基于机器学习的雷达电子侦察中的应用探析
2021-06-03徐福富刘欣怡高希光
徐福富,刘欣怡,高希光
(中国电子信息产业集团桂林长海发展有限责任公司 广西 桂林 541001)
1 引言
随着技术的不断发展,以人工智能技术基础的认知技术也迎来了新一轮的发展[1-2],在现代信息战场的电子战领域中,电子侦察是军事情报侦察的重要手段之一,可以说任何在战场上采取的大多数对抗及进攻模式都需要以电子侦察为基础,而且电子侦察装备并不辐射电磁能量,可灵活搭载于各种海陆空平台中,需要反应迅速、提供情报及时等特点。电子侦察对特定区域或特定辐射源目标的信号进行预先的精确参数测定、收集和记录,为己方有针对地发展和使用电子对抗技术、制定军事作战计划提供依据。强调的是快速反应能力以及实时的分析和处理能力,将人工智能技术应用于电子侦察能够提高侦察设备的反应速度与提供更准确的情报[3-4]。
传统的电子侦察是将侦察所得的信号进行分析,并将所得的结果存储于数据库中,如果之后遇到相同或者相似的威胁,仍需要进行比对,之后再采取相应的措施,这大大耗费了时间,很难进行有效的对抗,此外,传统的电子侦察没有进行有效整合,其数据库所包含的信息难以有效描述复杂多变环境下复杂多变的信号。本文通过采用机器学习的方法对所侦察得到的雷达信号进行处理,并将所得的分析结果进行图形建模,并能够通过数据量对模型进行完善,从而能够快速识别出辐射源的威胁情况,并建立与之对应的干扰策略,若后面有相同或者相似的威胁,可以根据先验模型直接识别出辐射源信息,对其进行快速干扰,而不必重新分析,从而节省时间与资源[5-6]。而对于新型和未知威胁信号,则可以利用其信号特征来完善所建模型,从而优化模型,相对于传统的“条目状”比对更具优势。
此外,电子侦察的作战对象如雷达、通信等电子信息设备开始逐步走向认知,智能化方向发展,使得相关设备具有自主学习,推理,决断能力,传统的电子侦察设备获得对方的信息难度加大,因此,采用将人工智能技术应用于电子侦察中,对未知信号进行检测,提取相应特征,优化所使用的智能识别设备模型,提高侦察设备的识别能力。
2 侦察处理流程
电子侦察主要对接收信号进行提取其相应信号特征,从而利用其特征信息对设备进行识别。其识别流程如图1所示。

图1 侦察识别流程
电子侦察主要对设备进行识别,从图1中可以看到,识别设备主要包括信号特征提取、模型建立与优化、模型识别等三个部分,在电子侦察中,对信号所提取的特征可以传给数据库进行积累,进行训练模型,也可以为干扰提供数据支撑。从图1可以看出,模型判决是侦察识别流程的关键,其主要是利用所建立的模型对信号进行快速识别,从而识别出设备,当无法匹配时,将所得到的未知信号特征存入数据库进行积累,对模型进行优化训练,从而使模型对在下一次对这种未知信号进行识别,为后续的干扰提供参考。
本文采用机器学习中的决策树方法进行建立模型,利用信号所提取的特征作为样本,进行建模,所建立的模型会随着数据库数据量的增加和充实,不断优化,相对于传统的比对匹配方法,更简洁,速度更快,随着模型的不断完善,其对设备的识别率也在不断提高,识别出设备的威胁等级,能为后续的干扰提供重要的信息。
3 建立决策模型的方法
决策树是一种常见的机器学习方法,一般情况一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;叶结点对应于决策结果,其他每个结点则对应于一个属性测试;每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集。从根结点到每一个叶结点的路径对应了一个判定测试序列。决策树的目的是为了产生一棵泛化能力强,即处理未示例能力强的决策树,其基本流程遵循简单而且直观的“分而治之”策略,是一种进行分类与回归的方法;本文利用决策树进行建模训练,学习时,利用训练数据,根据损失函数最小化原则建立决策树模型;训练时,对新的数据,利用决策树模型进行分类。
决策树学习主要包含3个步骤:特征选择、决策树的生成、决策树的修剪。本文采用的是CART算法,CART模型决策树的生成就是递归地构建二叉决策树的过程,对回归树用平方误差最小化准则,对分类树用基尼指数最小化准则,进行特征选择,生成二叉树。CART生成算法如下:
输入:训练数据集D
输出:决策树模型
根据训练数据集,从根节点开始,递归的对每个节点进行以下操作,构建二叉决策树。
(1)设结点的训练数据集为D,计算现有特征对该数据集的基尼指数。此时,对每一个特征A,对其可能取的每个值a,根据样本点对A=a时的测试为“是”或“否”将D分割成D1和D2两部分,计算A=a时的基尼指数。
(2)在所有可能的特征A以及它们所有可能的切分点a中,选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点,依最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
(3)对两个子结点递归地调用(1)、(2),直至满足停止条件。
(4)生成CART决策树。
算法停止计算的条件是结点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值,或者没有更多特征。CART剪枝算法由两部分组成:首先从生成算法产生的决策树T0底端开始不断剪枝,直到T0的根节点,形成一个子树序列{T0, T1,…,Tn};然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树,完成建模。
下面以10个样本数据为例子进行解释说明,用基尼指数来计算其节点。

表1 样本数据例子
从表1中可以看出,样本数据10个例子,型号有2种,“A”有6种,“B”为4种,对于信号类型和调制方式等特征参数,对其进行赋值量化,根据根节点信息熵的计算公式,计算信息熵为:

接下来,计算特征集合中每个特征的信息增益(即基尼指数),首先计算每个特征的基尼值,从表中可以看出,信号类型只有雷达,其基尼值为:
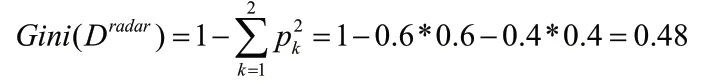
信号类型的基尼指数为:

调制方式的基尼值为:


信号类型的基尼指数为:
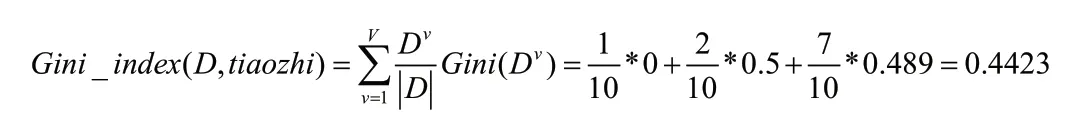
同理,下面对频率,带宽,脉宽,脉冲重复周期等特征参数求基尼指数,找出最小的基尼指数,即为根节点,并在最小基尼指数的特征上找出切分点,将训练数据分成两组,重复上面的情况,求解下一节点,依次即可建立决策树的模型。
对于类似频率等连续值的特征需要进行离散化处理,以频率为例,在表中10个样本中,频率的值为10个,分 别 是(8255,9004,9752,10504,11254,12005,8151,8903,9655,10402)直接对频率进行排序,排序后 的 结 果 为(8151,8255,8903,9004,9655,9752,10402,10504,11254,12005),然后取前后两个频率点的中间值做为分支点,分支点为(8203,8579,8953.5,9329.5,9703.5,10077,10453,10879,11629.5)同 理计算其基尼指数即可。
4 仿真与建模
下面利用数据进行仿真实验,选用4种设备的参数,型号为“A”、“B”、“C”、“D”四种型号的设备的训练样本,利用不同数据量进行建模,并对测试数据进行判决。
四种设备时,分别选取总样本数据120,600,3000,15000例,平均每种型号设备的训练样本分别为30,150,750,3750例,并且设备之间的特征参数具有重叠的区间。对模型进行建模,所建模型变化见图2。
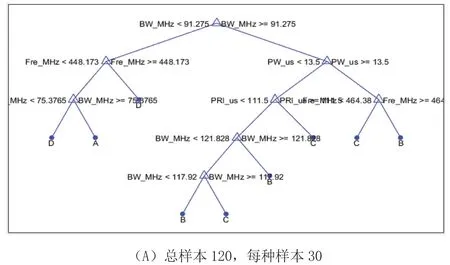

图2 四种型号建模情况
从图2可以看出,训练数据的增加,都会增加模型的复杂度,也使模型的构建不断完善,下面运用所建模型的四个模型,对测试数据进行测试,测试数据分别选择每种型号80,400,2000,10000个样本,做蒙特卡洛仿真测试100次,其测试结果见图3。

图3 模型测试识别情况
从图3中可看出,模型(D)的识别率是最好的,相对于其他模型,其识别率也比较稳定,从而可以看出,模型越完善,其识别率更好,图2可以看到,训练数据的增加,使模型更加优化。结合图2和图3,可以看到,随着数据库的完善,其对数据模型进行优化,从而使识别率更好,对后面的情报分析与智能干扰提供重要支撑作用。
5 结论
通过利用机器学习中的决策树对雷达辐射设备进行识别的仿真验证与分析,可以看到,相对于传统的匹配比对判断,决策树具有快速,不断优化,具象化的优势;判决模型也会随着数据的完善而不断优化,使得识别准确性提高,从树形图来看,对于某一种设备识别规则,有直观的认识。随着新型智能体制雷达的发展,传统电子侦察难度在不断提高,电子侦察技术需要往一体化,可优化,可重构方向发展,因此,将机器学习技术应用于电子侦察中能起到重要支撑作用。
