基于改进变分自编码器的零样本图像分类
2021-03-19谢红薇
曹 真,谢红薇
(太原理工大学 软件学院,太原 030024)
在传统的图像分类任务中,模型的训练过程必须提供所需识别某类事物的图像样本[1]。但是,这种假设在现实问题中有时无法成立,因为在现实世界中存在着大量的事物类别没有相应的图像样本。零样本分类(zero-shot classification,ZSC)也称作零样本学习(zero-shot learning,ZSL),是一种特殊的图像分类方法,可以作为一种解决上述问题的有效途径[2]。零样本学习的思想是利用一些已知类别的先验知识获得识别新类别的能力,即将未知与已知类别通过语义描述信息建立联系,通过有标签的已知类别在视觉和语义空间之间建立映射关系,最后根据已知类别数据和未知类别在视觉和语义上的联系,对未知类别的图像进行分类。近年来,零样本分类问题得到了广泛的关注。零样本分类问题最早由LAMPERT et al[3]提出,同时提出了基于语义属性的零样本学习的DAP和IAP模型。之后的研究中,学者又提出了联合嵌入模型[4],将语义特征和图像特征共同嵌入到同个特征空间来解决零样本分类问题。现有的大多数零样本分类方法都着眼于从各个方面提高语义特征空间在图像特征空间的映射效果。
然而,由于样本的缺失和映射关系存在偏差,通过语义特征映射的零样本学习方法存在很大的偏向性,这样就导致未知类别会被误识别为已知类别,产生领域漂移(Domain Shift)问题[5],从而导致模型泛化能力低。同时在现实问题中,理想化数据集很难找到,数据集往往存在类别样本不平衡的问题[7]。因此,零样本分类问题的另一种思路是利用生成模型生成未知类别的样本,将零样本分类问题转化为数据缺失问题,通过生成样本的方式对数据集进行有监督学习。LONG et al[6]提出了基于已知类样本生成未知类别的方法,构建了一个能够同时保持跨模态数据分布以及局部信息的语义属性到视觉空间的映射函数。该方法与直接语义预测和基于嵌入模型的零样本分类算法进行无监督分类相比,在基于生成模型的零样本分类算法中,语义信息将作为生成模型的引导信息,生成所需的样本。本文在此基础上提出了一种改进的基于最大均值差异分离噪声变分自编码器的零样本分类模型(zero-shot classifycation algorithm via variational auto-encoder with maximum mean discrepancy,MD-VAE),基本思路是利用变分自编码器进行样本生成,在已知样本输入编码器时利用最大均值差异对编码器产生的隐变量进行约束,之后利用样本标签信息控制生成,通过解码器生成目标类别训练样本,利用生成样本在分类模型中进行有效地监督学习,最终对未知类别进行分类。
1 相关知识
1.1 零样本分类
零样本分类是指依据一些可见类别的数据,辅以相关常识信息或先验知识,通过模型实现对不可见类别的数据进行类别预测的问题[2]。与传统的分类任务不同,零样本分类中测试样本Xs所属的类别和训练样本Xt所属的类别是不相交的,而传统的目标分类中测试样本所属的类别包含于训练样本类别的集合。如图1所示训练样本中有“马”与“熊猫”,测试样本中有“斑马”。模型虽然没有见过“斑马”这个未知类别样本,但是训练样本中具有测试样本中的特征,即可以通过对未知类别的样本描述,通过训练样本进行未知类别图像分类。
零样本分类问题的基本思路是利用训练样本和样本对应的辅助信息(例如文本描述或者属性特征等)对模型进行训练,在测试阶段利用在训练过程中得到的信息,以及模型的测试类辅助信息对模型进行补足[3],提高训练后的模型的泛化能力,使得模型的泛化能力足够强大到对未知类别的测试类样本进行分类,从而确定测试样本的类标签。而要把训练后的模型推广到未知类别的测试样本[2],需要训练样本和测试样本都具有辅助信息,并在训练时学习辅助信息的表示模型。测试时利用训练时学习到的辅助信息模型和测试样本的辅助信息,预测测试样本的类标签。
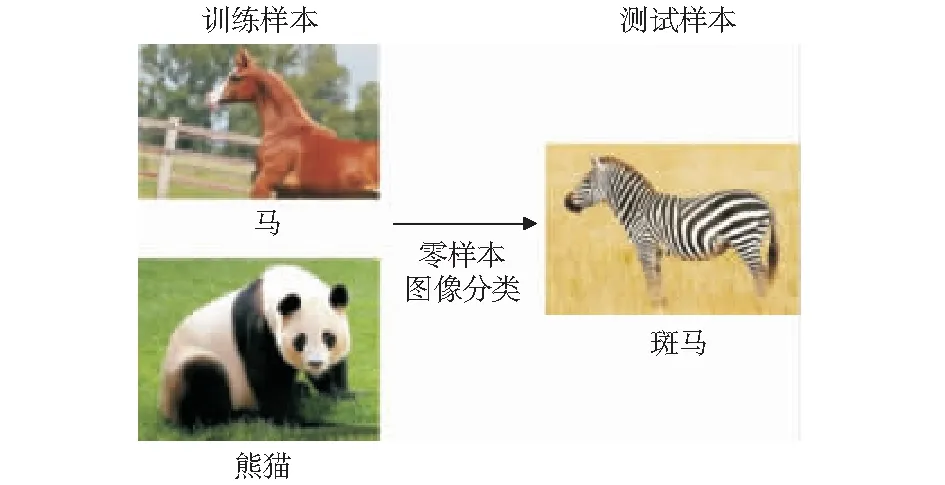
图1 零样本图像分类
1.2 领域漂移问题
SAENK et al[5]从自然语言处理和计算机视觉方面引入领域移位问题。在给定设置的数据上训练分类器,并在不同场景中进行测试,因为训练集与测试集属于不同的域,最终导致性能不佳。该问题的一个规范形式描述如下:
由于零样本分类问题中,训练集和测试集无交集,需通过语义等辅助信息进行域之间的信息传递,现有的零样本分类方法多采用语义特征空间在图像特征空间的映射,或反向映射,或将它们同时映射到一个子空间。假设在源域和目标域中分别存在两种类别:蝴蝶和蜂鸟,它们都具备翅膀这种语义属性,但它们的视觉属性是不完全相同的,例如分类器在蝴蝶类样本上学习到的翅膀属性,当用于蜂鸟类样本时分类结果就会出现偏差,导致模型泛化能力差。
基于语义特征空间向图像特征空间映射的零样本分类模型常面临领域漂移的问题。由于在训练模型使用的数据集中并未包含需要测试的数据类别,当训练样本与测试样本的类别相差较大时,零样本分类模型的效果将受到很大影响。
2 改进的零样本分类算法
零样本图像分类的难点主要是对未知类别无法得到具体的样本,因此本文利用变分自编码器生成未知类别图像,从而将零样本图像分类转化为有监督图像分类。本文对VAE模型编码器部分进行改进,加入类别标签信息控制已知类别噪声,从而优化隐变量生成[8]。
2.1 基于变分自编码器(VAE)的生成模型
变分自编码器(variational auto-encoders,VAE)是一种深度生成模型,是基于变分贝叶斯(variational bayes,VB)推断的生成式网络结构[9]。变分自编码器包含两个概率分布模型:一个用于原始输入数据的变分推断,生成隐变量的变分概率分布推断网络,即编码器;另一个根据生成的隐变量变分概率分布,还原生成原始数据的近似概率分布的生成网络,即解码器。相较于自编码器,变分自编码器的编码器与解码器的输出都是受参数约束变量的概率密度分布,而不是某种特定的编码。
假设原始数据集X,每个数据样本xi都是随机产生相互独立、连续或离散的分布变量,生成数据样本集合为X′,并且假设该过程产生隐变量Z,即有部分变量是不可直接观测的。其中可观测变量X是一个高维空间的随机向量,不可观测变量Z是一个相对低维空间的随机向量,如图2所示该生成模型可以分成如下过程:
1) 隐变量Z后验分布的近似推断过程qφ(z|x),即推断网络编码器。该过程会产生两个向量,一个是均值向量μ,一个是标准差向量σ.
2) 生成变量Xi的条件分布生成过程Pθ(z|x),即生成网络解码器。该过程会从标准差向量中采样加到均值向量上输入到生成网络中。
由于隐变量Z无法直接使用变分推断进行求解,VAE在推断网络中引入一个识别模型qφ(z|x)来代替无法确定的真实后验分布Pθ(z|x),并且假设识别模型qφ(z|x)是一个已知的分布形式,这样识别模型qφ(z|x)就可以作为VAE的推断网络部分,条件分布Pθ(x′|z)作为生成网络部分。使识别模型qφ(z|x)和真实后验分布Pθ(z|x)近似相等,VAE使用KL散度(Kullback-Leibler)[10]来衡量两者之间的相似度,并希望通过优化约束参数θ和φ使KL散度最小化,即:
φ,θ=argminDKL(qφ(z|x)‖Pθ(z|x))=Eqθ(z|x)[lbqφ(z│x)-lbPθ(x,z)]+lbPθ(x) .
(1)
假设记:
L(θ,φ;X)=Eqθ(z|x)[-lbqφ(z|x)+lbPθ(x,z)] .
(2)
由以上两个公式可得:
lbPθ(X)=DKL(qφ(z|x)‖Pθ(z│x))+L(θ,φ;X) .
(3)
由于KL散度DKL≥0恒成立,所以lbPθ(X)≥L(θ,φ;X)恒成立,L(θ,φ;X)被称为集合X对数边际似然lbPθ(X)的变分下界函数。
为了使生成的样本与目标样本相似程度更高,因此需要使qφ(z|x)和Pθ(z|x)近似相等,即KL散度最小化。由式(3)可知,为了使KL散度最小化,推断网络和生成网络的优化目标都是最大化变分下界函数,因此变分自编码器模型的整体优化目标即为最大化变分下界函数L(θ,φ;X).生成模型的训练过程最终目标就是让下界函数得到最大值,即:
L(θ,φ;X)=-DKL(*)+lbPθ(X) .
(4)
由于Pθ(x)可以直接通过神经网络计算,并且qφ(z|x)服从正态分布,因此可以通过随机梯度下降进行优化计算。
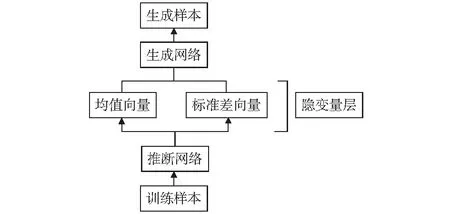
图2 变分自编码器结构图
2.2 最大均值差异
最大均值差异(maximum mean discrepancy,MMD)作为一种损失函数在域适应问题中使用广泛[11],可以定量度量两个不同但相关的分布距离。因此对于使用生成模型解决零样本分类问题中可以定量地对隐变量层进行控制,从而生成所需的未知类别样本。最大均值差异定义如下:
假设分别存在一个满足P分布的源领域XS=[xnt1,…xnt]和一个满足Q分布的目标领域Xt=[xt1,…,xtm],令H表示再生核希尔伯特空间(reproducing kernel Hilbert space,RKHS),φ(*):X→H表示原始特征空间映射到RKHS映射函数,当ns,nt→∞时Xs和Xt在RKHS中的最大均值差异(maximum mean discrepancy,MMD) 可以表示为:
(5)
由上式可以看出最大均值差异的原理是对每一个样本进行投影并求和,利用和的大小表述两个数据的分布差异。当MMD值越小则源域和目标域越相近,因此可以作为正则项来对数据样本内噪声因素进行可计算的优化,同时对样本类别信息进行控制从而对未知类别样本进行分类。
2.3 噪声分离改进模型MD-VAE
为了使条件变分自编码器更好地对已知类别样本进行生成,使生成的未知类别图像精度更高,从而提高零样本图像分类的准确率,本文提出将噪声因素与隐变量信息分离之后加入样本标签信息控制未知类别样本生成,使得模型更加明确地学习某些非变性因素的特征表示。
本文根据2.1节和2.2节设计了基于改进变分自编码器的零样本分类框架。如图3所示为MMD-VAE模型结构,分为生成模型部分和分类模型部分。
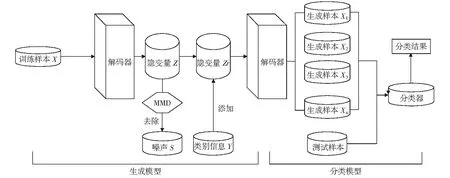
图3 最大均值差异改进变分自编码器结构示意图
对于生成模型部分,利用改进的变分自编码器进行样本生成,主要分为编码器层,2个隐变量层以及解码器层。原始数据集X={xi}中包含了部分噪声因素S={si},在隐变量Z的表示学习过程中,将噪声因素S单独分离出来,以便提高隐变量Z表示学习的准确度,从而提高零样本图像分类的准确率。如果直接根据变分后验分布qφ(z|x)将原始数据映射到隐变量空间,则无法彻底消除隐变量Z与噪声因素S之间的依赖关系,于是提出加入最大均值差异作为正则项,惩罚由噪声S得到的隐变量Z的后验分布qφ(z|x),使得qφ(z|x)尽可能小,则可以起到弱化隐变量Z与噪声因素S之间依赖关系的作用,即:
Dmmd=argminMMD(qφ(z|x‖s)) .
(6)
同时在生成模型模型中,噪声因素S和数据标签Y={yi}可能存在一定的联系,分离了噪声因素S也会对标签信息Y造成一定的影响,本文所提出的解决办法是增加一个隐变量层Z1,在经过噪声因素分离之后再将标签信息Y重新注入Z1,从而使得模型标签信息不受影响。通过添加了标签信息Y可以对生成样本类型进行控制。根据未知类别所属的标签信息可以生产未知类别图像。根据公式(4)和(6)可得:
L(θ,φ;X,Y)=-DKL(qφ(z|x,y)‖Pθ(z│x,y))-Dmmd(qφ(z|x‖s)+lbPθ(X) .
(7)
由以上公式可得最终目标为让L(θ,φ;X,Y)最大化,根据以上公式可得:
argmaxL(θ,φ;X,Y)=-DKL-Dmmd+lbPθ(X) .
(8)
对于分类模型部分,生成未知类别的训练样本,按照传统有监督训练方法进行训练,构造分类器进行未知类别图像的分类,得到未知类别的分类结果。在本文中使用支持向量机(SVM,support vector machine)作为分类模型,值得注意的是,本文提出的零样本分类模型中,分类模型部分可以进行改变。为了改进分类效果,可以使用分类效果更强的模型。
利用MMD作为正则项对样本噪声分离,改进变分自编码器在零样本图像分类实验准确度和非变性特征提取的过程,表现出较好的权衡关系,使生成样本与已有样本更接近,从而提高图像分类的准确性。
由此可得,本文提出的模型算法步骤归纳如下:
1) 使用训练集样本X输入编码器,进行样本特征输入。
2) 在编码器内利用最大均值差异作为正则项,对样本进行噪声分离,得到噪声分离后的隐变量层Z.
3) 在得到的隐变量层Z后新增一个隐变量层Z1,加入样本标签信息Y控制样本生成未知类别样本。
4) 使用生成的未知类别样本训练SVM分类器,进行图像分类。
3 实验分析
3.1 实验配置
本文使用软硬件环境为:Linux,Python3.6,pyTorch0.4.0,NVIDIA 1080ti,RAM16G及i7-4790.
本文使用AWA动物数据集、CUB鸟类数据集以及ImageNet-2数据集[12],数据为开源数据集。其中AWA与CUB数据集为小型数据集,ImageNet-2数据集为大型数据集,因此本文可以在不同维度的数据集上验证模型算法的有效性。
AWA是动物数据集,共有40个已知类,10个未知类,包含30 475个图片样本,其中24 295个已知类的样本,6 180个为未知类的样本。CUB鸟类数据库包含11 788个图片样本,150个已知类和50个未知类,其中8 855个已知类样本,2 933个未知类的测试样本。CUB和AWA两个数据集各自提供语义特征。
ImageNet-2数据集包含254 000个图片样本,其中1 000个已知类,360个未知类,数据集没有特征注释。为了进行对照实验,使用1 000维由Word2vec训练的语义特征。数据集描述如表1所示。

表1 实验数据集详细信息
3.2 评价指标与可视化
对于AWA,CUB数据集,本文使用类的平均分类准确率来和其他零样本分类模型进行比较。平均类别的分类准确率是评价所使用数据集较好的指标,削弱了实验的随机性。定义如下:
(9)
其中,Y为总体类别个数,NT为当前类别样本数量,NC为当前类别分类正确样本数量。
对于ImageNet-2大型数据集,由于类别数量较多,因此本文的评价标准是测量top-k准确率[13],即模型的最高k类预测中出现真标签的平均值,本文根据对照的零样本分类模型统一设置k值为5,即最高5类分类准确率。
零样本图像分类模型的性能还可以进行可视化研究,本文使用基于t分布的随机领域嵌入法(T-distributed stochastic neighbor embedding,T-SNE)[14]来进行每个类的图像特征可视化。T-SNE基于随机邻域嵌入法(stochastic neighbor embedding,SNE) 进行改进, 是一种非线性的降维方法,适合将高维数据降至2或3维,从而进行特征的可视化,即为每个类生成相应的图像特征向量。本文以AWA数据集为例将测试图像的原始特征分布、经改进条件变分自编码器生成样本的特征分布进行了比较。
3.3 参数设置
实验由于生成模型部分采用自适应生成模型,因此只需要将隐藏层Z和Z1的维度λ作为超参数。实验中生成模型部分采用交叉验证的方式找到隐变量层维度超参数λ.采用十折交叉验证,将数据集分为10份,每次选取9份作为训练集,余下为测试集。由图4可知,将超参数隐变量层维度设置为150时,可得到模型最佳分类效果。
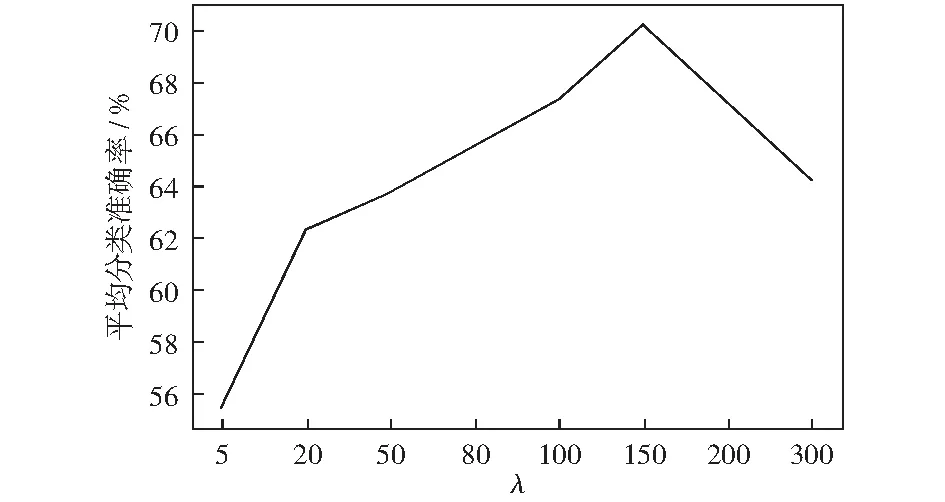
图4 平均分类准确率随超参数λ变化曲线
对于利用生成样本进行训练的分类模型,本文采用支持向量机作为分类模型,需要确定模型的惩罚系数C作为参数,需要兼顾模型的分类准确性与模型的训练耗时。如图5所示可知,在惩罚系数为100时,在分类准确性较高的情况下,训练耗时较低。因此选择惩罚系数为100,这时模型分类效果最好。
同时为了保证模型的鲁棒性,本文还验证了模型在小样本数据集AWA和CUB上的生成能力,经过验证在生成大约400个生成样本数据后模型性能在AWA和CUB数据集上达到饱和。
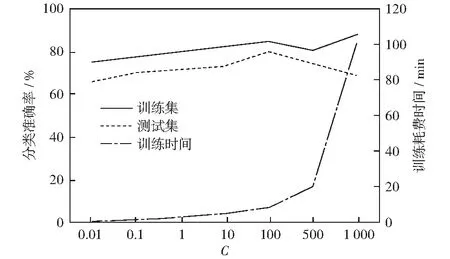
图5 支持向量机惩罚系数C分类准确率曲线
3.4 实验结果
本文对比的零样本图像分类算法有IAP[3]、DAP[3]、ConSE[15]、DeviSE[16]、SJE[17]、SAE[18]、GAZSL[19]、VAE[8]。实验结果在AWA,CUB和ImageNet-2数据集的对比见表2和表3.
如表2所示为本文提出的模型在AWA数据集合和CUB数据集上进行50次实验的平均结果。可以看出准确率均得到了提高。在AWA数据集上本文提出的方法与其他算法相比准确率增加了4.8%.在CUB数据集上与其他算法相比分类准确率增加了4.5%.横向对比,在CUB数据集中,相比在AWA数据集上分类性能稍差。其原因是CUB数据集图像存在细粒度特性,其中的类别非常的接近,仅靠语义信息作为辅助生成的样本在一定程度上存在误差。
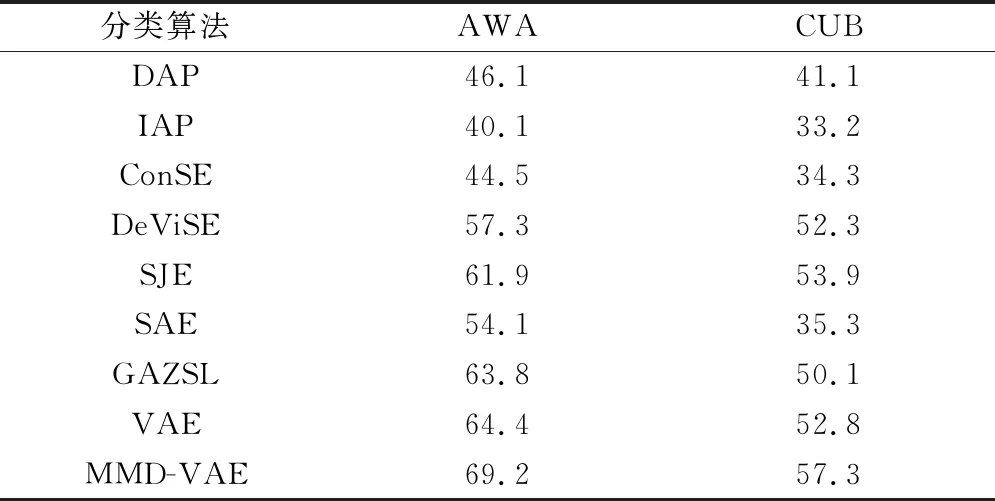
表2 各方法在AWA和CUB数据集分类准确率均值
如表3所示为在大型数据集ImageNet-2上30次实验平均结果。由表3可知,本文算法在ImageNet-2大型数据集上图像分类准确率相比对照的方法提高了5.4%.

表3 在ImageNet-2数据集top-5分类准确率均值
图6为使用3.2节提出的T-SNE特征可视化图进行零样本模型分析。以AWA数据集为例随机选取了9个已知类别样本,分别是原始特征分布和经过改进变分自编码器映射后的特征分布的可视化。从图6(a)可以得知原始图像的特征是杂乱的,在不同类间存在噪声,会对未知类别样本生成产生干扰。对比图(a)和(b)可知噪声分离改进变分自编码器后的生成样本分布类别相同的特征分布变得紧凑,不同类别之间的间隔更大,可以明显看出9个不同类别样本中的噪声干扰得到消除,减缓领域漂移问题,保证零样本图像分类模型训练的鲁棒性。
另一方面由于生成的样本经过样本标签信息控制与未知类别样本高度相似,样本特征更加集中。同时源域和目标域的映射是属性与类别一一对应的,因此可以直观看出本文提出的方法有效避免源域和目标域的映射偏差,改善了零样本图像分类问题中存在的领域漂移问题,即对生成样本特征进行极大约束,更有利于对未知类别进行分类。
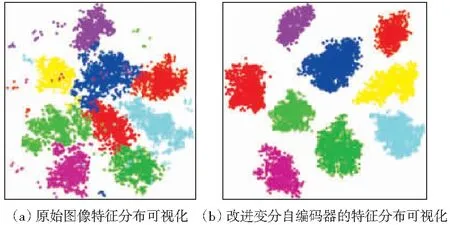
图6 视觉特征分布T-SNE可视化
4 结束语
针对零样本图像分类问题以及在分类过程中存在的领域漂移问题,本文提出了一种利用最大均值化差异改进变分自编码器的零样本图像分类算法,将零样本图像分类问题转化为样本缺失的图像分类问题,该算法在变分自编码器基础上利用最大均值化差异在隐藏层中进行噪声分离,提高生成样本质量,生成了更加符合原样本的生成样本数据集,然后按照有监督学习的方法利用生成样本对图像进行分类。
实验结果表明,该方法改善了零样本学习任务中的领域漂移问题,提高了零样本图像分类问题的准确率,在AWA数据集提高了4.8%,在CUB数据集提高了4.5%,在ImageNet-2数据集提高了5.4%.但是在ImageNet-2大型数据集上面准确率仍然有待提高,这是下一步的研究方向。
