基于K- Means 聚类算法的数据分析
2021-08-23邵小青贾钰峰章蓬伟
邵小青 贾钰峰 章蓬伟 丁 娟
(新疆科技学院信息科学与工程学院,新疆 库尔勒 841000)
1 概述
机器学习中有两类大问题:一个是聚类,另一个是分类。聚类是统计学的概念,属于非监督机器学习(unsupervised learning),应用中数据挖掘,数据分析等领域,根据数据不同特征,将其划分为不同的数据类,属于一种无监督学习方法。它的目的是使得属于同一类别个体之间的密度尽可能的高,而不同类别个体间的密度尽可能的低[1]。分类是用已知的结果类别训练数据,对预测数据进行预测分类,属于有监督学习(supervised learning),常见的算法如逻辑回归、支持向量机、深度学习等。聚类也是对数据进行归类,不过聚类算法的训练数据只有输入,事先并不清楚数据的类别,通过特征的相似性对文本进行无监督的学习分类。聚类试图将数据集中的样本划分为若干个通常不相交的子集,每个子集称为一个簇(cluster)[2]。K-means 属于经典聚类算法,根据样本间的距离或者相异性进行聚类,把特征相似的样本归为一类,相异的样本归为不同的簇。
2 理论基础

While(t) t 为迭代次数
For i in range(n+1): #n 为样本点个数。
For j in range(k+1): #k 为簇的数目。
For i in range(k+1): #计算样本i 到每个簇质点j 的距离。
找出属于这个簇中的所有数据点,计算这类的质心。重复以上步骤,直到每类质心变化小于设定的阈值或者达到最大的迭代次数。设置最大特征数,设置分类的组K 值,训练特征数据进行数据分析。
本文将数据过滤清洗,去除停用词转化为向量模型,使用TF-IDF 算法对词频进行权重计算,TF 是词频,IDF 是逆文档频率,TF-IDF 反应了一个词在文本中的重要性它的值是TF×IDF。 使 用 Python 中 的 sklearn 模 块 的 TfidfTransformer、CountVectorizer 方法计算TF-IDF 值,转化为空间向量模型,选用K-means 聚类算法对数据进行挖掘与分析。
3 实验结果与分析
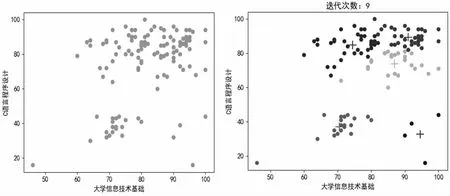
本文选择新疆科技学院某专业期末作为分析对象,选取大学信息技术基础和C 语言程序设计成绩作为实验数据。利用Python 聚类模块K-means 构建聚类模型并实例化,设置分类K=5 值。其中K 值选取直接影响K-means 算法的准确性,选取K值常见的方法有手肘法、Gap statistic 方法。下一步训练特征数据,查看聚类结果labels,对数据进行聚类分析,部分代码如下。


4 结论与不足
通过对数据聚类分析表明成绩可以大致分为4 类,其中大学信息技术基础学生成绩较好,C 语言程序设计对学生有一定难度,想要提高总体成绩,需要重点放到在C 语言程序设计这门课上,建议优化教学设计,采取任务驱动式教学,分层次因材施教,培养好学生的计算思维能力,为后面的专业课打好基础。
K-means 具有实现简单,应用广泛等优点,但由于需要指定K 值簇,直接影响分类的准确性,聚类结果可能会收敛到局部最小值。对于不规则形状的数据效果差。在现实生活中,簇并不总是均匀分布的,并且特征的权重很少相等。本文对期末成绩数据进行聚类分析是cluser 设置成5,有一定的满目性,通过迭代9 次各组数据达到收敛。下一步要提高数据集的数量,选择学生所有的成绩数据,合理选择K 值,高维映射等,优化K-means 算法,更客观地进行数据分析。
