基于N-gram特征的加权朴素贝叶斯文本分类算法
2021-09-27王瑛,荣麒,王勇
王瑛,荣麒,王勇


摘要:朴素贝叶斯算法由于其具有简单、稳定和高效的优点,被广泛运用在文本分类领域,但由于算法所涉及属性的独立性和同等重要性,算法的文本分类效果并不理想。针对以上问题,该文采用一种基于N-gram特征的加权朴素贝叶斯文本分类算法的模型对5种文本进行分类实验,然后将实验得到的准确率、召回率、F1值等评价标准对模型进行评估,并与传统的朴素贝叶斯模型分类算法得到的结果进行比较,结果表明分类效果得到较大的提升。
关键词:朴素贝叶斯;N-Gram;加权;文本分类
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2021)19-0136-03
Weighted Naive Bayes Text Classification Algorithm Based on N-gram Features
WANG Ying, RONG Qi, WANG Yong
(School of Computers, Guangdong University of Technology, Guangzhou 510006, China)
Abstract: The Naive Bayes algorithm is widely used in the field of text classification because of its simplicity, stability and efficiency. However, due to the independence and equal importance of the attributes involved in the algorithm, the text classification effect of the algorithm is not ideal. In response to the above problems, this paper uses a weighted naive Bayesian text classification algorithm model based on N-gram features to classify five types of texts, and then compare the accuracy, recall, F1 value and other evaluation criteria obtained from the experiment to the model It is evaluated and compared with the results obtained by the traditional Naive Bayes model classification algorithm. The results show that the classification effect has been greatly improved.
Key words: Na?ve Bayes; N-Gram; weighted; text classification
1 背景
朴素贝叶斯是一种简单又高效的分类算法,并且有强大的数学理论背景做支撑,其在分类过程中效率稳定,在很多领域表现出非常好的性能,被广泛应用于文本分类领域,但其用于文本分类的效果不够理想,有很大的改进空间。本文采用N-gram特征提取方法结合加权后的朴素贝叶斯分类算法对文本进行分类,本文第2部分介绍了传统的朴素贝叶斯文本分类算法的理论及其实现原理;第3部分主要介绍利用N-gram模型对文本进行特征词提取和利用TF-IDF模型对特征词进行加权;第4部分介绍了本文的实验,实验结果表明基于N-gram特征的加权朴素贝叶斯模型相比于传统的朴素贝叶斯有更好的文本分类效果。
2 朴素贝叶斯算法
朴素贝叶斯算法是一种典型以贝叶斯算法为基础的分类算法,其所涉及的各个特征必须相互独立,主要思想就是:对于给定的文本类标签集合C = {[c1],[ c2],[ c3],….,[ cn] }以及一个待分类的文本d,计算出输入各个类别的条件概率[Pci|d(i=1,2,…,n)],选出最大值,其对应的类别就是该文本所属的类别。朴素贝叶斯文本分类公式如下:
[pci|d=argmax pcik=1m pwk|ci]
其中,先验概率[pci]表示文本训练集中[ci] 类文本的数量在所有文本训练集数量中所占的比重,[pwk|ci]计算公式如下:
[ pwk|ci=l=1|D|Nwk, dl +1s=1|V|l=1|D|Nwk, dl+∣V∣]
其中[wk]表示某一特征词,[m]表示测试文本[d]包含的特征词数目,文本[dl]表示文本类[ci]中的某一训练文本,[i=1|D|Nwk, ci ]表示[wk]在类型为[ci]文本中的出现的次数,[i=1|D|Nwk, ci]表示在类型为[ci]的文本中出现特征词[wk]的总次数,[∣V∣]表示特征词总数目,[∣D∣]表示[ci]中文本数目。其为了防止0次的特征词对分类决策的影响,采用“拉普拉斯修正”,进行+1平滑操作。
3 N-gram特征提取和加權
3.1 N-gram特征提取
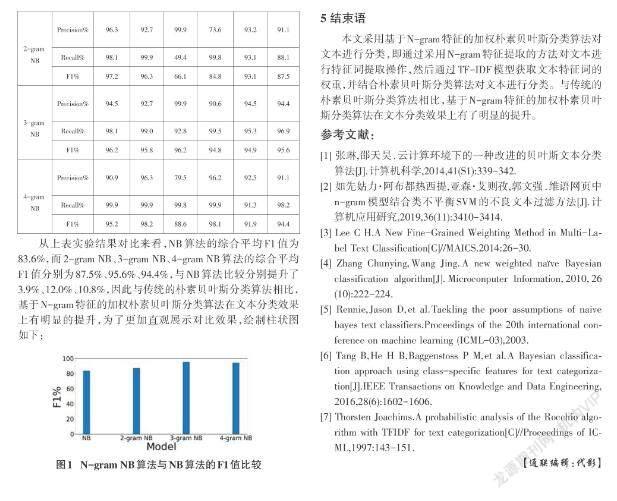
N-gram模型是基于统计语言的模型,它的基本思想是将文本内容滑动到N个字节大小的滑动窗口中,形成N个字节长度的片段序列。 每个字节片称为一个gram,对所有gram片段执行词频统计,并根据设置的阈值将词频较低的特征进行过滤操作,最后形成关键字gram列表,即文本的特征向量空间。
