基于机器学习算法进行电影票房预测
2021-06-16席一锴
席一锴
(江苏省新海高级中学,江苏连云港,222000)
0 引言
随着我国经济的快速发展,人们的生活水平稳步提升,在追求物质生活的同时,也不断追求着精神层面的满足,观看电影是当下大众消遣娱乐的基本形式,好的影视作品不仅能带来欢乐,也能带来不错的票房促进影视企业的发展。据统计,2018年我国电影票房高达417亿美元,电影行业比以往任何时候都更受欢迎,每年的内地影市,都有五六百部影片上映。虽然影片的票房不能代表一切,但是票房收入则是衡量一部商业片是否成功的最重要的指标,没有之一。了解电影票房的影响因素,有利于企业提前做好预判,有效抵御风险,因此对于电影票房的预测显得格外重要。80年代,美国的BarryLitman提出了票房收入预测模型,该模型能分析预测不同种类电影的票房价值,对之后美国电影投资界产生了颠覆性的影响。2012年我国企业也研究推出第一套票房预测系统,推动了我国影视产业的进一步发展。本文利用线性回归及xgboost算法,建立电影票房预测模型,取得了良好的实验结果。
本文研究意义如下:
(1)本文根据理论证明了相关电影票房预测模型的可用,证明了基于机器学习的预测模型的可行性,以及基于电影市场各种复杂因素进行预测的效果。
(2)为以后制作一款电影票房预测系统提供制作算法,制作理念和制作核心,为以后开发一个完整的电影票房预测系统做基础。
(3)鼓励电影从业者打造出符合大众审美的具有良好社会影响力的影视文化作品,提高国内影视产业水平。
1 机器学习算法建模
■1.1 机器学习
机器学习可以使计算机模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的算法。机器学习能够让计算机实现数据驱动的决策,是人工智能的核心。利用机器学习,可以迅速的训练出预测模型,应用到实际场景中。在电影票房的预测中,我们能在一定的数据集中挖掘出影响一部电影票房的潜在影响因素,发现并总结出电影各种特征的内在联系,从而适用于现实世界的真实场景进行票房预测,并对行业发展起到一定的指导作用。本文讨论的票房预测适用于机器学习中的回归问题,我们将采用相应的回归算法尝试建立模型拟合真实场景。
■1.2 构建电影票房预测模型
回归算法是机器学习中最常用的算法之一,分为线性回归和逻辑回归,在本文的业务场景中,我们需要通过数据分析一部电影的票房走势,即最终预测出一部电影的总票房收入,这是典型的回归模型。我们需要通过数据特征,诸如一部电影的多种信息来探索影响票房的因素,从而建模进行票房预测。在回归问题中,实际上是我们在建立数学方程对数据进行拟合的一个过程,我们利用机器学习通过大量数据进行学习的特点,不断让计算机通过建立好的回归模型不断优化和调节模型参数,从而达到预测值越来越接近真实值的目的。通过不断的迭代更新,最终我们可以利用算法模型得到一个能够近似反映真实世界规律的模型,这也就是本文中我们的目标。
■1.3 模型评估
我们已经知道票房预测是一个典型的回归问题,我们可以尝试一些基本的回归问题模型来对数据进行建模。相关的模型有很多,并且对每个模型,当尝试不同的参数,所表达出来的效果也是千差万别。这时候,我们要考虑的不仅仅是要构建模型,而且还需要对我们建立好的模型进行准确的评估,因为一个预测效果和真实情况差距很大的模型,或者是不稳定的模型都是远远不够甚至是包含风险的。
在机器学习算法的评估中,我们利用损失函数来评估建立好的模型。损失函数可以衡量模型预测的好坏,用来表现预测与实际数据的差距程度。通常损失函数最小,对应模型参数最优。比如在线性回归中,实际值和预测值肯定会有误差,那么我们找到一个函数表达这个误差就是损失函数。比如在本研究中,根据机器学习算法进行的电影票房预测难免与实际票房存在差距。机器所给出的票房是预测值,而电影实际在市场中所取得的票房就是实际值。通过模型和损失函数来进行模型构建的流程图如图1所示。
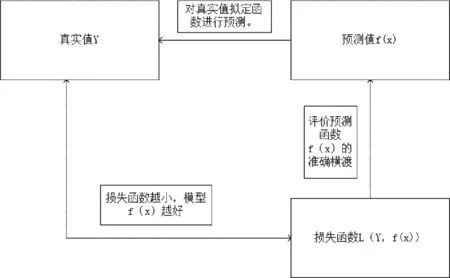
图1 模型构建
■1.4 模型优化
上文已经提到,我们完成模型的初步构建之后将会寻求一个用于评估模型是否接近真实物理模型的函数表达式,即损失函数。我们希望在模型训练的过程中最小化这个损失,一旦我们可以找到一个全局的最小损失,也将意味着模型达到了一个比较好的效果。
机器学习模型训练中由于涉及到大量的高维度数据,数学模型十分复杂,我们很难直接求得损失函数的这个最小值,因此一般我们采用多次迭代不断接近的方式去逼近这个最优解。这种方式即为梯度下降算法,也称为最速下降法。它在机器学习中应用非常广泛,主要通过不断迭代找到最小值,或者逼近最小偏差。
梯度下降算法如同下山,每走一步需要进行计算当前位置的梯度,沿着梯度负方向,进一步向下走。所以通过不断的迭代计算,就可以找到令损失函数最小化的参数,确定最优模型,用梯度下降算法循环更新模型参数,就可以找到一组最优参数,使损失函数得到一个接近最优解的结果,通过这组比较好的参数,我们可以构建一个接近真实的模型。
2 实验过程
■2.1 数据集介绍
本实验数据集来源于电影数据库TMDB,在这个数据集中包括7398部电影和从电影数据库(TMDB)获得的各种元数据。数据特征包括演员阵容、摄制组、剧情关键词、预算、海报、上映日期、语言、制片公司和国家等相关信息。
■2.2 数据预处理及探索性分析
我们首先对数据集进行预处理,预处理是机器学习建模的关键步骤,我们需要在预处理过程中将拿到的数据进行一定的清洗和筛选,并转换为我们的算法模型能够识别的数据类型。针对缺失值的数据,我们采用均值填充,即取其所在列中的其他数据的平均值来代替,而对离散型数据则采用众数填充。
在进行简单的处理之后,我们对数据的几个主要特征进行了探索,通过可视化工具我们观察了特征之间的相关性,以及我们的预测标签revenue(票房收入)与特征之间的关系。
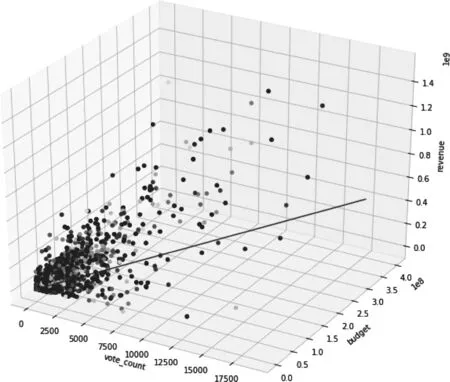
图2 预算,网站投票数与票房收入分布图
我们通过类似的方式对数据特征进行了一些探索,发现预算,投票数,电影主题,演员等几类特征和票房收入是正相关的,同时我们也筛选出了一些没有显著正相关的特征进行舍弃,如电影ID,语言等影响比较小或者比较不具备规律性的特征。通过图3的特征相关性我们认为特征之间没有显著的关联性,故认为不存在特征相似性过大的冗余特征
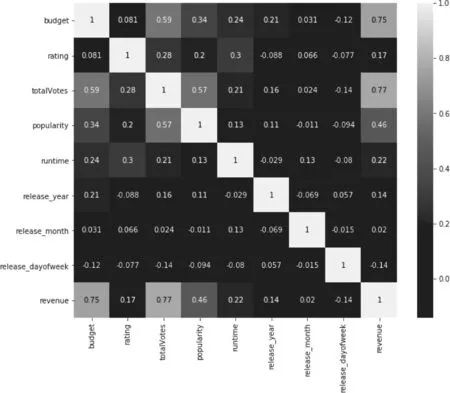
图3 特征之间的相关性
■2.3 构建算法模型及实验结果
数据的预处理及数据分析之后,我们接下来可以对数据进行机器学习算法建模,本实验数据集相对较小(训练集4398,测试集3000),我们先后尝试简单的回归预测模型线性回归,以及各种时下比较流行的集成算法如xgboost,lightGBM,模型的训练结束之后我们采用均方误差对预测结果进行了测试,结果如下:
LightGBM MSE: 1.8184;xgboost MSE:1.8320;linear model MSE:1.8819。
集成算法模型相对较为复杂,在大多数时候具有较好的效果,线性回归模型相对来说较为简单,并且从实验结果来看效果虽然略微弱于集成算法,但也具备了良好实验效果,因此具体的模型选择还需要结合业务场景。
3 结论与展望
本论文基于机器学习算法建立了对实际场景下的电影票房预测模型,在构建模型的过程中通过对TMDB数据集进行了详细的分析和处理,并建立回归模型进行了预测并得到了较好的效果。我们的模型尚可发掘更多的信息,比如我们可以在模型建立完成之后进一步查看分析特征的重要程度,这也能够指导我们在实际场景中对票房收入有更完善的理解。我们也可进一步调整模型并适用于更大规模和复杂的数据集上,得到更为全面的预测功能,使算法起到更多的作用。
