低度数值信息节点可按序消除的卢比变换编码算法
2021-10-08程乃平廖育荣倪淑燕雷拓峰
程乃平, 宋 鑫, 廖育荣, 倪淑燕, 雷拓峰
(1.航天工程大学电子与光学工程系, 北京 101400; 2.航天工程大学研究生院, 北京 101400)
喷泉码[1]最初是针对二进制删除信道(binary erasure channel, BEC)设计的,旨在为大规模数据分发和可靠广播场景提供一种理想的解决方案[2]。以卢比变换(Luby transform, LT)码[3]为代表的喷泉码,具有天然的信道自适应特性,可以灵活地产生任意数量的编码符号,因此,无论信道删除概率多大,发送端总能源源不断地产生编码数据直到接收端恢复出源数据。这使得它非常适合应用于传输视频和音频的广播场景[4]、协作中继场景[5]、水声通信场景[6]、不等差错数据保护场景[7-8]等。
尽管喷泉码最初是面向BEC进行设计的,但其在加性高斯白噪声(additive white gaussian noise, AWGN)信道中也具有潜在的应用前景[9-10]。文献[11]研究结果表明,LT码在二进制对称信道(binary symmetric channel, BSC)和AWGN信道中存在明显的误码平台。文献[12-15]考虑通过优化校验度分布来改善误码平台。文献[12]针对二进制输入AWGN(binary input AWGN, BIAWGN)信道,提出以最大化LT码的码率值为目标函数,采用线性规划的方法求解出最优的度分布系数。文献[13]针对极低信噪比条件提出了一种改进的度分布设计方式。文献[14]给出了一种适用于大范围信噪比的度分布函数策略,通过及时调整度分布函数以保持足够高的码率效率。文献[15]针对系统LT码,引入了误比特率(bit error rate, BER)下界作为新的约束条件,实现了以更小的译码开销进入瀑布区的效果。
但是,在BIAWGN信道中,通过优化校验度分布来提升BER性能,却存在以下两个问题:①度分布设计不可避免地引入了高斯噪声方差作为初始条件,且仅对某一小范围内的信噪比最优;②优化的度分布函数改善误码平台的效果有限,特别是在码长较短时。
针对上述问题,现暂不考虑优化度分布的问题,而是试图通过改进LT码的编码算法来提升其BER性能。文献[16]指出误码平台主要是由不可靠的小度数值信息节点造成的。为此,文献[16]提出了一种基于节点分类选取的改进编码算法,这种算法使得几乎所有的信息节点都具有了相同的度数值。文献[17]则将文献[16]的编码思想应用到了不等差错保护场景中,以略微增加译码开销为代价,将最重要数据(most important bits, MIB)的BER平台降低了将近3个数量级。文献[18]的改进算法,是在校验节点选择每个信息节点时,都先从所有的信息节点中随机选取T个节点作为一组,然后再从这一组中选择度数最小的信息节点进行连接。需要说明:文献[17]中改进算法对BER性能的提升程度取决于额外引入的参数T,但是却没有给出关于该参数的严谨设计方法。相较于文献[18],文献[19]的改进算法则引入了更多的参数,如衡量校验节点度数值大小的参数d*。若当前校验节点的度数大于d*,则将优先连接至小度数值的信息节点;若度数小于d*,则仍从所有的信息节点中随机选取;若等于d*,则依据预先给定的权重确定选取方法。仿真结果显示,这几种改进算法在BEC或者AWGN信道中都能够使LT码更快地进入BER瀑布区,并能显著地降低误码平台。
但是这几种改进算法也存在下述问题:①没有给出算法所涉及参数的选取原则;②算法的编码过程不具备可调控性;③缺乏对算法收敛性的分析。
针对上述问题,现设计一种面向AWGN信道的改进LT编码算法。引入可变的阈值对信息节点进行分类,将度数值相对较小的信息节点聚集在一起,并强迫这些节点频繁地连接至校验节点,从而使其获得足够可靠的度数值。首先,分析误码平台的成因,设计阈值递增的节点按序消除编码算法。其次,计算改进算法的理论BER下界,分析不同参数对改进算法BER性能的影响。最后,分析改进算法对LT码收敛性的影响,并指出算法参数的选取原则。改进算法能够显著地降低LT码的误码平台,实现优于文献[16-18]的BER性能。
1 传统LT码模型
1.1 LT码的编码算法
对于传统LT码,编码器会对K个信息节点v={v1,v2,…,vK}进行编码,生成N个校验节点c={c1,c2,…,cN},且N个编码节点与校验节点一一相连。LT码的Tanner图如图1所示。
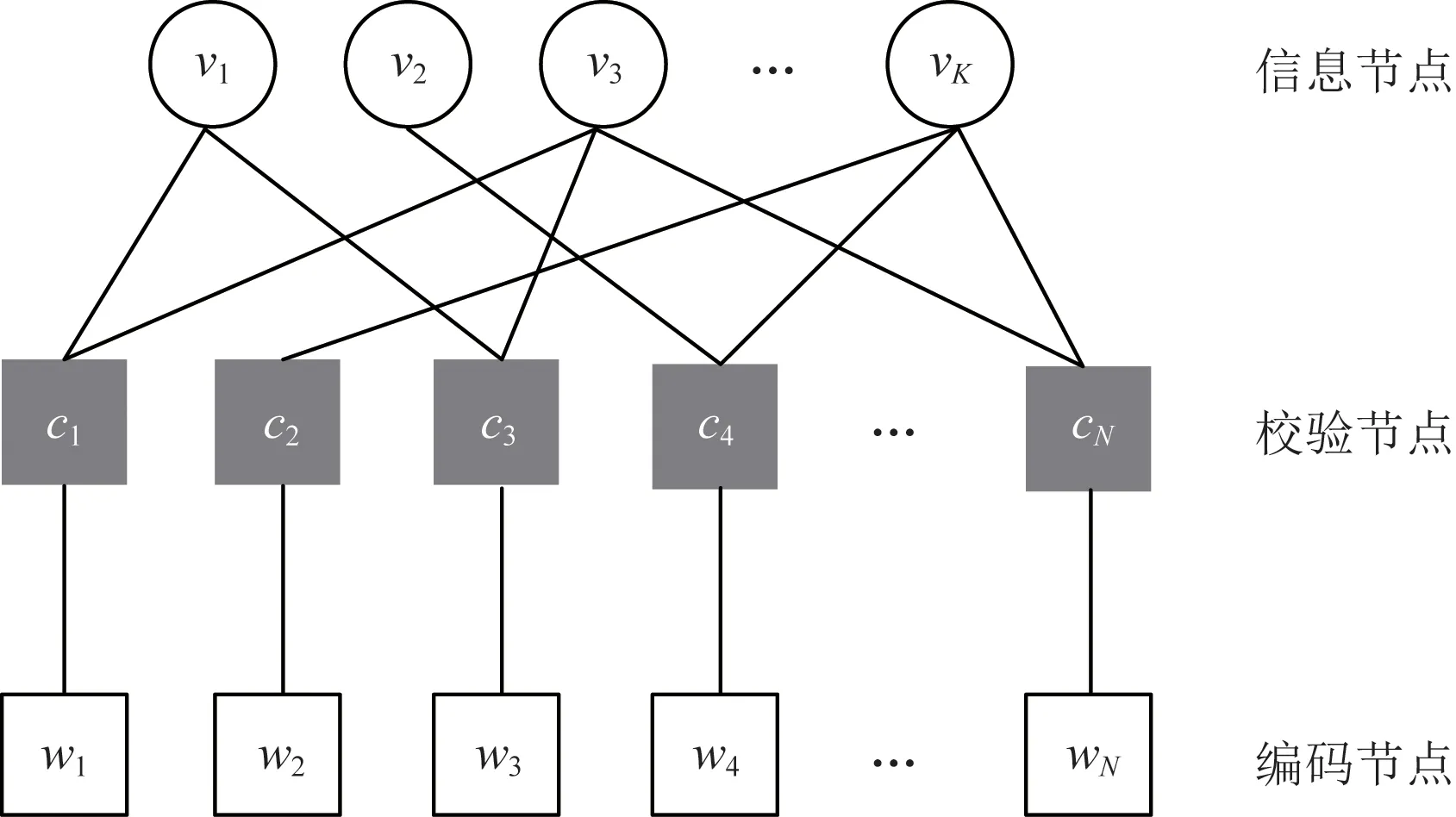
图1 LT码的Tanner图Fig.1 The Tanner graph of LT codes
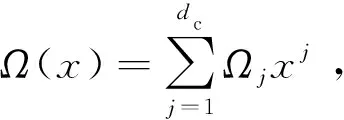

算法1 传统LT码的编码算法
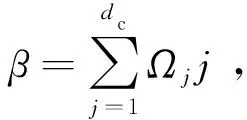
(1)
根据文献[11]可知,传统LT码的信息度分布可以看作以α为均值的泊松分布,即
(2)
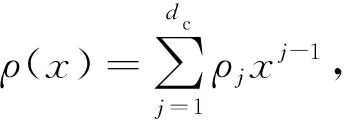
(3)
(4)
1.2 LT码的译码算法
在AWGN信道中,LT码采用置信传播(belief propagation, BP)算法进行迭代译码。该算法将对数似然比(log-likelihood ratio, LLR)信息在信息节点和校验节点之间进行迭代更新,使LLR信息逐渐收敛于稳定值并据此进行最佳判决。
令Lcj→vi表示迭代过程中第j个校验节点传递给第i个信息节点的LLR信息,定义为
(5)
(6)
式(6)中:N(i)(j)为除第j个校验节点之外,与第i个信息节点相连的所有校验节点的集合。
对于信息节点vi,其LLR判决值为
(7)
当达到最大迭代次数后,采用式(8)对比特值进行判决:
(8)
2 改进的LT编码算法及分析
2.1 改进的LT编码算法
传统LT码在生成度数为d的校验节点时,是随机选取d个信息节点进行异或,在这种方式下得到的信息节点度分布近似服从泊松分布。然而,从式(1)和式(2)中可以看出,即使α足够大时,小度数值信息节点(包括度数为0的节点)存在的概率仍不为零。因此,可以预测在大量重复试验时,必然还会出现一定数量的小度数值信息节点,这些节点所连接的校验节点很少,在译码过程中往往无法获得足够多的来自校验节点的LLR信息,因此,很难对自身的比特值进行正确判决,可靠性较低。
针对这个问题,拟对传统编码算法进行改进,以消除小度数值的信息节点,进而提升LT码的BER性能[21]。考虑以更直接的控制方式,即引入一个阈值,用于筛选出度数值小于该阈值的信息节点,并迫使这些节点频繁地参与校验节点的生成,从而使其获得足够可靠的度数值。此外,阈值是可变的,因此,可以保证改进算法持续发挥作用,按序消除低度数的信息节点,且能够便捷地控制信息节点能够达到的最小度数值。
具体而言,将编码过程分为两个阶段。第一个阶段,利用可变的阈值筛选出待编码的信息节点并动态更新,在生成校验节点时,只能从这些信息节点中选取。第二个阶段,当阈值达到给定的上限时,恢复为传统编码算法。编码过程如算法2所示。

算法2 改进的LT编码算法
所提出的改进算法的优点有以下几个方面。
(1)能够精准地消除小度数值的信息节点。算法2引入阈值,在每个校验节点生成之前,将所有可靠性较低,即度数值相对较小的信息节点汇聚在一起,从而使得这些节点能够始终优先连接至更多的校验节点。此外,在第一阶段的编码过程中,阈值是递增的,因此,能够确保所有的低度数值信息节点均被按序消除,不存在遗漏。
(2)能够灵活地调整信息节点能够达到的最低度数值。从算法2中可看出,编码后的信息节点最小度数值即为阈值上限,因此,可以通过改变阈值上限,调整信息节点的度数值下界,进一步可以借此预测算法的BER性能。这可以利用极限思维分析:若Tv为0,则所有的信息节点都将被无差别地选取,改进算法将退化为传统的编码算法,且仍然保持较高的误码平台。若Tv的值较为合理,则度数值相对较小的信息节点就能始终被高概率地选取,从而获得不小于Tv的度数值。
需要说明的是,通过改变阈值上限并非能够无限制地增大信息节点的度数值。这是因为,随着编码的进行,信息节点的度数会不断地向阈值上限处累积,这会造成某一种度数值的信息节点大量聚集。在这种情况下,若要再提高这些信息节点的度数值,将耗费更多的校验节点。但是,通信系统往往期望能以最小的译码开销实现成功译码,因此,校验节点的个数不能无限制地增大,这就限制了信息节点度数值的提升。
2.2 改进算法的复杂度分析
相较于传统算法,本文算法增加了分类信息节点的操作,因而不可避免地增加了算法的复杂度,下面对其进行详细分析。
传统LT编码算法中,关键步骤包括:①依概率选取校验度数d;②随机选取d个信息节点;③将选中的d个信息节点进行异或。对比算法2可知,本文算法主要对传统算法的第二步进行了改动,而在选取校验度数和求异或值时,与传统算法完全相同。因此,现重点分析信息节点的选取方式对编码复杂度的影响。
算法2中,每个校验节点选取信息节点时,新增操作为:节点按度数值大小排序、度数值d和阈值大小比较。但是,当阈值达到上界Tv时,便不再进行这两种操作。类似地,文献[16]中的改进算法增加的操作为:节点按度数值大小排序、度数值d和每种度数节点个数大小比较。文献[18]中的改进算法增加的操作为:随机选取T个节点、节点按度数值大小排序、已选信息节点和当前所选信息节点的序号比较。表1给出了上述几种算法在生成N个校验节点时,所产生的新增操作及其次数。
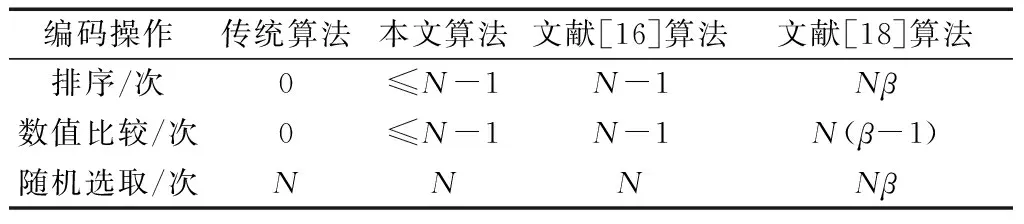
表1 生成N个校验节点时的新增操作对比Table 1 Comparison of new operations when generating N check nodes
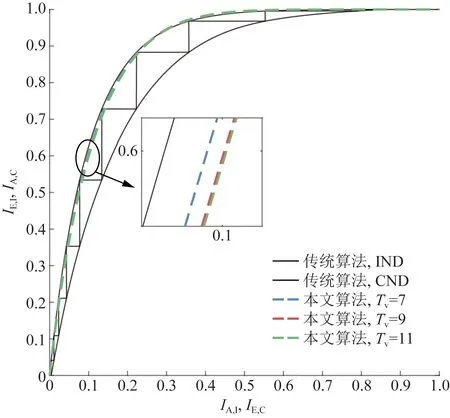
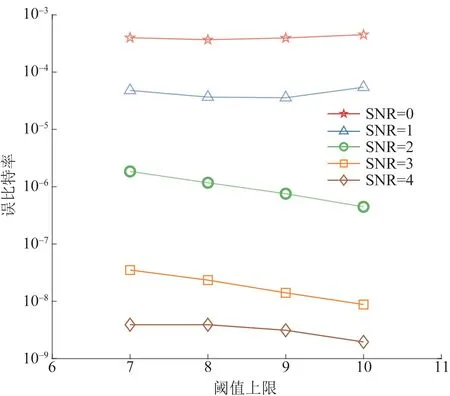
对于三种改进算法而言,生成每个校验节点时需对信息节点按度数值大小进行排序,这必然会增加编码复杂度。以归并排序算法为例,在本文算法和文献[16]算法中,其平均时间复杂度均为O(Klog2K)。但本文算法的排序、数值对比次数均不超过文献[16]算法,因此,本文算法的编码复杂度要低于文献[16]算法,但两者均高于传统算法。对于文献[18]算法而言,其平均时间复杂度为O(Tlog2T),其中T为该算法中的参数且T 表2给出了三种改进算法的编码运行时间。设计仿真次数为2 000次,K=512,N=1 024。其中,本文算法阈值上界Tv=10,文献[18]算法中T=3。可以看出,与传统算法相比,三种改进算法的平均编码运行时间均增加了。但本文算法的运行速度则相对较快,这与上述分析结果相一致,也体现了本文算法的优势。 表2 不同算法的平均运行时间Table 2 Average running time of different algorithms 评价LT码的好坏,通常从BER性能和收敛性两方面进行考虑[12]。文献[16]中指出,在BIAWGN信道中,传统LT码的平均BER的下界可表示为 (9) 从式(9)中可以看出,LT码的BER下界只与信息节点的度分布有关,因此,在设计改进的编码算法时,一般只需要考虑信息节点的分布情况即可。为了观察改进算法对误码平台的影响,仿真了不同参数下的理论BER下限,结果如图2所示。仿真采用的码率值为1/2,度分布为文献[22]中为K=512设计的校验度分布,记为Ω1(x)。 从图2中可以看出,改进算法能够显著地降低LT码的误码平台,并且,当阈值上限增加时,BER性能也会随之提升,这验证了算法的有效性。 图2 改进算法的BER下界Fig.2 The BER lower bound of the improved scheme 需要说明的是,这仅仅是理论计算结果,可能会与实际仿真结果存在一定的差距,主要有以下两点原因:①有限码长引起的损耗,式(9)是针对码长无限长时的计算情况,因此,当采用中短码长时,实际的BER性能可能会有所损耗,且码长越短,与理论BER下限之间的差距越大;②度分布改变造成的差距,传统算法的信息度分布近似服从泊松分布,而改进算法的度分布则无明显的规律,因此,采用式(9)直接计算BER时可能会造成偏差。 改进算法改变了信息节点的选取方式,但是并不希望出现无法收敛导致译码失败的情况,因此,对改进LT码的收敛性进行分析。 LT码在AWGN信道中采用BP算法进行迭代译码,分析LT码译码收敛性常用的工具为外信息传递(extrinsic information transfer, EXIT)图法。参照文献[23-24],定义单调递增函数J(θ)为 (10) 式(10)中:ε为积分变量;σ为噪声N的标准差;J(θ)具有唯一的反函数为θ=J-1(I)。关于J(·)和J-1(·),文献[25]中给出了一种近似的计算方法。为便于分析,将LT码的译码器分为校验节点译码器(check node decoder, CND)和信息节点译码器(information node decoder, IND)。在BIAWGN信道下,LT码CND的EXIT公式为 (11) LT码IND的EXIT公式为 (12) 式(12)中:σI为来自CND的先验信息的标准差,σI=J-1(IA,I),IA,I为信息节点的输入先验信息。 本文中的改进算法会改变信息节点的度分布,但不改变校验度分布。因此,令改进算法的IND的EXIT公式为 (13) 式(13)中:λi(S)为改进算法的信息节点边的度数分布;dv(S)为改进算法的最大信息节点度数值。 图3 改进算法和传统算法的收敛性对比Fig.3 The convergence comparison between the improved algorithm and the conventional algorithm 在图3中,定义CND曲线和IND曲线之间的空隙为“译码收敛区”。理论上而言,如果两条曲线没有交点,那么当码长K足够长时,译码器总可以经过有限次迭代成功恢复出源信息,图3中的阶梯即为迭代轨迹。可以看出,仿真结果与分析结论吻合。即改进算法的CND曲线与传统算法的CND曲线会重合,而两者的IND曲线则存在1个或多个交点。这说明在不同的先验信息IA,I条件下,改进算法和传统算法的输出外信息差值正负不定,可以直观地理解为:译码收敛区在不同位置会出现拓宽和压缩的情况。 若改进IND曲线位于下方,表明改进算法损失了一定量的外信息,译码收敛区被压缩;若改进IND曲线位于上方,表明改进算法获得了额外的外信息增益,译码收敛区被拓宽。当信噪比较低,或者码率值较小时,压缩现象会更为明显,严重时会导致算法无法成功收敛。这意味着,改进算法是以略微损失收敛性为代价,换取了误码平台的大幅度降低。因此,为改进LT码仍能成功译码,应合理设计阈值上限以确保:①译码收敛区是打开的;②被压缩的区域不应过窄。这为改进算法的设计指明了一条原则。 为验证本文算法的有效性,对改进LT编码算法的性能进行仿真分析,并与传统算法、参考文献算法进行对比。为便于对照,记文献[15]中的算法为等度数(equal degree, ED)算法。仿真条件为:发送端采用BPSK调制方式,采用校验度分布Ω1(x),码长K=512;接收端采用BP迭代译码算法,最大迭代次数设置为50次。所有的结果均通过500 000次蒙特卡洛仿真得到。 图4 R-1=2时,不同阈值上限时的BER性能Fig.4 The BER performance at different upper bounds of the threshold when R-1=2 图5 信噪比为1 dB时,不同阈值上限时的BER性能Fig.5 The BER performance at different upper bounds of the threshold when SNR=1 dB (1)改进算法存在明显的瀑布区。从2.1节中得知,传统算法存在明显的误码平台,即当BER达到某一界限时,继续增加信噪比或者增大译码开销,均不能使BER产生明显的降低。但是,从图4中可以看出,与信噪比为2 dB相比,3 dB时的BER下降了近两个数量级;类似的,图5中,相比于R-1=2.2,R-1=2.3时的BER也降低了近两个数量级。这意味着,增大信噪比和译码开销时,改进算法能够实现BER的瀑布式下降,从而显著地提升了LT码的性能,这也验证了算法的正确性。 (2)提高阈值上限,能够提升算法的BER性能。这是因为,提高阈值上限时,改进算法能够达到的最低信息节点度数值也随之提升。这意味着,可靠性较低的信息节点越来越少,因此,误码平台将会进一步降低。这与2.3节中的结论一致。 图6 改进算法在不同信噪比时的BER性能Fig.6 The BER performance of the improved algorithm at different SNRs 图7 改进算法在不同码率值时的BER性能Fig.7 The BER performance of the improved algorithm at different code rates (2)改进算法的BER性能,随着的Tv增加而提升。这与3.1节中的结论完全一致,此处不再赘述。 (3)通过合理设置参数,改进算法能够实现优于参考文献算法的性能。例如,图6中当Tv=7时,改进算法与ED算法的性能相近,但当Tv=10时,改进算法的性能便明显优于ED算法。类似的,在图7中,尽管Tv为7和8时,BER性能不及ED算法,但当Tv为10时,便可获得低于ED算法的BER下界,这也体现了本文算法的优势。 针对LT码在AWGN信道中存在的严重误码平台问题,设计了一种改进的编码算法。主要思想是对信息节点进行分类筛选,并迫使度数值最小的一类信息节点优先参与编码,从而达到了消除低度数值信息节点的目的。通过理论推导和仿真分析,可得出以下结论。 (1)改进算法能够显著地降低LT码的误码平台。在本文中仿真条件下,与传统算法相比,改进算法可将BER下界降低近3个数量级,并获得近3.5 dB的编码增益。 (2)可以通过改变阈值上限,调整改进算法的BER性能。当阈值上限较大时,算法的持续效果会更久,可靠性较低的信息节点会被不断地消除,从而进一步地降低了误码平台。这为合理地设置算法参数提供了依据。 (3)改进算法能够实现优于参考文献算法的BER性能。当阈值上限较小时,改进算法的BER性能差于ED算法;但通过调整参数,改进算法总可以达到优于ED算法的BER下界,体现了本文算法的优势。 (4)改进算法的收敛性略有损失。算法规定了校验节点必须选取度数值靠前的信息节点,这会在一定程度上破坏LT码的随机性,且不利于快速收敛。因此,下一步研究中可以考虑设计具有无损收敛性的编码算法。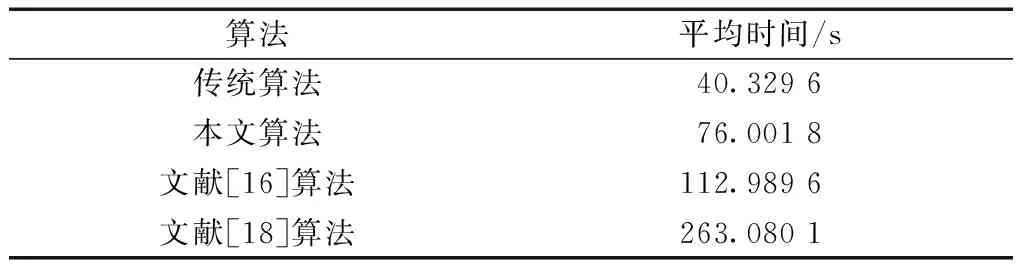
2.3 改进算法的BER性能分析
2.4 改进算法的收敛性分析
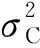
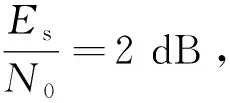
3 仿真结果
3.1 不同参数对算法性能的影响
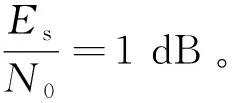
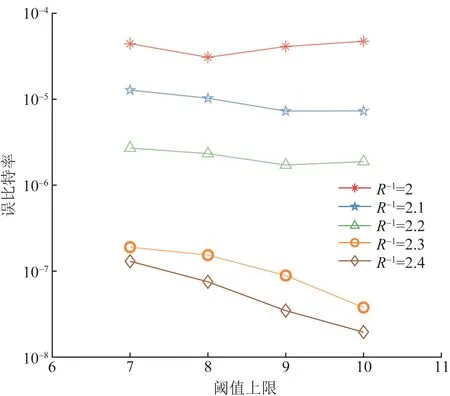
3.2 传统算法与改进算法的性能对比
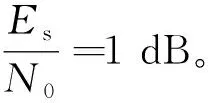
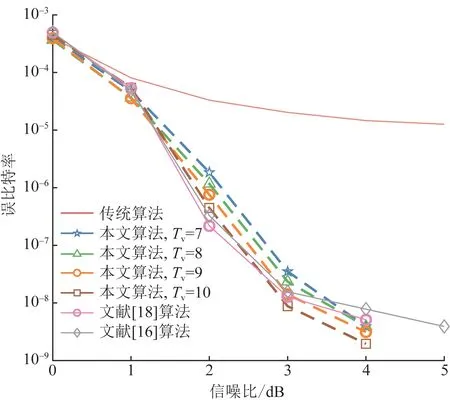
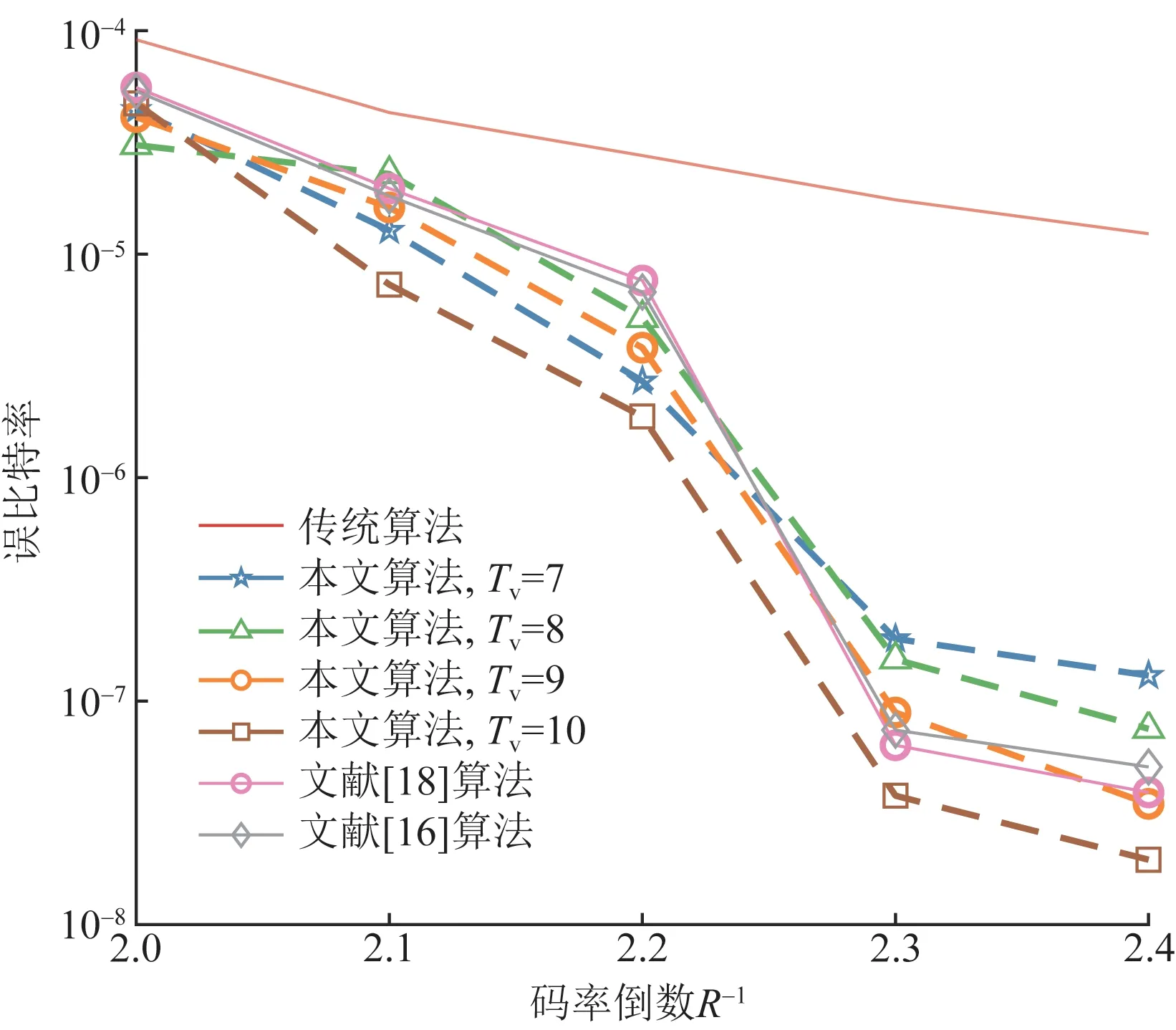
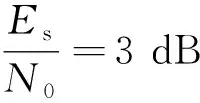
4 结论
