GTC2021 GraceCPU暴露英伟达的野心?
2021-06-20张平
张平


GTC是英伟达一年一度的技术盛会。在今年4月13日的GTC上,英伟达CEO黄仁勋依旧在厨房、依旧穿着皮衣面向全球用户进行着网络直播。不过和2020年“端出来”一整盘A100相关GPU不同的是,今年的GTC2021,黄仁勋“端”出来的是ARM架构的CPU、数据加速DPU以及面向汽车驾驶的SoC等产品。尤其是CPU的发布,迎来业内一片讨论热潮。这一次英伟达打算做什么?ARM架构的CPU登场,意味着英伟达计划和英特尔正面厮杀了吗?
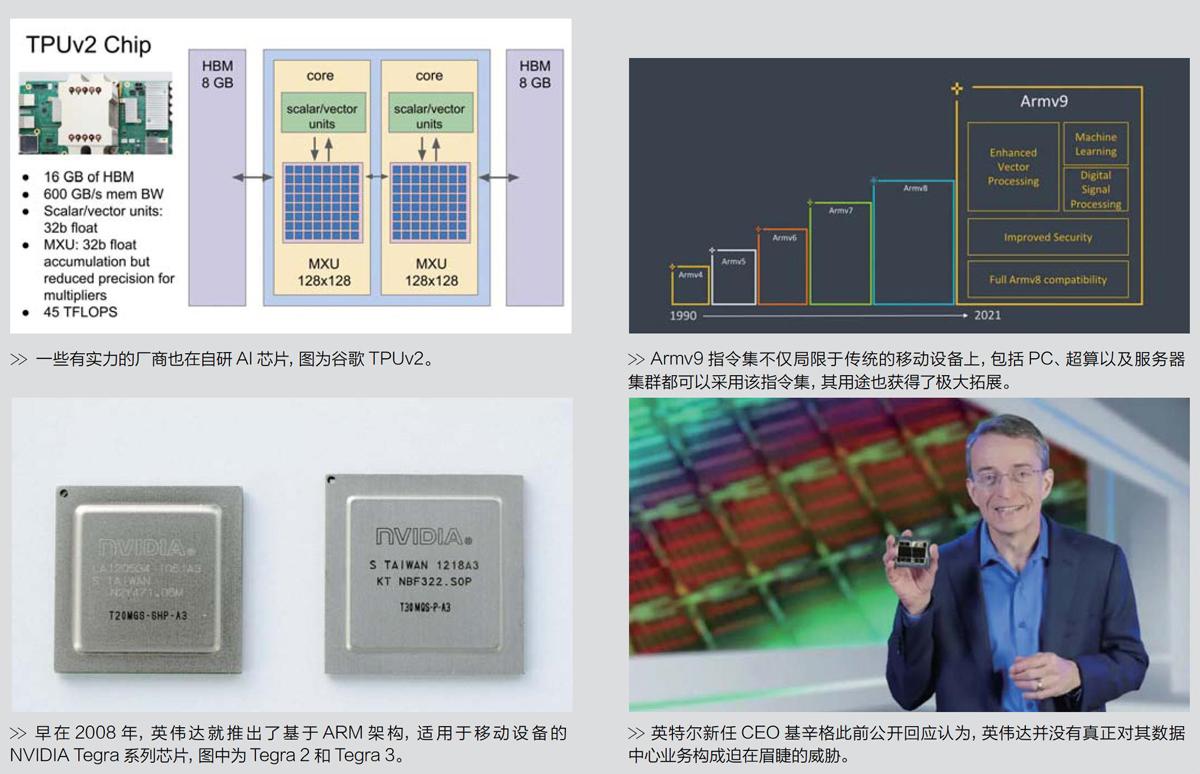
英伟达一直是—锐意扩张的企业。从GPU起家,随后进入图形计算、视觉计算市场,在多年耕耘后,终于乘上了AI计算的东风。现在的英伟达已经发展成为一家以人工智能计算为主,控制了大部分视觉计算市场和资源,并逐渐进入服务器、HPC市场的超大规模企业。其股票也从早期的数美元,一路暴涨至近期的600美元左右,公司市值也已经逼近4000亿美元,远远超过市值2800亿美元,拥有全产业链、全系列制造技术的英特尔,风头无两。
这些数据和成就的背后,英伟达锐意进取的态度和不断扩张的商业手段是关键。就在最近的2020年,英伟达宣布将收购ARM,希望借此进入移动GPU、移动CPU以及ARM相关处理器市场并掌控移动计算和其延伸产业的发展方向。虽然这顼收购目前被包括美国、英国企业在内的多家企业明确反对,却也没有影响到英伟达和ARM越来越深入的合作,并且合作的结果很快也显现出来。
在笔者看来,在2021年的GTC大会上,英伟达的最大新闻并不是发布了DPU和全新面向汽车行业的SoC,而是带来了代号为“Grace”的CPU广品(后文间称GraceCPU)。这款产品将用在英伟达即将推出的数据中心产品中,并搭配英伟达下一代GPU产品,实现英伟达在数据中心、HPC以及计算设备上的CPU+GPU“大一统”。
GraceCPU的发布,在业界迅速掀起了巨大的波澜。英伟达的股价从发布会之前的550美元左右一举冲上了630美元。与此对应的是英特尔的股价大跌7%,AMD的股價也受到了影响。部分市场分析人士也认为英伟达的GraceCPU是对英特尔的正面冲击。那么,事实真的是如此吗?英特尔是否真的危险了呢?
GraceCPU:从发布会说起
要明确GraceCPU的影响,可以从现有的资料和情况进行分析。在GTC2021上,英伟达提到GraceCPU将用于“计算领域的细分市场”;GraceCPU采用的是“ArmNeoverse”内核,其CPU在SPECrate2017_int_base基准测试中的分数超过了300分;GraceCPU和GPU的连接部分则采用了第四代NVLink,CPU到GPU的带宽超过900GB/S;内存则采用的是LPDDR5。英伟达表示,GraceCPU将搭配英伟达的GPU,配合瑞士国家计算中心建造一个算力可达20Exaflops的超算。另外,美国洛斯阿拉莫斯国家实验室也在考虑使用GraceCPU和GPU搭建全新的超算系统。
根据英伟达在本次大会后发布的白皮书,我们可以进一步分析:GraceCPU所使用的“ArmNeoverse”应该不是现在ARM发布的版本,而是采用下一代Armv9指令集的新Neoverse架构,这也和GraceCPU计划在2023年初上市在时间上相吻合。结合ARM在前段时间刚刚公布了全新的Armv9架构,可以确定GraceCPU肯定将引入Armv9指令集新加的大量功能。根据ARM官方内容,Armv9指令集主要是增强面向矢量、机器学习和数字信号处理器的相关内容,这和英伟达在GraceCPU上的诉求是高度相似的。
另外,英伟达在随后的新闻稿中也提到,GraceCPU是高度专业化的、面向巨型人工智能和HPC的产品,可以训练拥有超过一万亿个参数的NLP模型。英伟达还提到“今天最大的人工智能模型包括数十亿个参数,并且每两个半月翻一番。训练它们需要一种新的CPU可以与GPU紧密结合,消除系统瓶颈”。
俗话说,听话听音。虽然英伟达在发布会上并没有透露太多GraceCPU的信息,但是英伟达还是带来了很多关键点,比如GraceCPU面向的是一个比较窄且专业的领域、对带宽的需求是极其巨大,其本身性能表现比较2021年的产品还是可以的,已经逼近AMDEPYC7763这种当前x86架构下最强的CPU,但考虑其2023年才发布,这个诉求也并不夸张。显然,GraceCPU是用来帮助英伟达解决一个棘手问题的产物,解决这个问题可能并不会针对谁,但它带来的影响和余波却真的会影响到现在的行业格局。
AI计算:核心的问题是带宽
那么,英伟达需要解决的问题是什么?我们继续来看GTC2021上黄仁勋的演讲。在演讲中,黄仁勋特别提到,英伟达并不否认x86设备存在的意义,英伟达依旧认为x86设备拥有灵活的扩展性和对各类设备的支持,x86依然是目前HPC或者服务器应用场合的重点。不过问题来了,英伟达认为x86设备目前存在一些困难,其中比较典型的就是带宽不足。
英伟达的例证显示,目前x86设备的核心是x86CPU,x86CPU通过内存控制器连接DDR4内存,最新的英特尔至强处理器可以实现8通道DDR4内存连接,其带宽大约为200GB/S,但是和GPU连接的带宽只能依靠PCIe4.0×16,带宽大约只有16GB/S(双向32GB/S),同时GPU本地内存(显存)的带宽在使用HBM2的情况下大约可以达到2000GB/S。在这种情况下,当一个巨大的AI计算模型被读入系统需要CPU交由GPU计算的时候,GPU将其从主内存拷贝至本地内存(显存)的带宽仅为64GB/S—英伟达在这里的计算还是比较宽泛的,因为英伟达考虑到了1个CPU连接了4个GPU。每个GPU都可以使用16GB/S的带宽从CPU主内存中读取数据,因此4个加起来的带宽就是16x4=64GB/s。
这里的瓶颈显然就是CPU至IJGPU,如果说GPU本身的带宽是8车道高速公路的话,那么CPU本地带宽也许可以比作4车道的城市道路,而CPU到GPU的带宽只能看成一般的乡村道路了。从2000GB/S到200GB/S再至丨」16GB/S,这里的数据带宽跌落是以数量级的形式存在的,这显然不符合现代计算设备对数据带宽的强烈“渴求”。
为了解决这个问题,英伟达也想了很多办法,比如游说业内企业采用自家更高速的总线NVLink,不过到目前为止只有IBM的Power家族处理器给予了支持,其余的包括英特尔和AMD在内的企业都没有给予回应。考虑到Power处理器昂贵的价格以及其并不可能被英伟达完全掌控,因此英伟达开始慎重地考虑自己建立CPU平台。终于在购买了ARM授权并宣布收购ARM后,英伟达推出了GraceCPU,并希望借此来解决前述的带宽问题。
根据英伟达的规划,GraceCPU和GPU的连接通道不再是传统的PCIe,而是改用了第四代NVLink,其可以提供高达500GB/S的数据带宽。GraceCPU的内存控制器改用LPDDR5X,英伟达没有公布其具体的位宽情况,但是给出了一个数据带宽为500GB/s。
目前还不知道英伟达如何达到如此高的CPU带宽,因为这里存在一个很大的问题是LPDDR5X应该是32bit的颗粒,以现在LPDDR5最高6400MT/S的速率来计算的话,LPDDR5X速率可能最高在8000MT/S左右。这样一来,GraceCPU的内存位宽需要达到512bit才能实现大约500GB/S的带宽,也就是支持16个内存通道,这对一款CPU来说是非常不可思议的,并且GraceCPU还拥有第四代NVLink总线用于和GPU连接。这意味着CPU内部大量的面积和晶体管需要用于外部接口和高速总线。
根据英伟达公布的GraceCPU搭配下一代HopperGPU的示意图来看,GraceCPU内部的CPU部分划分为4个区域,每个区域拥有24个核心,总计有96个核心,再加上周围大量的总线和相关接口,GraceCPU的面积应该不会太小,我猜测其尺寸应该和隔壁的HopperGPU相差不多。考虑到类似的NVIDIAA100GPU面积已经超过800mm2,因此GraceCPU在2022?2023年的3nm或者更先进的工艺加持下,其包含的晶体管面积应该非常大,而且成本不低。
耗费了如此巨大的成本之后,英伟达获得了梦寐以求的针对AI计算以及气候、材料科学、高级天气计算等高带宽HPC解决方案。根据黄仁勋的介绍,除了HPC$h,面向行业用户的新产品,英伟达将集成8个GraceCPU,每个提供500GB/S的内存和500GB/S的NVLink带宽,8个GraceCPU搭配GPU后将使得内存到GPU的数据读取带宽提升至4000GB/S,这对大型或者超级大的AI计算模型来说是非常有利的,尤其是相比PCIe总线一即使是2023年PCIe5.0上线,读取带宽翻倍,届时8个PCIe5.0×16通道的带宽也应该只有大约256GB/S,即使到时候PCIe6.0都已经发布并在产品中部署(可能性不大),同等条件下其带宽也仅仅只有512GB/S,大约只有英伟达GraceCPU+GPU方案的1/8。
影响巨大:重新细分计算市场
从上文的分析可以看出,英伟达推出GraceCPU和相关产品的目的是为了解决AI计算和类似超大规模计算中存在的带宽问题。毕竟在现有的x86架构下,带宽已经严重制约了这类计算的发展。因此从这一点来看,GraceCPU可能能够重塑现有AI计算的市场,从而更加巩固英伟达在AI计算市场中的地位。
对英伟达来说,AI计算是其股价飙升的关键,并且英伟达现在已经是事实上成为AI行业的风向标。GraceCPU发布后,英伟达将在已经非常火爆的AI计算市场中再次细分出一个区域一也就是本文提到的,不依赖x86架构,以英伟达和ARM为主要计算架构供应者的全新AI计算生态圈。
这个AI计算生态圈解决了之前AI计算对带宽的“渴求”,通过GraceCPU、英伟达的GPU、NVLink、LPDDR5X
等为大规模数据、超大规模数据的AI计算需求提供了解决菌口。对于这类全新广品,再力口上附加的英伟达CUDA和相关AI的软件产业圈,应该很快就可以打开市场,为AI计算的发展带来全新的方向。
其次,英伟达的GraceCPU并非针对英特尔和AMD的x86产品,它们在定位上的差距还是比较大的。正如前文所说,英伟达的GraceCPU在性能方面并不是重点,根据英伟达公布的数据,其整数算力目标是在SPECrate2017_int_base中提供300分以上的成绩,浮点算力目标值暂时未矢口。GraceCPU的重点依旧是解决CPU和GPU互联中的带宽问题,并且英伟达也提到并不排除x86计算市場,英伟达的目标是为所有计算市场都提供可匹配的广品。另外,目前x86市场已经形成了一个庞大且拥有长久历史积累的生态圈,任何企业面对这个庞然大物首先想到的应该是加入,而不是直接挑战。
不仅如此,英伟达在CPU上的努力都会成为该公司在未来发展的助力。毕竟现在拥有一个完整、闭环的产业生态是所有企业发展的目的。英特尔在GPU上努力,AMD在软件和产业圈上努力,英伟达自然应该在CPU上努力。如果英伟达借助ARM的指令集和生态圈,在企业级、服务器以及HPC领域培育出属于自己的整个生态系统,那也是非常值得期待的。
第三,英伟达目前也存在很多竞争对手,英伟达需要持续加强技术护城河。比如英特尔一直在持续加强CPU在AI方面的计算能力,推出了DLBoost、AVX-512等相关指令集,并且还通过自研GPU进入了并行计算市场。另外,目前全球市场也涌现出很多专注于AI计算的企业,一些巨头也开始布局AI计算,比如亚马逊、谷歌、百度、阿里巴巴等,都在不断地投产自己的AI计算芯片。在这种情况下,如何守住基本盘并开拓新市场就是英伟达需要考虑的内容。在ARM的加持下,英伟达在CPU端拥有了强力助力,加上自己在GPU端的先天优势就能够将自己的技术壁垒再次抬高,继续成为行业中不可替代的选择。
GraceCPU暴露英伟达的野心?
从上文的分析来看,英伟达针对GraceCPU的布局主要有以下意义。首先是重新细分计算市场增加利润增长点;其次则是有利于加强自己的技术壁垒,同时在CPU计算方面给出自己在未来成长的可能性;另外一点则是可以通过GraceCPU进一步加高自己的技术壁垒,抵抗竞争对手对市场的侵蚀。
因此,在现在这个阶段,我认为英伟达在数据中心CPU上的所有操作都还是在为自己蓄力,并不是以正面抗衡英特尔和AMD以及整个x86产业生态圈的目的。如果说非要有一些想法的话,那也可能是英伟达在尝试另起炉灶,想要在x86的束缚下解脱出来,给自己的未来发展带来一个新的希望,这也算是其野心暴露的一种端倪吧!
