结合Shortcut Connections结构的卷积稀疏编码图像去噪算法
2021-10-08张运杰白明明
张 膑, 张运杰, 白明明
(大连海事大学理学院, 大连 116026)
稀疏编码算法(sparse coding, SC)是解决线性逆问题的有效算法[1],其中Daubechies等[2]所提出的迭代收缩阈值算法(iterative shrinkage thresholding algorithms, ISTA)是最经典的稀疏编码算法。
ISTA算法结合Landweber迭代算法完成迭代,并采用使用加权展开式来代替传统的惩罚项。ISTA算法虽然能够有效解决稀疏编码问题,但是算法该算法收敛速度却很慢,为进一步提升ISTA算法收敛速率,Beck等[3]提出快速迭代收缩阈值算法(fast iterative shrinkage thresholding algorithm, FISTA)。FISTA算法中新编码向量与原编码向量之间呈线性关系,该算法保留了ISTA的计算简单性,并且在理论上和实践上均被证明具有比ISTA算法更好的全局收敛速度,有效提升了ISTA算法整体收敛速度。为进一步提升ISTA这一类算法计算效率,Li等[4]提出坐标下降算法(coordinate descent method, CoD)。CoD算法在每次迭代中只对精心选择的编码向量中某一子向量进行优化,直至其收敛为止。这样一来,算法相比之前FISTA算法进一步降低了获取最优稀疏编码所需计算复杂度。Gregor等[5]、Koray等[6]提出基于学习的迭代收缩阈值算法 (learned iterative shrinkage thresholding algorithm, LISTA)。LISTA算法通过结合常规方法所得编码向量,以训练参数化的非线性编码器来预测最优稀疏编码。
传统稀疏编码算法是将图像整体分为若干过冗余图像块,然后基于所有过冗余图像块训练所需字典。这样一来所学习到的字典中会含有大量的冗余信息,从而最终降低了所得目标图像质量。Kavukcuoglu等[7]提出卷积形式的坐标下降算法(convolutional extension to coordinate descent sparse coding, CCoD),该算法在卷积训练过程中通过使用大窗口代替小窗口以减少过冗余信息。康传利等[8]提出可以从平滑角度出发来去除噪声。华志胜等[9]采用噪声检测对图像块进行分类进一步提高传统方法对图像的特征的描述。孔英会等[10]通过改进传统算法来提升去噪效果并提出新算法,该算法可以对噪声图像进行高低频分离,进而可以更好地描述图像信息。为进一步提高算法去噪效果,张宇中等[11]通过将曲波算法与传统算法结合起来。新算法不但同时结合曲波算法与传统算法的优势,而且多尺度字典可以更加充分的描述图像信息。Zeiler等[12]通过训练组卷积核来学习所需字典,提出卷积稀疏编码模型(convolutional sparse coding, CSC)。CSC模型通过交替训练卷积核与其对应的特征响应来完成对原始图像的重构。卷积稀疏编码使用全局模型代替了传统稀疏编码基于图像块的局部模型,具有移位不变性[13]的全局模型不再区分位于不同图像块中的相同图像特征,有效提高了所获取目标图像的质量。
目前对于卷积稀疏编码算法的研究主要为Bristow等[14]、Heide等[15]、Brendt等[16]所提出的结合ADMM算法在傅里叶域中对CSC模型进行优化求解。后来,Vardan等[17-19]为优化求解CSC模型给出了理论保障,并结合传统稀疏编码算法提出卷积字典学习算法(slice based dictionary learning, S-BCSC)[20]。Choudhury等[21]提出共识卷积稀疏编码模型(consensus convolutional sparse coding, CCSC)。CCSC有效解决了CSC模型在每次迭代中过程所占内存较大问题。Chalasani等[22]提出卷积形式的快速迭代收缩阈值算法(convolutional fast iterative shrinkage thresholding algorithm, CFISTA)。该算法首次将ISTA算法应用于求解CSC模型,但算法并不成熟最终所带来的效果并不理想。Wang等[23]提出可拓展的在线卷积稀疏编码算法,通过重新设计目标函数进一步减少了在线训练卷积字典算法中所需历史矩阵的大小。陈小陶等[24]将传统模型与CSC模型相结合提出卷积稀疏表示图像重构算法。Lama等[25]在对偶域中重新设计了卷积稀疏编码模型,新模型进一步提升了模型收敛速度,但没有考虑到与深度学习相关算法相结合。Wang等[26]提出在线字典学习算法,该算法首先在全体图像集上训练基字典,然后在训练与相关的自适应系数,以此用来在基字典中选择出与样本相关的滤波器从而可以更好地描述图像特征。Wang等[26]所提出的在线字典学习算法可以通过仅与样本相关的图像来训练所需卷积字典,该算法是初步借鉴深度学习领域相关算法来优化卷积稀疏编码。
为进一步优化卷积稀疏编码模型,Hillel等[27]将卷积神经网络的计算能力和稀疏编码理论结合在一起提出近似卷积稀疏编码算法(approximate convolutional sparse coding, ACSC)。ACSC算法并不是直接对CSC模型使用标准LISTA算法,而是先将标准ISTA算法转延拓为卷积形式,进而在转化为卷积形式的LISTA算法。ACSC算法通过在卷积形式的LISTA算法迭代的末尾添加由滤波器数组组成的线性编码器来学习卷积字典,进一步提高了CSC模型生成编码向量的精确程度。ACSC算法首次将CNN应用于卷积稀疏编码模型中,虽然使用该算法所得效果要优于传统卷积稀疏编码模型,但是并没有从理论上给出可行性解释。
卷积稀疏编码算法虽然已经应用于图像卡通纹理分离[20]、图像融合[28]、图像超分辨率[29]等其他问题。但对于图像去噪等问题,卷积稀疏编码算法依旧落后于经典算法。为进一步研究CSC模型,Aviad等[30]、Vardan等[31]在之前研究者基础上,从理论上分析了卷积稀疏编码模型与卷积神经网络的不同与相同之处,并通过实验给出相关对比。为更好地将卷积稀疏编码应用于图像去噪,Dror等[32]结合ACSC算法提出卷积稀疏编码网络模型(convolutional sparse coding network, CSCNet)。新模型在图像去噪应用上效果要优于传统算法,而且相比深度学习算法大大减少了模型训练参数。
CSCNet模型虽然有效解决了卷积稀疏编码图像去噪问题,而且模型整体相比深度模型大大减少了所使用参数量。但是CSCNet模型并没有考虑到卷积层与反卷积层之间叠加会改变原始输入数据分布方式,进而降低最终图像去噪效果,而这种现象在深度学习中被称之为内部协变量偏移。为避免这种现象对CSCNet模型带来影响,现结合批处理标准化算法(batch normalization, BN)[33]、非线性激活函数(non-linear activation function rectified linear unit, Relu)[34-35]、 残差结构(residual learning, RL)[36]对CSCNet图像去噪网络模型作进一步改进与研究。首先讨论在CSCNet模型中加入以及不加入BN、Relu函数、残差结构对原模型所带来的影响,然后在此基础上提出带有跳跃联结结构(Shortcut Connections结构)的卷积稀疏编码模型,通过实验将本文研究中所提算法与CSCNet模型、S-BCSC算法[20]所得结果进行对比来验证所提算法有效性。
1 相关工作
1.1 稀疏编码
稀疏编码(sparse coding, SC)[1]是稀疏矩阵与学习到的字典矩阵之间通过线性组合的方式来完成对原始输入的重构。该模型表达形式为

(1)
式(1)中:X为原始输入;D为所训练的字典矩阵;z为稀疏矩阵;α为惩罚系数;L(X,z,D) 为算法优化过程中所涉及的量。对于给定的输入X,z*=argminL(X,z,D) 为算法最终所得编码向量。
1.2 卷积稀疏编码
传统稀疏编码算法是将图像整体分为若干过冗余图像块,然后将每一个图像块看为整体使用基追踪方法相互独立的处理。通过这种方法学习到的字典中会含有大量的冗余信息,因此,由此所得中高级图像特征并不能准确描述图像信息。为有效解决该问题,Zeiler等[12]通过训练组卷积核来生成所需字典,提出卷积稀疏编码模型(convolutional sparse coding, CSC)。CSC通过交替训练卷积核与其对应的特征响应来完成对原始图像的重构,模型表达式为

(2)
式(2)中:X为原始输入图像;dj为第j个卷积核;zj为卷积核所对应的特征响应;m、K分别为模型对特征响应非零数目的限制以及所训练卷积核总数。
1.3 批处理标准化
卷积神经网络因可以有效解决大规模数据集特征提取问题而受到广泛关注,但随着网络层数的增加模型也会变得越来越难训练。虽然小批量随机梯度下降算法(stochastic gradient descent algorithm, SGD)是一种非常有效的深度模型训练方法,但是在训练过程中随着前一层参数的变化后一层输入数据的分布同样也会发生变化从而导致模型不易训练,这种现象称之为内部协变量偏移(internal convariate shift, ICS)。通常的解决方法是在训练过程中设置较小的学习率以及选取适当的初始化参数。为进一步有效解决内部协变量偏移对模型的影响,Sergey等[33]提出批处理标准化算法。批处理标准化算法在每一层非线性映射函数之前,通过数据归一化步骤来降低ICS问题对模型的影响。批处理标准化算法如表1所示。目前CSC模型同类算法中,还没有算法通过考虑加入BN来优化CSC模型。

表1 批处理标准化算法[33]Table 1 Batch normalizing algorithm[33]
1.4 Shortcut Connections
随着卷积神经网络层数的不断增加,不得不面临的一个问题就是梯度消失、爆炸。当然这个问题可以通过在每一层非线性映射函数之前,通过批处理标准化(batch normalization, BN)来解决。但是随着网络层数的进一步增加,最终训练得到的模型精确度却不高。这一现象不再与梯度消失、梯度爆炸相关,而是由所设计模型本身的复杂程度所导致。为有效解决该问题,He等[36]提出残差学习。残差学习网络模型由带有跳跃结构的基础残差块构成,其中基础残差块结构如图1所示。残差网络不再是直接学习目标未知函数H(x),而是先学习残差映射F(x)=H(x)-x,最终通过H(x)=F(x)+x获得原始目标映射。目前卷积稀疏编码同类算法中,还没有算法使用Shortcut Connections结构、基础残差结构[36]来优化CSC模型。

图1 残差块结构[36]Fig.1 Residual block structure[36]
1.5 卷积稀疏编码图像去噪网络模型
具有移位不变性的卷积稀疏编码模型广泛应用于信号图像处理各领域,但是在诸如图像去噪之类的应用中仍落后于传统算法。Dror等[32]对CSC模型应用于图像去噪给出新的见解,并提出带卷积步长且以MMSE算法作为近似逼近的卷积稀疏编码网模型(CSCNet)。CSCNet是在ACSC模型[27]基础上改进的,算法主要迭代内容如下:

(3)


图2 卷积稀疏编码网络模型Fig.2 Convolutional sparse coding network model
CSCNet模型虽能有效解决图像去噪问题,但模型并没有考虑到由卷积以及反卷积之间的叠加会改变数据的分布方式。Zhang等[37]将BN[33]、残差学习[36]加入深层卷积神经网络提出深层卷积去噪网络,并在文中提高实验证明加入服从高斯分布的BN、残差网络有利于模型去除高斯噪声。李敏等[38]后来对Zhang等[37]提出的模型做出改进,并在模型中加入了Inception结构。CSCNet模型并没有考虑加入非线性激活函数、BN、基础残差块等其他深度学习常用方法。Wang等[26]、Sreter等[27]虽然借鉴了深度学习相关方法来优化CSC模型,但并没有给出理论依据。Dror等[32]从理论上分析了CSC模型与CNN之间的相同与不同之处并提出了CSCNet网络模型,但是该模型没有考虑到卷积层与反卷积层之间的叠加会改变数据传播方式。本文研究中借鉴Zhang等[37]的思想,尝试将非线性激活函数Relu、批标准化处理、残差块结构加入卷积稀疏编码网络模型中,并通过实验讨论了加入这些结构对CSCNet模型所带来的影响。目前在CSC同类算法中,还没有算法考虑使用非线性激活函数Relu、BN、残差块结构这些方法来优化CSC模型。
2 本文算法
2.1 新网络模型结构图
为进一步深入研究卷积稀疏编码网络模型,在保持原始卷积稀疏编码网络结构、优化算法不变的情况下,给出两种不同的网络模型设置。模型1是仅在CSCNet模型每一层加入BN、Relu函数,模型1网络结构如图3所示。在模型1中,输入图像被分若若干128×128图像块,然后使用LISTA算法完成近似编码过程,在此过程中输入数据会经历卷积层、反卷积层叠加,为不改变数据分布方式模型1中在卷积层、反卷积层后加入BN,为进一步促进模型稀疏性加入Relu函数,模型1最后一层反卷积层为图像解码以及图像重构过程。模型1中卷积层、反卷积层均由175个11×11卷积核构成。模型1中LISTA迭代为Gregor等[5]所提出的可学习的迭代收缩阈值算法。具体模型结构图如图3所示。

图3 模型1网络结构图Fig.3 Model 1 network structure diagram
模型2不仅在原始网络每一层上加入批处理标准化层、非线性激活函数层,还在原始输入与卷积输入之前加入了Shortcut Connections结构,改变了原始模型参数传播方式而且使模型变得复杂。为不增加原始模型负担。模型2由三部分组成,第一部分为数据处理阶段,该部分由1个3×3的卷积层,1个1×1的卷积层,以及将原始输入与残差输出联结起来的Shortcut Connections结构构成。第二、三部分为向量编码、解码过程,这两部分结构与模型1一致均使用175个11×11的卷积核构成。模型2中LISTA迭代为Gregor等[5]所提出的可学习的迭代收缩阈值算法,Conv代表卷积层。模型2具体结构如图4所示。

图4 模型2网络结构图Fig.4 Model 2 network structure diagram
2.2 BN、Shortcut Connections结构对CSCNet模型的影响
Dror等[32]提出CSCNet是以近似卷积稀疏编码算法[20]为基础,由卷积层、反卷积层构成的网络模型。但由于卷积、反卷积层之间的叠加,CSCNet模型在训练过程中数据会随着前一层参数的变化,从而导致影响最终所得结果。为避免或减少该现象对CSCNet网络模型的影响,借鉴Zhang等[37]在卷积神经网络中处理类似问题的方法,在原始CSCNet模型中每加入Batch Normalization[33]、Relu[35]函数。并且通过实验对比了不同卷积步长的CSCNet模型中,加入以及不加入BN结构对模型去噪效果的影响。在CSCNet模型中加入Relu函数会使一部分元素的输出为0,进一步促进了网络的稀疏性。
Zhang等[37]指出BN、残差结构均是服从高斯分布,从而能够更好地去除高斯噪声。本文中尝试在CSCNet模型中卷积输入之前加入基础残差块结构,该残差块结构从输入层出发由1个3×3的卷积层构成,然后通过Shortcut Connections结构将原始输入与1×1卷积层卷积输入联结起来。在模型中加入3×3卷积层是通过依次添加不同尺度卷积核,最终对比实验结果所得。在CSCNet模型中加入3×3卷积层进一步增加了图像特征的多样性。在模型中加入1×1的卷积,是为了使新模型在卷积稀疏编码部分卷积输入与原始模型卷积输入数据维度保持一致。在卷积稀疏编码网络模型中加入基础残差块结构,改变了原始参模型数传播方式,使模型能够更好地去除高斯噪声。
选取文献[39]中BSD432图像集60幅图像为一组作为训练集,Set12标准图像集作为测试集,其中测试集中的图像均不会出现在训练集中,以添加均值为0、方差为σ=25的高斯白噪声为例,观察非线Relu、BN、基础残差块结构对CSCNet网络模型去噪效果的影响。图5~图7是卷积步长固定时Relu函数、BN、基础残差块结构对模型去噪效果影响。图8~图12是对于不同步长同时加入Relu、BN、基础残差块结构对模型去噪效果影响。图13、图14显示的是基础残差结构中卷积核选取方法。
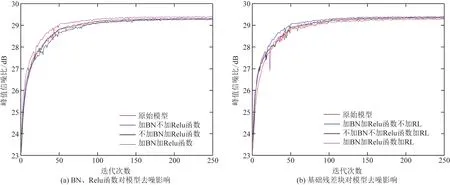
图5 卷积步长为9时BN层、Relu函数对、基础残差块对CSCNet模型去噪效果影响Fig.5 The influence of the BN layer, Relu function pair, and basic residual block on the denoising effect of the CSCNet model when the convolution step size is 9
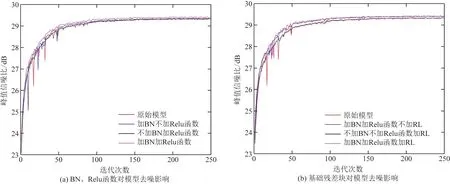
图6 卷积步长为8时BN层、Relu函数对、基础残差块对CSCNet模型去噪效果影响Fig.6 The influence of the BN layer, Relu function pair, and basic residual block on the denoising effect of the CSCNet model when the convolution step size is 8

图7 卷积步长为7时BN层、Relu函数对、基础残差块对CSCNet模型去噪效果影响Fig.7 The influence of the BN layer, Relu function pair, and basic residual block on the denoising effect of the CSCNet model when the convolution step size is 7

图8 不同卷积步长时加入BN对CSCNet模型去噪影响Fig.8 The effect of adding BN to the denoising effect of the CSCNet model at different convolution steps
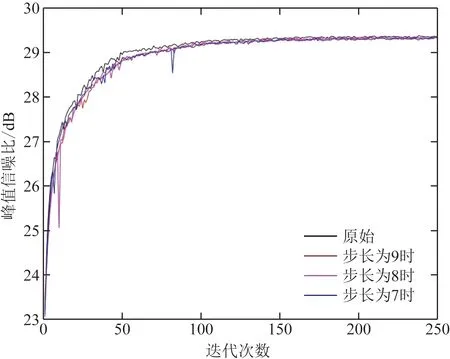
图9 不同卷积步长时加入Relu对CSCNet模型去噪影响Fig.9 The effect of adding Relu on the denoising of the CSCNet model at different convolution steps

图10 不同卷积步长时同时加入BN、Relu函数对CSCNet模型去噪影响Fig.10 The effect of adding BN and Relu functions to the denoising of the CSCNet model at different convolution steps

图11 不同卷积步长时加入基础残差块对CSCNet模型去噪影响Fig.11 The influence of adding the basic residual block to the denoising of the CSCNet model at different convolution steps

图12 不同卷积步长时同时加入BN、Relu、基础残差块对CSCNet模型去噪影响Fig.12 The effect of adding BN, Relu, and basic residual block to CSCNet model denoising at different step
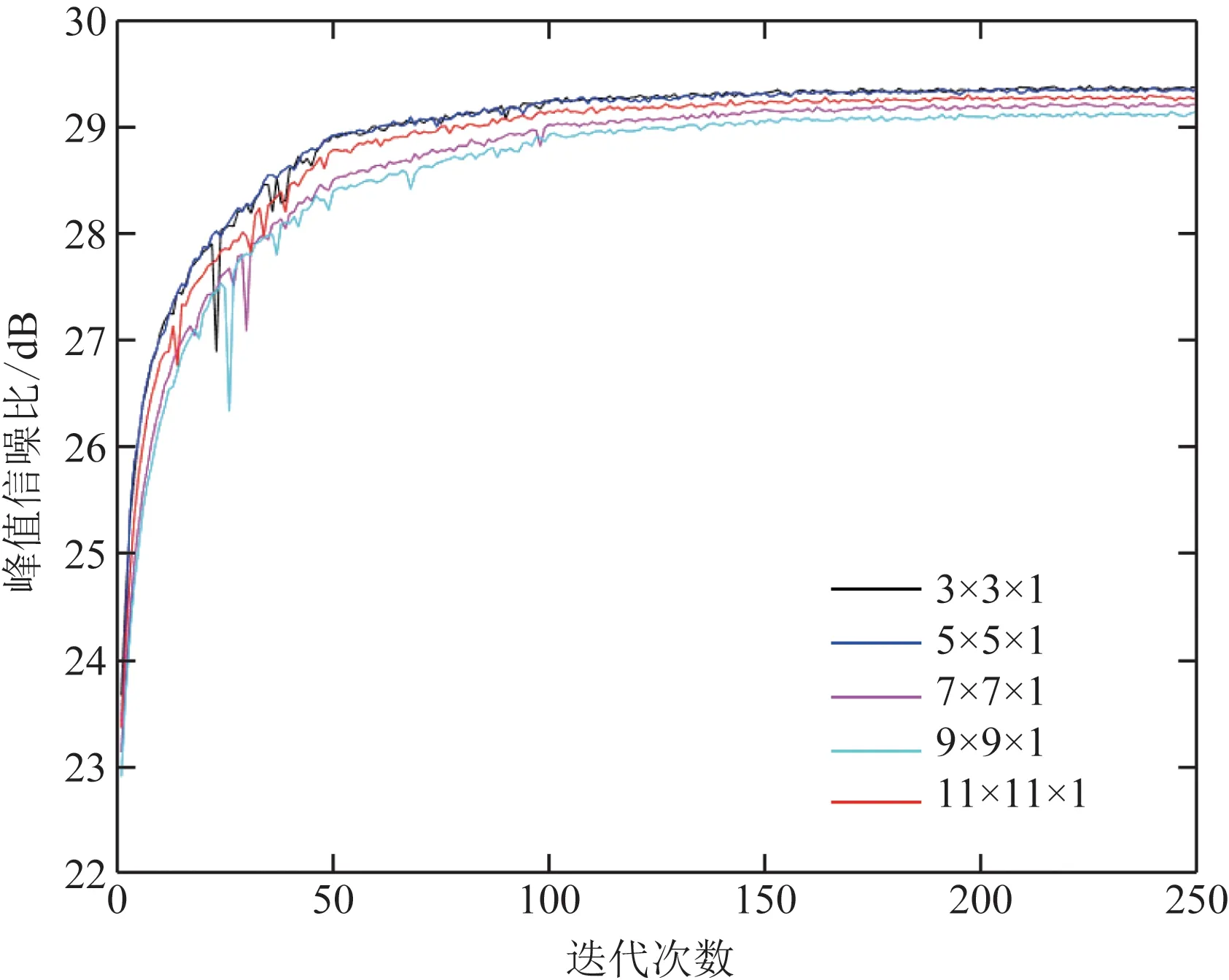
图13 不同尺度卷积核对CSCNet模型去噪影响Fig.13 The influence of different scale convolution kernels on the denoising of CSCNet model

图14 不同数量卷积核对CSCNet模型去噪影响Fig.14 The influence of different numbers of convolution kernels on the denoising of the CSCNet model
从图5、图6、图7(a)中可以看出,在CSCNet模型中仅加入BN、Relu函数对原始模型带来的效果并不明显,甚至可能没有不加之前效果好,但是在CSCNet模型中同时加入两者后新模型整体收敛速度要比原始模型更平稳,而且最终收敛值要比原模型高一些。从图5、图6、图7(b)中可以看出,在模型中只加入基础残差块结构在一定程度上影响模型去噪效果,在模型1结构基础上加入基础残差块对模型影响可能没有不加之前要好,但是与原始模型相比去噪效果有了些许提升。图8~图12是对比不同步长同时加入BN、Relu函数、基础残差块结构对CSCNet模型去噪影响。从中可以看出在步长不同时仅加入BN或者Relu对模型带来的影响并不大,甚至可能没有原模型效果好,但从图8~图12中可以看出,当步长为7时模型整体从收敛速度以及收敛值来说要好一些,也即图中蓝色曲线部分。图13、图14描述的是如何设置残差块结构中卷积核,可以看出卷积核并不是加入越多、设置的越大越好。
3 实验结果
通过实验对比模型1、模型2与CSCNet模型去噪效果。CSCNet原模型、模型1、模型2中LISTA迭代为Gregor等[5]所提出的可学习的迭代收缩阈值算法。实验中以文献[39]中BSD432图像集60幅、120幅为一组分别记为训练集1与训练集2,接着以文献[40]中Waterloo exploration database图像集60幅、120幅为一组分别记为训练集3与训练集4。再以文献[32]中Set12作为测试集,文献[39]BSD68图像集中20幅图像为一组作为测试集2。在上述实验中测试集中的图像均不会出现在训练集中。为方便对比实验结果,各模型均采用DCT变换初始化卷积字典,CSCNet模型、模型1、模型2卷积步长均设置为7。测试实验是在i7-8550U 1.8 GHz CPU和8 GB RAM的设备上进行的。
表2~表9是各模型在不同训练集不同测试集上所得结果对比,最终结果取多次重复实验所得结果的平均值。表10显示的是各模型在训练集1、Set12测试集上每次迭代所需平均时间对比。表11描述的是各模型所使用参数对比情况。

表2 训练集为1时各模型在测试集Set12上平均峰值信噪比值对比Table 2 Comparison of average peak signal-to-noise ratio of each model on test set Set12 when training set is 1

表3 训练集为1时各模型在测试集2上平均峰值信噪比值对比Table 3 Comparison of average peak signal-to-noise ratio of each model on test set 2 when training set is 1

表4 训练集为2时各模型在测试集Set12上平均峰值信噪比值对比Table 4 Comparison of average peak signal-to-noise ratio of each model on test set Set12 when training set is 2

表5 训练集为2时各模型在测试集2上平均峰值信噪比值对比Table 5 Comparison of average peak signal-to-noise ratio of each model on test set 2 when training set is 2

表6 训练集为3时各模型在测试集Set12上平均峰值信噪比值对比Table 6 Comparison of average peak signal-to-noise ratio of each model on test set Set12 when training set is 3

表7 训练集为3时各模型在测试集2上平均峰值信噪比值对比Table 7 Comparison of average peak signal-to-noise ratio of each model on test set 2 when training set is 3

表8 训练集为4时各模型在测试集Set12上平均峰值信噪比值对比Table 8 Comparison of average peak signal-to-noise ratio of each model on test set Set12 when training set is 4

表9 训练集为4时各模型在测试集2上平均峰值信噪比值对比Table 9 Comparison of average peak signal-to-noise ratio of each model on test set 2 when training set is 4

表10 不同模型测试时间对比Table 10 Comparison of Test Time of Different Models

表11 不同模型参数对比Table 11 Comparison of different model parameters
从表2~表9中实验数据可以看出,模型1、模型2所得结果相比原CSCNet模型所得结果略有提升,当所添加噪声程度较低时这种。使用本文研究所设计的两种模型去噪后的结果要比原S-BCSC算法以及原始CSCNet网络模型要好一些,这种优势在噪声程度较低时会明显一些。表10、表11是各模型运行时间以及参数对比,可以看出模型1、模型2再不大幅增加CSCNet模型计算负担的前提下使模型去噪效果略有改善。
4 结论
围绕迭代求解近似编码向量过程中卷积、反卷积层叠加会改变CSCNet模型中数据分布方式,通过在原模型中加入BN、Relu函数,先后设计了模型1、模型2。通过一系列实验验证所设计模型可行性,通过实验得出模型1、模型2最终所得结果要优于S-BCSC算法以及CSCNet模型。但由于实验设备有限仅在部分数据集上进行实验,后续会继续扩大数据集来进一步验证所提方法有效性。模型1、模型2虽然所得结果相比CSCNet模型所提升,但提升结果并不是特别明显,后期会继续结合其他可行方法对CSCNet模型做进一步研究。
