目标检测算法及其在无人驾驶领域应用研究
2021-06-16张舒瑞
张舒瑞
(江苏省新海高级中学,江苏连云港,222000)
0 引言
无人驾驶作为当今人工智能领域的头号研究目标,其广阔的应用前景使其受到世界各国的强烈关注。人们对于无人驾驶的遐想早已在19世纪20年代便初现端倪,那时因为还不存在人工智能的概念,人们将无人驾驶的定义仅仅局限于用无线电对其进行操控。直到半个世纪过后,智能驾驶逻辑算法的问世方才突破此领域中的瓶颈,从而对实现无人驾驶迈出关键性的一步。无人驾驶最受争议的部分就是安全问题,而安全问题大部分基于对路况和突发情况的判断,这时让汽车拥有独立的“思想”就尤为重要,其中目标检测算法更为关键,只有拥有了成熟的目标检测算法才可以让无人驾驶这一技术达到更安全的保障[1]。而深度学习技术则推动了目标检测算法的不断进步,使无人驾驶技术在商用领域取得了重大进展和突破。
1 目标检测技术
目标检测属于计算机视觉中的一个子问题。目标检测技术主要目的是找出图像中感兴趣的物体,包含物体的定位和分类两大任务,即同时确定物体的类别和物体的位置。因此目标检测任务可分为两个子任务:目标分类和目标定位。目标分类任务负责判断输入图像或所选择图像区域中是否有感兴趣类别的物体出现,输出一系列带分数的标签表明感兴趣类别的物体出现在输入图像或所选择图像区域中的可能性[2]。目标定位任务负责确定输入图像或所选择图像区域中感兴趣类别的物体的位置和范围,输出物体的包围框、或物体中心、或物体的闭合边界等,通常使用方形包围盒,即Bounding Box用来表示物体的位置信息。目标检测示意图如图1所示。

图1 目标检测示意图
■1.1 目标分类任务
图像分类主要采用统计机器学习中的有监督学习方法,通过主动的喂给计算机关于某些特定标签的数据,并建立模型、策略、算法的统计机器学习三要素[3],实现对物体的识别过程。经典的二分类方法主要使用Logistic Regression进行图像分类,其算法流程如下:
首先需要将图像数据进行预处理,图像在计算机中以三原色的方式存储,通过数据的拼接将单一图片由[p_x,p_y,3]转变为[p_x*p_y*3,1]的一维向量。同时为每一个训练数据指定其标签,即物品的分类结果。
其次,在机器学习领域中,逻辑斯蒂回归(Logistic Regression)可以用来实现分类操作,它可以看做一个没有隐藏层的简单神经网络。通过建立线性部分WTX+b,其中W为各节点的权重、b为偏置,并对线性部分的计算结果添加非线性的激活函数Sigmoid,从而实现对数据的更高维度的拟合,比如二次项等。最终建立的预测模型为[4]:
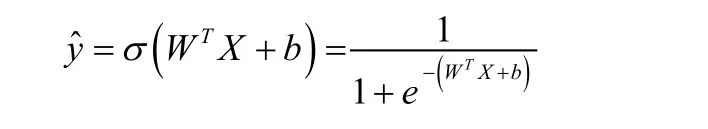
随后,在建立了模型的基础上,指定模型拟合评价的策略即损失函数,该部分用来衡量参数W和b对模型拟合的效果。
最后,制定优化损失函数的算法,较为常用的方法是梯度下降法。通过不断更新参数,从而实现模型的最优化,最终得到参数W和b。
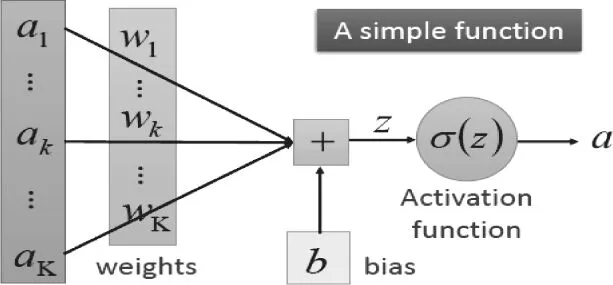
图2 逻辑回归算法示意
图3所示的猫分类就是典型的分类算法,通过将图像进行预处理和向量化,输入到模型中,最后模型的输出结果就是图片为猫的置信度。
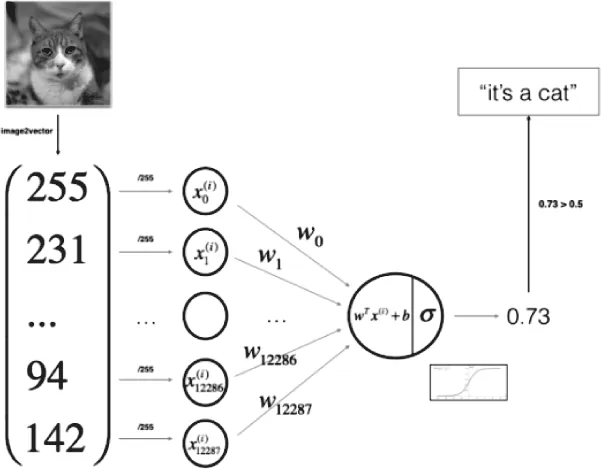
图3 图片分类示意图
■1.2 目标定位任务
目标定位即准确的输出目标所在的位置,二维的物体可以使用输出目标的所在区域的(x,y)方框来实现。目标定位任务所要预测的结果是一个连续的点,因此可将其看作一个典型的回归任务。
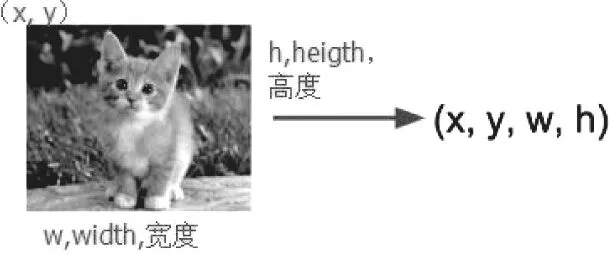
图4 目标定位坐标
将其看做回归问题,我们需要预测出(x,y,w,h)四个参数的值,从而得出方框的位置。
基于传统的机器学习算法进行分类和回归问题时,当图片输入维度较大时,会导致参数数量的剧增,尤其是传统算法普遍使用全连接的方法,只能使用较浅的层次进行学习。在此基础上,逐渐发展而来的卷积神经网络、反向传播等算法降低了参数量和参数计算的复杂度,从而实现了更深层次的模型,从而可以模拟更复杂的模型,实现更高的精度。
2 深度学习与卷积神经网络
■2.1 深度学习的概念
深度学习是机器学习的子集,主要使用人工神经网络来妥善解决计算机网络视觉效果、自然语言处理、自动语音辨识等等关键问题。
深度学习器由若干处理层组成,每层包含至少一个处理单元,每层输出为数据的一种表征,且表征层次随处理层次增加而提高。深度的定义是相对的。针对某具体场景和学习任务,若学习器的处理单元总数和层数分别为M和N,学习器所保留的信息量或任务性能超过任意层数小于N且单元总数为M的学习器,则该类学习装置为严格的或是狭义的深度学习装置,其对应的设计、训练以及使用方式集合为严格的或是狭义的深度学习。
■2.2 深度学习和卷积神经网络
卷积神经网络(CNN)是一类包括卷积运算且有着深度内部结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络有着表征学习能力,通过叠加深层次的网络,能够拟合较为复杂的模型。
深度学习的概念起源于人工神经网络,本质上是指一类对具有深层结构的神经网络进行有效训练的方法。神经网络是一种由许多非线性计算单元(或称神经元、节点)组成的分层系统,通常网络的深度就是其中不包括输入层的层数。
卷积神经网络用于通过将原始图像通过层转换为类分数来识别图像。CNN的灵感来自视觉皮层。每当我们看到某些东西时,一系列神经元被激活,每一层都会检测到一组特征,如线条,边缘。高层次的层将检测更复杂的特征,以便识别我们所看到的内容。
深度学习CNN模型进行训练和测试,每个输入图像将通过一系列带有卷积核,Pooling,全连接层(FC)的卷积层并通过Softmax函数对目标的概率值的对象进行分类。
卷积神经网络分为多层结构:
(1)输入层(即训练数据):输入图层或输入体积是具有以下尺寸的图像:[宽x高x深]。它是像素值的矩阵。
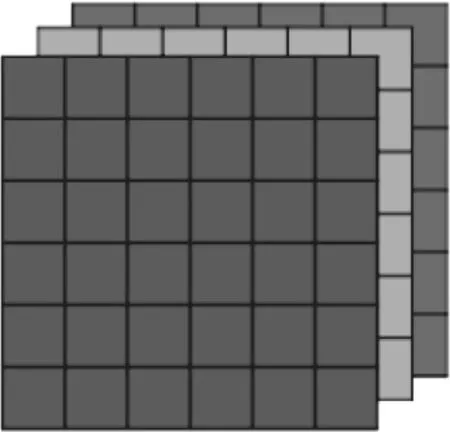
图5 RGB矩阵
(2)卷积层:卷积是从输入图像中提取特征的第一层,Conv层的目标是提取输入数据的特征。卷积通过使用小方块输入数据学习图像特征来保持像素之间的关系。

图6 卷积
(3)Stride:Stride是输入矩阵上的像素移位数。 当步幅为1时,我们将滤波器移动到1个像素。 当步幅为2时,我们一次将滤镜移动到2个像素,以此类推。
(4)Padding(填充):有时卷积的滑动幅度不一定适合输入图像。我们有两种选择:用零填充图片(零填充)以使其适合;删除滤镜不适合的图像部分。

图7 步幅
(5)激活函数(ReLu):ReLU代表整流线性单元,用于非线性操作。输出是ƒ(x)=max(0,x)ReLU的目的是在我们的卷积操作中引入非线性。 因为,现实世界的真实模型往往是复杂的非线性模型。
还可以使用其他非线性函数,例如tanh或sigmoid代替ReLU。大多数数据科学家使用ReLU,因为ReLU的性能明显比其他两个更好。
(6)池化层:池化层部分将减少图像太大时的参数数量。空间池化也称为子采样或下采样,它降低了每个图片映射的维度,但保留了重要信息。空间池化可以是不同类型的:最大池化;平均池化;总和池化。
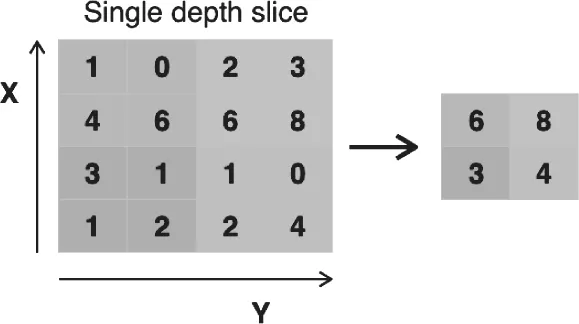
图8 空间池化
(7)全连接层:我们称之为FC层,我们将矩阵展平为矢量并将其馈入神经网络的全连接层。
在图9中,特征映射矩阵将被转换为矢量(x1,x2,x3,...)。通过全连接层,我们将这些功能组合在一起以创建模型。最后我们通过一个激活功能,如softmax或sigmoid,将输出分类为猫,狗,汽车,卡车等。
图9 全连接
图10就是通过卷积神经网络进行图像分类的过程。
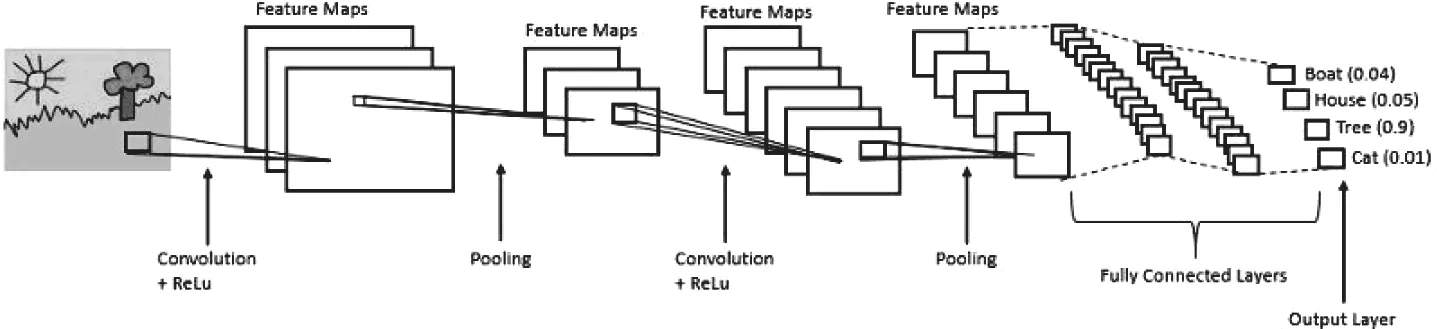
图10 图片分类
上述神经网络的尾部展开,也就说CNN前面保持不变,对CNN的结尾处作出改进:加了两个头:“分类头”和“回归头”,这样就能实现一个主干网络进行多目标学习,即classification + regression模式。
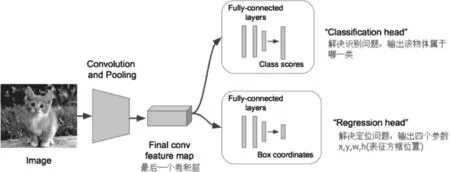
图11 目标分类 + 位置检测
3 数据准备与模型训练
本论文采用PASCAL VOC 数据集,共使用20类目标分类,包含person、car、bicycle、bus等关键目标,样例数据如图12所示。

图12 voc数据样例
标签文件采用xml格式的标注文件,数据标注样例如图13所示。

图13 voc数据标注样例
本文主要采用YoloV3算法,YOLOv3算法的主体结构是一个庞大的卷积神经网络[5],YOLOv3原理图如图14所示。YOLOv3网络的输入层接收416×416的输入图像,网络中有代码体现出来的网络层次共计252层(统计包括用于构建res_block块的add层)。从第0层到75层被统称为darknet-53的部分共含有53层卷积层以及23层残差层。这一部分网络结构不是对darknet-19的简单加深,而是引入了残差网络的跳层连接思想[6],从76到105层是YOLOv3的特征交互和输出层,这一部分舍弃了全连接层转而通过连续的1×1和3×3卷积核实现局部特征交互,作用类似于全连接层,但全连接层实现的是全部像素的全局特征交互。

图14 YOLOv3原理图
神经网络训练部分程序如图15所示。

图15 模型训练部分程序
神经网络训练完成后,在测试集上对算法的性能进行测试,并最终对网络实时视频检测性能进行测试。采取的思路是先捕获实时视频流,从中依次截取出每一帧图像,再调用训练好的YOLOv3网络的单张图像检测的函数对每帧图像检测目标。单张图像检测部分程序如图16所示。

图16 图片检测验证代码截图
4 应用领域及展望
随着图像分类精度在某些领域达到了超越人类的水平,其应用价值也得到了广泛的认可从而应用在诸多领域。无人驾驶汽车在行驶过程中需要对周围的物体进行精确的识别,从而区分哪些是障碍物、哪些是行人,同时需要对行车指示牌等进行精确的划分,从而为驾驶决策提供支持。可以预见,高精度的图像分类技术将广泛应用在无人驾驶领域中。总之,通过将深度学习算法运用于无人驾驶中的目标检测算法,将会大大提升目标检测精度及进一步加速无人驾驶技术的成熟。并结合其他传感技术,增强无人驾驶汽车的感知能力,这也就大大增加了无人驾驶汽车的安全性能,只有这样才能够推动无人驾驶技术的尽快落地运行。
本文通过对目标检测算法的阐述,并运用传统机器学习算法和深度学习方法进行训练和验证,对目标检测算法进行了原理和实际验证。在训练过程中,存在着数据归一化、过拟合等问题,后续将对参数初始化、正则化等有助于提高训练速度、防止过拟合的问题展开研究,从而实现更好的对图像数据进行分类。
