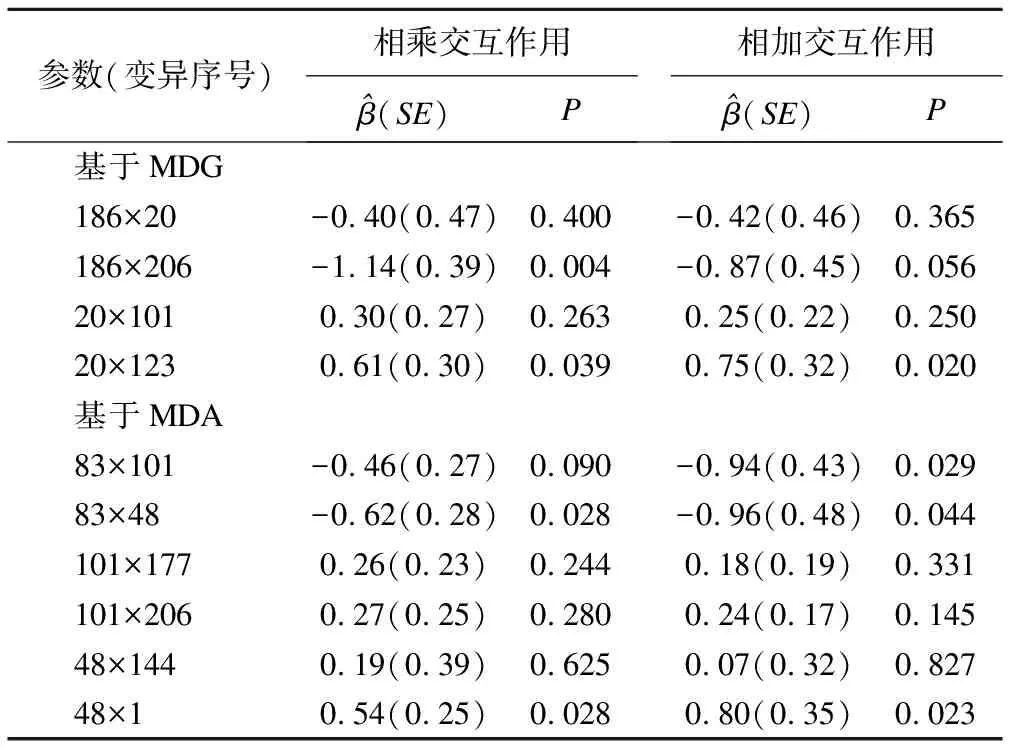
表5 决策树的logistic交互作用验证结果
3.两种方法结果比较
筛选变异的第一阶段,BGTA比RF筛选出较多低频变异和编码蛋白信息,见表6。在低阶交互作用分析的第二阶段,BGTA仍筛选出较多低频变异。尽管主要的交互作用都可在logistic回归中得到验证,但BGTA比决策树识别的无主效应交互作用更多,见表7。
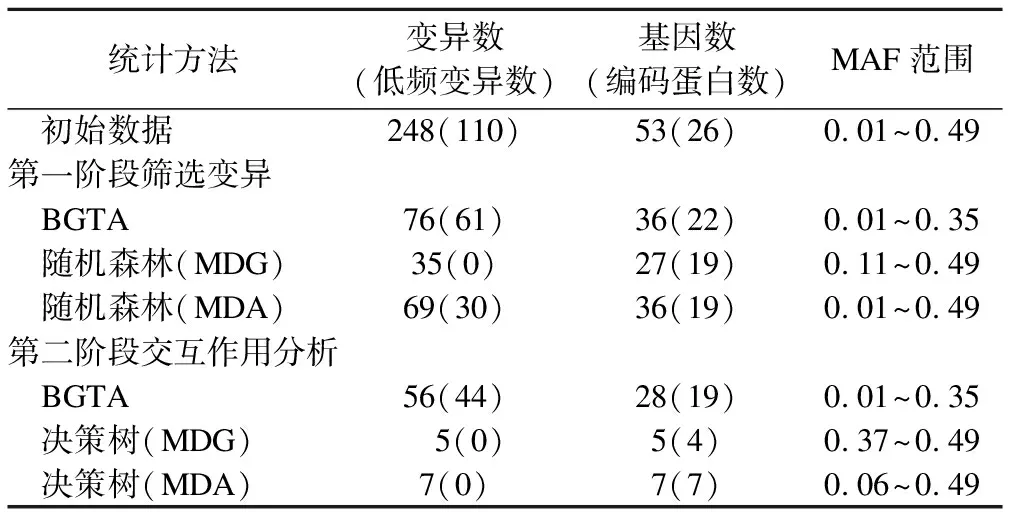
表6 BGTA与RF筛选交互作用变异数比较

表7 BGTA算法与决策树识别的交互作用对结果比较
讨 论
研究显示,基因-基因间的交互作用(上位效应)是解释复杂性状“遗传缺失”的重要原因之一,寻找广泛的基因-基因交互作用有助于了解复杂疾病的生物学机制[16-17]。很多情况下遗传变异对疾病没有主效应,而是通过基因-基因间的交互效应对疾病造成影响,而传统方法几乎很难直接检测到这种无主效应的交互效应[18-19]。BGTA算法计算病例对照中多变异联合基因型的差异,并采用逐一向后剔除法来评价各变异的重要性。当无主效应或弱主效应的SNVs仍有较高保留频次时,其重要性表现为该SNV与其他SNVs的交互作用;特别是如与多个其他SNVs交互,则代表疾病关联通路上潜在的枢纽基因或关键变异。本研究将BGTA算法用于GAW19数据,分析高血压相关通路基因交互作用。结果显示和随机森林相比,BGTA算法能有效地识别无主效应的交互作用,并对低频变异有较高的效能,借此构建的遗传交互网络有更强的生物解释性。
已有的研究显示RAAS系统的激活与高血压发生存在明显的关联[20]。作为一种常见复杂性状,高血压的遗传力为20%~60%[21-22]。但是,即便在已确认的高血压关联生物通路中,由GWAS发现的遗传变异对遗传度的解释也十分有限[23]。如近期的一项高血压GWAS仅识别到RAAS通路中少量遗传变异的主效应,包括前期已识别的基因REN、ACE、AGT、CYP11B2等[24],因此,探索遗传变异中更广泛的交互作用是填补现有“遗传缺失”的重要途径。
本文通过两阶段BGTA算法筛选RAAS候选通路中可能存在交互作用的遗传变异并构建遗传交互网络,显示该通路中存在大量的无主效应、包括很多低频变异间的交互作用,其中26(ATP1A4)、247(THOP1)、49(PIK3R3)、183(ANPEP)、52(REN)与其他SNVs存在多项交互作用,显示在遗传网络中可能起着关键的枢纽作用。logistic回归验证也发现交互作用主要集中在少数变异如26、49、169与其他变异间。进一步将遗传变异交互网络映射到基因交互网络,可直观显示基因REN、ACE、ATP1A4、PIK3R3、THOP1、ANPEP、DAGLB等间的高度连接,揭示了RAAS通路内基因的广泛交互作用。特别是PIK3R3、ATP1A4等作为潜在的关键枢纽基因在后续生物学机制研究中更值得关注。这些结果与KEGG分子信号通路中的基因关联也较为一致。
尽管如此,本研究也存在一些局限性。在研究设计上,由于GAW19的遗传数据仅提供奇数染色体的基因,所以本研究遗传交互网络不能代表完整的RAAS生物通路。在算法原理上,BGTA算法基于联合效应,可很好地识别无主效应的交互,但当变异有较强主效应时可能会高估变异间交互作用;此外,对于MAF更低的稀有变异,BGTA算法仍面临挑战。
总之,结合通路分析策略,BGTA算法可探索复杂疾病全基因组关联研究中的重要遗传变异,识别复杂疾病的遗传交互作用,尤其是无主效应时低频变异交互及关键枢纽基因,并通过构建遗传交互网络可视化遗传结构,为理解复杂性状的遗传生物学机制提供有益参考。
