浅析Hadoop高可用的配置
2021-09-10刘庆生陈位妮
刘庆生 陈位妮










摘要:高可用是保持服务高度可用性的一种设计。Hadoop高可用是应用在只有一个NameNode节点无法在故障宕机或者升级软硬件需要重启时而导致中止服务时,可快速用候补节点替代。要实现Hadoop高可用性,配置高可用是关键,特别要掌握配置过程中的技巧。
关键词:高可用、Active(服务)、Standby(候补)、配置
HA is a design to keep services highly available.Hadoop’s HA is mainly used in cases where only one NameNode node is unable to suspend service in the event of a failure or a software or hardware upgrade requiring a restart,and can be quickly replaced with a standby node. To achieve Hadoop’s HA,configuration high availability is the key,especially to master the skills in the configuration process.
一、什么是高可用
高可用(High Availability),简称HA,是通過专门设计来减少不可用时间并保持其服务高度可用性的一个系统。它能监测与排除软件故障、备份和数据保护、监视各站点运行情况,并随时或定时报告,主动采用必要的控制手段、实现错误隔离、切换的主备份服务器间的服务。其核心体现在配置多台服务器发生故障后,能快速的自动切换。
二、hadoop集群高可用的应用背景
hadoop集群一般包括一个NameNode和三个DateNode节点,由FSNameSystem负责管理可靠性低的内存中的数据。因fsimage持久化操作只在edits中更新,当客户端操作时,变化的元数据仅在日志里面记录过程,只有操作成功后,才在内存中记录数据,因而edits中记录的数据与fsimage中的数据没有合并,故SecondaryNameNode每隔一段时间需将edits文件下载合并后加载到内存形成新的元数据,再把内存中的数据形成新的fsimage发送到NameNode节点,来替换原有的fsimage。若仅有一个NameNode节点,当故障宕机或升级软硬件需重启时,Hadoop会暂时中止服务,hdfs无法提供服务,导致可用性降低。若hadoop集群有两个NameNode节点,一个节点发生故障便可用另一个节点来代替,就可以解决无法持续提供服务的问题。
三、Hadoop高可用的配置(以搭建3个节点组成的Hadoop高可用模式集群为例)
1、高可用群集规划。分析Hadoop HA架构,集群由3台主机组成,先准备三台已配好ZooKeeper组件的虚拟机,其参数如表1:
2、安装Hadoop
执行/softs stud tar - zxvf hadoop-2.7.3.tar.gz -c/usr/local将Hadoop安装包解压到安装目录,更名为/usr/local/Hadoop,修改目录权限。在/usr/local/Hadoop目录下创建tmp子目录。
执行vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml,编辑hdfs-site.xml文件,共16个属性和值。
执行vi /usr/local/hadoop/etc/hadoop/core-site.xml,编辑core-site.xml文件,共3个属性和值。
执行vi/usr/local/hadoop/etc/hadoop/mapred-site.xml,编辑mapred-site.xml文件,共3个属性和值。在编辑mapred-site.xml文件时,先由模板mapred-site.xml.template复制生成mapred-site.xml。
执行vi /usr/local/hadoop/etc/hadoop/yarn-site.xml,编辑yarn-site.xml文件,共8个属性和值。
执行vi /usr/local/hadoop/etc/hadoop/slaves,编辑slaves文件。其中虚拟机master1、master2、slave是DataNode节点。
3、设置JAVA_HOME
在/usr/local/hadoop/etc/hadoop下的hadoop-env.sh、yarn-env.sh、mapred-env.sh三个配置文件中设置JAVA_HOME,增加语句:export JAVA_HOME=/usr/local/jdk,如果存在JAVA_HOME配置语句,注释后再增加。
4、配置Hadoop环境变量
用vi .bashrc命令编辑.bashrc文件,文件内容如图1所示:
5、加载环境变量
用source .bashrc命令使设置的环境变量生效,在master1虚拟机上用hadoop version命令测试。
6、目录打包、复制分发、解包
将/usr/local/hadoop目录打包,使用scp命令分发到master2、slave并解包到/usr/local目录。分别在master2和slave上执行。如图2所示:
7、分发加载.bashrc文件
将master1上的~/.bashrc文件分发到master2、slave,并加载。在master2和slave上执行。
8、初始化
(1)启动ZooKeeper组件
分别在三台虚拟机上用zkServer.sh start命令依次启动ZooKeeper组件,检查ZooKeeper的角色:一个leader和两个follower。
(2)启动所有节点的journalnode进程
启动后,三台虚拟机进程都包括:journalNode、quorumPeerMain两个进程。
(3)在master1上执行格式化命令
在master1上格式化~$ hdfs namenode - format,因兩个NameNode管理同一个元数据,所以仅需在一个NameNode上格式化。
(4)启动master1虚拟机上的NameNode进程
启动后,master1包括NameNode、journalNode、quorumPeerMain三个进程。
(5)在master2上同步master1上的元数据
在master2上执行~$ hdfs namenode -bootstrapStandby,图4所示信息表示同步成功。
(6)停止master1的NameNode进程
在master1上执行~$ hadoop -daemon.sh stop namenode stopping namenode即可停止。
(7)同时开启DataNode进程
执行master1的~$ hadoop -daemon.sh start datanode,即同时开启所有主机上的DataNode进程。
(8)初始化zkfc监听
执行master1上~$ hdfszkfc - formatZK,进入ZooKeeper客户端,用ls命令显示如图5所示的hadoop-ha节点。
(9)在两台主机上单步启动zkfc
在master1和master2执行~$ hadoop -daemon.sh start zkfc,单步启动zkfc。
(10)在两台主机上单步启动NameNode
分别在master1和master2执行~$ hadoop -daemon.sh start namenode,单步启动NameNode。
(11)在master1上启动yarn
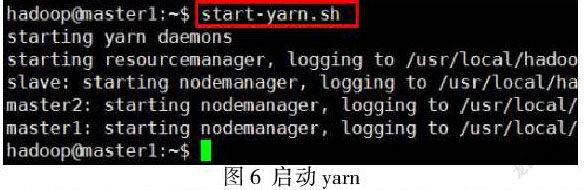
在master1上执行~$ start -yarn.sh,但只启动了如图6所示的一个resourcemanager,所以执行~$ yarn --daemon.sh start resourcemanager单独动master2的进程。
(8)检查三台虚拟机进程,如图7所示即完成了高可用的设置。
9、Hadoop高可用的日常启动
按ZooKeeper->所有节点的journalnode服务->所有节点的datanode服务->分别启动master1、master2上ZKFC监听器->分别启动master1、master2上namenode服务->启动master1所有节点的yarn服务->单独启动master2的resourcemanager进程顺序能正常启动,说明Hadoop高可用搭建完成。
10、关闭高可用集群。
执行master1的stop-all.sh后,如果master2上的resourcemanager进程无法停止,需在master2上手工停止;master1和master2上的JournalNode进程需单独停止。
11、查看高可用状态
分别用浏览器打开master1、master2的50070端口,在Web界面可以看到两个主机的高可用状态,如图8 所示。
12、测试Hadoop高可用
在Web界面看到两个NameNode节点,一个处于激活(active)状态,一个处于备用(standby)状态。手工停止处于激活状态节点(master2)的namenode进程,观察处于备用状态的节点(master1)是否能自动切换到激活状态。
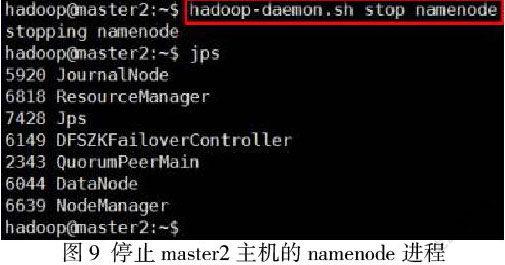
(1)手工停止master2虚拟机上namenode进程. 如图9所示:
(2)用浏览器查看master1和master2的50070端口。master1节点已经切换到active状态,master2节点则因为停止了namenode进程而无法访问。至此,Hadoop高可用配置成功。如图10、图11所示:
Hadoop高可用模式对硬件要求比较高,要求宿主机至少8G内存,才能开出3台1G内存的ubuntu虚拟机。建议创建5台虚拟机,将NameNode和DataNode分开到不同虚拟机中,搭建Hadoop高可用的虚拟机或服务器使用奇数台数。
Hadoop高可用的配置是一个比较复杂的过程,高可用性能能否在系统因故障停机时启用,关键在于搭建过程中配置是否正确。在实际搭建过程,出现缺失进程的情况,一般是配置出错使一些进程无法正常启动。所以在搭建过程要注意一些操作技巧避免出错:修改配置文件后,需重新格式化hdfs和zkfc。在格式化hdfs前,先删除tmp目录下所有内容;格式化zkfc前,需进入ZooKeeper客户端,删除hadoop-ha和yarn-leader-election节点。另外特别注意配置文件hdfs-core.xml中的dfs.namenode.shared.edits.dir值的设置,需设置为不运行namenode进程的主机。
参考文献:
[1]汤愈韬.Hadoop集群的高可用-HA[EB/OL].https://blog.csdn.net/qq_38200548/article/details/84790353.2018-07-05
[2]灯火阑珊.大数据之Hadoop HDFS-HA架构[EB/OL].https://zhuanlan.zhihu.com/p/82190205.2019-09-11
课题项目:2020年湖北省职教学会课题,课题名称:基于OBE理念课程体系建设的内在逻辑及实践路径研究-以大数据技术与应用专业为例,课题编号: ZJGA202022
作者简介:
刘庆生(1971-),性别:男,民族:汉,籍贯:湖北咸宁,职称:教授,本科,研究方向:大数据、人工智能
陈位妮(1974-),性别:女,民族:汉,籍贯:湖南常德,职称:教授,硕士,研究方向:大数据、计算机应用、职业教育
