基于RF-LSTM的地表水体水质预测
2021-02-14郝玉莹
郝玉莹, 赵 林, 孙 同, 乔 治
(1.天津大学 环境科学与环境工程学院, 天津 300350; 2.天津市滨海生态关键带保护与功能构建工程技术中心, 天津 300350)
1 研究背景
近年来,随着工业化和城市化的快速推进,水污染问题愈发严重,对人类健康造成极大威胁[1]。水质预测是水资源综合管理和水污染防治的重要基础[2],利用历史水质数据建立高精度的水质预测模型,有助于提前发现区域内的水环境问题,预防大规模水体污染事件的发生。传统的水质预测方法包括多元线性回归法[3]、ARIMA(autoregressive integrated moving average model)方法[4]、灰色系统[5]、人工神经网络[6-7]等,其中,人工神经网络由于具有强大的非线性拟合能力[7]得到了研究者们的广泛应用。
随着大数据时代的到来,传统人工神经网络方法在高维度、大容量水质数据的学习中表现不再突出[8],相较之下,起源于人工神经网络的深度学习网络由于可以逐层、深入分析数据集中的复杂结构[9],在处理大数据样本时更具优势。此外,水质数据本质上是时间序列数据,在进行水质预测时应充分考虑其中的时序信息[8]。作为一种深度学习网络,LSTM (long short-term memory) 在网络结构设计中引入了记忆单元,既继承了深度学习的优势,又具有较强的分析数据中时序信息的能力[10]。自2017年Wang等[11]首次利用LSTM预测太湖水质后,不断有学者将LSTM应用于我国水质预测领域[8,12-13]。然而,单个LSTM模型的预测效果有限,为了提高模型的预测精度,学者们仍在不断探索。例如,王军等[14]构建了卷积神经网络(convolutional neural network, CNN)和LSTM的混合模型预测黄河小浪底水库溶解氧(dissolved oxygen, DO)含量,预测结果的均方根误差(root mean square error,RMSE)和平均绝对误差(mean absolute error,MAE)比单一LSTM模型降低了19.71%和10.44%;许佳辉等[15]针对水质数据在空间和时间上的复杂关系,提出了图卷积神经网络(graph convolutional network, GCN)和LSTM耦合的水质预测模型,结果表明该模型相比ARIMA、支持向量回归(support vector regression, SVR)和单一LSTM方法具有明显优势。由此可见,基于LSTM实现高精度水质预测还有很大的研究空间,可以朝着优化网络内部结构或者与其他方法组合等方向进行深入探索[16]。
多元水质数据具有复杂的相关性,在建立水质预测模型时经常会输入多种影响水质变化的环境指标。但输入特征过多不仅会加大计算难度,而且易导致预测精度下降[17],因此选取合适的特征组合对于提高预测精度具有重要意义。现今水质预测领域通常主观确定输入特征,或者采用主成分分析等方法降低特征维度[17-18],缺少对于数据的解释性。RF (random forest)算法是一种基于决策树的集成学习方法[19],具有简单高效、鲁棒性好等优点,其内嵌的特征重要性评价机制可以通过分析数据间的相关性筛选出对待测目标影响较大的关键特征。例如,郭昱辰等[20]首先利用RF算法确定影响鸡舍氨气浓度的最优特征组合,再结合LSTM预测鸡舍氨气浓度,结果表明引入RF算法后,氨气预测值的MAE、RMSE和平均绝对百分比误差MAPE(mean absolute percentage error)分别降低了15.4%、2.3%和16.2%。然而,在水质预测领域,尚未发现关于RF特征选择与LSTM结合的研究。
基于上述问题,本文以桃林口水库的水质监测数据为样本,首先利用RF算法对影响高锰酸盐指数(CODMn)、氨氮(NH3—N)、总氮(total nitrogen, TN)和总磷(total phosphorus, TP)浓度变化的各水质指标进行重要性评分,再将筛选出的最优特征组合输入LSTM网络中,构建一种RF特征选择与LSTM预测结合的水质预测模型,以期为实现高精度水质预测提供参考。
2 数据来源与研究方法
2.1 研究区概况与数据来源
秦皇岛市桃林口水库位于河北省秦皇岛市西北部的青龙河上,控制流域面积5 060 km2,总库容8.59×108m3,是一座以城市供水、农业灌溉为主,兼具防洪和水力发电等多种综合任务的国家大型水利枢纽工程。目前,桃林口水库主要担负着秦皇岛市和唐山市生活用水供给、农业灌溉、防洪、发电等任务,其水质对于两市的生活和经济发展有着举足轻重的作用。
本文数据是桃林口水库水源站2016年8月24日16时至2018年4月19日16时的水质在线监测数据,水库水源站监测点地理位置如图1所示。水质数据采集频率为4 h,采集数据共计31 530个,包含pH值、温度(Temp)、浊度(Turb)、电导率(Elecon)、DO、CODMn、NH3—N、TN、TP、叶绿素(Chl)共10项水质指标。结合桃林口水库的水质情况,本文选择其中的CODMn、NH3—N、TN和TP为预测目标,利用桃林口水库水源站监测数据分别构建基于RF-LSTM的未来4 h水质预测模型。
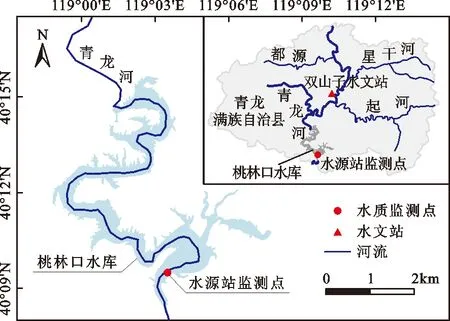
图1 桃林口水库水质监测点位置
2.2 随机森林(RF)算法
RF算法是一种基于决策树的集成学习方法,利用bootstrap重采样技术[21]在原始数据集中随机抽取K个训练集,分别训练K棵决策树组成随机森林。以原始数据集中没有被抽取出来的袋外数据(out-of-bag, OOB)作为随机森林的OOB测试集,最终根据决策树在对应OOB测试集中的投票分数进行分类决策。目前,RF算法凭借建模简单、泛化能力强、不易过拟合等优势,在很多分类和预测任务中表现突出。
值得一提的是,RF算法内嵌的特征重要性计算模块使其具有分析复杂特征间相互作用的能力,因此RF算法也可以作为高维数据的特征选择工具计算各个特征变量的重要性。基于RF算法进行特征选择的基本步骤如下:
(1)从容量为N、特征数为M的初始数据集中有放回地随机取出n(N>n)个数据,生成K个新训练集,没有被抽中的数据则构成K个OOB数据集;
(2)在K个新训练集中分别训练K棵决策树模型,然后计算每棵决策树在对应OOB数据集中的投票分数;
(3)随机扰动OOB数据集中的特征xi,i=1,2,…,M,形成新的OOB数据集,重新获取投票分数;
(4)用公式(1)计算每个特征xi的重要性,即:
(1)
式中:K为决策树数量;SK为决策树在对应OOB数据集中获得的投票分数;SK,i为施加扰动后决策树在对应OOB数据集中获得的投票分数;IMPi为各特征的重要性评分。
(5)对IMPi降序排列可得到各特征的重要性排序,排名越靠前表明该特征对分类的贡献量越多,最终选出既使特征数目尽可能少又满足分类效果较好的最优特征集。
2.3 长短时记忆神经网络(LSTM)
作为深度学习方法中一类非常重要的神经网络,循环神经网络(recurrent neural network, RNN)可以通过为网络添加额外的权重在网络图中创建循环,使其输入不仅取决于当前输入,还取决于之前的输入。可是大量实践表明,标准RNN在对长时间序列数据进行建模时易发生梯度消失和爆炸的现象[22]。为了避免这一现象,Hochreiter等[23]通过改进RNN引入了LSTM网络。相较于标准RNN,LSTM在其隐藏层的各神经单元中增加了记忆单元,开创性地引入了输入门、遗忘门和输出门,通过这些门控结构进行细胞状态的存储与更新,实现时序信息的长期保留。LSTM记忆体示意图见图2,具体工作原理表达式如公式(2)~ (7)所示。
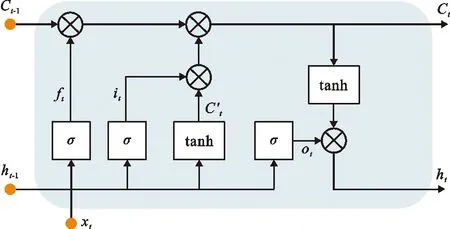
图2 LSTM记忆体示意图
ft=σ(Wf[ht-1·xt]+bf)
(2)
it=σ(Wi[ht-1·xt]+bi)
(3)
(4)
(5)
ot=σ(Wo[ht-1·xt]+bo)
(6)
ht=ot⊙tanh(Ct)
(7)
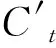
由公式(2)~ (7)可知,遗忘门ft控制t-1时刻细胞状态Ct-1的通过程度;输入门it决定哪些信息可以输入当前时刻记忆细胞;遗忘门ft和输入门it共同更新当前时刻细胞状态Ct;输出门ot决定当前时刻细胞状态的输出。
2.4 基于RF-LSTM的水质预测模型
本文首先采用RF算法对水质指标进行特征选择,在此基础上结合LSTM网络构建水质预测模型。图3展示了该混合模型的算法流程,可分为数据预处理、特征选择、LSTM模型的构建与训练、水质预测等。
(1)数据预处理:考虑到数据集缺失值大于10%,以及水质指标间的相关性,选用多重插补法[24]填补缺失值;接着利用标准化方法消除水质指标间由于量纲不同带来的影响,标准化方法如公式(8)所示:
(8)
式中:x为水质数据;x*为标准化后的数据;xmean为水质数据的平均值;xstd为水质数据的标准差。
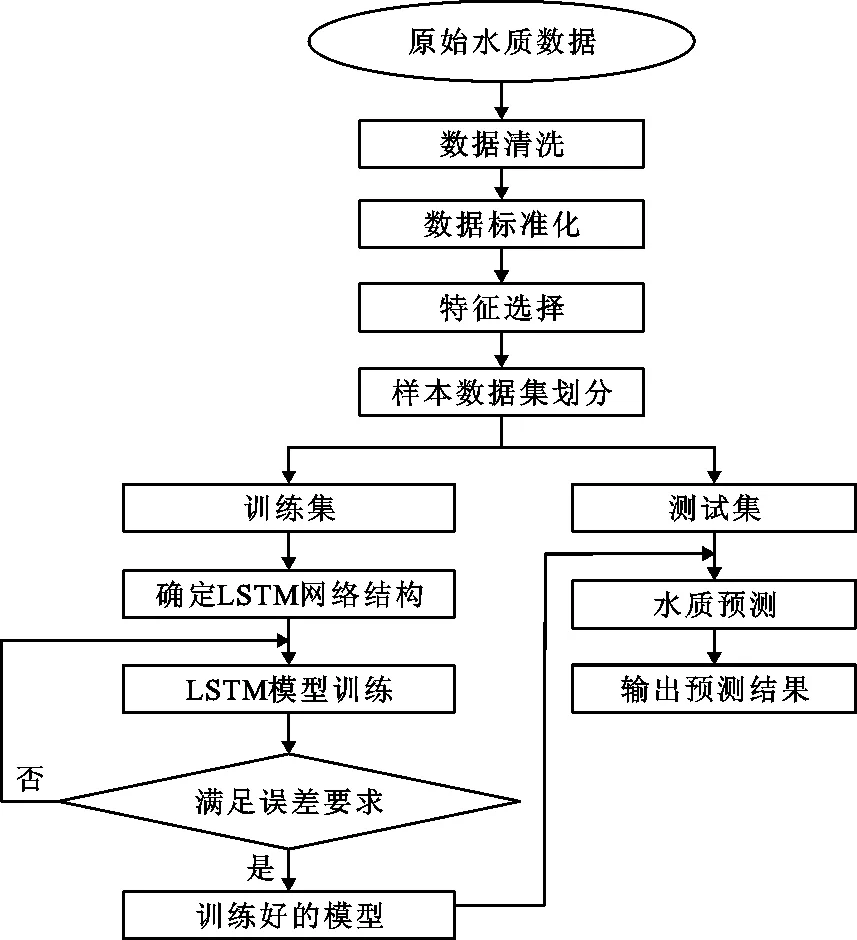
图3 RF-LSTM水质预测模型流程图
(2)特征选择:通过RF算法计算各水质指标对于待测指标的重要性并降序排列,合并重要性排名靠前的水质指标和待测水质指标作为后续LSTM模型的输入特征;
(3)LSTM模型的构建与训练:通过滑动时间窗技术构建输入样本及输出样本,按一定比例划分训练集与测试集。将训练集的输入样本输入LSTM网络中训练模型,当模型输出的预测结果满足精度要求时,保存训练好的模型参数;
(4)水质预测: 将测试集的输入样本输入训练完毕的模型中预测水质,输出预测值。
2.5 模型预测效果评价
水质预测问题实质上是一种回归问题,因此本文选用MAE、RMSE和决定系数(R2)来衡量模型的预测效果。MAE和RMSE表征预测结果与实际数据的偏差,其数值越小意味着模型预测效果越好;R2表征模型的拟合能力,其值越接近于1表示拟合能力越强。
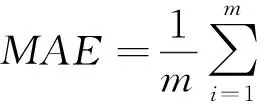
(9)
(10)
(11)
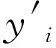
3 结果与分析
3.1 基于RF算法的特征选择结果
水质数据具有非线性、非平稳性、受多种环境因素影响等特点,利用其他水质指标构建多对一预测模型可以在一定程度上提升预测精度。然而,在实际水质预测过程中,参与预测的水质指标过多反而会降低预测精度。因此,本文通过RF算法分别计算各水质指标对于CODMn、NH3—N、TN和TP的重要性,选取重要性评分大于0.1的水质指标和待测指标合并,作为后续预测的输入特征,基于RF算法的特征选择结果如图4所示。
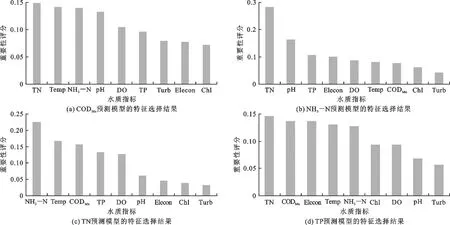
图4 基于RF算法的特征选择结果
由图4可知,在构建CODMn预测模型时,可选用CODMn、TN、Temp、NH3—N、pH和DO作为输入特征;同理,选用NH3—N、TN、pH、TP和Elecon作为NH3—N预测模型的输入特征;选用TN、NH3—N、Temp、CODMn、TP和DO作为TN预测模型的输入特征;选用TP、TN、CODMn、Elecon、Temp和NH3—N作为TP预测模型的输入特征。
3.2 LSTM模型网络参数设置
除了固定的输入层和输出层外,本文构建的LSTM网络还具有两个隐藏层。将特征选择后的数据与待测目标数据合并为新数据集,通过滑动时间窗技术重新采样,经过综合考虑和多次试验,设置滑动窗口宽度为24,从数据集中切分相应时间宽度的水质数据作为输入样本,以滑动窗口后1个时间宽度的水质数据作为输出样本,向后滑动该窗口形成一系列相互覆盖的样本数据,即用过去96 h的数据预测未来4 h的数据。将样本数据中的80%作为训练集,其余则作为测试集。初始化模型参数,代价函数选择均方误差(MSE),优化器选择Adam,多次训练模型并不断调整参数,当实际值与预测值之间的误差满足精度要求时,保存模型。各待测水质指标预测模型网络参数见表1。

表1 各水质指标预测模型网络参数
3.3 基于RF-LSTM模型的水质预测结果
本文以桃林口水库水质监测数据为研究对象,利用RF-LSTM模型分别对CODMn、NH3—N、TN和TP未来4 h的浓度变化进行预测。选取2016年8月24日16时至2017年12月20日16时的水质数据为训练样本,训练模型并保存参数。选取2017年12月20日20时至2018年4月19日16时的水质数据为测试样本,输入到训练好的模型中,输出预测结果,每个模型均输出719个预测值。为充分验证RF-LSTM模型的性能,使用相同数据,以单一LSTM、RF-BPNN(random forest-back propagation neural network)以及RF-RNN模型作为对比模型。图5和表2展示了不同模型分别对于CODMn、NH3—N、TN和TP的预测结果。
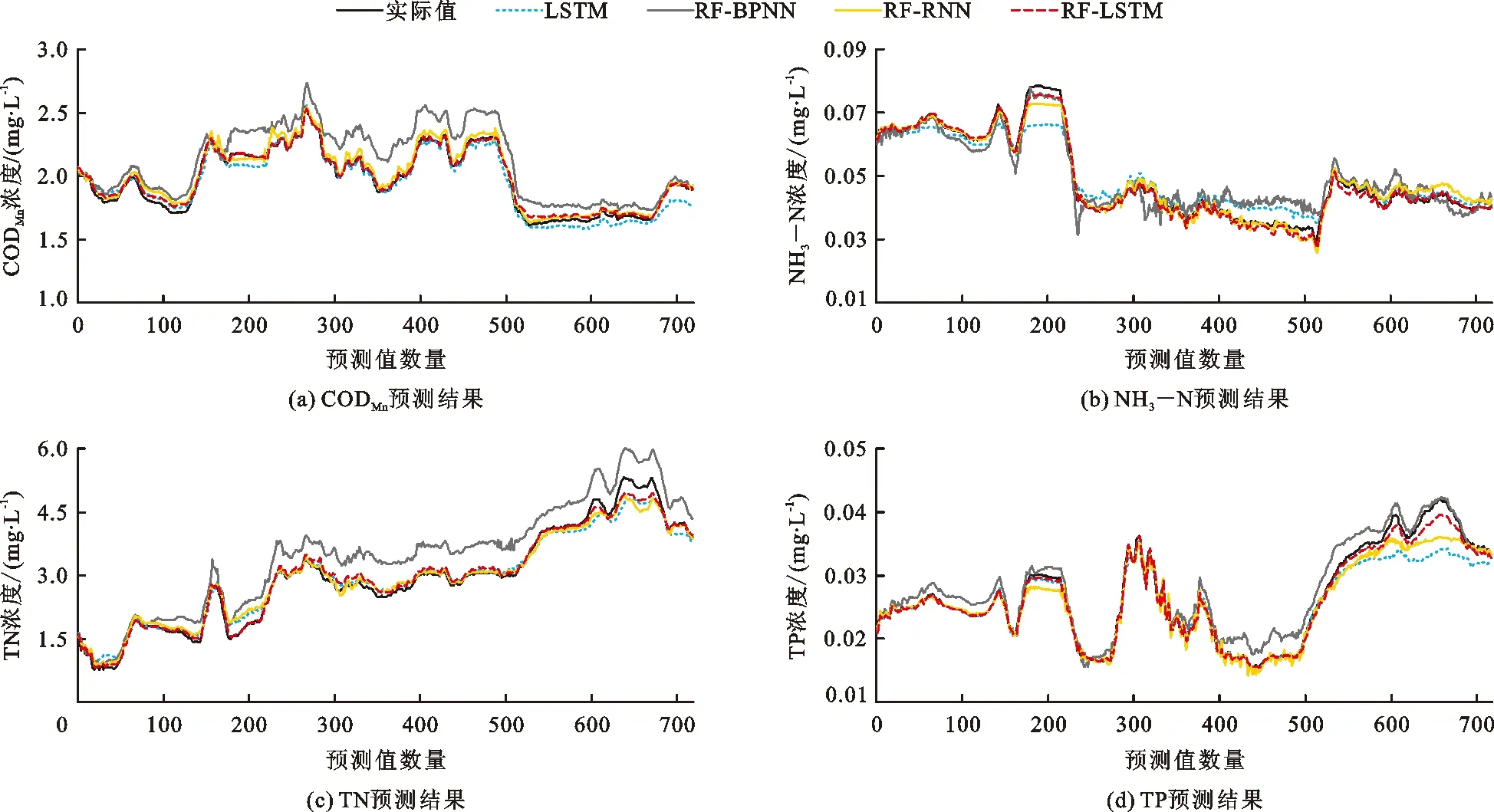
图5 不同模型对各水质指标预测值与实际值对比
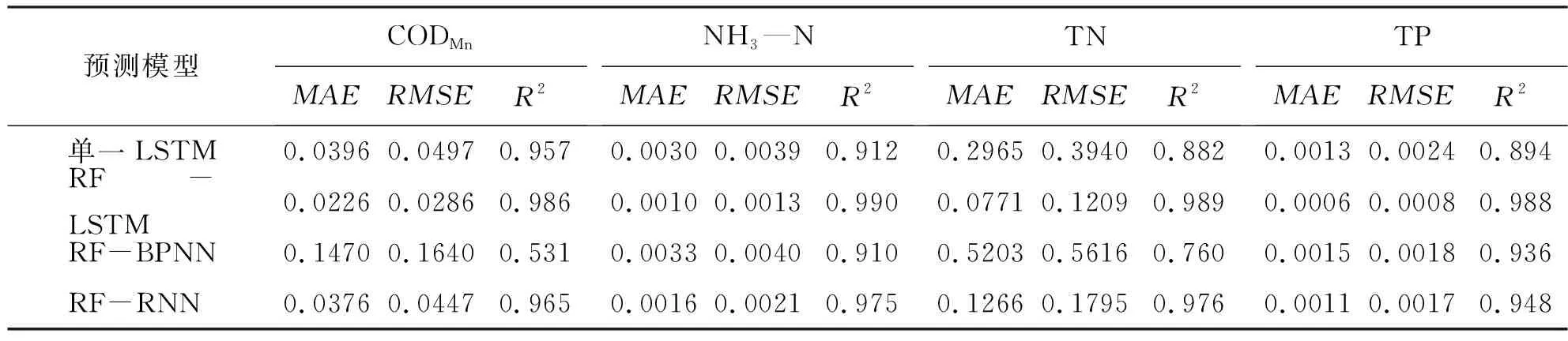
表2 不同模型对各水质指标预测效果对比
为降低训练难度,提高预测精度,在构建LSTM网络之前,本文首先通过RF算法对原始水质指标进行了特征选择。为验证该算法对于模型预测精度的提升效果,以单一LSTM模型作为对比模型,进行特征选择有效性分析试验。通过对比图5中RF-LSTM模型和单一LSTM模型对CODMn、NH3—N、TN和TP的预测结果,可以直观地看出RF-LSTM模型的预测结果曲线更贴合实际值曲线。此外,结合表2可知,经过特征选择处理后,LSTM模型对于以上4项水质指标的预测误差均有不同程度的降低。CODMn预测结果的MAE和RMSE分别降低了42.9%和42.5%;NH3—N预测结果的MAE和RMSE均降低了66.7%;TP预测结果的MAE和RMSE分别降低了53.9%和66.7%;尤其是TN预测结果的MAE和RMSE大幅降低了74.0%和69.3%。因此,本文证明了通过RF算法进行特征选择可以有效减小预测误差,有助于提高模型预测精度。
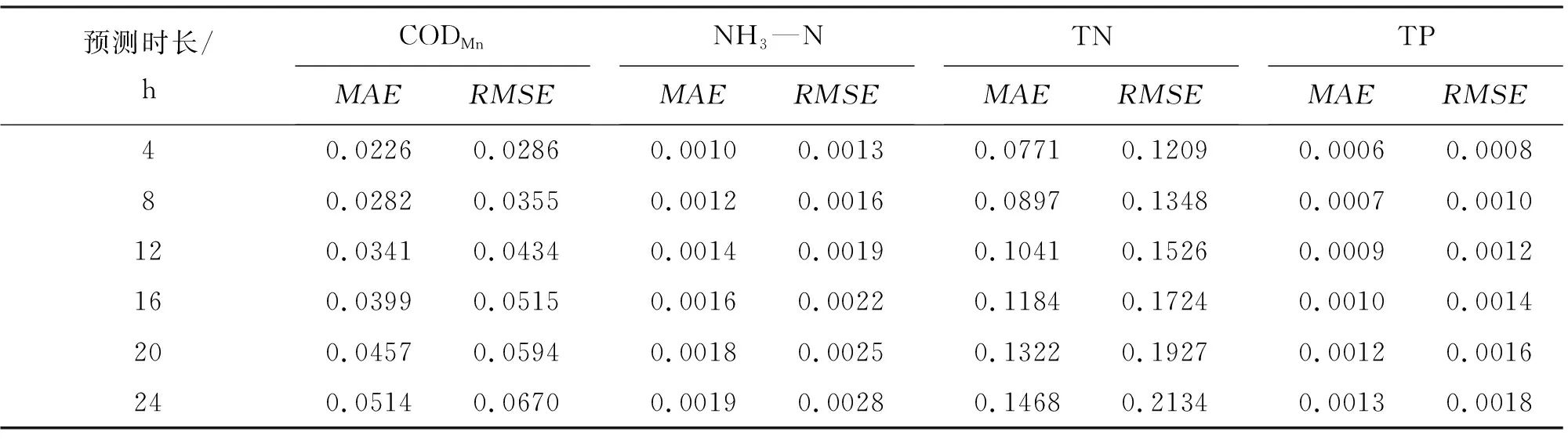
通过对比图5和表2中RF-LSTM、 RF-BPNN与RF-RNN模型分别对于CODMn、NH3—N、TN和TP的预测结果可知,RF-LSTM模型的预测结果明显具有更高的拟合优度,对于以上4项水质指标的预测结果分别达到了98.6%、99.0%、98.9%和98.8%的高拟合度。整体来看,RF-LSTM模型预测误差 为进一步验证RF-LSTM模型的预测性能和泛化能力,本文进行了不同步长下CODMn、NH3—N、TN和TP水质预测实验。设置滑动窗口宽度仍为24,预测步长分别为2、3、4、5、6,即用过去96 h的数据预测未来8、12、16、20、24 h的水质。 表3为不同步长下RF-LSTM模型对于以上4项水质指标的预测误差。整体来看,随着预测步长的增加,模型预测误差均越来越大,不如预测未来4 h的效果好,但这些预测误差都在可接受范围内,可以满足实际水质预测的精度要求。因此,本文证明了在不同预测步长下RF-LSTM模型仍可以保持较好的预测效果,可以预测未来24 h的水质,具有很强的泛化能力。 表3 不同步长下RF-LSTM模型预测误差对比 凭借更深层次的网络和强大的结构,深度学习不仅继承了传统神经网络的非线性拟合能力,而且在大容量数据集上也有更突出的表现,被研究者们越来越多地应用于水质预测中。LSTM是众多深度学习算法中的一种,特有的门控式结构使其既可以充分挖掘水质数据中的时序信息,又可以解决其他深度学习算法无法处理的时间长期依赖问题,在预测水质时具有明显优势和较高精度。此外,在预测前先通过RF算法对模型的输入特征进行筛选,适当减少输入特征,有助于降低模型训练难度,实现对预测精度的进一步提升。据此,本文提出了RF-LSTM水质预测模型,并以桃林口水库水质监测数据为样本进行验证,发现在对CODMn、NH3—N、TN和TP这4种不同水质指标浓度进行预测时,RF-LSTM模型的MAE和RMSE相比单一LSTM模型均有所减小,更接近实际值,并且在与RF-BPNN和RF-RNN模型进行对比时,也展现出了更高的预测精度。印证了其他研究者们先降维、后预测的模型研究结果[25-26]。 随着大数据时代的到来,水质数据采集方式逐渐由人工采集转变为自动化监测,这使得现今水质数据具有大容量、高频次的特点。然而,传统水质预测方法难以充分挖掘大量水质数据中的潜在信息,预测精度无法满足实际应用中的业务需求,亟需研究出具有高精度的水质预测方法。本文提出的RF-LSTM水质预测模型,在预测桃林口水库CODMn、NH3—N、TN和TP未来4 h的浓度变化时,分别达到了98.6%、99.0%、98.9%和98.8%的高拟合度,展现出明显优于其他传统模型的高预测精度和强泛化能力。在实际应用中,可以用于建立桃林口水库的水质预测预警平台,提前感知水库水质的潜在污染风险,发送预警报告,并进行污染回溯,极大地提升相关部门对水环境风险的预测能力,将被动的水环境风险应急处理提升为自动化预测预警与主动防治,有效保障水库的水环境安全。同时,本文提出的模型还可为其他地区地表水体水质预测模型的构建提供参考,具有重要的应用价值和现实意义。 此外,本文提出的RF-LSTM预测模型还有进一步的优化空间,后续研究工作可围绕以下两点展开:(1)加入并筛选更多可能影响水质变化的其他特征,如气象数据、周边污染源的实时排放数据等;(2)本文仅使用了一个监测站点的水质数据,后续可以加入研究区内其他站点的水质监测数据,结合ArcGIS软件更加直观地从时间和空间两个角度进行预测。 为了实现高精度的水质预测,本文提出了基于RF算法和LSTM网络结合的水质预测模型,并以桃林口水库水质监测数据为样本进行了验证,得到如下结论: (1)为分析RF算法对于提升模型预测精度的有效性,通过RF算法分别筛选出影响CODMn、NH3—N、TN和TP浓度变化的关键特征,在此基础上建立RF-LSTM模型。对比实验结果显示,RF-LSTM模型预测CODMn的MAE和RMSE比普通的LSTM模型降低了42.9%和42.5%;预测NH3—N的MAE和RMSE均降低了66.7%;预测TN的MAE和RMSE降低了74.0%和69.3%;预测TP的MAE和RMSE降低了53.9%和66.7%。这一结果表明,通过RF算法进行特征选择可以有效降低模型预测误差,提升预测精度。 (2)为验证模型精度,采用相同的研究数据,分别构建RF-BPNN和RF-RNN模型,并与RF-LSTM模型进行对比实验。结果表明,RF-LSTM模型在预测CODMn、NH3—N、TN和TP未来4 h浓度时,分别达到了98.6%、99.0%、98.9%和98.8%的高拟合度,均优于其他模型,具有极高的预测精度和较强的泛化能力。此外,该模型在多步预测实验中也展现出了较好的预测效果,可以预测以上4项水质指标未来24 h的浓度,为实现高精度水质预测提供了新思路。3.4 基于RF-LSTM模型的多步长预测结果
4 讨 论
5 结 论
