布隆过滤器算法误判率的分析与应用
2021-04-12李卓宇夏必胜马乐荣
李卓宇,夏必胜,马乐荣
(延安大学 数学与计算机科学学院,陕西 延安 716000)
1 布隆过滤器算法
1.1 背景和原理
布隆过滤器(Bloom Filter)是在1970年由布隆(Burton Howard Bloom)提出,是一种紧凑型的、比较巧妙的概率型数据结构,它由一个很长的二进制向量(位向量)和一系列随机均匀分布的散列(哈希)函数组成[1]。用多个散列函数,将一个数据映射到位数组结构中,可以用来高效地插入元素和检索判断“某个元素一定不存在或者可能存在于某个集合当中”。此种方式不仅可以提升查询效率,也可以节省大量的内存空间[2]。
当一个元素被加入元素集合时,通过k个散列函数将这个元素映射成一个位数组中的k个点(特征),把它们置为1,检索时这些点如果是1,则被检元素可能存在,如果这些点当中有任何一个0,则被检元素一定不在。
基本思路:①设数据集A={a1,a2,…,an}含n个元素,作为待操作的集合;②Bloom Filter用一个长度为m的位向量V={b1,b2,…,bm}表示集合中的元素,位向量的初始值全为0;③获得k个具有均匀分布特性的散列函数;④对于集合中的每一个元素,首先经过k个散列函数产生k个随机数h1,h2,…,hk,使向量V的相应位置{b1,b2,…,bm}均置为1。集合中其他元素也通过该操作将向量V的若干位置为1;⑤对于待查找的元素,首先将该元素经过前四步操作获得k个随机数h1,h2,…,hk,然后检查向量V的相应位置{b1,b2,…,bm}上的值,若全为1,则该元素可能存在于集合中,若至少有一个0存在,则元素不在该集合中,为新元素。步骤过程如图1、图2、图3所示。

图1 位数组m的初始状态
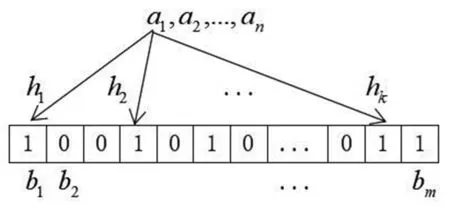
图2 集合A中元素的位置状态
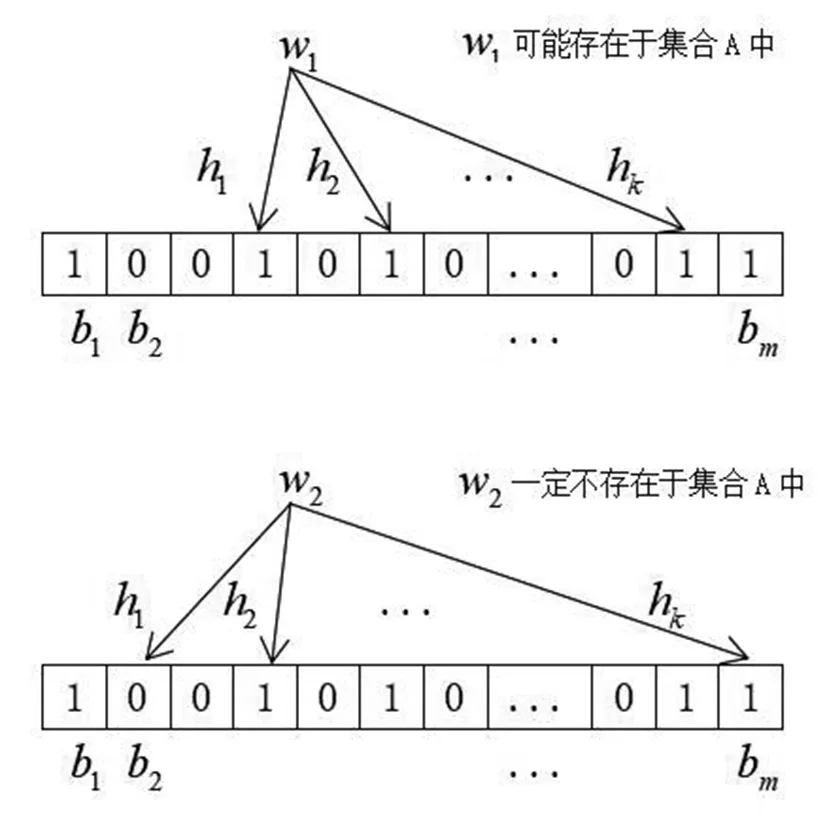
图3 查找状态
1.2 算法优缺点
关于布隆过滤器的优点有以下6个:①在增加元素或查询元素的时候其时间复杂度都为O(k),(k是散列函数的个数,一般都比较小),且该时间复杂度与数据量的大小没有关系;②散列函数相互之间没有关系,在硬件方面实现并行运算很方便[3];③布隆过滤器不需要存储元素本身,所以对某些数据要求严格保密的情况下选择布隆过滤器更好;④在能够承担一定的误判时,布隆过滤器和其他的数据结构对比更具有空间优势;⑤数据量很大时,布隆过滤器可以表示全集,而其他数据结构不能;⑥使用同一组散列函数的布隆过滤器可以进行交、并、差运算。
当然,布隆过滤器也有它的缺点。第一,存在误判(假阳性)[4]。那就是既不能准确判断元素是否存在于该集合当中,也不能获得这个元素,只能判断这个元素存在或者不存在。因为存在误判,所以误判率被提出来,对于固定长度的位数组来说,当存入的元素数量增加,那么误判率就会增加。第二,通常情况下不能从布隆过滤器中删除元素。对于一个已经放入布隆过滤器的元素,通过散列函数将它映射到位数组的k个位置上是1,那么删除的时候就不能直接将这些位置重新置为0,因为同一个位有可能有好几个随机数都标记了它,直接删除可能会影响其他元素的判断。虽然布隆过滤器可以支持删除,但删除的效率不高而且浪费空间[5]。当然现在也有一些支持删除操作的方法,如采用计数方式删除一个元素,但在计算过程中可能就会存在计数回绕问题[6]。
2 布隆过滤器算法的误判率
2.1 最小误判率
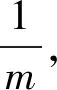
(1)
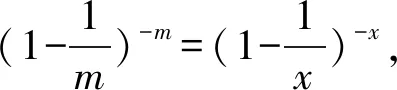
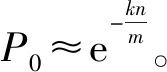
(2)
所以布隆过滤器真实误判率为:
(3)
现在要检测某一元素是否在该集合当中,需要判断这个元素通过散列函数映射以后,对应的位数组上的k个特征位都置为1。但是该方法可能会错误的认为原本不在集合中的元素是在集合中的,所以对于规定的数组长度m和元素个数n,散列函数的个数k是至关重要的,只有求得k的极值,才能知道误判率P最小的时候关于k的取值个数。
因此对(3)式两边取对数,得到:
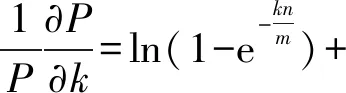
(4)

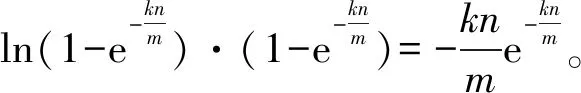
(5)
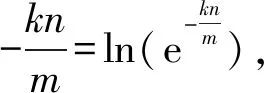
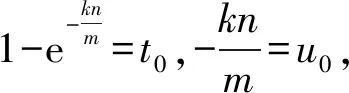
lnt0·t0=lnu0·u0。
设函数f(x)=lnx·x,那么就有
f(t0)=lnt0·t0,f(u0)=lnu0·u0,
即f(t0)=f(u0)。
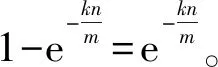
(6)

(7)
所以要使得误判率最小,那么散列函数的个数k的取值就是公式(7)计算所得。由此可知,如果规定位数组m的长度大小小于集合中要输入的元素个数n时,那么误判率P就会增加。
2.2 误判率P与m、n、k的关系
根据布隆过滤器的误判率,总结了以下的关系:
①误判率P与m位数组长度的关系
由公式(3)可知,当元素数量n和散列函数个数k不变,m的长度增加的时候,说明存储空间增大了,误判率P就会减小。
②误判率P与k个哈希函数计算量的关系
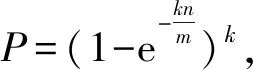

(8)
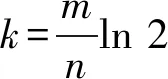
③误判率P与n的关系
令位数组长度m和散列函数的个数k不变,输入元素n的大小取决于实际任务的决策,所以当n减小时,P显然减小。
3 应用
3.1 置信度与置信区间分析
对于置信区间的分析,用一个范围来对某个事情进行估计的方式称为区间估计,在该区间估计中,由样本估计量构造出的总体参数在一定置信水平下得出来的区间就称为置信区间[8]。区间的最小值为置信下限,用a表示,区间的最大值是置信上限,用b表示,所以置信区间就表示为[a,b]。对于置信度的分析,把这个估算的区间的准确度(可信度)称为置信度(也叫置信水平或置信系数)。一般置信度和置信区间是同向也就是具有一样的趋势。当置信度很高时,置信区间也会很大;当置信区间很大时,置信度也会很高。
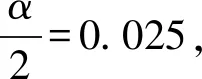

表1 置信度和标准分值的对应表
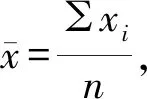
通过上述公式的计算,置信度为90%、95%、99%时误判率的置信区间结果如表2所示。

表2 预估误判率的置信区间结果
3.2 置信度为95%,元素规模n大小为1e10、1e11、1e12时的m,k
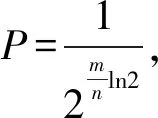
(9)
引入公式(7)和公式(9),相应的位数组长度m和散列函数个数k计算结果(均保留整数)如表3所示。

表3 元素规模n为1e10、1e11、1e12时的m、k
4 结论
(1)布隆过滤器是通过散列函数映射到位数组上的一种数据结构,用来查找判断某个元素是否在当前集合里[10]。散列函数的所有特征点对应的位数组至少存在一个0,那该元素一定不在集合里;如果全部为1,那么该元素在这个集合里。布隆过滤器比其他数据结构具有很多的优势,如时间复杂度小、散列函数相互独立、无需存储元素本身、能高效查询又能节省大量的内存空间、可以表示为全集,可以做基本的并交差运算。但是布隆过滤器也存在误判,会将不属于集合的元素判断为属于,并且一般情况下不能删除元素。
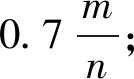
(3)对置信度设置为90%、95%、99%时误判率的置信区间进行了分析,同时计算了置信度为95%,元素的规模为1e10(十亿级)、1e11(百亿级)、1e12(千亿级)时的位数组长度m分别能存储7GB,73GB,726GB的数据容量,其散列函数个数k都为4。
