面向众核处理器的水动力学CFD并行计算探索
2021-09-07张亚英吴乘胜王建春刘宏斌
张亚英 吴乘胜 王建春 刘宏斌
(1. 中国船舶科学研究中心 无锡 214082;2. 国家超级计算无锡中心 无锡 214072)
引 言
高性能计算已深入诸多科学与工程应用领域的数值模拟中,成为科技创新和提升核心竞争力的重要手段和支撑。具体到船舶水动力学领域,随着CFD计算量成几何量级增长,对计算能力的要求越来越高,在超级计算机上开展大规模计算渐趋普遍。
近年来,超级计算机架构正在发生由同构向异构发展的变革。由于“主频墙”的限制,单核处理器计算性能趋于极限;由于“通信墙”的限制,基于分布式的并行计算无法在大规模并行中获得优秀的加速效果;由于“功耗墙”的限制,通过大规模扩展通用处理器(CPU)提升计算能力也不太现实。因此,异构众核逐渐成为超级计算机架构的发展趋势。以2020年6月22日发布的超级计算机TOP500榜单为例,其中144台都采用加速器或协处理器,也就是采用异构众核架构;在榜单前10名中,8台采用异构众核架构;而近十年来登顶的超级计算机,全部采用异构众核架构。
异构是相对于同构而言,因此先简单介绍一下同构架构。同构架构中所有的计算核心都是由CPU构成,所有计算核心的逻辑处理能力和数据计算能力都很强,不受计算任务复杂度的影响;但其缺点是成本高、功耗大。异构与同构相比,计算核心的种类不同,一般既有CPU,也有协处理器。异构系统可以进行深层次并行,使计算任务划分更加细化,并行程度更高。典型的异构众核处理器架构包括CPU+GPU架构、CPU+MIC架构等,“神威·太湖之光”超级计算机的国产申威架构SW26010处理器,也属于异构众核架构。
异构众核架构使得超级计算机的计算能力大幅度提升,但对CFD高性能计算也是挑战。因为要实现对计算资源的充分利用,需要从数值算法、数据结构、计算流程等各个层面进行重构和优化。NASA的《CFD Vision 2030 Study》报告也将其列为重大技术挑战。
国内外不少研究人员针对CPU+GPU架构、CPU+MIC架构,开展了CFD众核并行计算研究;也有少量基于开源软件针对国产申威架构的CFD众核并行计算研究。总体看来,目前CFD界远未实现对异构众核超算能力的有效利用,有以下原因:
(1)目前常用CFD软件的并行计算,大多数是针对MPI并行设计的,一般不适合在异构众核平台上运行。
(2)CFD计算通常具有全局相关性特点,并行规模的增大带来了并行复杂度与通讯开销的增加,导致并行效率下降;同时水动力学CFD常用的SIMPLE算法的流程相对复杂,增加了细粒度并行优化的难度,异构加速面临巨大挑战。
(3)CFD软件一般具有数据结构复杂、计算流程复杂和代码量庞大等特点,从程序移植到优化,都需要大量的重构工作,难度和工作量相当大。
本文面向异构众核处理器,开展水动力学CFD并行计算探索研究,为自主CFD求解器与国产超级计算机硬件的有效结合进行关键技术攻关。针对国产申威26010异构众核处理器,对水动力学CFD中典型的SIMPLE算法和人工压缩算法,从数据存储、数据分配和数据结构等多个方面入手,设计众核并行计算方法,通过典型算例测试和验证众核加速效果,并针对SIMPLE算法计算热点分散的特点,采用循环融合的方法对其计算流程进行优化,使SIMPLE算法和人工压缩算法分别获得11倍和24倍的最高加速。该项研究工作,初步展现众核处理器在水动力学CFD并行计算中的应用潜力,并将为自主CFD求解器与国产超级计算机硬件的有效结合提供技术储备。
1 水动力学CFD计算方法
水动力学CFD计算处理的通常为不可压缩粘性流动,其无量纲化积分形式控制方程组如下:
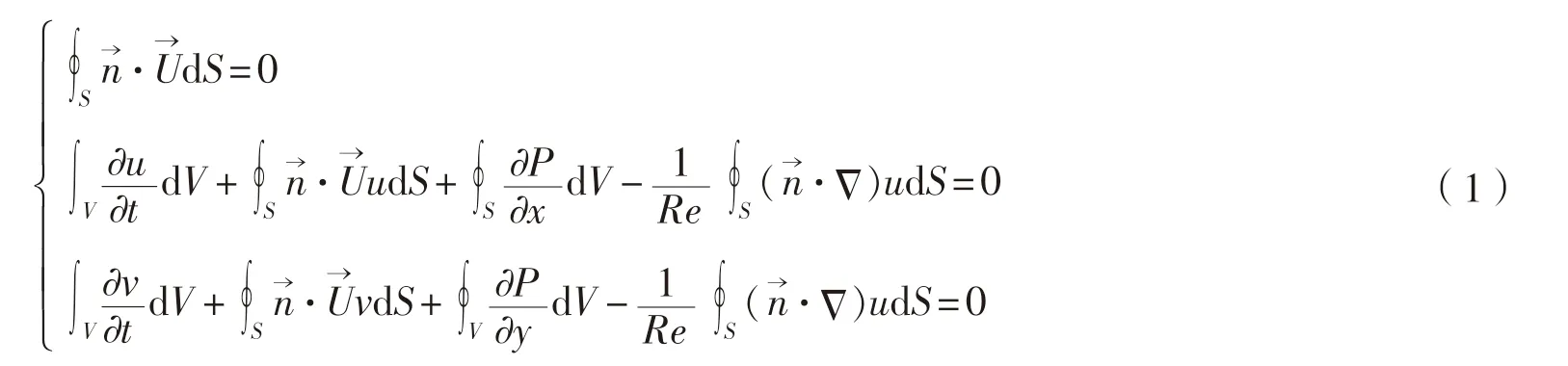
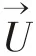
本文采用基于交错网格的有限体积法离散控制方程。论文在求解控制方程组时,使用了两种数值算法——SIMPLE算法和人工压缩算法,两种算法的求解流程参见图1。
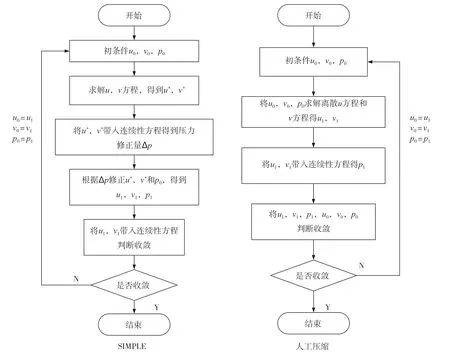
图1 SIMPLE和人工压缩算法计算流程
2 CFD模拟并行计算方案
2.1 国产申威众核处理器简介
“神威·太湖之光”超级计算机系统,采用的是国产申威架构SW26010处理器。处理器本身就包括控制核心和计算核心阵列,相当于把CPU和加速处理器集成到一个芯片上,其内部架构见下页图2。
图2 SW26010处理器架构示意图
SW26010处理器包含4个核组(CG),各核组之间采用片上网络(NOC)互联,每个核组内包含1个主控制核心(主核,MPE)、1个从核(CPE)集群(由64个从核组成)、1个协议处理单元(PPU)和1个内存控制器(MC)。核组内采用共享存储架构,内存与主/从核之间可通过MC传输数据。
与其他异构众核架构一样,SW26010处理器的计算能力主要体现在从核上;但相比于GPU和MIC,从核上的存储空间和带宽较小,往往使数据传输成为程序运行的瓶颈。
2.2 主要并行工具与函数
Athread与OpenACC*均可用来进行从核并行,与OpenACC*相比,Athread的操作性更高,可以通过调用相关实现数据传输和从核运算的自主可控,加速部分不再只限于循环计算,能够更加方便对并行方案进行设计。
完整的从核加速过程通常包含以下函数,如表1所示。
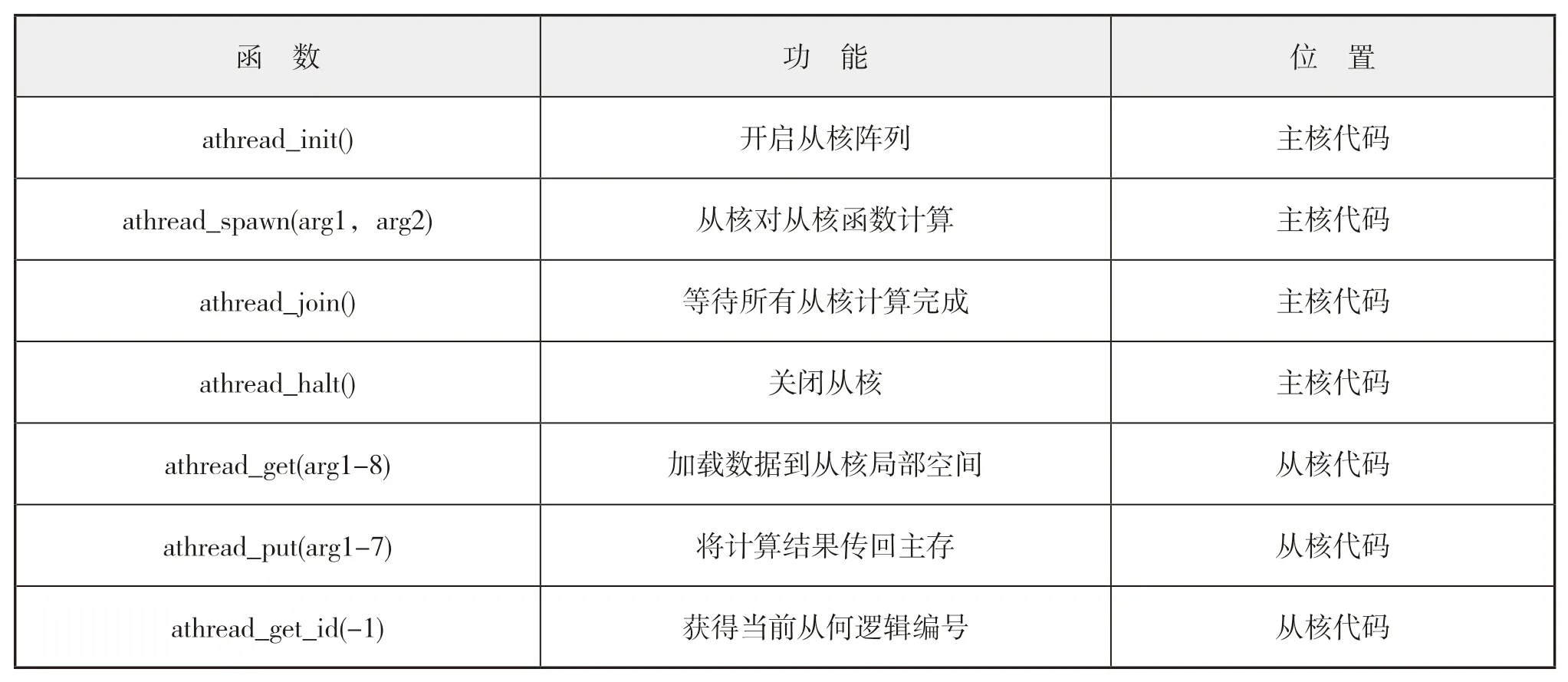
表1 Athread常用行数
2.3 众核并行计算方案设计
2.3.1 数据存储模式
由于本文采用交错网格,速度u
、v
和压力p
3个主要变量存储在3套网格上,数据量和计算索引均不统一,将会使寻址过程变得更加复杂。为此,本文中采用一种特殊的数据存储模式(如图3所示):将速度u
、v
相对压力p
多出的数据单独存储,此时,u
、v
、p
共同存储在主控制体上,且拥有相同的索引,从而简化寻址过程、提高寻址效率。
图3 交错网格下变量分布和存储方式
2.3.2 数据分配
本文采用循环并行,由于从核局部空间大小有限(64 KB),因此合理分配数据才能充分利用从核局部空间和计算资源。数据分配方案设计为:设定单个从核单次计算的数据量NS,则64个从核一次能够计算64×NS
个数据,当数据量很大时,可以将数据分批多次加载到从核上进行计算。此时,可以根据当前的加载次数k
、当前次加载的数据量N
以及从核ID号,确定当前从核(线程)所计算数据的起始位置,并从主存获取数据。同时,为了考察通信的影响,论文对单独一个循环进行测试,测试对象为人工压缩算法中内部单元压强的计算过程,结果见图4。从图4可见,当NS
增大时,加速比逐渐上升并趋于定值(左图)。其原因为:随着NS
值的增加,通信占比逐渐降低并趋于定值(右图),从而使计算过程的加速效果愈发突显。
图4 不同NS值下加速比、通信占比和计算占比变化曲线
2.3.3 数据结构
根据数据分配方案,NS代表从核计算的数据量,而从核局部空间的大小使单个从核存储的数据量有限;同时,由于CFD计算过程复杂,将数据以结构体形式合理存储,可使数据的传输和使用更为方便。但是,将多个变量集中在一个数据结构中,必然会造成在当前计算中部分变量未使用的情况,这样既增加通信负担,又占据存储空间。因此,合理的数据结构非常重要。
由于CFD程序中有多个计算热点需要并行化,因此对数据结构进行针对性的设计比较困难,本文将重点放在尽量减少无用数据的存储和传输上。在CFD程序中,将系数变量组成单个结构体,将u
、v
、p
以主控制单元的形式组成结构体,并在此基础上设计了如图5所示的数组结构体和结构体数组两种形式,用于对比两者并行加速效果。
图5 两种数据结构
3 典型流动众核并行计算结果与分析
3.1 并行计算结果
本文以二维方腔驱动流CFD模拟为算例,研究众核并行的加速效果。
方腔驱动流,是指方腔中的不可压缩流体随顶盖匀速运动过程中的流动及流场结构变化等现象,具有几何外形简单、流动结构特征显著、边界条件容易实施等特点,常被用作不可压缩流动模拟结果验证和数值算法测试的典型算例。数值模拟中,边界条件都可采用速度边界:其中上边界(顶盖)有水平方向速度,其他边界满足无滑移条件。
使用SIMPLE和人工压缩算法,分别采用数组结构体和结构体数组两种数据结构,开展不同网格单元数(100×100 ~1 000×1 000)情况下、Re
= 1 000工况方腔驱动流的CFD模拟。图6给出了方腔水平中线与垂直中线上的无量纲速度分布数值计算结果,下页表2则给出主涡和次涡相对位置的数值模拟结果;图表中同时给出文献[10]中Ghia的计算结果。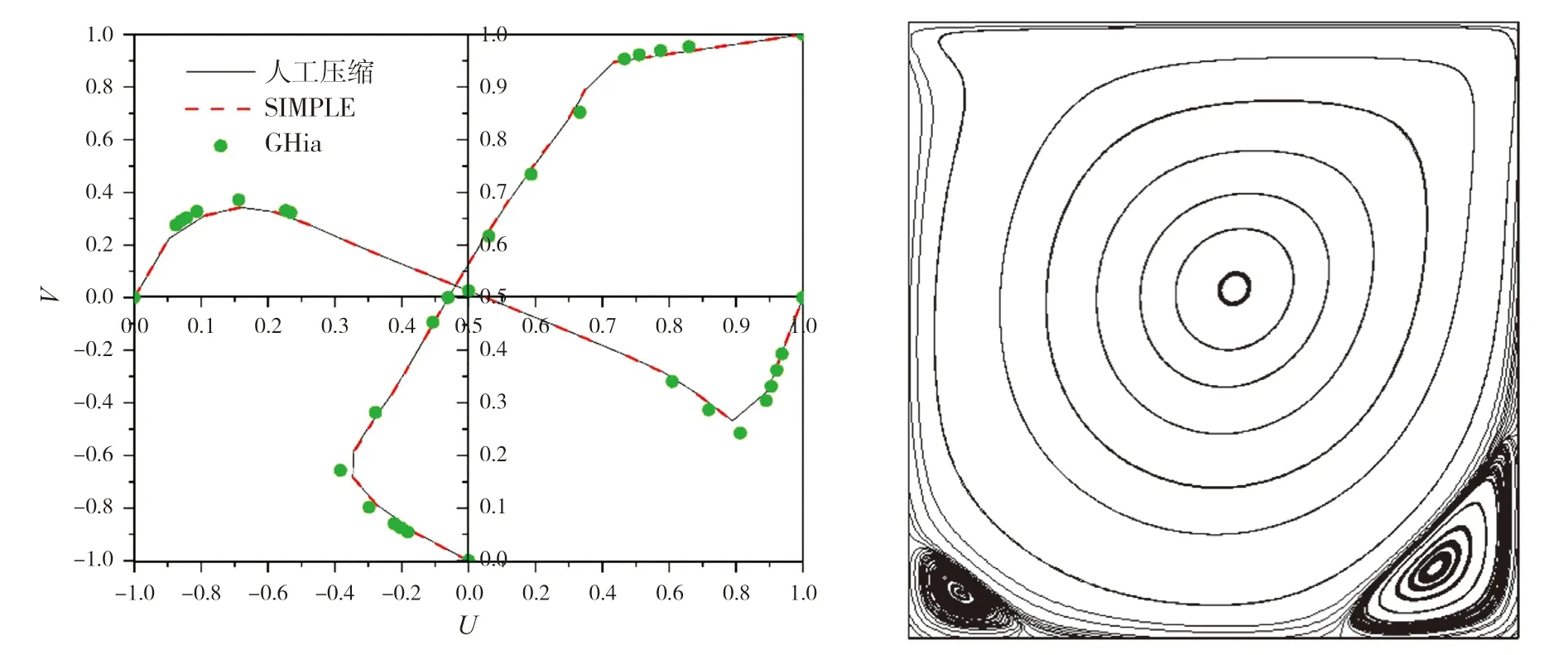
图6 方腔水平和垂直中线上速度分布(左)及方腔内部流线分布(右),Re=1 000
本文在并行计算过程中,并未改变迭代方法等计算过程,因此,不同的数据结构和算法应有基本一致的计算结果。根据图6以及表2可以看出:无论是速度分布或主涡与次涡的涡心坐标,均与参考文献的结果十分接近,这也说明并行计算结果的正确性。
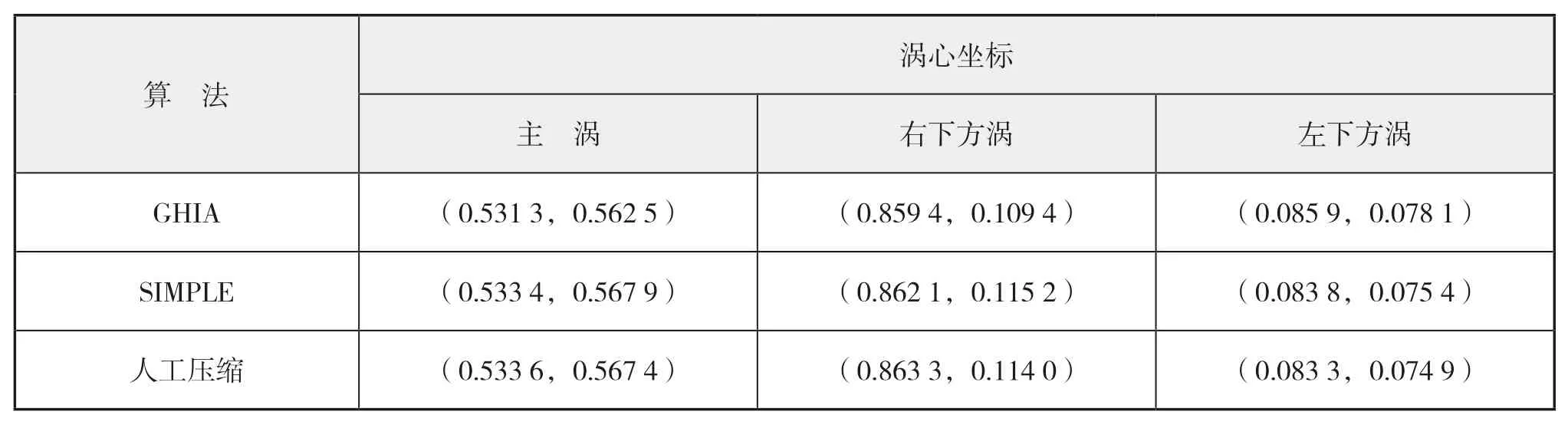
表2 涡心位置计算结果
图7给出不同网格单元数情况下,众核并行的加速情况。从图中可以看出:
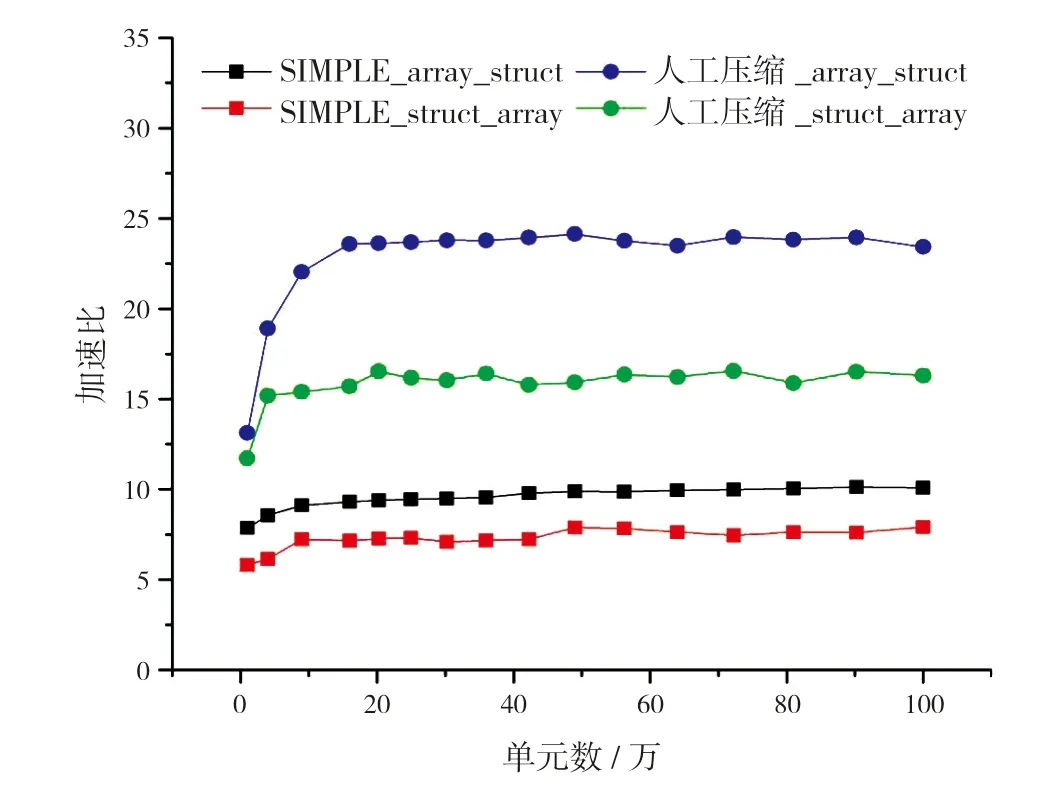
图7 众核并行加速曲线
(1)随着网格单元数增加,加速比逐渐上升并趋于平稳;
(2)从两种算法的对比来看,人工压缩算法的加速效果(最高约24倍)优于SIMPLE算法(最高约9倍);
(3)从两种数据结构的对比来看,采用数组结构体并行加速效果优于采用结构体数组。
3.2 对SIMPLE算法计算流程的优化
根据上一节的研究可以发现,在采用相同数据结构的情况下,SIMPLE算法的并行加速效果明显不如人工压缩算法。其原因是SIMPLE算法的计算流程更为复杂(见图1),从而导致计算热点分布较为分散。表3给出了SIMPLE算法和人工压缩算法的计算热点分析结果。
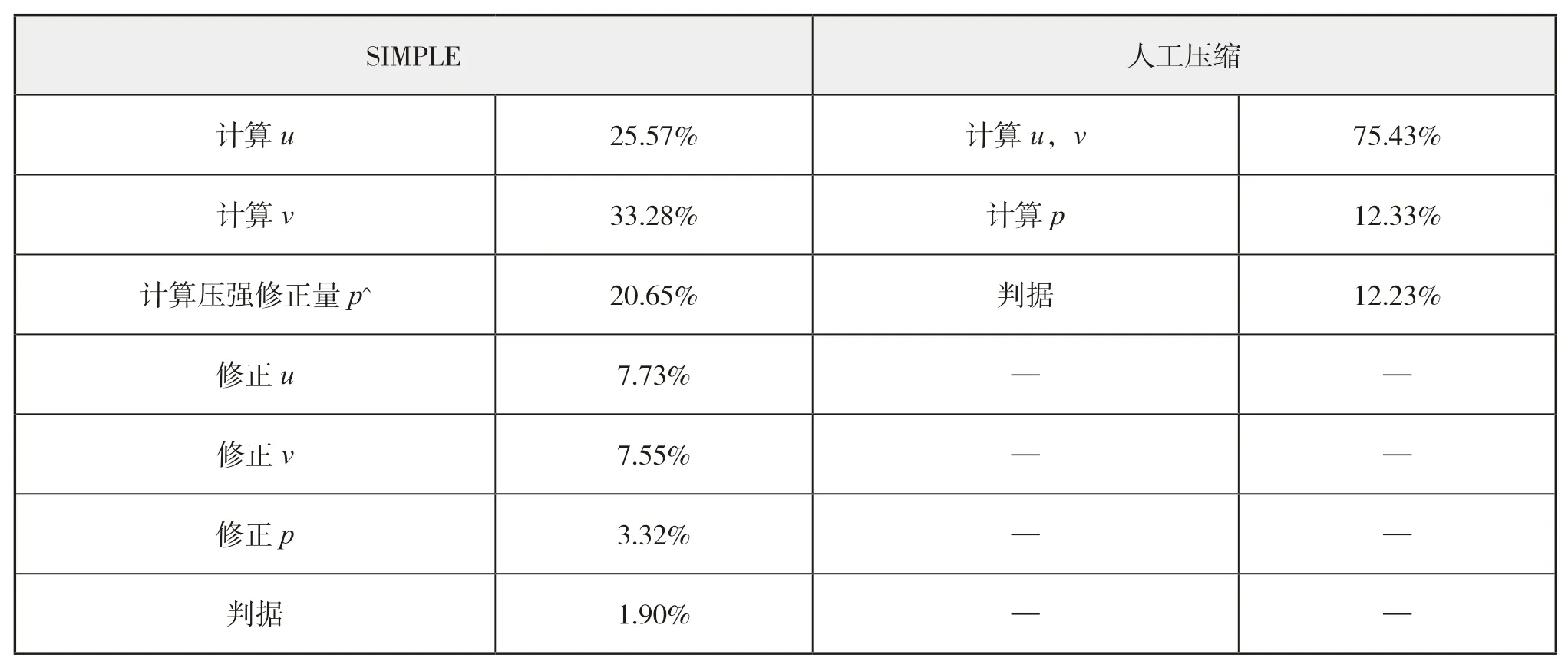
表3 SIMPLE算法和人工压缩算法计算热点分析
结合2.3节(图4)通信占比与计算占比之间的关系,SIMPLE算法分散的热点会导致在众多的简单循环计算中,因数据量有限,当计算中需多个变量时,必然造成通信的增加,导致通信相对计算有较大的占比,使局部加速效果偏低,进而导致整个CFD计算程序的并行加速效果不理想。
为此,本文对SIMPLE算法的计算流程进行优化,将SIMPLE算法中非相关的数据计算过程进行集中处理,即在一个大循环中通过判断语句进行不同的计算。这样,在从核计算中,提高了数据的复用性,减少常用变量的重复传输。流程优化前后的计算热点对比见表4。
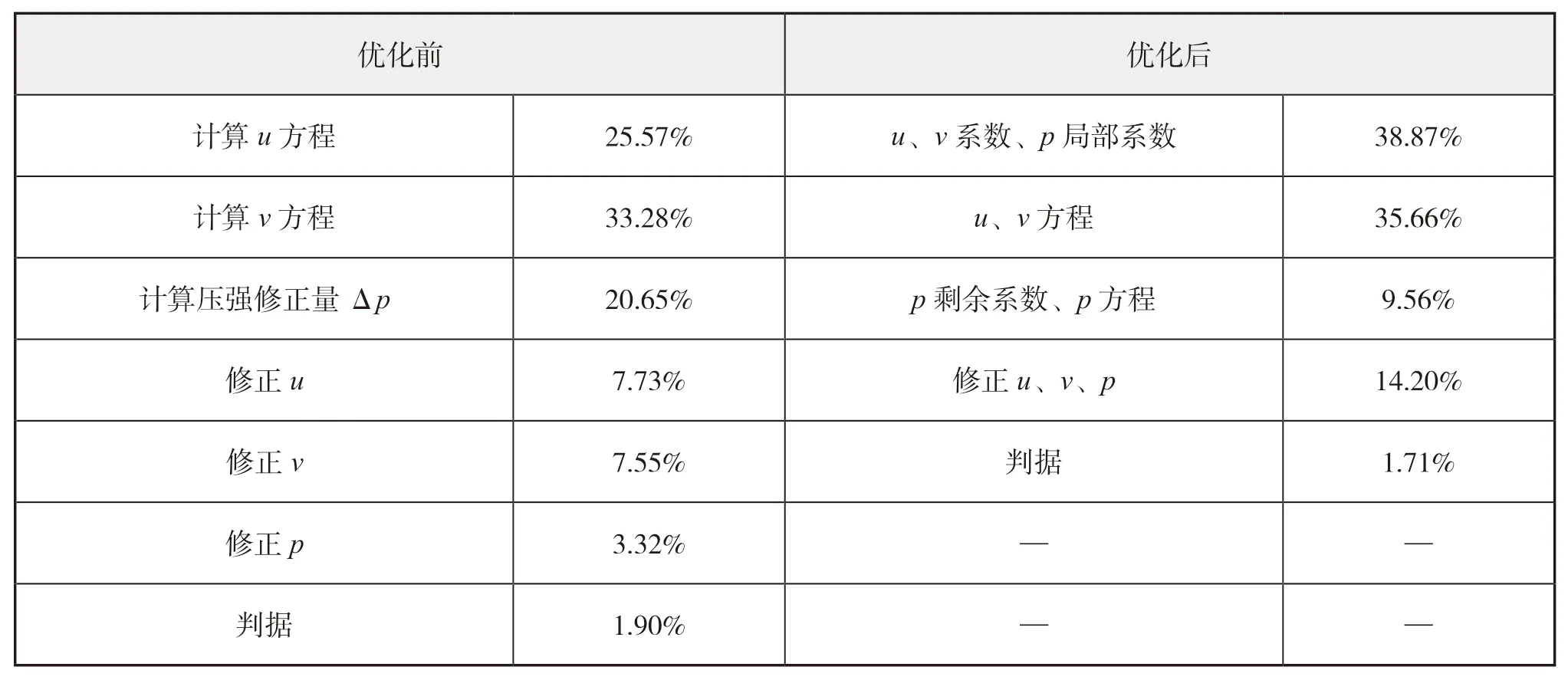
表4 SIMPLE算法计算流程优化前后计算热点分布
由表4可见,优化后的SIMPLE算法流程,减少了计算步骤,使计算热点分布更加集中,其中u
、v
系数、p
局部系数(由u
,v
,p
计算的部分)计算与u
、v
方程求解两部分总和占比超过74%。图8给出了SIMPLE算法计算流程优化前后的众核并行加速曲线。从图中可见,优化算法流程使加速效果略有提升,说明计算热点分布的集中程度会影响众核加速效果,且热点越集中加速效果越好。
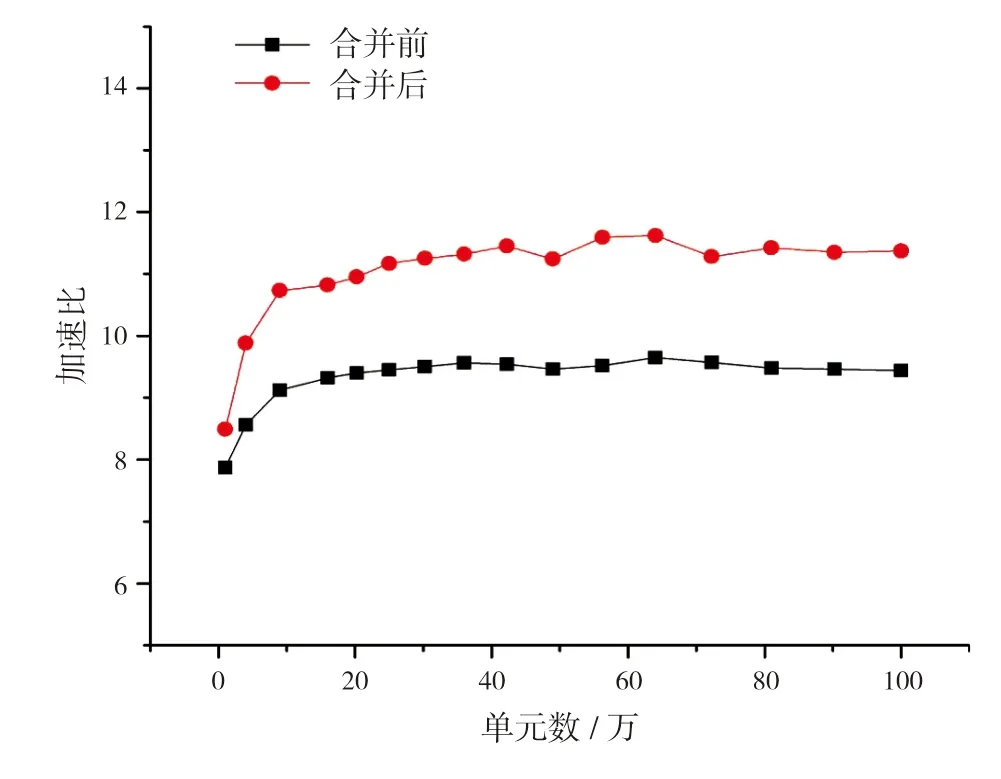
图8 SIMPLE算法计算流程优化前后并行加速比
同时,对比图7和图8可见,即使经过计算流程优化,SIMPLE算法的众核并行加速效果也远未达到人工压缩算法的并行加速效果,经分析主要原因如下:
(1)SIMPLE算法涉及方程的迭代求解,迭代过程自身就包含数据更新、计算新值和判断收敛三部分,而数据更新和判断收敛在单个迭代步内占比较小,但是由于内迭代和外迭代的重复进行,也会影响最终的加速效果。
(2)算法本身计算过程中读取数据对于高速缓存的利用等。
4 结 语
本文面向异构众核处理器,开展不可压缩流动的CFD并行计算探索研究。针对国产申威26010处理器的特点,对SIMPLE算法和人工压缩算法设计了众核并行计算方案,并通过二维方腔驱动流算例测试和验证了众核加速效果:人工压缩算法最高加速约24倍,SIMPLE算法最高加速约11倍。论文的研究工作,初步展现了众核处理器在不可压缩流动CFD计算中的应用潜力。
论文的研究工作目前还是探索性的:一方面,仅探讨了单个核组使用从核阵列的加速效果,并且诸如寄存器通信、双缓冲等优化方法暂未使用,因此加速效果还有一定的提升空间;另一方面,论文中开发、使用的CFD程序较为简单,而面向工程应用的大型CFD软件在数据结构、计算流程等方面复杂得多,在神威平台上进行众核加速,则需要在各方面进行更多的探索和研究。
