基于RBF神经网络优化的无人驾驶车辆增量线性模型预测轨迹跟踪控制研究
2021-04-12肖宗鑫李晓杰肖宗烁张志文董小瑞
肖宗鑫,李晓杰,肖宗烁,张志文,董小瑞
(1.中北大学 能源动力工程学院,太原 030051;2.东北林业大学 经济管理学院,哈尔滨 150040)
由于在提升车辆主动安全性、改善交通效率以及降低能耗等方面的巨大潜能,无人驾驶技术已经成为当前车辆行业的研究热点[1-2],而轨迹跟踪是无人驾驶车辆的研究重点之一[3]。
模型预测控制(MPC)[4-5]具有很高的控制精度,且便于添加约束条件,在过程控制中被广泛应用[6]。Borrelli等[7]、Falcone等[8-9]设 计了MPC控制器,实现了车辆前轮的自动转向,较好地完成了轨迹跟踪任务;ATTIA等[10]基于非线性模型预测控制设计了侧向控制器,计算负担大,不适于高速工况;对于线性模型预测控制,李培新等[11]只考虑了运动学因素的影响,王秋等[12]仅建立了2自由度的车辆动力学预测模型,孙银健[13]研究了车辆在低附着路面的轨迹跟踪问题,将最高安全速度限定在12 m/s内;线性时变模型预测控制实时计算量相对较小,但当状态偏离线性化工作点时可能会产生较大的预测误差从而导致系统不稳定[14];邹凯等[15]考虑轮胎力进入非线性区[16]的情况,设计了增量线性MPC(ILTV-MPC)提高了计算的实时性。
HU Jianjun等[17]提出利用模糊控制对ILTVMPC补偿控制,但模糊控制器不具备自适应能力,无法满足复杂的行驶工况,且缺乏理论上的稳定性证明;引入包络线约束的ILTV-MPC优化方法[18-19]和变步长的模型离散化方法[20-22]仅集中于对转向的优化;BROWN M等[23]提出了N-MPC并进行了实车验证,但可能陷入局部最优。
传统MPC对系统不确定性的处理能力有限,当系统模型描述不准确或者存在外部扰动时,往往难以实现既定的控制目标[24]。神经网络具有并行运算能力强、学习和容错能力强等优点,研究基于神经网络的自适应轨迹跟踪算法具有重要的实际意义,其中RBF(径向基函数)网络是连续函数的最佳逼近[25]。同时,为了满足不确定性系统的控制需求,鲁棒模型预测控制是未来的发展方向[26]。
本研究在ILTV-MPC基础上,利用RBF的局部逼近特性,设计了RBF自适应补偿控制器对MPC模型的不精确部分进行逼近;但由于在逼近过程中仍会存在误差,进而将RBF神经网络与鲁棒控制相结合,设计了RBF鲁棒优化控制器,将逼近误差作为外部干扰予以抑制;应用Lyapunov函数推导了隐含层网络权值训练规则,并证明了2个控制系统的稳定性。最后,搭建Simulink/Carsim联合仿真平台对3种轨迹跟踪控制系统进行对比仿真验证。
1 ILTV-MPC轨迹跟踪控制器
1.1 预测模型
采用3自由度车辆-轮胎模型进行动力学分析,为简化计算,在较为准确地描述车辆动力学过程的基础上,进行如下假设:①假设无人驾驶车辆只做前轮转向;② 忽略车辆垂向运动、纵向和横向空气动力学的影响;③忽略悬架运动及其对耦合关系的影响;④用非线性单轨模型描述车辆运动,不考虑载荷左右转移。
利用Pacejka提出的魔术公式(magic formula,MF)对每个控制周期进行线性化处理,计算出适用范围更大的轮胎纵向力、侧向力和回正力矩等输出变量,得到轮胎时变模型,进而结合车辆3自由度单轨模型[4]。
得到基于上述假设的3自由度车辆非线性动力学模型:

式中:a、b分别为质心到前、后轴的距离;m为车辆整备质量;Iz为车辆绕z轴的转动惯量;δf为前轮转角;φ为质心横摆角;Cl为轮胎纵向侧偏刚度;Cc为轮胎横向侧偏刚度。
由车身坐标系和惯性坐标系之间的转换关系,可得:


将车辆的动力学模型近似线性化,在任意点(ξt,ut)处进行泰勒展开并只保留1阶项,忽略高阶项,则可得到:


对式(4)进行近似离散化处理,同时结合系统的状态量和状态量参考值之间的偏差,表示为:

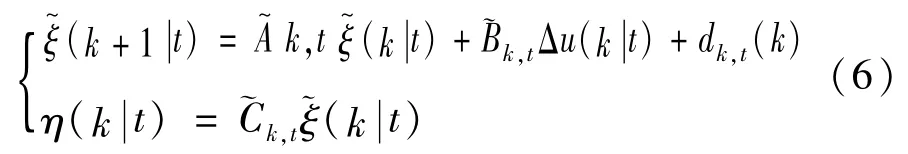
式中各状态系数矩阵、控制系数矩阵和输出系数矩阵为:
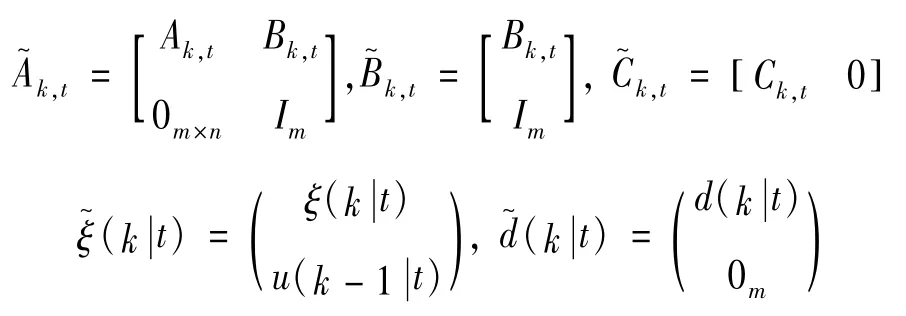
设定系统的预测时域为Np,控制时域为Nc,从而实现模型预测控制算法的预测功能。
1.2 优化求解
车辆动力学模型虽已经过一定程度的简化,但仍有较大的计算复杂度,而且系统的模型是实时变化的,可能会出现规定时间内无法得到最优解的情况,所以引入松弛因子,使每次优化都能得到可行解。由文献[4]优化目标函数设为以下形式:

式中:ρ表示权重系数;ε表示松弛因子;Q表示输出偏差的权值矩阵,R表示控制增量的权重系数。
为保证车辆能够平稳地跟踪期望轨迹,设计了前轮转角及其增量约束、质心侧偏角约束、加速度约束和轮胎侧偏角约束,其中为防止求解失败,在加速度约束中引入松弛因子,设为软约束。
将ILTV-MPC每一步带约束的目标函数优化求解问题转换为如下二次规划问题以方便计算机求解:
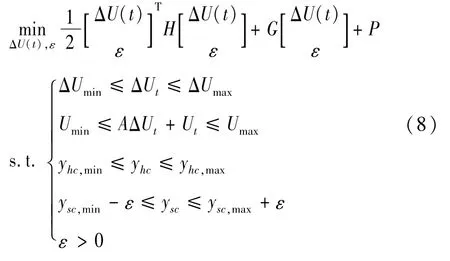
式中:yhc为硬约束输出;ysc为软约束输出;yhc,min和yhc,max为硬约束输出极限值;ysc,min和ysc,max为软约束输出极限值。
1.3 反馈校正
在每个控制周期内完成对式(8)的求解后,可以得到控制时域内一系列控制输入增量:

将得到的控制序列中的第1个元素作为实际输入增量,可得到未来时刻的输入量:

Δut作用于系统的当前时刻,系统执行这一控制量直到下一时刻,在新的时刻,系统根据状态信息重新预测下一段时域的输出,再次求解优化目标函数,可得到一个新的控制增量序列,再将其作用于系统的下下个时刻,循环往复,形成最优滚动控制[4]。
如此,完成了增量线性时变模型预测轨迹跟踪控制器的建立。
2 RBF神经网络自适应补偿控制器
由于在建立ILTV-MPC预测模型过程中进行了诸多假设和简化,这些假设和简化的存在必然会导致控制器模型存在一定的不精确部分f,进而导致轨迹跟踪误差的增大,因此,设计了RBF自适应补偿控制器对不精确部分进行逼近。
2.1 ILTV-MPC控制器建模不精确部分
将建立的车辆动力学模型式(1)以状态方程的形式表示:
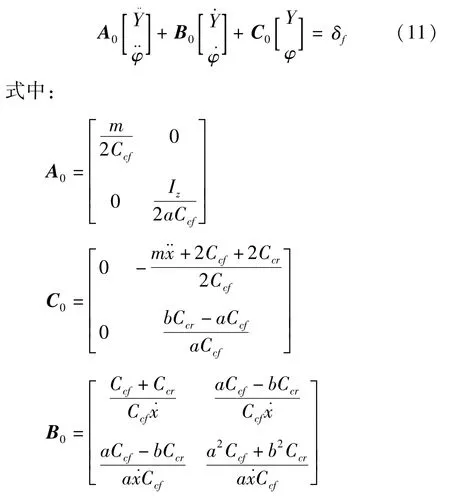
令q=[Y ]φT,则可将式(11)写为

式中:A0、B0和C0在实车模型中为未知参数,但在本节设计的车辆动力学模型中若暂时忽略建模过程中的假设和简化,可认为其是已知量,即式(12)所示的车辆动力学模型是精确的,则控制律暂可设计为:


将式(13)代入式(12),可得:

此时可认为系统是闭环稳定的,但由于真实的车辆模型很难得到,故假设实际的车辆模型为:

将式(13)代入实际的车辆模型式(15),可得到

式中:ΔA=A-A0、ΔB=B-B0、ΔC=C-C0。结合式(14)(16)可取ILTV-MPC控制器中由于建模过程的假设和简化而产生的不精确部分为f=
因此,控制律(13)可修正为
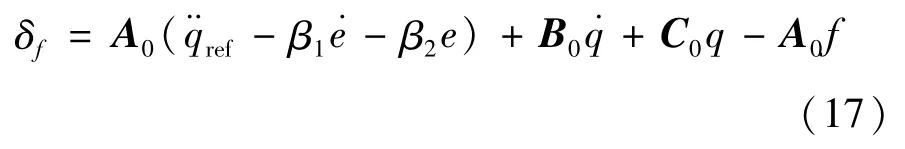
2.2 RBF自适应补偿
本文建立的RBF神经网络结构为2-5-1,输入向量为横向位置和横摆角误差e及其误差变化率隐含层以高斯函数作为核函数;输出向量为模型的不精确部分。
隐含层高斯基函数按下式计算:
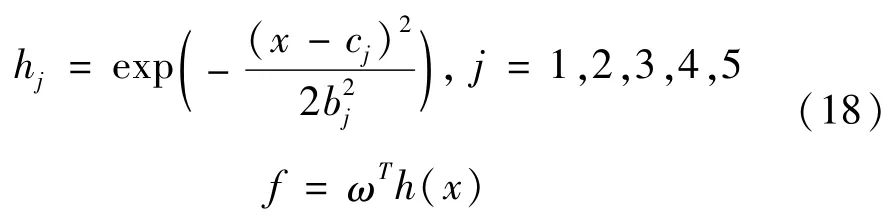
式中:x为网络的输入;cj为第j个节点的中心值向量;bj为第j个节点的高斯基函数基宽值;h(x)=[h1h2h3h4h5]T为高斯基函数的输出;ω为神经网络权值。
假设x=(e˙e)T,可得到在控制律(17)下的误差状态方程:

由文献[23]可知,RBF神经网络的建模误差η是有界的,假设其上界为 ηsup,即 ηsup=
因此,RBF神经网络输出的估计值为:
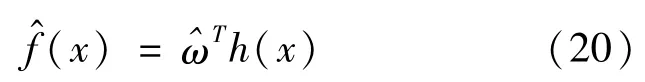
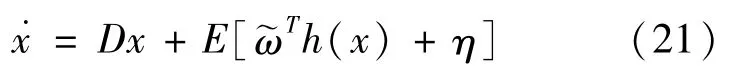
由此可得到车辆动力学模型前轮转角:

2.3 Lyapunov稳定性分析
针对本节控制系统,采用Lyapunov稳定性分析的方法对双移线期望轨迹的数据进行网络权值训练。
定义Lyapunov函数为:
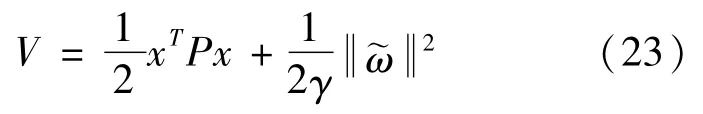
式中:γ为待定系数,本节γ取20;P为对称正定矩阵,且满足Lyapunov方程:


对V求导并代入式(21)(25)得到:


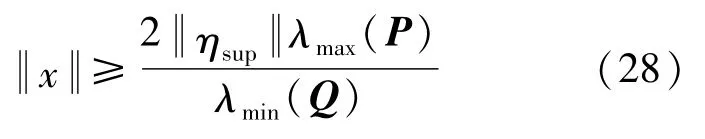
由式(28)可知,Q的特征值越大,P的特征值越小;建模误差上界ηsup越小时,x的收敛半径越小,所建立的控制器补偿能力越好,轨迹跟踪效果越好。因此,本节设计的控制系统是稳定的。
由此,完成了RBF神经网络对ILTV-MPC轨迹跟踪控制器不精确部分的补偿控制。
3 RBF神经网络鲁棒控制器
由于RBF神经网络逼近过程中仍会存在一定的逼近误差,因此将RBF神经网络和鲁棒控制相结合,利用鲁棒抑制外界干扰的特性,将逼近误差作为外部干扰,设计了RBF鲁棒优化控制器,对其予以抑制。
仍采取所设计的2-5-1结构的RBF神经网络,但定义输入向量为:

式中,α为待定系数,经多次仿真实验测试,α值取0.3。
3.1 RBF神经网络鲁棒控制
当考虑模型不精确部分和外部干扰时,式(12)可修正为:

式中:f为模型的不精确部分;d为外部干扰。
通过采用前馈项进行非线性补偿,取控制律为:

ε表示RBF神经网络的逼近误差,结合式(30)和(31),可得到系统的状态误差方程:

结合式(32),式(29)可转化为:

控制器u控制律设计为:

系统的L2增益可体现控制系统对外界干扰的抑制能力,控制系统的干扰抑制问题可归结为设计控制器使L2增益尽可能小或者小于给定值γ,γ>0[27]。
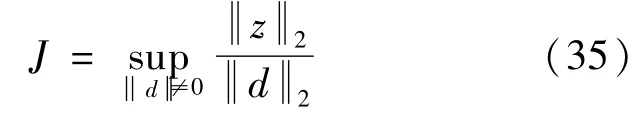
对于上述闭环控制系统,设定评价信号z=pe=px1,若其中的参数p满足:

式中:ε0为给定常数,则该闭环系统的L2增益小于给定值 γ,γ值取0.1。
3.2 Lyapunov稳定性分析
针对建立的闭环控制系统,定义Lyapunov函数为:

对V求导,同时代入式(34)(35),可得:

取自适应律为:

结合式(38)(39)可知

根据L的定义,可知

由HJI(Hamilton Jacobi Issacs)不等式定理可知,此时控制系统L2增益小于γ,性能指标满足J≤γ,即本节设计的闭环控制系统是稳定的。
综上所述,完成了RBF鲁棒优化控制器对RBF补偿控制的改善,即完成了对ILTV-MPC轨迹跟踪控制器的再次优化。
4 仿真与分析
针对所设计的RBF补偿-ILTV-MPC和RBF鲁棒-ILTV-MPC两种控制系统,无人驾驶车辆的输入前轮转角δf由ILTV-MPC轨迹跟踪控制器输出δf0和RBF补偿控制器或者RBF鲁棒控制器输出δf1共同组成。

系统控制框图如图1、2所示。

图1 RBF补偿-ILTV-MPC系统控制框图
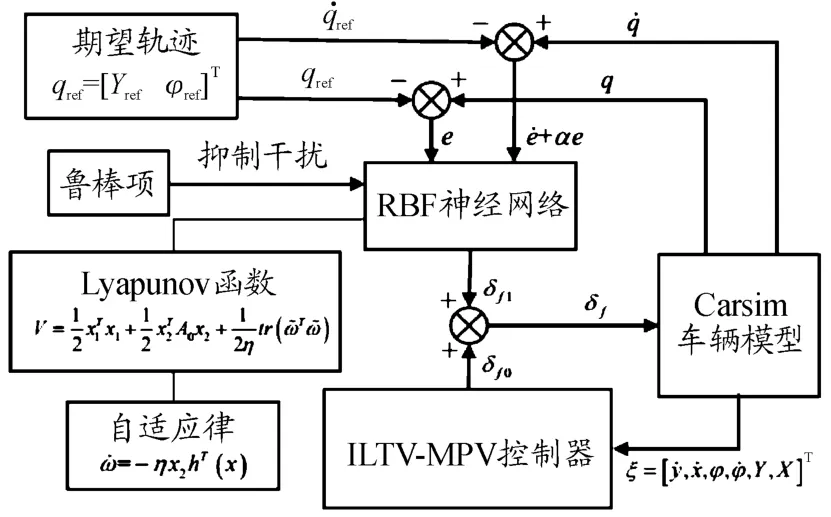
图2 RBF鲁棒-ILTV-MPC系统控制框图
搭建Simulink和Carsim联合仿真平台,其中Carsim测试车型选用E-Class,SUV。设置了不同纵向行驶速度和路面附着系数的3种仿真工况:①v=30 km/h,μ=0.8(工况1);②v=50 km/h,μ=0.8(工况2);③v=50 km/h,μ=0.4(工况3),分别对优化前后3种控制系统进行不同工况下的双移线[9]仿真对比。仿真过程中参数值见表1。

表1 仿真参数设置
控制器的轨迹跟踪精度通过横向位置及横摆角的跟踪误差判定,无人驾驶车辆在3种双移线仿真工况下的横向位置Y随横向位置X跟踪结果及误差e1随时间t变化如图3、4所示。
由图3、4可知:在工况1条件下,ILTV-MPC轨迹跟踪控制器横向位置最大误差为0.125 7 m,经RBF自适应补偿控制后减小至0.077 02 m,约38.73%,均方根误差减小32.35%;经RBF鲁棒优化控制后减小至0.039 68 m,约68.42%,均方根误差减小60.29%;随着速度的提高,误差逐渐增大,在工况2条件下,与传统ILTV-MPC相比,RBF补偿-ILTV-MPC均方根误差减小23.24%,RBF鲁棒-ILTV-MPC均方根误差减小49.01%。

图3 横向位置轨迹跟踪结果
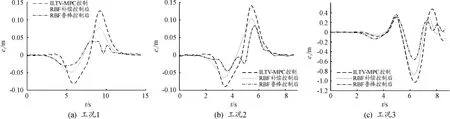
图4 横向位置误差
在良好路面上,3种控制系统均可较好地完成双移线路径的轨迹跟踪。RBF鲁棒控制较RBF补偿控制可进一步提高ILTV-MPC控制器的跟踪精度。
在工况3条件下,仿真前期可较好地完成轨迹跟踪,但后期由于控制量(δf)大幅度增大而出现较大偏差,虽车辆仍处于可控状态,但易发生转向失控等危险工况。与传统ILTV-MPC相比,RBF补偿-ILTV-MPC均方根误差减小20.38%,RBF鲁棒-ILTV-MPC均方根误差减小45.86%。此时经RBF鲁棒控制优化后的控制器在仿真前期精度虽有所下降,但在可接受范围内。
当车辆以较高速度行驶在附着系数小的路面上时,3种控制系统在仿真后期均出现不同程度侧滑;RBF鲁棒控制较RBF补偿控制可进一步减小ILTV-MPC控制器的误差,减轻车辆侧滑程度,在一定程度上提高车辆行驶稳定性,减少危险的发生。
车辆在3种工况下横摆角φ随横向位置X跟踪结果如图5所示。

图5 横摆角轨迹跟踪结果
由图5可知,2种经RBF优化后的ILTV-MPC控制器,对横摆角的跟踪虽然精度有所提高,但仍存在一定时间的延迟。
此外,经多次仿真可知,ILTV-MPC轨迹跟踪控制器最高安全纵向行驶速度为67 km/h,当速度超出最高安全速度时,横向位置出现明显偏差,车辆发生大幅度侧滑;经RBF自适应补偿控制后的控制器虽未有效提高临界纵向行驶速度,但横向位置偏差明显减小,车辆侧滑程度减弱;经RBF鲁棒优化后的控制器最高安全纵向行驶速度可明显提升至90 km/h。
3种控制系统不同纵向行驶速度横向位置跟踪结果如图6所示。

图6 不同纵向速度的横向位置跟踪结果
5 结论
设计了RBF补偿-ILTV-MPC和RBF鲁棒-ILTV-MPC 2种控制系统,与传统ILTV-MPC轨迹跟踪器相比,均可提高轨迹跟踪精度。当以30 km/h速度行驶在良好路面时,与传统ILTV-MPC相比,RBF补偿-ILTV-MPC最大误差减小约38.73%;RBF鲁棒-ILTV-MPC最大误差减小约68.42%。结果表明,经RBF鲁棒控制优化后的ILTV-MPC控制器与经RBF补偿后的控制器相比,可进一步减小轨迹跟踪误差,提高车辆的行驶稳定性。
但本研究仅考虑了3种工况,未能完全体现控制器所有工作环境,且优化后的2种控制系统对于横摆角的跟踪仍存在一定时间的延迟,导致误差的产生;同时经RBF鲁棒优化后的ILTV-MPC控制器临界速度仅提升至90 km/h,对于高速下的无人驾驶车辆无轨迹跟踪效果还需进一步改善。
下一步计划对2种控制系统的实时性进行研究,并于多种工况下进行实验验证。
