基于主题细分的社交网络用户间交互特征分析*
2021-02-01杨欣谊朱恒民
杨欣谊 朱恒民,2 魏 静 陈 文
(1.南京邮电大学 管理学院 南京 210003;2.江苏高校哲学社会科学重点研究基地—信息产业融合创新与应急管理研究中心 南京 210003)
0 引 言
据第44次《中国互联网络发展状况统计报告》,截至2019年6月,我国网民规模达8.54亿。在规模巨大的用户基础上,在线社交平台上形成了纷繁复杂的用户关系网络。正是这种庞大网络上的用户间交互行为,促使信息在互联网上迅速传播和扩散[1-3]。
在线社交网络中,用户间交互行为往往受到用户主题偏好的影响,即令用户感兴趣的话题更容易被传播。用户间交互行为呈现什么样的主题偏好特征?如何在纷杂的信息中探索出这种特征?从用户间交互记录中细分出不同的主题维度,进而从微观层面细粒度地刻画用户间交互行为的主题偏好特征,为网络信息的引导和干预提供科学的依据。
1 文献综述
用户的信息交互行为已成为国内社交网络研究的热点之一[4],主要涉及两个方面:挖掘影响用户间交互行为的因素,以及基于交互行为的应用研究。徐建民等[5]融入转发者与发布者的社交关系、转发者对内容的偏好等影响因素对用户转发行为进行预测。刘玮等[6]通过实验发现社交关系对预测模型的准确率提升最大。上述工作均指出了社交关系是影响用户间交互行为的重要因素之一。基于网络用户行为的“记忆性”[7],Zhu等[8]利用用户间历史交互纪录构建了以交互概率为权重的用户关系网络,能够反映用户间交互的偏好;琚春华等[9]提出了基于关系圈与个体交互环境的用户交互关系强度计算方法。张继东等[10]提出了基于用户间交互行为的用户影响力度量模型;Liu等[11]以转发概率作为用户间关系的权重,挖掘在特定主题下对特定节点的转发最具影响力的节点。社交网络中用户间关系是影响用户交互行为的重要因素,目前已有工作是根据交互概率或转发概率等一维指标来度量用户间交互关系的强度,并没有考虑到用户间在不同主题下交互行为的差异。
主题模型越来越多地被用来挖掘在线社交网络中用户的兴趣偏好[12-14]。夏立华等[15]基于PLSA方法分析用户评论中产生的子话题,而Varshney等[16]则利用主题模型实现Twitter文本的潜在主题挖掘,从而获得用户兴趣;夏立新等[17]利用LDA主题模型获取用户标签主题来研究用户兴趣的层级演化规律;安璐等[18]基于主题模型刻画了微博用户特征,实现了恐怖事件情境下的用户画像。上述工作均是采用主题模型对社交网络中单个用户的行为特征进行细粒度地分析,如何利用主题模型探索用户间交互的主题偏好特征,仍需要进一步地研究。
社交网络中用户间的交互具有一定的主题偏好,不同主题下用户间的交互强度是不一致的。为了细粒度地刻画出用户间交互的主题特征,本文提出基于主题细分来分析用户间交互行为的研究思路。首先,通过用户间交互实例分析得出主题细分的必要性;其次,基于主题细分,采用多维向量来表示用户间的交互关系强度;在此基础上分析用户间交互的主题偏好特征。
2 用户间交互的主题偏好实例分析
社交网络用户在选择阅读或传播信息时是有兴趣偏好的,这种偏好也影响着用户之间的互动。用户间互动的主题是否集中?用户间在不同主题上的互动强度有没有差异?为了回答这些问题,本文选取了新浪微博的一些用户实例,通过分析其在3个月内转发的内容,来探索用户间交互的主题偏好。
表1列出了6个新浪微博用户在3个月内的交互主题统计情况。实例用户的ID分别为“头条新闻”(用户1)、“微天下”(用户2)、“立春SpringBegins”(用户3)、“人民网”(用户4)、“新浪综艺”(用户5)和“新浪娱乐”(用户6)。表中数字为交互用户在各主题下的交互频次。

表1 用户间交互主题及频次统计
从表1中可以看出用户间的交互内容往往涵盖多个主题。例如,用户1与用户2的交互内容涉及社会、时政、娱乐3个主题;用户3与用户4的交互则涉及除此以外的时尚、生活、科技、情感、体育等共8个主题。此外,从表1中还可发现,虽然在一段时间内用户间交互主题涉及到多个方面,但是不同主题上的交互频次是有差异的。如用户1与用户2的交互偏向时政和社会主题,而娱乐主题甚少涉及;用户5与用户6的交互则偏向娱乐方面。这说明用户间的交互是具有主题偏好的,即在不同主题上的交互强度是不一致的,仅使用一维的连边权重(交互总频次)无法精确地描述用户交互的主题偏好,因而有必要对交互内容进行主题细分,细粒度地分析用户间的交互行为。
3 基于主题细分的用户间交互特征分析思路
首先在微博用户交互纪录数据获取与预处理的基础上,采用LDA模型进行主题识别;基于主题细分思想,采用多维向量表示用户间交互的强度,并计算不同主题下的强度分量;最后,针对具体实例,利用统计分析和复杂网络方法分析用户间交互的主题偏好特征。具体流程如图1展示。

图1 基于主题细分的用户间交互特征分析流程
3.1数据获取与预处理针对新浪微博在线社交平台,首先爬取一个用户关注关系子网,再以该子网为基础,获取子网内用户间的交互纪录。
LDA主题识别的前提是对数据进行清洗和分词。交互纪录爬取程序针对单个用户进行,因而记录中涉及许多子网外用户的纪录,对这些纪录进行删除。本研究仅针对文本内容进行分析,因而剔除仅包含链接或图片等非文本数据的纪录,删除重复数据。新浪微博的文本内容包含用户的多级转发数据,对这样的纪录进行剥离,获得多级交互数据。最终,每一条交互纪录被表示成一个四元组(上游节点,下游节点,内容,转发时间)。
对于每一条交互纪录中的文本内容,利用jieba工具包进行分词。文本中包含许多出现频次高却无实际含义的词(停用词),对于这类词,在哈工大停用词列表的基础上,增加数据集中重复出现的无意义字符,去除停用词。
3.2LDA主题识别LDA主题模型首先由Blei等[19]提出,这一模型通过无监督的学习方法发现文本中隐含的主题信息,从而将文档集中每篇文档的主题按照概率分布的形式表示。LDA模型能够预测训练集与非训练集中文档和词的主题分布,经过完善,亦成为分析大规模非结构化文档集的有效工具[20]。
LDA主题模型获得结果的好坏与文档总数、主题数量、词汇总数、迭代次数等相关。因获取文档集的大小是确定的(虽然可以通过语料库训练,但仍然是确定的),主要通过调节主题数量、词汇总数、迭代次数等获得最优模型。模型常用衡量指标为困惑度(Perplexity),困惑度越小,模型越好。通过不断调参获得最优主题模型,将每一条文本表示为一个多维向量:
c=(t1,t2,…,tm)
(1)
其中,m为主题总数;tk表示这条纪录内容属于主题Tk的权重,所有主题下的权重相加为1。
3.3主题细分下用户间多维交互强度表示用户间交互强度是根据一段时间内产生的历史交互纪录综合计算而定。基于历史交互纪录内容的主题向量,节点i和j的交互强度tISij可表示为同维度的向量形式:
(2)
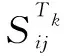
(3)
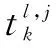
3.4用户间交互的主题偏好特征分析将用户表示成节点,用户间交互关系表示为连边,则构成用户交互网络。利用可视化工具Gephi绘制用户交互网络,观察用户间交互形成的主题子网。基于Python编程和统计分析方法,首先观察交互强度在各主题上的分布;再对不同时段的用户间交互关系进行相关性分析;最后,基于复杂网络分析方法挖掘特定主题下的用户子网,观察子网内用户交互的主题偏好特征。
4 实例分析与结果讨论
4.1数据准备本文爬取的用户网络为新浪微博中一个包含1 488个用户的关注关系子网,交互数据为该子网内用户3个月内的交互纪录,时间跨度为2017年9月1日至2017年11月29日,经过预处理获得17 509条交互纪录。原有关注子网中的用户之间产生了16 324条单向关注关系,但大部分用户未发生交互,历史纪录中的交互发生在645个用户的2 224条关注关系上,本次研究针对关注且发生交互的用户间关系(简称交互关系)。
4.2主题识别与分析在LDA主题模型中,经过实验最终选择的迭代次数为100,总词数为500,主题数量为12,困惑度值为364.0898。各个主题由词语及其在该主题出现的概率组成,表2列出了各主题下权重排名前15的词语。从表中可看出,识别出的各主题区分度较大。主题T1与海外新闻相关;主题T2、T3、T6比较相似,侧重情感类话题;主题T4与电影和时尚相关;主题T5与婚姻话题相关;主题T7主要与财经新闻相关;主题T8是儿童成长方面的话题;主题T9与社会新闻相关;主题T10与慈善事业较为相关;主题T11与娱乐新闻更相关;主题T12与电竞行业相关。
4.3用户间交互主题特征分析
4.3.1 交互关系强度值分布 将所有用户间交互关系强度按照主题分量的大小进行降序排列,以排列顺序为横坐标,交互强度值为纵坐标作散点图,可得到各主题下交互强度的分布图。图2所示为主题T1、T5、T9下的交互强度分布。可见这3个主题下的关系强度分布较相似,且大部分交互关系的强度值较小。例如主题T1下交互强度值小于0.5的关系占91.73%,但仍有部分关系的交互强度值很大,有4.09%的关系交互强度值大于0.9。这说明用户间交互强度值分布具有长尾特征,即在特定主题下,尽管大部分交互的主题分量比较小,但仍有少部分交互分量值较大。
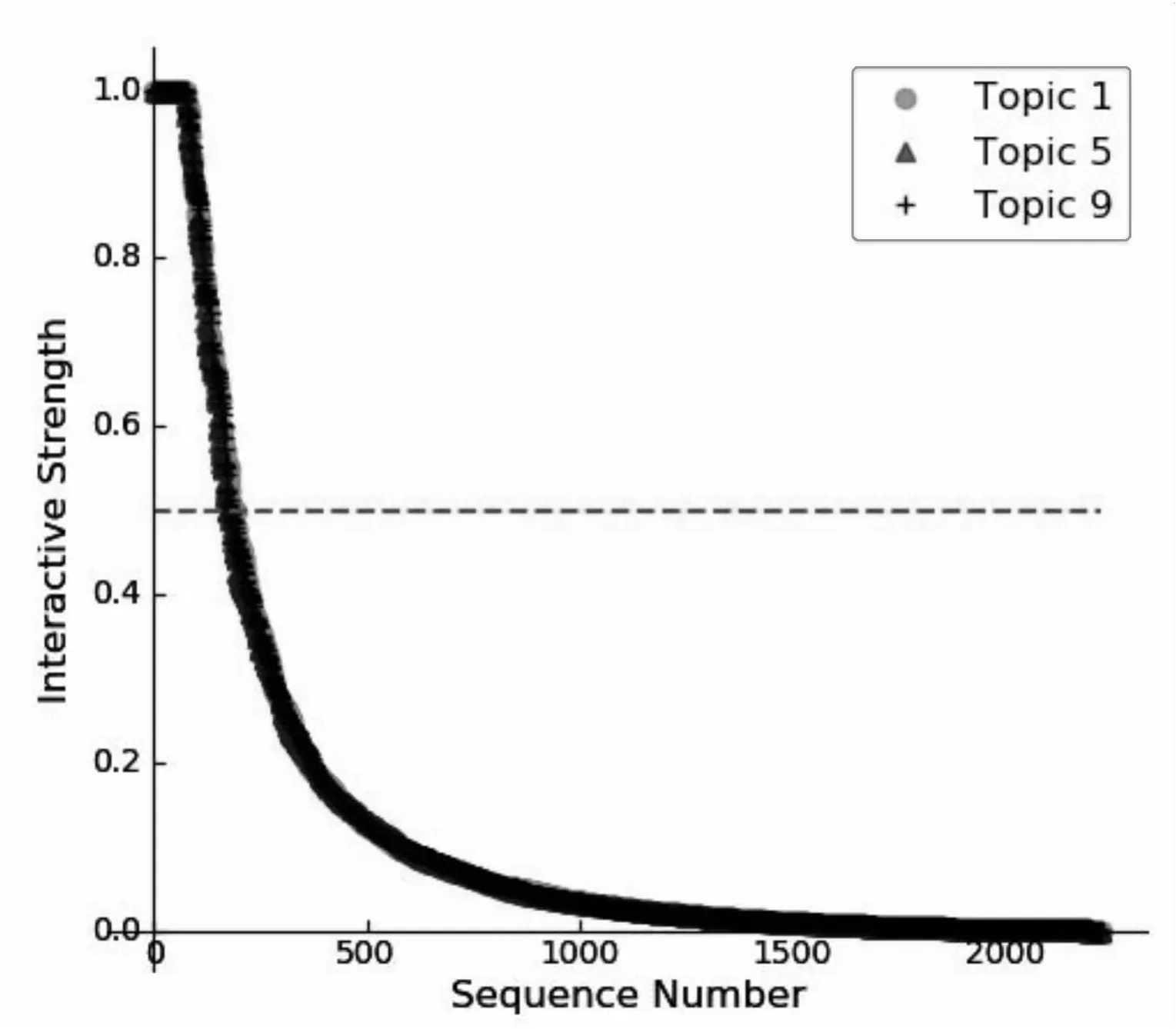
图2 不同主题下交互强度的分布
选择权重最大的主题分量作为交互关系的偏好主题,则交互关系可以划分为不同的偏好主题类。为了验证这种划分的合理性,本文通过计算交互关系两两之间的相似度,来对比分析具有相同偏好主题和不同偏好主题的交互关系相似度分布的差异。
图3中浅色部分代表偏好主题不同的交互关系之间的相似度分布(分别为T8与T10),深色部分为偏好主题相同的交互关系之间的相似度分布(T8)。从图3可以发现,主题偏好相同的交互关系之间相似度分布呈现明显右偏,其相似度平均值为0.7733,标准差为0.0134,其中92.94%的相似度大于0.6;而相较之下,偏好主题不同的交互关系间相似度较小,平均值为0.5562,标准差较大,为0.0494,其中58.42%的相似度小于0.6。可见,偏好主题相同的交互关系相似度高,而偏好主题不同的关系相似度则较低,这表明采用权重最大的主题分量来标识交互关系的偏好主题,是可以在主题上区分用户间的交互关系的。
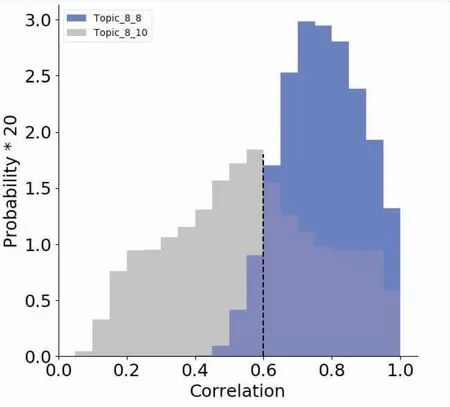
图3 交互关系间的相似度分布
4.3.2 用户间交互主题的时序相关性分析 将交互纪录按照时间顺序分为两份,计算两个时间段内用户间在各主题下的交互强度,再计算同一用户对在两段时间内多维交互关系的相关系数,可用于评价用户间交互主题的时序相关性。图4展示了两段时间内用户间交互关系强度相关性值的分布,可发现相关性值的分布明显右倾,有74.61%的交互关系在前后两段时间内的相关性值大于0.5230,说明用户间交互在前后两段时间内具有显著的相关性。这说明用户间交互的主题偏好在一段时间内具有稳定性。用户间交互行为的这一特征可被用于用户传播行为的预测。
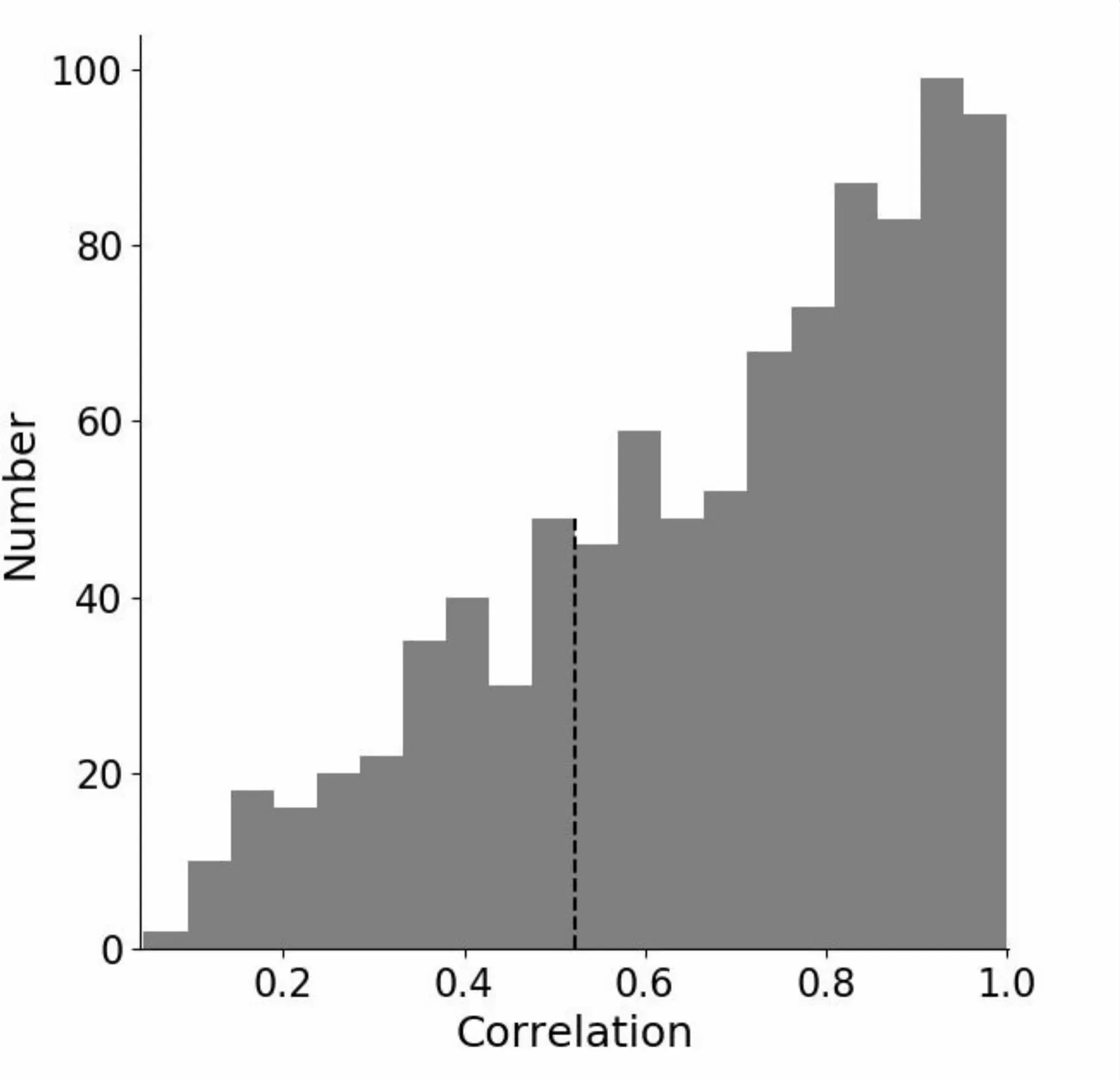
图4 用户间交互主题的时序相关性分布
4.3.3 用户间交互主题子网分析 偏好主题相同的交互关系可形成一个交互子网。图5为偏好主题为T4的关系及其所连接的用户构成的部分网络,图中节点表示用户,节点内数字表示用户编号,连边表示用户之间的有向交互关系,从下级用户指向上级用户。偏好主题T4的关系共有206条,连接了253个用户,其中103条交互关系连通了93个用户。图6为主题T4子网内所有用户在3个月中传播内容的词云,可以看出,主题子网传播高频词为“电影”“感觉”“时尚”“生活”“艺术”“朋友”等,是与电影、时尚相关的内容,这说明同一主题子网的用户之间传播的话题也是与该主题相关的。因此,可根据信息的主题有针对性地对某个子网采取措施,实现有效的信息传播监控和干预。
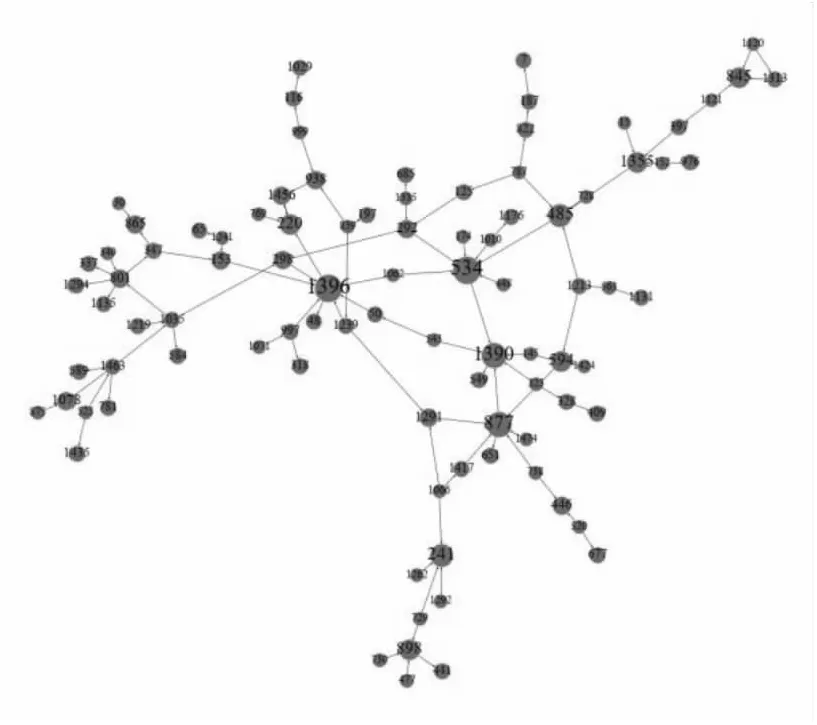
图5 偏好主题T4的交互关系形成的最大连通子网

图6 主题T4下子网的传播内容词云
偏好主题T11的交互关系形成的最大连通子网如图7所示。对比分析T4和T11两个主题子网的节点重要性,如表3所示。其中,主题Tk子网中节点A的入度表示在数据获取时间段内,对用户A传播的特定主题Tk的信息进行转发的用户数目。显然,入度值高的用户节点对该主题的信息传播起到的作用也大。考虑到网络中相当数量节点的入度值是相同的,本文结合另一常用指标PageRank来进行节点重要性的评价。

图7 偏好主题T11的交互关系形成的最大连通子网
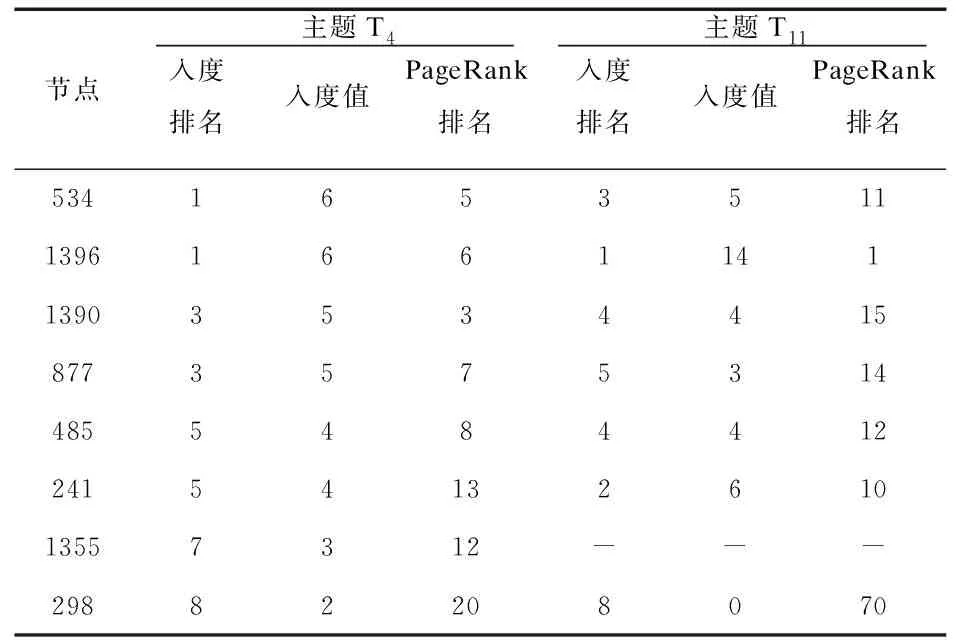
表3T4和T11主题子网节点重要性对比
对比分析T4与T11两个主题子网中的节点重要性。可看出标号分别为534、1396、1390、877、485和241的这6个节点在两个主题子网中的入度值和PageRank值排名均靠前,说明这些节点在两个子网的话题传播中都起到了重要作用。此外,我们也发现两个子网中一些节点的重要性存在差异。例如,节点1355在主题T4下很重要,入度排名第7,PageRank排名第12,但不存在于T11子网中;此外,节点298是主题T4下的重要节点而在主题T11下入度为0,PageRank排名靠后,对主题T11下的话题传播作用很小。由此可见,节点在不同主题子网的话题传播中发挥着不同的作用。因而对于不同主题子网,需要选择相应的关键节点实现有效的信息传播干预。
5 结 语
本文主要贡献在于提出了基于主题细分的用户间交互强度的表示和度量方法,以及基于此对社交网络用户间的交互主题偏好特征进行了细粒度分析。研究发现用户间交互关系强度的分布具有长尾特征;在不同时间段,用户间的交互主题具有时序相关性,即一段时间内用户间交互的主题偏好会相对稳定;基于多维的用户间交互强度,可抽取出具有相同主题偏好的用户交互子网,发掘出子网中的关键节点,研究结论可用来预测用户传播信息的行为,方便对信息传播进行监控和干预。
