基于语义关联的专利有害性能知识挖掘研究
2021-08-26林文广赖荣燊肖人彬
林文广 赖荣燊 肖人彬
1.厦门理工学院智能制造高端装备研究厦门市重点实验室,厦门,3621142.华中科技大学人工智能与自动化学院,武汉,430074
0 引言
据统计,一款新产品从方案设计到最终的市场投放,成功率不足20%,超过90%的产品上架时间不足8%,给企业造成了极大的资源损失[1]。如果能够在产品设计阶段预先充分获取设计相关案例的功能知识、结构知识、性能知识等信息,并对方案中的潜在风险进行勘探及规避,不仅可以有效改善产品的设计质量,同时有助于降低研发成本,提高企业市场竞争力。
事实上,现代产品设计是知识驱动的过程,其中知识是已有研究事实和设计经验的提炼与总结,是产品设计创造力的关键属性。传统设计过程中,知识的获取往往来源于工程师经验以及企业问卷调查数据,不仅数据量少,而且受主观经验影响,容易导致设计偏差。随着数字化时代的到来,受益于传感器、电子存储以及信息技术的快速发展,以专利数据、网络评论、科技文献、社交媒体、移动位置、设备运行状态为代表的新型数据信息不断涌现,推动着社会的不断进步。这些信息中不仅蕴含着丰富的产品设计知识,同时具有成本低、时效性强的优点,为传统产品设计向数据驱动产品设计转型升级提供了机遇。但是现有数据信息存在多源异构、价值密度低、准确性差等方面的不足,这对知识来源的遴选及挖掘手段都提出了较高的要求,是影响设计转型的关键[2]。
1 专利挖掘研究现状
相较其他数据类型,专利数据在数据量、时效性以及客观性方面都更优。如果能够有效利用专利数据,不仅可以缩短60%的研发时间,同时能够节省40%的研发费用[3]。但是专利中包含大量复杂文本信息,尤其是发明专利以及实用新型专利,这些信息呈现非结构化、维度高、一词多义的特点,是实现专利数据有效挖掘的主要障碍[4]。如何从海量专利数据中快速获取有价值的设计知识,一直是学术界高度关注的问题,并开展了诸多相关研究。根据数据挖掘方法的不同,现有研究主要分为以下两类。
(1)基于统计的挖掘方法。基于统计的挖掘方法主要是通过计算特征频次或者概率方法获取技术关键词。侯鑫[5]基于图上随机游走词汇加权算法计算词的重要性,并利用语义网络中的顶点聚类算法对技术文档词汇进行分类及筛选,进而形成技术概念。梁艳红等[6]针对专利不同部分的信息内容,围绕发明问题解决理论(theory of the solution of inventive problems, TRIZ),结合特征函数信息增益算法从专利中提取产品创新设计信息。陈忆群等[7]利用专利结构化信息之间的关联关系构建专利背景知识库,进而获取词汇特征值以进行重要性排序,并结合支持向量机提取关键词。YOON等[8]利用线性判别式分析算法挖掘专利文本信息主题,并通过协同过滤筛选同领域中不同竞争对手的专利,以此作为新产品开发的参考技术对象。SRINIVASAN等[9]根据机械产品专利文献中功能术语特点和句子中不同字符串的共现强度,结合网络度量方法获取关键术语。陈志泊等[10]在词向量化基础上,通过构建融合词语特征值、边权值的图模型对词汇重要性进行排序,并通过词聚类以及过滤算法形成关键词集合。KIM等[11]结合神经网络,提出基于词嵌入以及专利聚类的方式提取专利技术特征。
(2)基于规则的挖掘方法。基于规则的挖掘方法主要是通过词语词性以及前后位置获取技术关键词。王朝霞等[12]在词性标注的基础上获取专利组件关键词及功能词汇,利用浅层句法规则获取不同组件之间的技术关联关系,并通过语义网络实现专利表达。YOON等[13]在词性分析的基础上,利用依存句法关系提取专利中对象功能及其属性信息。薛驰等[14]通过最大熵理论筛选关键词,通过词性以及行业专业词典提取机械专利技术对象,并联合动词库获取不同对象之间的作用关系,进而构建机械产品专利的知识模型。FANTONI等[15]在功能、原理及属性定义的基础上,通过专利文本分词以及词性标注,结合wordnet数据库以及词性组合规则获取对应的关键词。张惠等[16]从单词词性角度出发,通过研究描述性能、功能及结构等类型关键词组合的词性特点,并结合关联规则算法从专利中提取绿色产品设计知识。韩爽等[17]在分析专利不同部分信息特点的基础上,结合公理化设计理论以及专家筛选的方法获取不同域的知识。KIM等[18]在传统主谓宾(subject-action-object,SAO)三元组的基础上,引入其他语义,构建SAOx扩展模型,并结合TRIZ工程参数以及发明原理提取对应的关键词信息。
综上所述,可以看出现有研究虽然在部分专利设计知识挖掘方面取得了一定的成果,但也存在以下两方面不足。
一方面是通过统计词频以及共现的方法对目标文本进行分析,只能挖掘专利中的显性知识,而不适用于隐形知识的提取。尽管文献[19]利用词频方法计算专利语义距离,通过构建向量空间获取相似专利,实现基于类比方法的创新设计,但是该方法忽略了单词之间的语义相关性,未能实现同义词的识别及提取,导致信息资源浪费。
另一方面是研究对象主要针对专利技术方案及其实现的功能效果,虽然目的是为产品设计提供类似的成功案例,但忽略了对现有专利方案潜在不足之处的研究。若直接参考此类专利,容易导致产品创新设计过程的技术风险。
挖掘现有专利所涉及产品及其技术的有害性能知识对企业具有重要的意义,不仅可以促使企业在产品设计过程中避免出现类似的问题,同时可为目标专利的规避设计提供有价值的参考。因此,本文提出基于语义关联的中文专利有害性能知识挖掘方法,在分析有害性能语义特点及分类的基础上,集成word2vec和复合依存关系两种方法构建产品有害性能数据库,进而为设计方案的评估及改进提供参考。
2 专利有害性能知识研究
2.1 有害性能的概念
2.1.1有害性能定义及表达
目前关于有害性能(harmful performance,HP)定义的研究较少,部分研究主要集中在设计缺陷或者有害功能上。如文献[20]将设计缺陷定义为产品错误设计导致后续生产以及使用过程存在不足。这是将有害因素简单视为一个整体,并没有对其进行详细的分析及分类。文献[21]将有害功能定义为对象之间带来不期望的关系结果,并通过对象之间的效应进行识别。事实上,产品除了产生有害功能外还容易存在有害质量,这些都是产品设计过程需要考虑的因素。
对此,本文引入性能概念。从设计过程来看,性能是产品设计过程的起点及终点,是设计过程的驱动力[22]。从设计对象来看,性能指系统或者元素对外输出作用的效果,这种效果不仅包含功能效果,也包含质量效果。功能是作用关系的描述,质量是作用强度的度量。根据效果的差异,性能分为有利性能和有害性能。有利性能是指满足既定设计要求的作用,是设计者所期待的;有害性能是指未能满足设计要求的作用,具体定义如下。
定义1 有害性能是设计对象未能输出满足设计要求作用效果的性能。相比有利性能,有害性能会给设计过程带来潜在风险,进而影响产品的生产、使用以及回收等环节。一个对象可能同时存在多个有害性能,不同性能又有各自的输出效果,进而形成三个层级。参考SAO模型[18],引入三元组模型PH={S,A,E}对对象的有害性能进行表达,其中,S表示产生作用效果的对象来源;A={A(t)|t=1,2,…,n}表示所产生的作用;E={E(t)|t=1,2,…,n}表示作用强度的描述或者变化情况。
作用A根据性能的性质分为AP和AO,其中AP为正面作用,是指对象输出属于设计要求的作用;AO为负面作用,是对象输出不属于设计要求的作用。与AP不同,AO不论作用强度多大,都会对方案产生不利影响。
效果E根据强度大小分为EM、EL和EN,其中,EM为过高强度,指产生的作用效果超出设计要求;EL为过低强度,指产生的作用效果低于设计要求;EN为正常强度,指作用效果符合设计要求。
2.1.2有害性能分类
根据作用强度大小,有害性能具体分为不足性能PHL、过剩性能PHM以及负面性能PHP。不同性能具体定义如下。
定义2 不足性能PHL是指作用强度未能满足设计预定的要求,例如花洒水压较低、喷口流量不足等。
定义3 过剩性能PHM是指作用强度超过设计预定的要求,例如花洒水压超标、手柄载荷过大等。
不论是不足性能还是过剩性能,都是正向作用,但是作用强度未能在设计要求范围之内,则属于质量缺陷,需要通过参数调整变成正常有用性能。
定义4 负面性能PHP在性质上属于完全有害作用,是有害功能,难以通过参数改变来消除,需要对系统进行重新改造。
为了便于有效开展专利性能知识挖掘研究,结合S、A、E三元组分类情况以及不同类型有害性能定义,可以得到相应性能的计算公式:
(1)
2.2 专利有害性能分布分析
根据专利法实施细则第17条规定,专利正文包括摘要、权利要求、技术说明书,其中技术说明书包括技术领域、背景介绍、发明内容、附图以及实施案例等内容。基于文献[6,12,14]的研究,可以看出不同部分可提取的技术内容以及所包含的数据量、数据类型及其提取难度存在明显差异,如表1所示。
由表1可以看出,与有害性能相关的内容主要集中在背景技术上,即与已有公开技术的比较,引申出专利所要解决的问题,同时凸显本专利所蕴含的技术先进性及合理性。在综合比较数据量以及提取难度的基础上,本文主要选择技术背景文本内容进行语义挖掘研究。
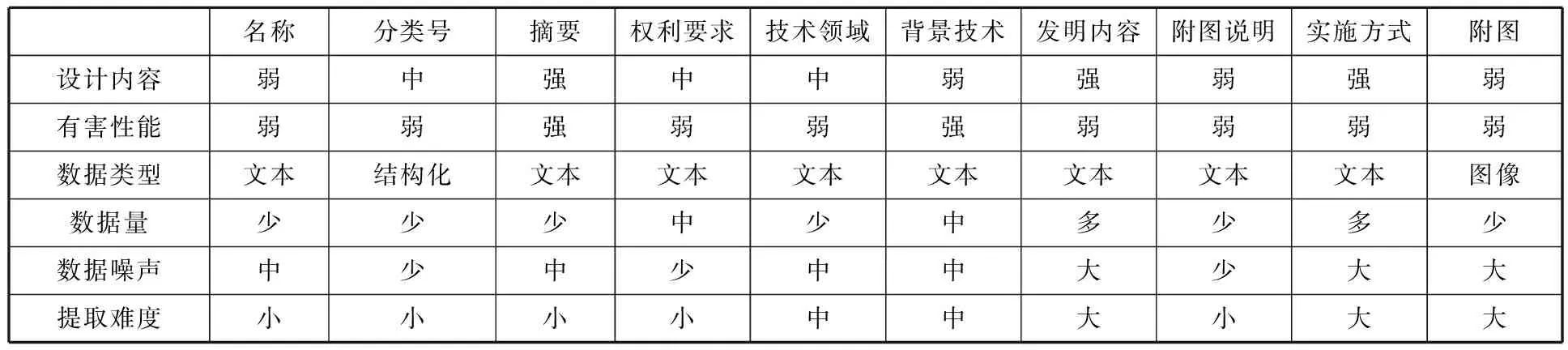
表1 专利不同部分的数据属性
2.3 有害性能的专利语义特点分析
鉴于属性的不同导致专利有害性能语义特性存在差异,为了提高文本挖掘的适用性,分别对不同类型的有害性能的语义特点进行分析。同时由于有害性能文本词性存在明显的多样性,为了提高准确率,采取同句共现的词性组合方式进行关键词的识别与挖掘。
由于不足有害性能和过剩有害性能主要涉及面向对象技术效果的评价,为了提取词语三元组中的A和E,采取“性能名词np+形容词adj”、“性能名词np+动词vt”以及“形容词adjm+动词vt”的组合形式进行提取。其中形容词又分为高强度形容词adjm和低强度形容词adjl,例如“高”“大”“强”“多”等属于adjm,“低”“差”“弱”“少”属于adjl。动词也分为提高强度动词vtm和降低强度动词vtl,例如“提高”“增大”“加强”属于提高强度动词,而“降低”“减少”“减弱”属于降低强度动词。性能名词是指对产品性能的描述术语。根据产品生命周期的不同环节,在文献[23]研究基础上对这些性能名词进分类,具体如表2所示。

表2 性能指标举例
对于负面有害性能,借鉴文献[12,14]所提出的功能知识获取方法,三元组中A和E主要通过“负面动词vte+名词n”和“动词vt+负面名词ne”的双元复合形式展示。例如“阻碍水流”“阻塞喷口”“影响流速”“导致损失”等,其中“阻碍”“阻塞”“影响”是负面动词,而“损失”是负面名词。与前述两种有害性能相比,负面有害性能的词汇所包含的名词类型范围较宽,不局限于某一类名词。
3 基于语义关联的专利有害性能知识挖掘框架与关键技术
3.1 专利有害性能知识挖掘框架
为了获取专利技术所蕴含的有害性能信息,针对专利中同时存在技术方案和对现有技术缺点评价两方面内容的现象,借鉴大数据分析方法,通过引入语义关联算法对专利数据进行挖掘,研究框架如图1所示。具体研究步骤如下。
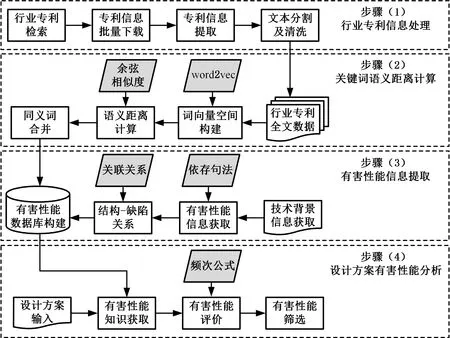
图1 面向有害性能的专利信息提取框架
(1)行业专利信息处理。根据市场需求,确定待分析产品或者技术对象所处的行业领域,并分析领域行业发展特点,设计专利检索关键词以及分类号。通过对比国内外专利数量,选择现在特定区域的专利,并结合专利类型以及授权时间检索专利,下载相关资料并对全文进行划分。随后提取专利不同部分的文本信息,并结合停词数据库对文本进行分割及清洗,过滤无关及低价值噪声数据。
(2)关键词语义距离计算。首先基于行业全部专利的全文文本构建关键词语料数据库,利用word2vec算法中的计算模型对数据进行训练,进而获取每个词的词向量,并形成整个数据库的词向量空间,结合余弦算法计算不同单词之间的语义距离,并确定相似度阈值以实现同义词聚类。
(3)有害性能信息提取。针对专利背景部分文本信息,首先利用词性分别提取相应的关键词,并通过多重复合依存句法规则提取有害性能信息及其分类信息。在此基础上,利用 “。”“?”“;”等结束符号对文本进行分句以提取完整句子。根据词性筛选获取名词信息,并结合三种主谓关系构建名词与有害性能的关系三元组模型,结合步骤(2)的提取结果构建基于背景信息的有害性能数据库。
(4)设计方案有害性能分析。利用语义关联相似度算法获取创新设计方案不同元件关键词的同义词,利用关键词分别检索有害性能数据库,获取关联专利的结构词及其有害性能三元组,与专利技术方案进行比较分析,结合频次公式评估元件不同有害性能的出现概率。考虑到方案中部分已经解决的技术问题以及出现概率较低的有害性能,通过排除法获取方案需要解决的有害性能,为后续方案改进以及专利规避提供参考意见。
3.2 基于词向量模型的文本相似度计算
词向量,又称为词嵌入(word embedding),是将自然语言中的词汇进行向量化得到的属性模型。word2vec是谷歌公司于2013年开发的一款将词表示为实数值向量的高效工具,利用词的上下文信息,通过神经网络将词表征为向量,是实现文本内容向量运算的有效工具[24]。word2vec主要包含Skip-gram模型以及CBOW模型。Skip-gram模型利用输入词w(t)预测前后相关词。CBOW模型则相反,利用前后相关词预测当前词w(t),具体原理如图2所示。
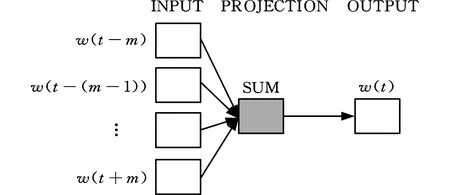
图2 CBOW模型
由于采取多对一的方式,相比较Skip-gram模型,CBOW模型训练词向量的时间更短。为此,本文采取CBOW模型训练词向量,该网络模型包含输入层、投影层和输出层三层,训练样本为(content(w(t)),w(t)),其中,content表示目标单词前后词所组成的词向量。目标函数为
(2)
投影层将前后C个词向量进行累加求和,表示如下:
(3)
其中,V代表词向量的值。
模型的输出层采用Hierarchical softmax技术,以训练语料样本中出现的词作为叶子节点,以词频作为权重进行Huffman树构造。利用随机梯度使L函数值最大。模型训练完之后,获得词的向量表示。
利用word2vec得到不同词的向量空间,结合余弦算法计算词相似度。假定有两个n维单词向量wi(xi1,xi2,…,xin)和wj(xj1,xj2,…,xjn),相似度计算如下:
(4)
通过设定最低相似度阈值,对满足条件的关键词进行合并。
3.3 有害性能知识提取
3.3.1依存句法
句子往往由多个关键词组成,这些关键词之间都属于同句共现关系。如果仅以词性组合获取技术短语,则只是将短语视为同个句子内一个独立的词汇,忽略了词汇之间的前后关系,会将不相关的词汇也视为性能组合关键词,影响提取效果。为了进一步提高有害性能知识的提取准确率,需要在已有词性组合的基础上融合关系规则。
文本句子是由一系列单词短语通过一定关联关系组成的,这些关系遵循相应的依存语法。依存语法最早由法国语言学家L.Tesniere提出,他认为单词之间的关系是有方向的,往往是一个词支配另一个词,这种支配和被支配的关系就是依存关系(dependency relationship,DR)[25]。例如输入文本“花洒能够喷出洗手液,具有杀菌消毒功能”,该句子的依存关系如图3所示。可以看出一个句子中,不同词语彼此构成各种复杂的依存关系,形成关系对。

图3 句法结构关系图
依存关系分析就是通过给定的语法,结合词性自动识别同一个句子中前后不同单词或者短语之间的支配关系[26]。通过统计,目前中文依存关系主要分为14种,不同类型关系及其词性组成情况如表3所示。
3.3.2基于依存句法的有害性能提取
根据表3,主谓关系、动宾关系以及定中关系涉及对象的作用及描述,与过剩性能及不足性能的定义紧密相关,适用于这两种性能关键词的提取。
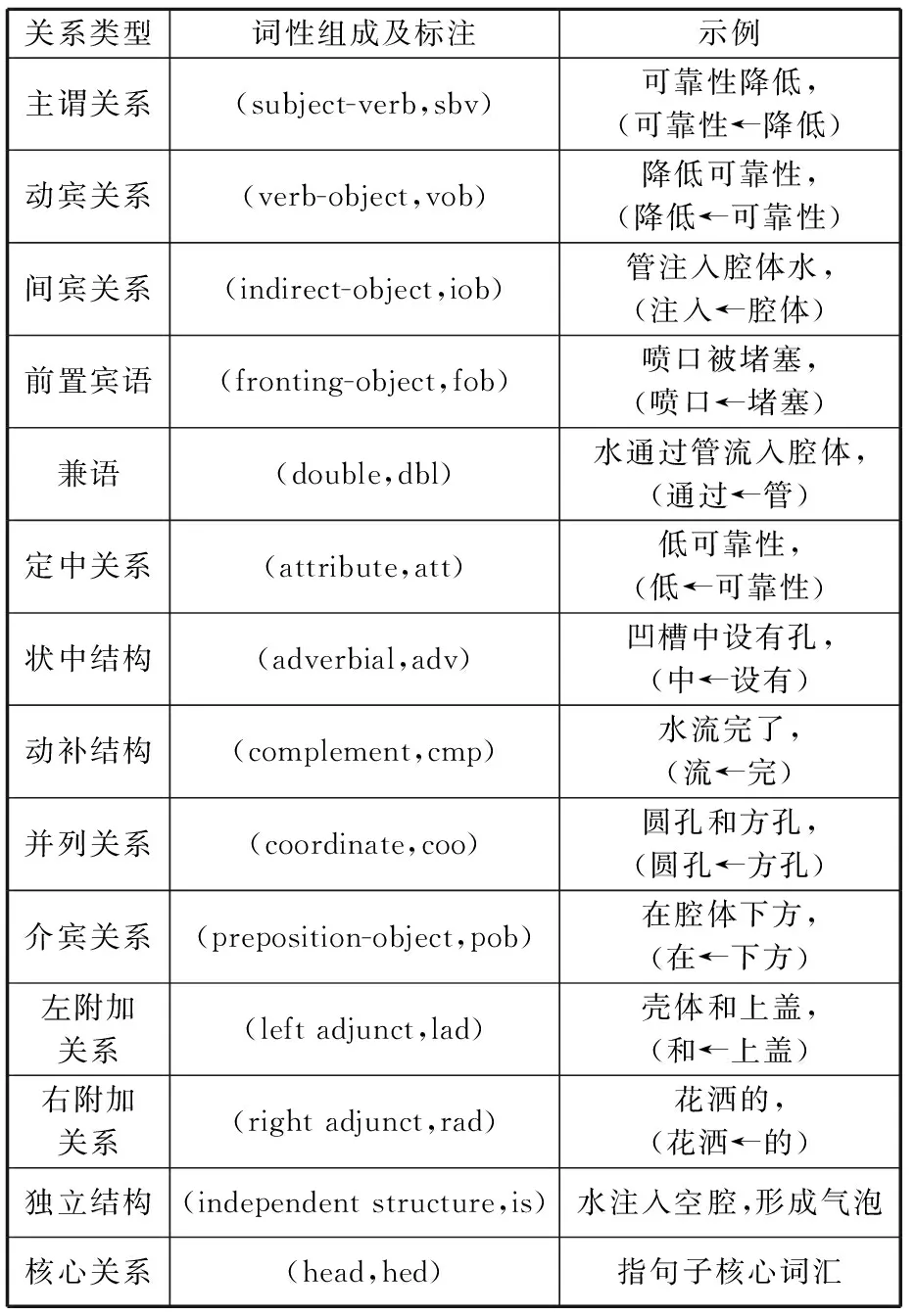
表3 主要句法依存关系
对于负面有害性能,由于涉及“动词+名词”组合,因此可以通过动宾关系、前置宾语实现,其中前置宾语适用于被动语句。例如“堵塞喷头“是动宾关系,而“喷头被堵塞”属于前置关系。
针对不同性能分别设计对应的复合提取规则。现在假设存在单词组合w={wi,wj},则三种类型有害性能知识的提取规则如表4所示,其中,tag表示依存关系。
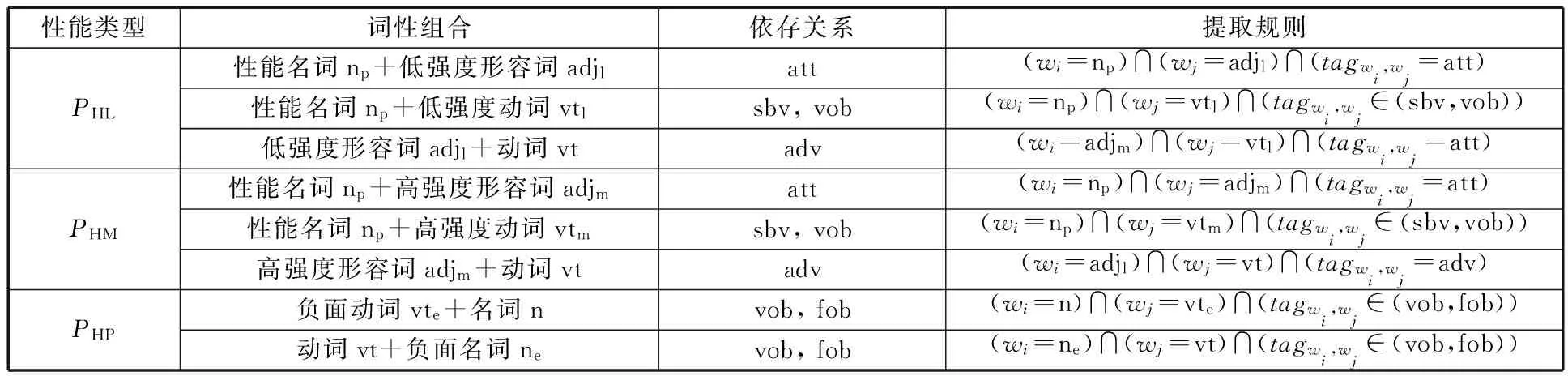
表4 不同类型有害性能知识提取规则
3.3.3结构性能关联关系分析
描述产生有害性能结构对象的名词通过“负面动词+名词”的句法形式存在于同个句子文本中,进而形成关联关系。根据主语数量,这种关系分为一对一、一对多、多对一以及多对多四种类型,如图4所示。一对一关系是指包含一个结构和一个性能,例如“弹簧生锈”,这种情况较为常见。为了让文本更加紧凑,申请人还会采取一对多或者多对一的方式,例如“弹簧和过滤网都容易生锈”属于多对一关系,而“弹簧容易生锈,且不易拆卸”则属于一对多关系。也有采取多对多的方式,例如“塑料和橡胶材料,都容易腐蚀以及不耐磨”。因此,在分析过程中需要区分开,防止关键词被遗漏。
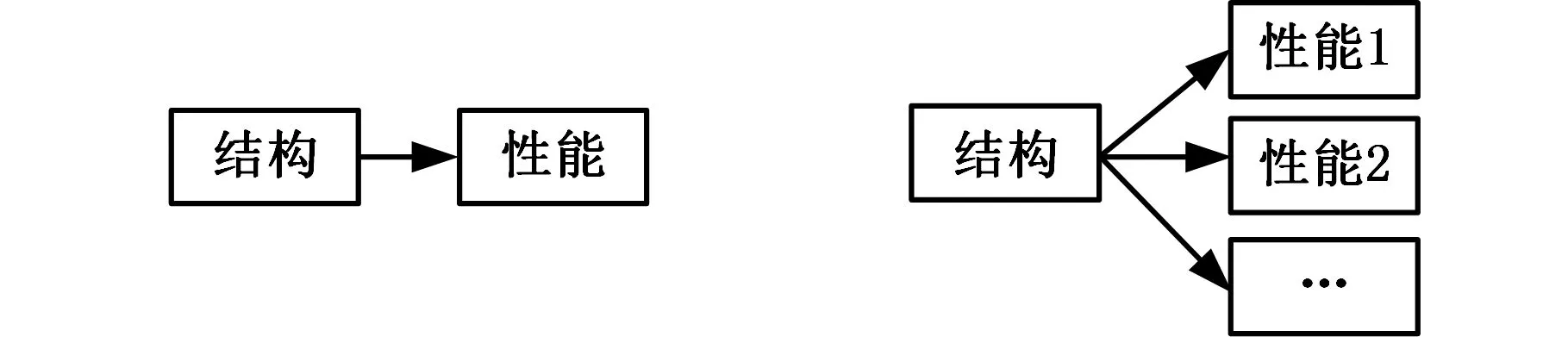
(a)一对一关系 (b)一对多关系
根据主要句法依存关系,不论是一对多、多对一还是多对多关系,关键词对象之间都存在并列关系,因此在挖掘的时候,需要对同句中名词对象之间进行并列关系分析。假设同句中存在结构单词组合s={sl,sk}以及性能组合PH={PHi,PHj},则四种关联关系分类规则及分类结果如表5所示。

表5 关联关系分类规则及分类结果
3.4 方案元件有害性能辨析
由于技术缺陷数据库和目标专利技术文本分别包含多个关键词向量,故需要对两类数据进行关联匹配,进而实现专利有害性能评价。现假定存在设计方案元件集合wS={wS1,wS2,…,wSm},以及有害性能数据库中全部性能集合wP={wP1,wP2,…,wPn}。通过计算不同元件与性能在所有专利中的关联频次,可以算出元件出现某种有害性能的概率,具体计算公式如下:
(5)
式中,Fij为元件wSi出现有害性能wPj的概率;N(wSi,wPj)为出现元件wSi与有害性能wPj产生关联关系的专利数量;N(wSi)为具有元件wSi的专利数量。
通过计算设计方案关键元件不同类型性能出现的概率,为方案改进及创新设计提供参考。
4 实例研究
4.1 数据集及方法
为了验证所提方法的有效性,同时针对目标客户的要求,选择卫浴花洒领域专利作为研究对象。通过智慧芽专利引擎,利用表6中的专利检索式共计下载9353件专利。这些专利的类型包括发明专利和实用新型专利。专利内容分别包含专利标题、专利摘要、专利要求以及技术背景等全文数据。实验环境为:Intel(R)Core(TM)i7-10700 CPU @3.0GHz,32.00 GB内存,Windows 10操作系统。
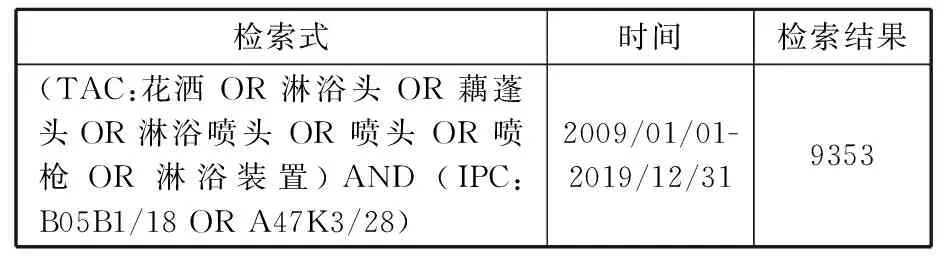
表6 国内花洒专利检索式
本文以全文数据作为词向量训练语料,有效文本数量和关键词数量分别为37 412、11 541 602。采用Python编程语言机械学习包gensim中的word2vec模块来训练查询所需要的词向量。首先选用jieba作为分词工具,并借助本地中文停词数据库去除专利中部分停用词,进而形成语料库。然后将语料加载到word2vec模块中,进行词向量的训练,结果形成词向量库。由于CBOW模型的效率高,故本文采取该模型作为词向量训练工具。针对专利文本的特点以及训练数据的数量,同时参考文献[27]的研究结果,将word2vec参数根据表7进行设置。
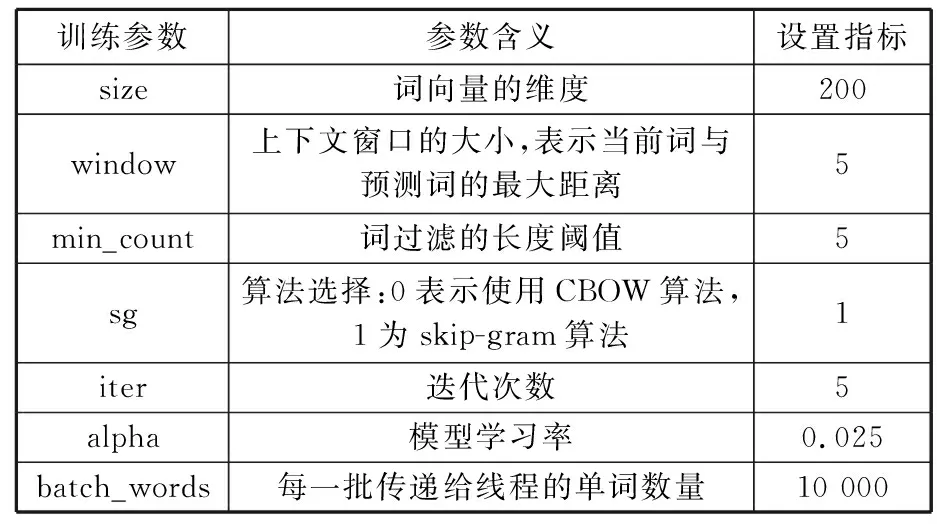
表7 word2vec参数设置
结合多种复合DR算法,对9353件专利的技术背景进行挖掘,一共提取了1 824 299条关系,其中不同规则的提取结果如表8所示。通过表8可以看出两个现象:一方面不同规则的提取数量存在明显差异,如有害性能的提取规则“(wi∈np)∩(wj∈adjl)∩(tag= att)”获取的数量要多于规则“(wi∈adjm)∩(wj∈vt)∩(tag= adv))”获取的数量;另一方面,不同有害性能的提取结果也存在差异,如PHL的数量要多于PHM的数量,说明现有专利方案更加注重通过提高自身产品性能来满足客户的需求。

表8 不同类型有害性能知识提取数量
在获取依存关系信息基础上,进一步挖掘不同结构及其关联有害性能关键词组合,并对有害性能进行分类,部分结果如表9所示。
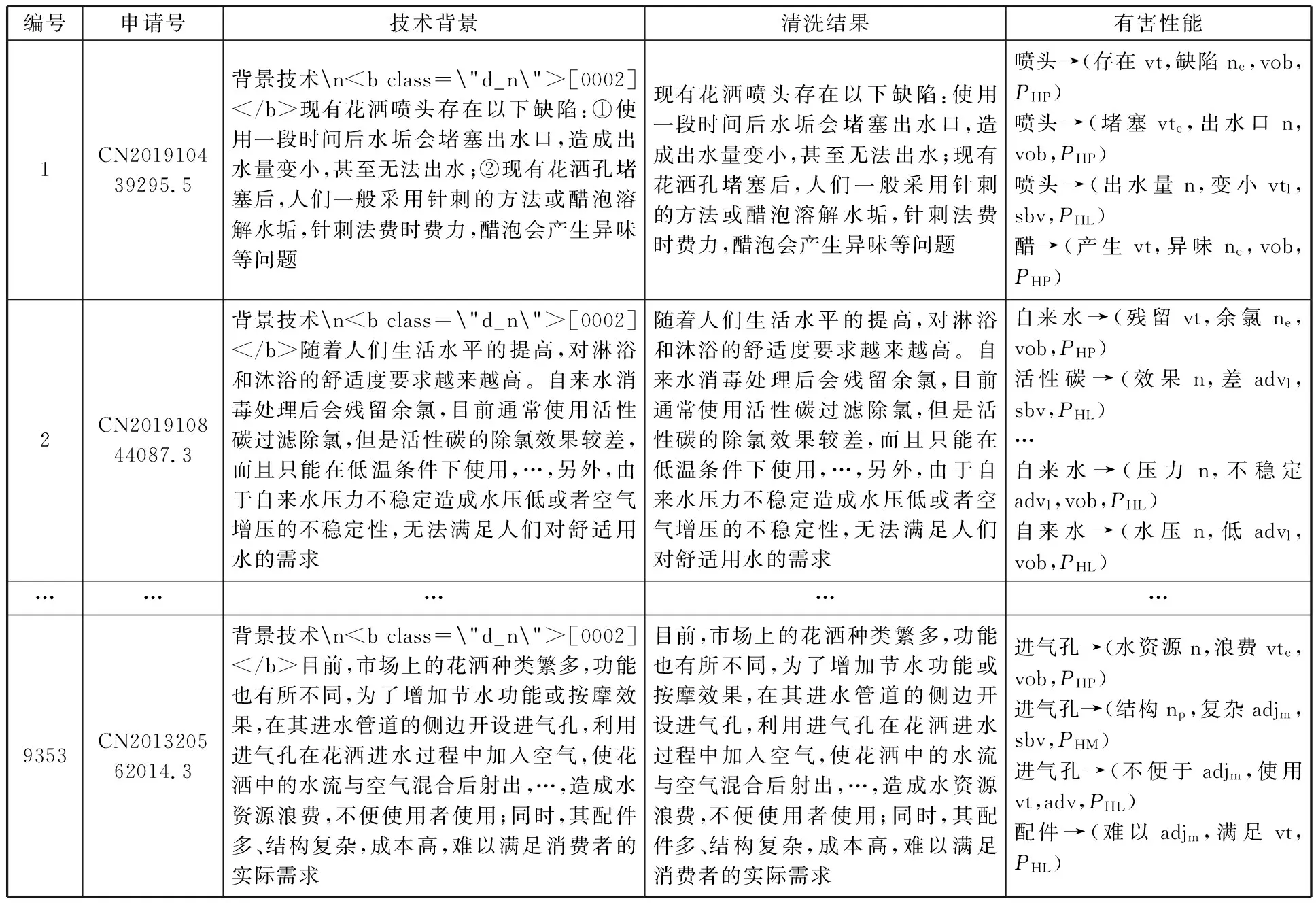
表9 部分专利清洗以及有害性能提取结果
4.2 结果验证
本实验以精确率P、召回率R和F值作为评价指标,以随机抽取200篇专利技术内容文本作为测试对象。采取人工参与方式对整个分析的实验效果指标进行验证,验证计算公式如下:
(6)
(7)
(8)
式中,NTP为正确预测出来的正例样本数量;NFN为错误预测出来的正例样本数量;NFP为错误预测的负例样本数量。
为了验证本文所提方法的有效性,结合现有同类短语挖掘研究成果[28-29],引入另外3种方法进行比较测试,比较结果如表10所示。可以看出词频-逆文档频度(term frequency-inverse document frequency, TF-IDF)算法在有害性能提取方面效果最差,主要是因为该算法采取词频和逆文本频率相结合方法,筛选在语料库中出现次数较少但在单个文档中出现次数较多的词汇。事实上,专利文档中对方案性能的描述出现次数较少以避免反复说明,显然这样导致性能关键词的权值较低,容易被过滤掉。同理,采取互信息熵(mutual information entropy,MIE)算法提取专利文本信息也存在准确率和召回率低的问题,主要还是因为该算法和TF-IDF算法一样,都是根据词汇共现频次来筛选关键词组合。

表10 四种算法结果比较
相比之下,基于DR规则获取产品有害性能关键词的指标要优于TF-IDF算法,因为DR算法有涉及关键词词性的筛选,并通过不同词性的组合获取性能描述组合,适合提取文档中出现频次较低但是重要程度较高的词汇。相比之下,传统DR算法没有考虑同义词,准确率较低。因此融合word2vec算法,可以进一步提高DR算法的精确率和召回率等指标。
4.3 创新设计方案有害性能评价
为了进一步展示所提方法的有效性,选择申请号为CN202010117313.0的花洒专利作为目标设计方案进行展示,如表11所示。由于该专利属于2020年新申请技术方案,较少被引用及关注,故难以通过专利引文获取其技术评价信息。为此利用关联方法获取其技术方案中深层次设计知识。
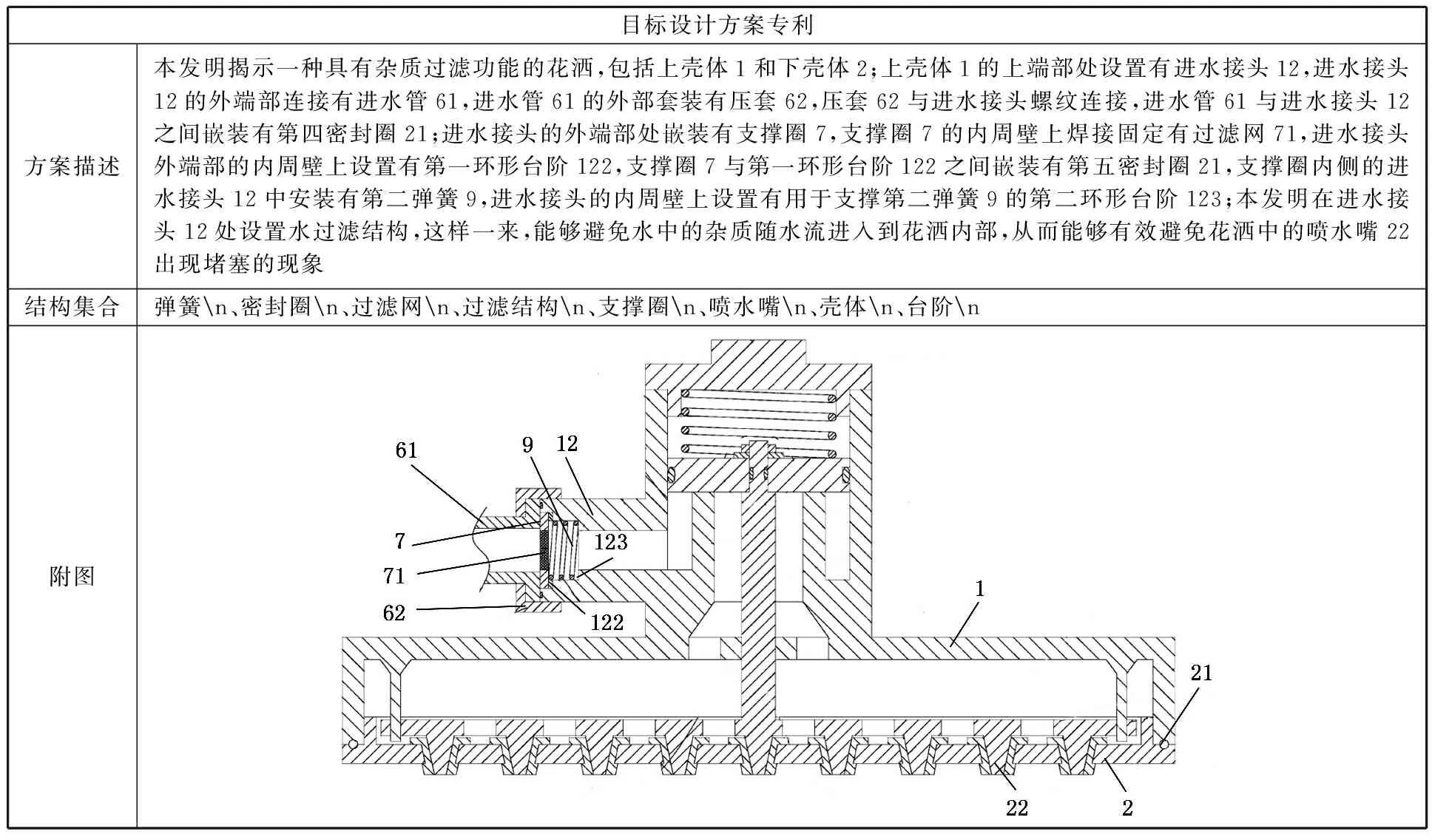
表11 目标专利设计方案分析
首先提取专利技术摘要中的结构关键词,可以看出该专利主要集中在弹簧、密封圈以及过滤网三个对象上。然后在此基础上,结合行业专利数据库对上述元件的有害性能知识进行进一步挖掘及评估。
通过word2vec中词向量空间及其语义相似度算法获取其他同义关键词。为了提高分析效率,选择0.6为过滤无关词汇的相似度阈值,得到同义词及其有害性能数据库关联结果,如表12所示。
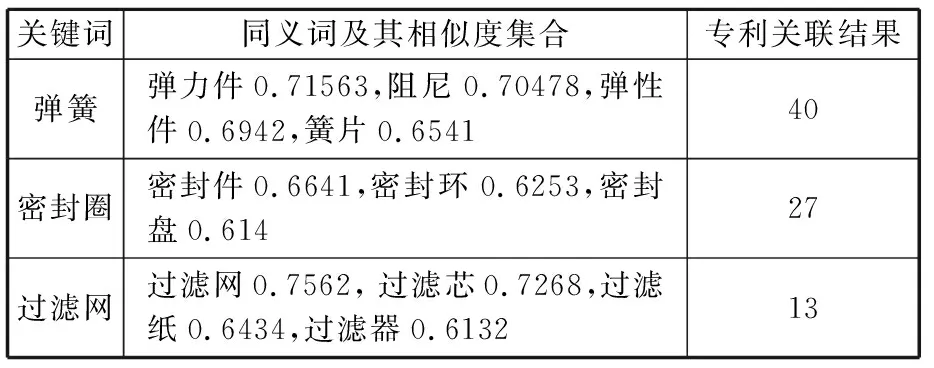
表12 方案元件关键词的同义词及其专利遍历结果
针对不同关键词所对应的专利,分别利用依存关系及词性组合算法获取与关键词相关的有害性能信息,并选择部分概率超过0.13的进行展示,如表13所示。可以看出相同元件会出现诸多不同类型的有害功能。通过分析目标专利的技术摘要,显示该专利主要解决喷嘴堵塞问题,但是其他有害性能没有涉及,表明这些有害性能是发明人忽略或者不关注的技术问题。对此,邀请行业专家对结果进行评价,他们认为该方法的确找出了上述元件容易出现的问题。以弹簧为例,存在生锈的问题,不过可以采取不锈钢材质,所以此类有害性能发生的概率也较低。相比之下,由于弹簧装置是活动件,存在结构复杂、成本高、粘水垢后不易清洗的问题;如果用于按键操作,还存在容易泄漏的情况。这些都是本专利技术规避或者改进设计需要重点考虑的问题。
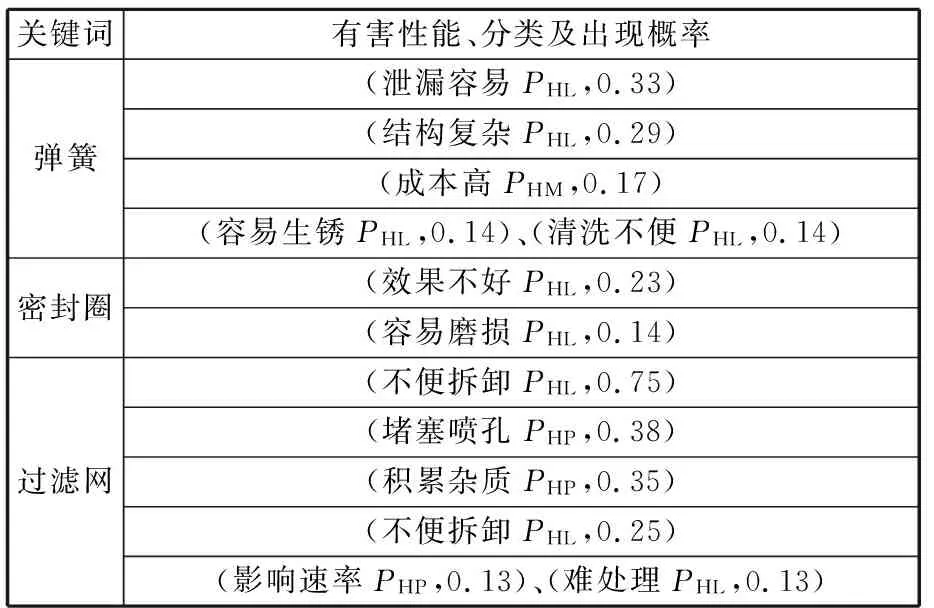
表13 专利有害性能信息
利用语义关联方法不仅可以挖掘专利潜在的技术问题,同时可以计算不同有害性能出现的概率,进而为后期方案改进及创新提供技术参考。
5 结论
(1)从产品设计角度出发,根据作用强度对产品结构有害性能进行分类,并结合专利数据不同部分的特点,研究有害性能的分布情况。
(2)融合行业专利全文数据,利用word2vec算法构建专业知识模型,并借助余弦相似度计算不同关键词的语义距离,提高了文本相似度计算精度,实现了同义词的合并。
(3)借助词性及依存关系,设计针对不同类型有害性能的复合提取规则,同时利用多种分类规则挖掘有害性能与结构关键词的关联关系,并结合专利词频计算有害性能发生概率,进而对专利方案元件有害性能进行分析与评估。
(4)自然语言处理是一个复杂的过程,尤其是深层知识的获取,相关研究还在不断探索及完善中。虽然本文方法在花洒专利方面不论是精确率、召回率以及F值都达到一定水平,但是考虑到不同领域产品专利撰写风格以及文本内容的差别,还需要扩展到其他领域进行验证。同时为了便于产品设计人员数据导入、分析、管理及输出,开发面向有害性能知识的专利文本挖掘系统也是后续研究的重要任务。
