基于FAR-HK-ELM的燃煤电站锅炉NOx排放预测
2021-05-21付文华任密蜂续欣莹阎高伟
付文华,谢 珺,任密蜂,续欣莹,阎高伟
(太原理工大学 a.电气与动力工程学院,b.信息与计算机学院,太原 030024)
火力发电作为一种重要的发电方式,是保障充足稳定电力供应的基础,但其以燃煤机组为主,燃煤产生的NOx在一定条件下可破坏臭氧层、形成酸雨等,直接或间接地危害生态环境。近年来,我国不断加强电力外送通道建设,使得国电外送规模持续创新高,这无疑加剧了对我国生态环境的影响。在国家节能减排政策的严格要求下,火力发电厂纷纷通过锅炉燃烧优化技术降低 NOx排放,在一定程度上提高火电机组的环保性。
锅炉燃烧系统的优化依赖于锅炉燃烧预测模型的建立,一般采用回归建模法。由于NOx排放量和其运行操控参数间存在很强的非线性关系,传统建模方法难以准确地建立NOx排放预测模型。近年来,随着统计学、机器学习、神经网络等不断发展,国内外学者围绕燃煤电站锅炉NOx排放量预测模型的构建进行了大量的研究。其中BP神经网络、SVM、ELM等被广泛用于电站锅炉NOx排放建模预测中[1-4]。HU et al[5]将660 MW燃煤机组作为研究对象,采用BP神经网络建立了NOx排放预测模型。2006年,GUO et al[6]以一台300 MW旋流对燃锅炉为研究对象,建立了基于SVM的锅炉燃烧过程中的NOx排放预测模型。李素芬等[7]基于粒子群优化算法和LS-SVM建立电站锅炉NOx排放预测模型。然而BP容易出现过拟合现象,SVM算法因需要二次规划使得样本数量受限而仅适用于小样本建模。为了解决以上问题,TAN et al[8]基于从某电厂700 MW燃煤电站锅炉采集的约5 d实际运行样本数据,建立了基于ELM的NOx模型,提高了模型的泛化性。陈琪[9]提出基于GMM的数据重采样及SKPCA-ELM算法,建立锅炉NOx排放模型,其中基于GMM的数据重采样通过选择代表性样本有效地解决了样本数据分布不均衡问题,缩短了模型训练时间。然而以上算法仍存在局限性,一方面将SKPCA用于特征数据降维,没有考虑特征属性与决策属性之间的关系,使模型不能达到很好的预测精度;另一方面使用ELM建模,模型的稳定性和泛化性不理想。K-ELM的提出,有效地解决了ELM存在的缺陷。基于ELM的燃煤锅炉NOx排放预测模型的稳定性和泛化性与核函数密切相关,然而单一的核函数难以准确描述NOx排放与被操控运行变量之间的非线性关系,导致该预测模型的学习能力与泛化能力不足。
为了有效地平衡建模时间与模型预测准确度,本文提出了一种基于FAR和HK-ELM的燃煤电站锅炉NOx排放预测方法。该方法以锅炉NOx排放量为预测目标,首先利用FAR算法筛选出影响NOx排放量的主要影响因素,生成新样本数据集;然后基于生成的新数据集采用HK-ELM建立NOx排放预测模型。实验结果表明,本文所提方法能够有效地建立NOx排放预测模型,同时保证模型提高预测精度、缩短建模时间。
1 快速属性约简相关知识
燃煤电站锅炉的燃烧过程是一个复杂的物理化学过程。在其运行过程中常常受到外部干扰及内部设备振动等诸多随机因素的影响,使得特征属性间存在冗余性和耦合性,这必然会影响NOx排放预测模型的建模效率及模型准确性。因此通过科学筛选影响NOx排放的核心影响属性因子来提高建模效率和准确性显得尤其重要。
粗糙集理论于1982年由波兰数学家Z.Pawlak教授提出,由此众多学者开始研究粗糙集,使其广泛发展。目前粗糙集理论已经被应用于特征选择、模式识别和预测[10-12]等方面,其中属性约简[13]就是粗糙集研究的一个核心内容,主要在不改变原始样本数据的基础上,通过删除冗余的属性特征来保持信息系统的预测能力。而邻域粗糙集模型的引入解决了经典粗糙集只能处理名义型数据的问题,用于处理数值型数据,在此基础上,属性约简算法得到了进一步发展。
给定邻域大小,有性质1:如果条件属性子集B1、B2满足B1⊆B2⊆C,且样本集X⊆U,则对于论域U中的任一个样本x,如果x∈POSB1(D),则x∈POSB2(D).
知识约简定义:设P和Q是U中两个等价关系组,若Q∈P,Q是独立的,且ind(P)=ind(Q),则称Q为P的一个约简,记为red(P).
一般采用前向贪心搜索策略来进行属性约简,即依次将新属性添加到已选条件属性集,将粗糙集属性依赖度作为属性重要度的度量指标,重新依次判断每一个样本是否在正域内。2008年,胡清华等[14]根据性质1,表明新样本的增加不会使原来属于正域的样本变为边界样本,基于Pawlak属性约简,提出一种邻域粗糙集前向搜索属性约简快速算法(forward attribute reduction based on neighborhood rough sets and fast search,FARNEMF),该算法所采取的加速思想仅会提高属性约简速度,并不会对属性约简结果产生影响。因此本文将其用于燃煤电站锅炉NOx预测建模时大规模样本数据的属性特征选择中。
2 混合核极限学习机(HK-ELM)
ELM是黄广斌等[15]提出的一种快速单隐层前馈神经网络(SLFNs).因结构简单、速度较快、参数较少、泛化能力强等被广泛应用于工业、农业等多个领域的分类及回归问题中。2012年,通过对SVM、LS-SVM与ELM的算法机理进行对比,将核函数应用于ELM,提出了K-ELM[16].K-ELM不仅继承了ELM的诸多优点,同时解决了ELM模型输出容易因随机复制而出现随机扰动的问题,使其泛化性、稳定性进一步增强。
ELM的SLFNs模型可描述为:
f(x)=h(x)β=Hβ.
(1)
式中:x为样本输入,f(x)为神经网络的输出,H表示隐含层特征映射矩阵,β表示输出权重矩阵。
根据文献[16],K-ELM对应的输出为:
(2)
式中:C为正则化因子,T为样本对应的输出。
K-ELM的核矩阵定义如下所示:
ΩELM=HHT∶ΩELMi,j=h(xi)h(xj)=K(xi,xj) .
(3)
核函数有很多种类型,如线性核函数、小波核函数等。一般情况下,样本输入往往不同且有较大差异,使得难以选择有效的核类型和核参数。文献[17]选择多项式核函数(Poly)和高斯径向基核函数(RBF)线性相加构造一全新的混合核函数模型,使其兼具局部核函数学习能力较强和全局核函数泛化性较好的优点,进而具有更好的学习能力和泛化性能。混合核函数表达式为:
ΩELM=HHT∶ΩELMi,j=h(xi)h(xj)=Kmix(xi,xj) .
(4)
在这种情况下,混合核极限学习机(hybrid kernel ELM,HK-ELM)模型的输出为:
(5)
式中:ΩELM为N×N对称矩阵,Kmix(xi,xj)为混合核函数,据Mercer原理和线性加权原则,得之比混合核函数Kmix也是Mercer函数:
Kmix(x,xj)=rKpoly(x,xi)+(1-r)Krbf(x,xi),
(0≤r≤1) .
(6)
其中,参数r为平衡因子,用于调节局部核函数和全局核函数的作用大小,范围为[0,1];Kpoly(x,xi)为多项式核函数,Krbf(x,xi)为高斯径向基核函数,即
(7)
Kpoly(x,y)=(xTy+1)d.
(8)
在使用HK-ELM进行建模时,正则化因子C与核函数参数(γ,d,r)的设定直接影响HK-ELM模型的性能。
3 基于FAR-HK-ELM的燃煤电站锅炉NOx排放预测方法
本文结合FAR与HK-ELM算法,提出了一种基于FAR-HK-ELM的燃煤电站锅炉NOx排放预测方法。基于FAR-HK-ELM的燃煤电站锅炉NOx预测模型,其基本方法是:
1) 首先,通过拉以达准则、线性插值法、归一化处理等对采取的样本数据进行数据预处理。
2) 其次,采用FAR算法对预处理后的样本数据集进行属性约简,筛选影响NOx排放量的主要影响属性变量,构建新的属性子集,以作为NOx排放预测模型的输入变量。
3) 最后,通过带约束的权重线性递减粒子群寻优算法结合10-fold交叉验证方法,优化HK-ELM的正则化因子及核参数,以实际数据和预测数据的均方根误差最小化作为目标,基于属性约简后所构建的新样本集,建立基于HK-ELM的NOx排放量预测模型。
基于FAR-HK-ELM的燃煤电站锅炉NOx预测模型构建过程如图1所示。
4 实验分析及结果
4.1 实验数据准备及评价指标
本文采用某电厂600 MW燃煤电站锅炉的历史运行数据对模型进行测试,采样周期为1 s.在锅炉实际运行中,锅炉负荷、一次风、二次风等是影响其NOx排放的主要因素,本文充分考虑从燃煤电站锅炉采集的实际测点数据,选取共57维运行操控参数作为模型的输入量,以锅炉NOx排放量作为模型的输出量,具体如表1所示。
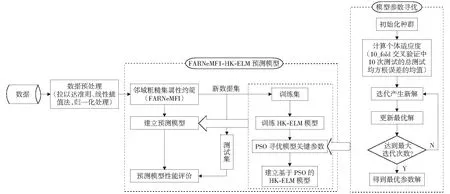
图1 基于FAR-HK-ELM的燃煤电站锅炉NOx预测模型构建过程Fig.1 NOx prediction model construction process of coal-fired utility boiler based on FAR-HK-ELM
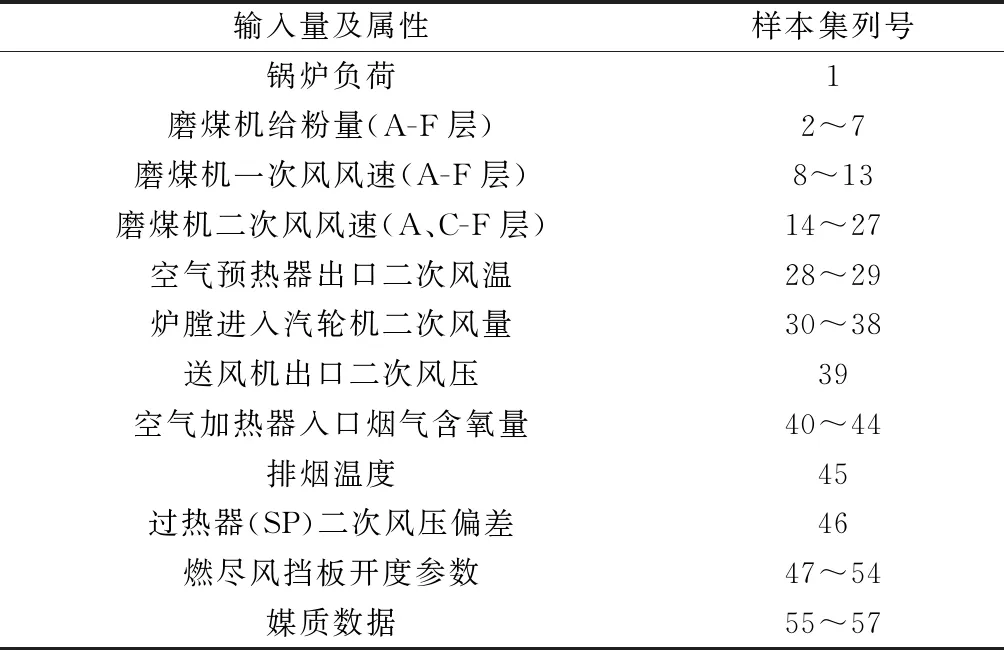
表1 NOx排放预测模型输入量Table 1 Input of NOx emission prediction model
为保证燃煤锅炉NOx排放量预测模型的性能,在模型训练之前需要对样本数据进行数据预处理,依次采取拉以达准则、线性插值法剔除数据离群点、补齐空值、替换异常值。然后随机选取10%样本数据,共1 200组样本数据归一化处理到[-1,1],使其量纲达到同一数量级。
为了准确地评价本文所建立的基于FAR-HK-ELM的燃煤电站锅炉NOx预测模型的性能,本文采用粗糙集属性重要度作为度量指标衡量属性特征的贡献,采用拟合优度R2、均方根误差(root mean squared errors,RMSE)、平均相对误差(mean relative error,EMRE)作为标准来衡量模型的学习能力和预测能力。
1) 粗糙集属性重要度计算公式如下:
(9)
式中:|·|表示集合内元素的个数;U为论域;B,D分别为条件属性子集、决策属性;POSB(D)为条件属性子集B所确定的正域。
2) 衡量模型的学习能力和预测能力的计算公式如下:
(10)
(11)
(12)

4.2 FAR-HK-ELM建模
在研究锅炉NOx排放量预测模型时,为了保证模型预测精度同时减少建模时间,首先使用FAR算法将全部样本数据用于属性特征选择,选定邻域半径计算参数、重要度下限的控制参数分别为6.1,0.000 1,以属性重要度为评价指标,即条件属性对决策属性的贡献,约简后的样本输入属性为{1,2,3,6,8,9,12,13,14,15,19,25,28,34,35,39,43,46,53},共计19个,各特征属性的重要度如图2所示。从燃煤电站锅炉实际运行情况来进行分析,锅炉NOx排放量主要取决于锅炉负荷大小、一次风速、二次风速等影响,与排烟温度等的关系并不是很密切,其与约简结果基本一致。

图2 属性重要度Fig.2 Attribute importance
将属性约简后新的特征属性构成的新样本集用于HK-ELM建模,随机选取其中80%的样本数据作为训练样本,剩余20%作为测试样本。HK-ELM模型的学习能力和泛化能力取决于HK-ELM的正则化因子C和混合核函数参数(γ,d,r).通过带约束的权重线性递减粒子群寻优算法寻找HK-ELM模型的最优参数,以10-fold交叉验证中10次测试的总测试均方根误差的均值作为粒子群算法的适应度值(见公式(13)),以达到避免模型训练中出现过拟合的目标。
(13)
为了平衡模型预测准确性与建模时间,多次调整迭代次数及核函数范围,则带约束的权重线性递减粒子群寻优算法及HK-ELM模型具体参数设置见表2.根据表2参数设置进行寻优,此时得到HK-ELM模型中的参数组(C,γ,d,r)为(189.043, 3.434 65, 3,0.436 496),建立NOx排放的HK-ELM模型,并对测试样本进行预测,NOx排放量模型预测值与实际值的对比如图3所示,可以看到FAR-HK-ELM模型的预测值与实际值有很好的一致性。模型对训练样本EMRE、R2、RMSE分别为1.90×10-11,1,1.33×10-11,测试样本的EMRE、R2、RMSE分别为0.001 4,0.980 6,0.043 2,结果表明FAR-HK-ELM模型不仅学习能力很强,且具有较高的预测精度和拟合泛化能力,可以对燃煤锅炉NOx排放量进行准确预测。

表2 粒群寻优算法及HK-ELM模型具体参数设置Table 2 Particle swarm optimization algorithm and specific parameter setting of HK-ELM model
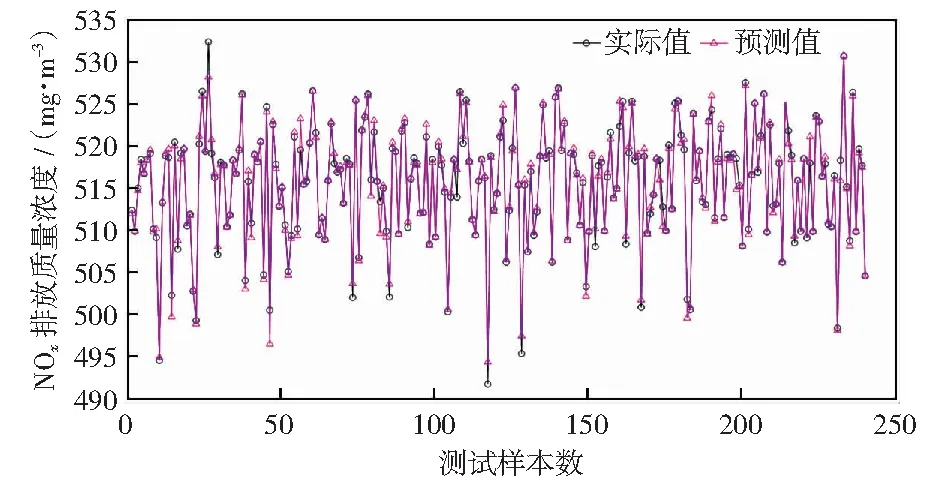
图3 NOx排放量模型预测值与实际值的对比Fig.3 Comparison between the prediction values of NOx emission model and the real value
4.3 多种算法性能比较分析
为了综合评定FAR-HK-ELM预测燃煤锅炉NOx排放量时时间复杂度、预测精度等方面的性能,将本文方法与其他算法进行比较,分别为BP神经网络、SVM、ELM、多项式核极限学习机(PK-ELM)、高斯径向基核极限学习机(GK-ELM)、混合核极限学习机(HK-ELM),以R2,RMSE,EMRE作为评定指标进行实验对比分析,均取20次实验均值作为最后结果如表3.
实验均随机选取其80%作为训练样本,剩余20%作为测试样本。实验中所有对比算法的核函数参数、惩罚系数、初始权值等参数都通过粒子群优化算法和10-fold交叉验证进行参数寻优。
由表3可知,针对电站锅炉NOx排放量建立预测模型,BP神经网络模型学习能力和预测性能较差;ELM模型学习能力很强,但模型泛化性较差;SVM模型相较于BP、ELM模型,模型性能有了一定提升,但时间复杂度较高。引入核函数后,从训练集的EMRE,R2,RMSE三个指标来看,PK-ELM模型的学习能力优于GK-ELM模型;从测试集的EMRE,R2,RMSE来看,GK-ELM模型的泛化性能优于PK-ELM模型。综合PK-ELM和GK-ELM两个模型优点所建立的HK-ELM模型,与PK-ELM和GK-ELM模型相比,其学习能力和泛化性能都显著提高,但混合核的引入增加了HK-ELM模型计算复杂度,使建模时间加长。为此通过属性约减减少样本属性维度,在保证提高模型学习能力和泛化性能的同时降低模型计算复杂度。
综合分析可知,FAR-HK-ELM模型学习能力和泛化性能均优于其他模型,实现了模型预测准确性与建模时间之间的平衡,能够较为精准地对NOx排放量进行预测,在锅炉NOx预测中是一种可行且有效的方法。
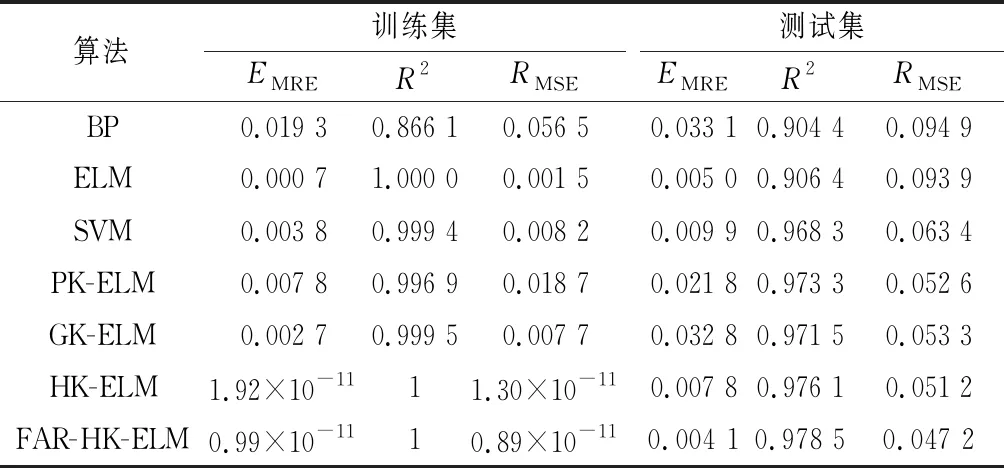
表3 不同算法性能指标比较Table 3 Comparison of performance indexes of different algorithms
5 总结
本文基于燃煤电站锅炉实际运行情况,提出了一种基于FAR-HK-ELM的锅炉NOx排放预测方法,采用领域粗糙集属性约简算法筛选建模样本核心特征属性,删除属性间的冗余信息,然后综合考虑多项式核函数和高斯径向基核函数的优点构建基于HK-ELM的NOx排放预测模型,提高了预测模型的准确性与泛化性。通过与BP,SVM,ELM,PK-ELM,GK-ELM和HK-ELM的对比实验,进一步验证了本文所提出的FAR-HK-ELM建模方法,能够很好地用于实际电站锅炉NOx排放建模中,该模型不仅具有很好的学习能力,并且可以较为准确地预测NOx排放量,具有良好的拟合泛化性能力。
