基于随机森林的县域土壤有机碳密度及储量估算
2021-08-23李海萍杜佳琪唐浩竣
李海萍,杜佳琪,唐浩竣
(中国人民大学环境学院,北京 100872)
土壤中的有机碳库相比于无机碳库更加活跃且总量更大[1],故大部分气候变化研究都将有机碳库作为研究对象,研究表明全球土壤有机碳总量为1.15×103~2.00×103Pg,约占陆地生态系统碳储量的2/3[2-3]。土壤有机碳在空间上具有高度的变异性,对其进行精确评估对土壤肥力评价及土壤合理利用、全球碳汇及气候变化研究具有重要意义。
早期的土壤有机碳估算基于少量土壤数据进行,Rubey[4]使用9 个土壤剖面的碳含量,估算出全球土壤有机碳储量为710 Gt。Bohn[5-6]在Rubey的基础上根据不同土壤类型和剖面数据,估算出全球土壤有机碳储量分别为2946 和2200 Gt。Batjes[7]在前人基础上又增加了厚度、容重、有机碳及砾石含量等参数,估算全球土壤有机碳储量在1462~1548 Gt 之间。20 世纪80 年代起,有学者利用生命带类型及其分布面积计算土壤有机碳储量[2]。这种方法难以统计出全球植被类型及其面积,与土壤类型的对应关系也不够准确,且未考虑土地利用等其他因素,难以应用于小尺度区域。20 世纪90 年代后,基于GIS的空间差值方法得到应用,Galbraith等[8]通过空间插值估算整个研究区的土壤有机碳储量,李海萍等[9]将土壤类型法与GIS 方法相结合,在县域尺度上估算了土壤有机碳储量,该方法与土壤类型法类似,只是将结果精确直观地通过GIS 展示出来。
基于土壤类型法和观测数据的估算,发现该方法成本较高却精度有限。许多学者采用遥感数据反演土壤有机碳,将高时空分辨率影像、反映生态系统碳循环动态变化的过程模型、实测土壤有机碳结合起来,从而提高了结果的空间分辨率[10]。也有学者通过建立遥感数据与土壤有机碳储量相关模型进行估算[11-12],不同学者在不同条件下所使用的模型具有明显的针对性,鲜有县域尺度下的土壤有机碳精确估算研究。
模型法能模拟和预测土壤碳储量在自然界中的动态变化趋势,也可解决尺度变换问题,因此能全面细致描述土壤有机碳的含量。随着技术的快速发展,随机森林模型也出现在土壤有机碳的估算研究中,Yang 等[13]使用增强回归树和随机森林模型绘制了青藏高原东北部的土壤有机碳含量分布图,Sreenivas 等[14]对比多种土壤有机碳储量预测方法,通过随机森林模型给出各个解释变量重要性的排序。
云南省玉龙纳西族自治县(玉龙县)有山地、盆地、河谷3 种地貌类型,海拔落差大,山区和半山区占县域总面积的96%以上,地形复杂。因此以其作为研究对象,采用集合方式确定回归树,在县域尺度上进行土壤有机碳储量估算不仅能提高小尺度的估算精度及效率,也为大尺度估算提供精确的基础数据。
1 材料与方法
1.1 研究区
地处云南省西北部的玉龙纳西族自治县,位于青藏高原与云贵高原交界的横断山脉中部,金沙江从西北向东北呈近90°的拐弯,形成了万里长江的第一弯,县域总面积6198.76 km2(图1)。
玉龙县属典型山地高原,受新构造和河流切割影响,高山峡谷地貌特征明显,海拔1300~4500 m,土壤垂直地带性发育完全,依次为亚高山寒漠土(4200~4500 m)、亚高山草甸土(3500~4200 m)、暗针叶林土(3600~3800 m)、暗棕壤(3200~3600 m)、棕壤(2600~3200 m),黄棕壤广泛分布于2500~2800 m 地势低凹的湿润山地,1300~2600 m 为红壤,包含棕红壤、黄红壤、红壤3 个亚类,非地带性的紫色土、沼泽土、草甸土及石灰(岩)土等也有分布,见图2。
1.2 数据
数据主要为土壤采样数据、遥感影像及其派生数据和基于数字高程模型(DEM)提取的地形参数。
土壤采样数据主要依据第二次土壤普查技术要求的采样布点原则,于2009 年5 月至11 月进行实地采样,使用棋盘法布点10~15 个,取样后采用四分法将1 kg 土样分开取样,经实验室分析得到的结果,对原始数据进行检查后共得到686 个有效样点,空间分布见图3。
为保持数据的时间一致性,选用2009 年9 月Landsat7-Level2 影像,空间分辨率30 m。对因SLC传感器故障导致的条带在图像处理软件ENVI 中采用fillgap 插件去除。已有研究表明归一化植被指数(NDVI)与土壤有机碳存在正相关关系[15],因此,基于原始遥感影像,计算NDVI;缨帽变换是一种特殊的主成分变换,最早由Kauth 等[16]提出,通过线性变换、多维空间旋转,不仅可提取植被和土壤信息,还可通过坐标变换将植被与土壤的光谱特征分离,故通过缨帽变换提取地表辐射亮度、植被绿度及土壤湿度等参数。
地形因素可在一定程度上反映土壤有机碳的状态,不同高度因光照、温度、水分等差异而使土壤微生物的活动也不相同,间接影响到土壤的腐殖化过程。将高程、坡度、坡向、曲率、地形湿度指数等作为土壤有机碳估算的辅助数据,能有效提高估算结果的精度。地形变量的提取主要基于数字高程模型(DEM),本研究采用SRTM(航天飞机雷达地形测绘使命)90 m DEM,分别提取坡度、坡向、曲率和地形湿度指数,并以45°间距将坡向分为8 个方向。
1.3 基于克里金差值的土壤有机碳储量估算
土壤在空间上呈连续变化,因此,需要将采样点数据空间化,采用克里金插值,该方法因考虑样本的形状、大小及其与预测点空间位置的关系而成为常用的线性无偏最优估计方法,公式为:
克里金插值考虑空间自相关,因此,先要判定数据的半变异函数并拟合相关参数,在ArcGIS 中将采样点的经纬度坐标转换为投影坐标并导出文本文件,采用GS+7.0 地统计分析软件分别进行线性、球型、指数和高斯4 种常用理论模型的拟合,拟合参数见表1。
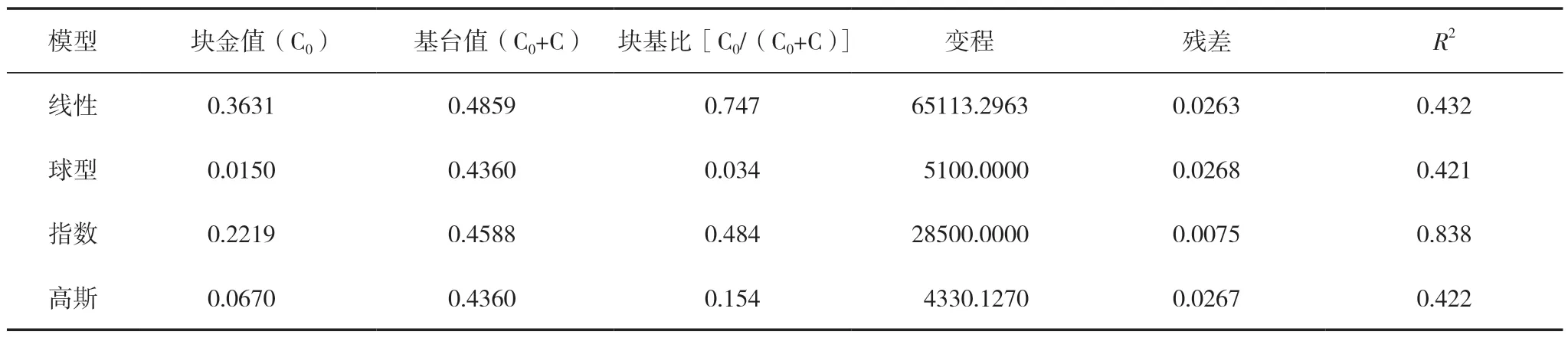
表1 半变异函数拟合模型参数
比较发现,指数模型残差最小而决定系数最大,0.484的块基比说明土壤有机碳密度的空间变异是随机性因素与结构性因素共同引起的。故选择指数模型进行插值试验,当步长为10 时拟合效果最好。
根据插值结果并结合土壤类型,计算土壤有机碳储量,公式如下:
因原始数据缺乏土壤容重属性,故依据Song等[17]的研究结果进行估计,公式如下:
因采样点均为耕地,各类型土壤的砾石含量较少,故采用耕地容重模型并忽略砾石含量,得到基于栅格的土壤有机碳密度。
1.4 随机森林模型估算土壤有机碳密度
1.4.1 随机森林模型
随机森林是基于分类和回归树(CART)延伸出的机器学习新算法,由Breiman 等提出,在运算量没有显著提高的前提下提高了预测精度,且对多元共线性不敏感,结果对缺失数据和非平衡数据比较稳健,能很好地预测多达几千个解释变量的作用[18],被誉为当前最好的数据挖掘算法之一[19-20]。
决策树通过建立对象间属性与值的映射关系来构建训练数据的树模型,既可用于分类,也可进行连续变量的预测。算法将所有数据作为一个根节点,从全部特征中挑选一个分割后生成若干子节点,采用节点-分支的树结构进行决策,每个非叶子节点是一个判断条件,每个叶子节点是结论,从根节点开始,判断每一个子节点,若满足停止分裂的条件则将该节点设为子节点,多次判断后输出节点占比最大的类别。
随机森林对决策树进行了优化,在变量(列)和数据(行)的使用上进行随机化,生成多个分类树,再汇总分类树的结果。从解释变量中随机抽取n 个子样本,针对每个样本建立一棵分类树,通过对多个样本数据训练、分类后进行预测,森林由多个决策树组成,为避免树间的相关性,采用套袋法获取不同的训练数据以增加其多样性,再通过放回方式抽取数据集,过程中的数据完全随机,有可能某一数据被多次使用,也会出现从未使用的情况,结合回归策略输出最终结果。
随机森林的构建方式使其更加稳定,构建森林时使用数据集的最佳特征降低每棵树的强度,对于任意划分的特征G,对应的任意划分点S 划分成的数据集A1与A2,且A1与A2各自的均方差与均方差之和最小时所对应的特征值为划分点,随机选择每个节点的特征,对比不同情况下的误差以减少树间的相关性泛化误差,最终的回归预测值为所有树的预测值均值。
1.4.2 随机森林建模
土壤有机碳生成机理复杂且影响因素较多,随机森林又具有较强的高维数据处理能力,还能对各个影响因素的重要性进行解释,适于进行土壤有机碳的定量研究。
模型最初主要通过R 语言中的随机森林包、栅格包等实现[21],2019 年ArcGIS Pro 在其2.3 版本中增加了这一功能模块,既可对采样点数据建模,也可对矢量或栅格数据建模,通过加入相应的栅格或矢量变量可直接获得预测结果的空间分布,并对多个变量的重要性进行排序,比编程更便捷高效。
在ArcGIS Pro 环境下,采用“分析-工具-空间统计工具-空间关系建模-基于森林分类与回归”功能,将土壤有机碳密度(SOCD)作为预测变量,分别导入坡度、坡向、曲率、DEM、地形湿度指数等地形变量以及NDVI、亮度、绿度、湿度等环境变量,作为模型的解释变量。
2 结果与分析
2.1 表层土壤有机碳储量估算结果
2.1.1 变量的描述性统计
对687 个采样点0~20 cm 深度的土壤有机质含量、有机碳含量、有机碳密度、土壤容重等属性,以及NDVI、亮度、绿度、湿度等环境参数和坡度、坡向、曲率、地形湿度指数等地形参数的描述性统计结果见表2。
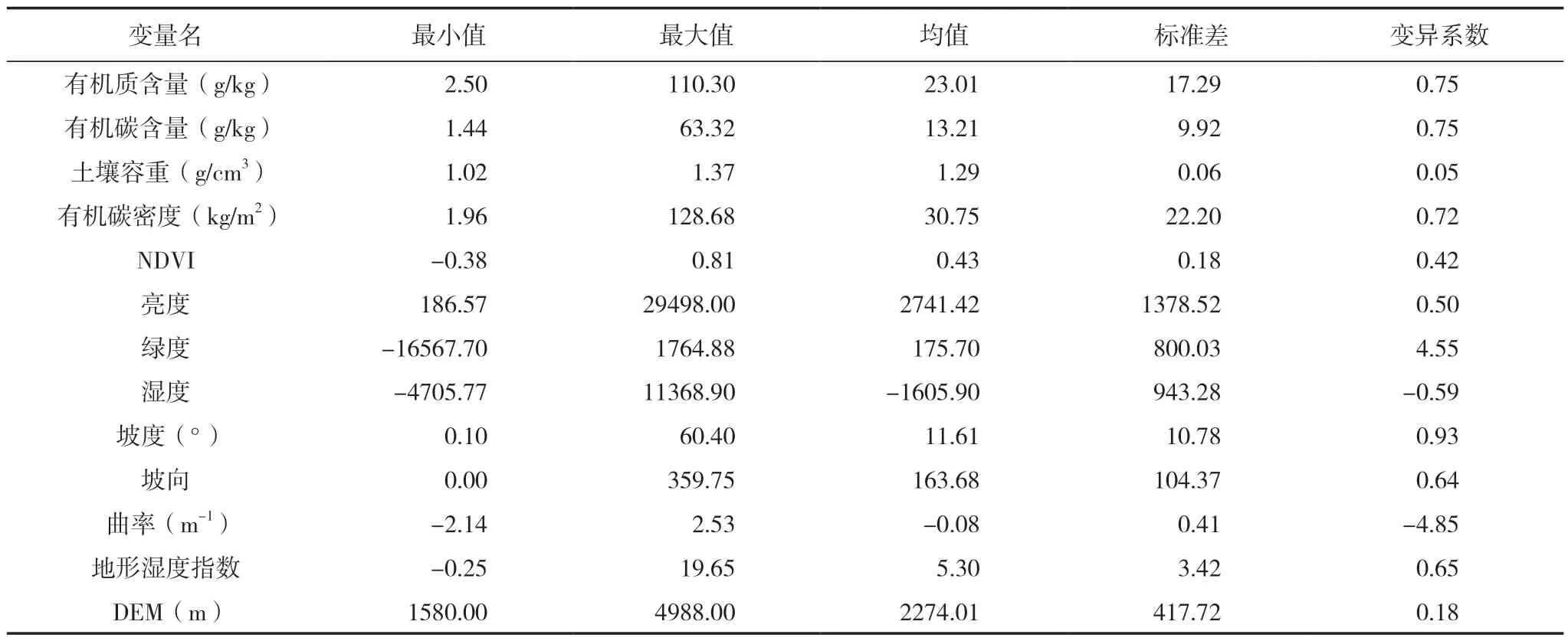
表2 土壤有机碳及其相关变量描述性统计
变异系数显示,表层土壤的有机质含量、有机碳含量、有机碳密度、绿度、坡度、曲率的离散程度较大,说明研究区植被分布差异大,地形复杂度高,NDVI、亮度、湿度、坡向、地形湿度指数及高程的离散程度较小。
2.1.2 表层土壤有机碳总储量
分别以克里金插值与随机森林模型所预测的土壤有机碳密度为属性值,在ArcGIS 中统计栅格单元的值及其面积,两者的乘积即为该栅格的土壤有机碳储量,汇总后得到整个研究区表层土壤的有机碳总储量,克里金插值结果为2.4×108t,随机森林结果为1.7×108t。
2.2 土壤有机碳密度空间分布
2.2.1 克里金插值空间分布特征
采用指数模型及其参数进行克里金插值计算,得到0~20 cm 表层土壤的有机碳密度及其空间分布,见图5。
图5 显示,土壤有机碳密度的高值区集中在西北部、中部山地以及东南部金沙江及其支流沿岸的平坦区域,最大值为66.5 kg/m2,东北部的玉龙雪山为低值区,最小值为7.82 kg/m2,中部的水域和城镇也为低值区,因采样点的空间集群特征而使插值结果不够平滑,对空间分布的连续变化特征表达较差。
2.2.2 随机森林空间分布特征
以土壤有机碳密度为预测变量,以NDVI、亮度、绿度、湿度、曲率、坡度、坡向、地形湿度指数为解释变量,进行随机森林回归预测,对叶子数、树数多次实验后发现,当生成1000 棵树时误差趋于稳定,故将森林树量设为1000 棵,叶子节点为5,树深范围0~25,平均为7,每棵树可用的数据百分比为100%,随机采样变量数为3,输出栅格与Landsat 一致,为30 m×30 m,得到土壤有机碳密度的空间分布如图6。
结果显示,土壤有机碳密度最高为79.37 kg/m2,最小为13.34 kg/m2,整体上西高东低,西部的高值区主要为河流下游及其沿岸。对照土壤类型分布,红壤及棕壤的有机碳密度较高,此外,海拔适中地区的有机碳密度也较高,中部地形平坦区及东部边界区则较低,0 值的空白区为金沙江河谷两岸及丽江市城区,是河流与人类活动区的多个变量为空值所致。
随机森林所提供的变量重要性排序能反映其对预测变量的解释程度,根据去除该变量时模型所受的影响进行估算,结果见表3。
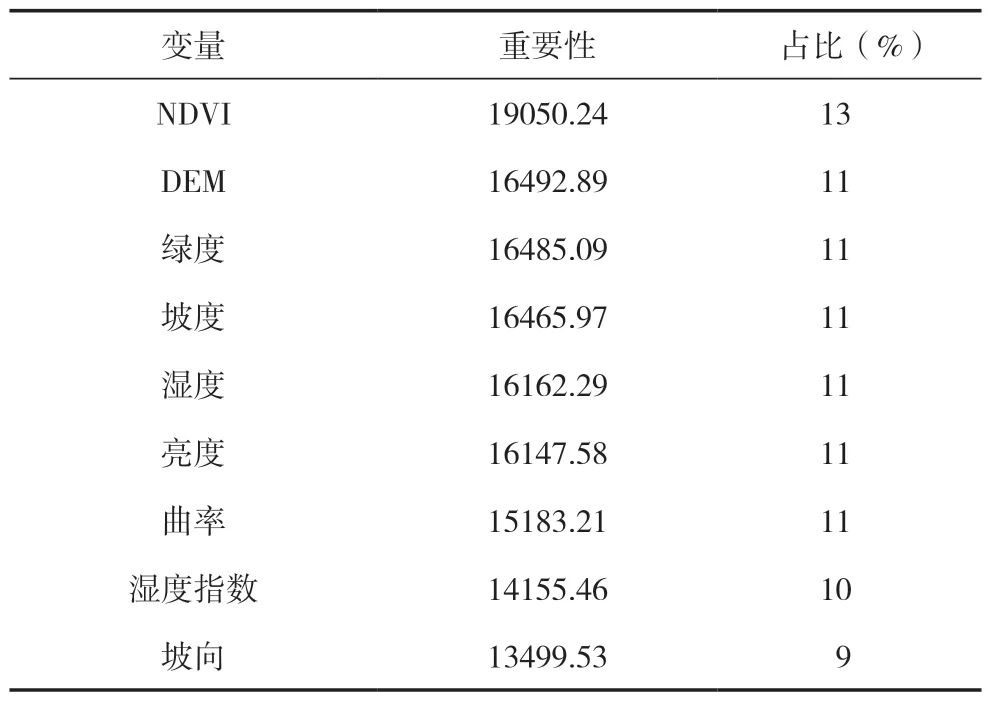
表3 随机森林模型各变量的重要性排序
NDVI 占比最高,坡向最低,说明NDVI 对土壤有机碳密度的解释作用最大,坡向则最小,其他变量的解释程度基本一致。
2.3 精度验证
2.3.1 普通克里金插值的精度验证
将数据分成训练集(2/3)和测试集(1/3),用测试数据集验证克里金插值的精度表现,比较不同样点的测量值与预测值,计算均方根误差、标准平均值、标准均方根误差、平均标准误差等精度评价指标,结果见表4。

表4 普通克里金插值模型精度
精度验证的参考标准一般为均方根误差越小越好、标准平均值接近0,平均标准误差接近于均方根误差,平均标准误差接近于1的估计为最优估计。本研究的标准平均值近于0,标准平均值很小,平均标准误差接近于均方根误差,但均方根误差达20.77,说明克里金插值结果与最优估计还存在一定差距。主要由于实际采样困难,难以达到插值所要求的样点均匀分布条件。
2.3.2 随机森林模型精度验证
随机森林算法每次抽取约2/3的样本,套袋时第k 棵树中未被选用的训练样本称为“袋外”(OOB)子集。OOB 子集对于训练集是不可见的,可用来对模型精度进行验证,此处采用默认设置,即验证数据为总数据的10%,验证精度见表5。

表5 随机森林精度验证
决定系数R2是主要的性能指标,本研究的验证结果大于0.5,说明模型的解释能力强,且较为稳定,达66.7%。但均方根误差较大,究其原因,因Landsat7 原始影像存在缺陷,虽进行了条带修复,但条带区域的误差无法避免,因此用其提取其他解释变量时必然存在误差传递和积累,加之横断山区地形复杂,也使验证结果不甚理想。
3 讨论
空间插值主要根据有机质、容重、采样深度等计算出的采样点土壤有机碳含量进行。不同土壤的有机质转换系数应有所不同,本研究由于数据的缺陷而采用了统一的转换系数,故不能精确解释每个采样点的情况。此外,土壤容重主要通过环刀法测定,而本研究的采样数据未进行容重测定,基于经验公式的模拟结果精度有限。再者,样点空间分布不均匀也导致了插值结果的空间分布不平滑,样点稀疏区域比较粗糙。
随机森林模型需要较多的解释变量,本研究基于Landsat7 影像提取其他变量,虽进行了条带修复,但仍然影响到所提取变量的精度。90 m DEM与30 m Landsat7 空间尺度的不一致也影响了模型结果的精度,基于土壤类型法计算出的有机碳密度本身就存在误差,再经过解释变量的回归模拟必然会出现误差传递和放大效应,增加了结果的不确定性。
两种方法的差异性表现在随机森林的高值区分布在西北、中部及东南部,低值区在东北及南部地区,克里金的低值区与随机森林大体相同,但中部的高值区差别较明显。
此外,本文仅对0~20 cm的表层土壤有机碳密度进行预测,未能对100 cm 内的土壤进行分层预测,对缺失的容重参数进行拟合也影响了结果的精度。
解释变量的选取是影响随机森林预测结果的重要因素,若能获取更深层的土壤数据,并辅之以人类活动、气候、土地利用、pH 值等更多解释变量,就不会出现本研究因解释变量值缺失所造成的人类活动区域结果为0的情况。
4 结论
基于GIS的普通克里金插值所需变量较少,能够快速预测土壤有机碳密度及其空间分布,且预测结果与随机森林结果相差不大,但其结果受采样点数量及其空间分布的影响较大,用于横断山区的玉龙县这种样点少且分布不均匀的情况时结果较粗糙。随机森林模型因所需变量多而效率较低,且算法复杂也使处理速度较慢,但预测结果的精度以及对小尺度区域的细节表现优于普通克里金插值,通过变量的相对重要性评估也可深入了解各变量对模型的影响,因此更适于对高维数据进行分析。
