基于小波分解的LSTM水质预测模型①
2021-01-21魏守科王莹洁赵金东袁梅雪
孙 铭,魏守科,2,3,王莹洁,赵金东,袁梅雪
1(烟台大学 计算机与控制工程学院,烟台 264005)
2(山东琢瑜清泉智能软件科技有限公司,烟台 264005)
3(北京迪普迅智能信息技术有限公司,北京 100089)
水是人类和其它生命体赖以生存的重要资源,由于过去工业废水和生活污水未经处理而排放到水体,导致河流湖泊水体的严重污染,从而严重破坏了水体的生态环境、生物多样性及其生态功能和服务功能[1].据相关研究,全世界只有小部分河流没有受到水污染影响[2,3],在一些发展中国家,水污染是导致疾病和死亡的主要原因之一[4],仅在中国范围内,每年因水污染导致约1.9 亿人次患病,其中6 万人死于肝癌、胃癌等疾病[5],有数据统计,自1980年以来太湖水域频繁发生藻华,导致长江三角洲地区约41 种鱼类、65 种浮游动物和16 种大型植物消失[6].因此,建立准确有效的水质预测模型,意义重大.
目前,对于水质的模拟预测方法主要有灰色动态模型群,混沌理论,小波神经网络和BP 人工神经网络等.如:李如忠等[7]利用灰色系统理论构建了一个由6 个灰色模型组成的灰色动态模型群,并且利用该模型对水体中的氨氮浓度进行预测,最终结果取这6 个GM 模型的平均值,消除了GM 模型本身的不稳定性,取得了不错的预测效果;徐敏等[8]利用混沌理论和相空间重构思想对于水体中溶氧量进行了分析,结果表明水质具有混沌性,看似水质变化是无规律的,但其在短期内具有一定的内在规律可以探寻和预测,利用混沌相空间模型对水质进行了短期预测,也取得了一定的成果;陈建秋等[9]使用小波神经网络来对水质进行长期预测,预测精度较高,证明了其方法的可行性;RI 和侯德刚等[10]提出BP 神经网络对水质进行预测,其中化学需氧量(COD)、pH 值等数值较接近真实值,其他指标的预测值的误差也与真实值相差不大,取得了非常好的预测效果.
水质数据通常是按照时间先后顺序排列的,较前述文献模拟预测方法,循环神经网络(Recurrent Neural Network,RNN)更加适合处理这种时间序列数据.如:Jia 等[11]使用RNN 对湖泊温度和水质数据进行建模,通过与ANN 模型对比证明RNN 对时间序列数据预测具有更高的精度和准确性;Kumar 等[12]对河流月流量数据进行预测研究,将RNN 与前馈神经网络进行对比试验,结果表明RNN 能够以更少的时间代价取得更好的预测效果.然而,RNN 网络模型存在梯度弥散、梯度爆炸以及对序列数据中长距离依赖信息能力差的问题[13],而LSTM 拓展了RNN 能够更好地解决上述问题,有效地提高了预测准确度.LSTM 也在许多领域都取得了不错的进展,比如在自然语言处理方面,胡新辰[14]利用LSTM 解决语义关系分类问题取得了重要成果;在股票运作方面,孙瑞奇[15]基于LSTM 并利用拟牛顿法原理改变网络模型的学习速率,证明了LSTM 能够很好地预测股市的变化;在空气质量预测方面,张冬雯等[16]利用LSTM 更精确地对Delhi 和Houston 两地的空气质量AQI 指数做出了预测;在降雨径流量预测方面,Hu 等[17]通过对比ANN 和LSTM两种模型的预测结果,表明LSTM 模型具有更好的仿真性和更高的智能性.上述多个研究都表明LSTM 对时间序列数据的预测方面具有得天独厚的优势.然而,利用LSTM 对水质时间序列进行预测的文献资料相对较少.如:刘晶晶等[18]采用K-Similarity 方法对地表水水质数据进行降噪,利用LSTM 神经网络预测降噪后水质数据变化,研究表明相较于BP 神经网络和RNN,LSTM 对水质序列数据有更好的预测能力;Hu 等[19]和Liu 等[20]使用LSTM 分别研究了海产养殖区的海水水质和扬子江水源地的饮用水水质,他们实验结果都表明LSTM 能够更准确地反映水质变化的发展趋势,证明了LSTM 预测水质的可行性和有效性.但是,传统的神经网络模拟预测方法对于序列波动变化较大并存在长期趋势的时间序列,其预测结果并不理想[21,22].本文提出基于小波分解的LSTM 时间序列模拟预测方法(W-LSTM),运用小波将水质数据分解为高频和低频信号,作为LSTM模型的输入,来训练模型预测水质数据.同时,将模型预测结果与传统LSTM 神经网络的结果进行对比,验证该方法的有效性.
1 W-LSTM 算法原理
1.1 小波变换原理
傅里叶变换是信号处理领域应用极广的一种分析手段,它可以将时域信号转换成频域信号,但是傅里叶变换在时域中没有辨别能力[23].小波变换正是针对傅里叶变换的不足之处发展而来,利用小波和一族带通滤波器对原时域函数进行分解,将信号分解为二维的时频信息,极大地增强了局部信号的表现能力,提高了模型的抗噪性[24].
小波变换是一种数据分解、重构方法,该方法首先分别利用低通滤波器和高通滤波器将原始数据分解成低频小波系数cAn和高频小波系数cD1,···,cDn.其中,低频小波系数还可以再做进一步的分解,此过程可以迭代数次,直至达到最大分解次数.
小波变换可以分为连续小波变换(CWT)和离散小波变换(DWT).为了提高连续小波变换处理复杂问题的能力,CWT 对基小波ψ (t)进行改造,如下式:
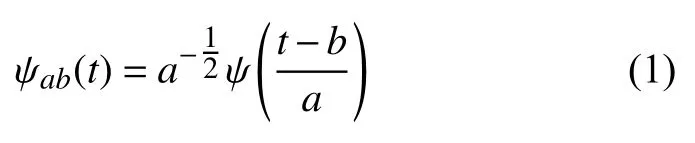
其中,a为伸缩因子(a>0),b为平移因子(b∈R),通过调整a和b的值来够控制小波变换的尺度,从而达到高频处时间细分,低频处频率细分,实现自适应时频信号分析的要求[25].
连续小波变换公式如下:
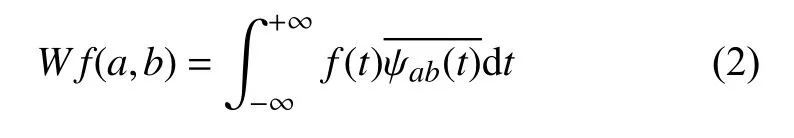
其中,Wf(a,b)表示连续小波系数,f(t)表示原始数据,表示ψab(t)的共轭函数.
然而,连续小波变换会计算所有尺度上的小波系数,这一耗时的过程也会产生许多冗余数据.因此,在实际过程中通常使用离散小波变换.离散小波变换是对连续小波变换在尺度和位移上按照2 的幂次进行离散化所得.将 ψab(t)函数中a和b的计算方法如式(3)所示:
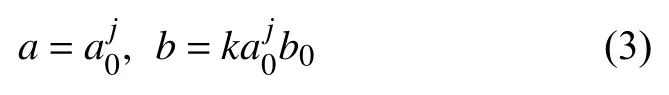
其中,a0>0,b0∈R,∀j,k=0,1,2,···,m∈Z,则函数ψjk(t)的计算方法如式(4)所示:
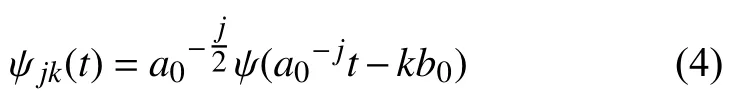
离散小波变换公式如下:
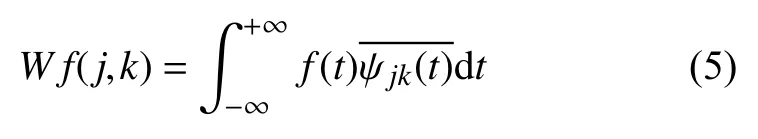
其中,W f(j,k)表示离散小波系数,f(t)表示原始数据,表示ψjk(t)的共轭函数.
将原始数据进行分解之后,再分别对低频小波系数和高频小波系数进行重构.低频小波系数和高频小波系数重构后得到低频信号rAn和高频信号rD1,···,rDn.其中,低频信号表示逼近信息,高频信号表示细节信息.
最后,将所有低频信号和高频信号相加实现数据还原.重构与还原公式如下:
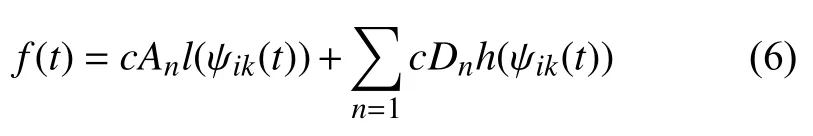
其中,f(t)表示还原之后的数据,l(ψik(t))表示低通滤波器,h(ψik(t))表示高通滤波器.
1.2 LSTM 原理
RNN 擅长处理以时间序列数据作为输入的预测问题,其原因在于RNN 的网络结构可以处理时间序列数据之间的相关性.RNN 结构如图1所示.
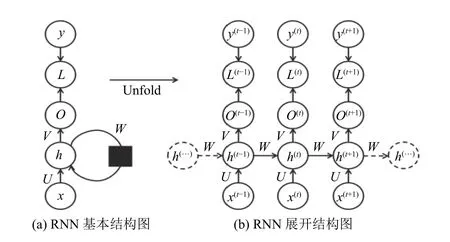
图1 RNN 原理结构图
图1(a)为RNN 的基本结构图,包括输入层x、隐藏层h、输出层o,在隐藏层h上有一个循环操作,同时RNN 在所有时刻的线性关系参数U、W、V都是共享的,极大地减少了参数训练量.图1(b)为RNN 展开结构图,可以看到RNN 通过权值W实现隐藏层之间的依赖关系.
然而,在实际使用时发现RNN 存在诸如梯度消失、梯度爆炸以及长距离依赖信息能力差等问题,为了解决这些问题,引入了LSTM.LSTM 在主体结构上与RNN 类似,其主要的改进是在隐藏层h中增加了3 个门控(gates)结构,分别是遗忘门(forget gate)、输入门(input gate)、输出门(output gate),同时新增了一个名为细胞状态(cell state)的隐藏状态.
图2展示了LSTM 隐藏层的内部结构,其中f(t)、i(t)、o(t)分别表示t时刻遗忘门、输入门、输出门的值,a(t)表示t时刻对h(t-1)和x(t)的初步特征提取.
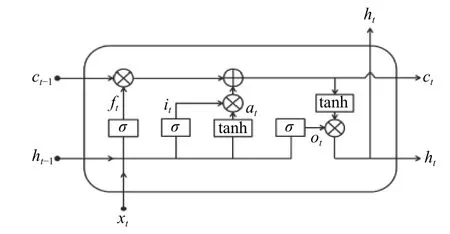
图2 LSTM 隐藏层结构原理
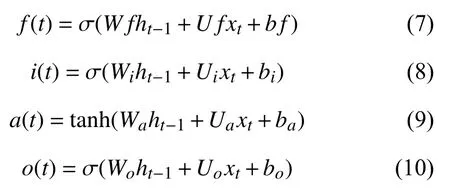
其中,xt表示t时刻的输入,ht-1表示t-1 时刻的隐层状态值,Wf、Wi、Wo和Wa分别表示遗忘门、输入门、输出门和特征提取过程中ht-1的权重系数,Uf、Ui、Uo和Ua分别表示遗忘门、输入门、输出门和特征提取过程中xt的权重系数,bf、bi、bo和ba分别表示遗忘门、输入门、输出门和特征提取过程中的偏置值,tanh 表示正切双曲函数,σ表示激活函数Sigmoid.
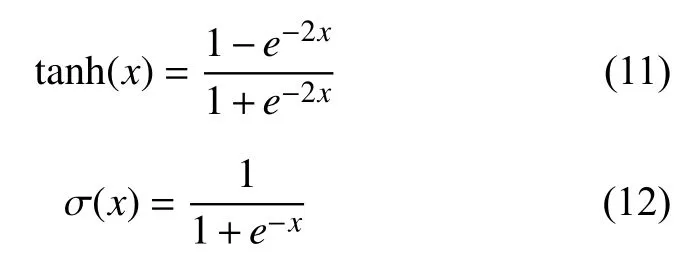
遗忘门和输入门计算的结果作用于c(t-1),构成t时刻的细胞状态c(t).
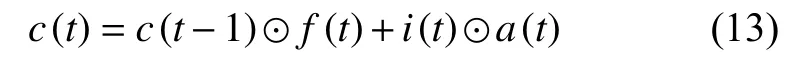
其中,⊙为Hadamard 积[26,27].最终,t时刻的隐藏层状态h(t)由输出门o(t)和当前时刻的细胞状态c(t)求出.
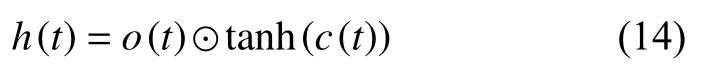
2 W-LSTM 模型
2.1 W-LSTM 网络模型
LSTM 神经网络对预测时间序列数据具有较强的优势,但对于复杂度和变化频率较高的数据,单一LSTM预测方法很难获取数据的变化规律,使得模拟和预测结果欠佳.而小波分解能将原始数据中不同频段的信息进行分解,极大地降低数据复杂度,再分别对这些数据进行预测从而提高预测精度.本文将上述两种方法结合提出基于小波分解的LSTM 时间序列预测模型(W-LSTM).其训练、预测流程如图3所示.步骤如下:
(1)对采集到的水质指标数据使用均值平滑法降噪,然后归一化.
(2)4 项样本数据统一划分为前435 组作为训练数据,后45 组作为测试数据.
(3)使用训练数据作为样本输入用于训练W-LSTM神经网络模型,对模型进行如下两步操作:
① 选取“db5”作为基小波,并对数据进行3 阶小波分解,获取低频信号rA3和高频信号rD1、rD2、rD3.
② 使用LSTM 分别对rA3、rD1、rD2、rD3进行预测.
不断调整参数,直到获取目标loss 或者达到最大训练次数.最终生成W-LSTM 神经网络模型.
(4)使用测试数据作为W-LSTM 模型输入样本,输出模型预测准确度并与对比试验模型进行误差比较.
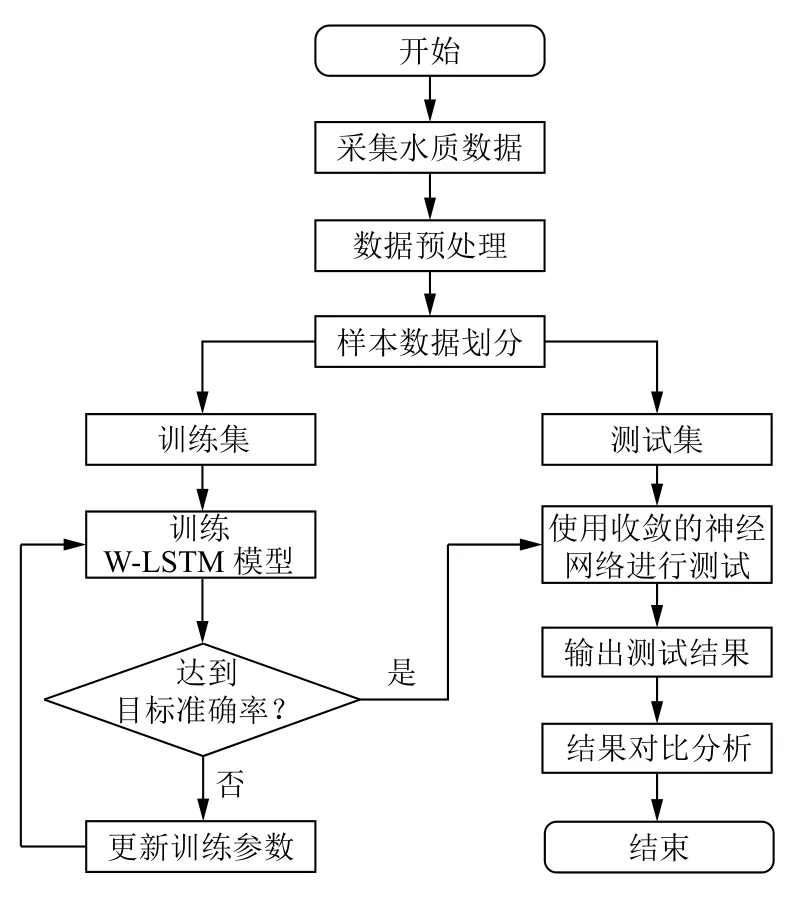
图3 基于W-LSTM 模型的水质预测流程图
2.2 数据样本
本文以安徽阜南王家坝水库的水质数据作为研究对象,该水库位于安徽省阜阳市阜南县王家坝国家湿地公园,湿地占地面积约为6761.71 公顷,作为当地市民主要的供水水库,其水质健康显得十分必要.根据国家地表水质环境质量标准[28],选取pH 值、溶解氧含量(DO)、高锰酸盐指数(CODMn) 和氨氮含量(NH3N)指标作为实验数据.所有指标数据的采集时间均为2018年03月01日到2019年06月23日,每24 小时采集一次,数据一共480 组,取前435 组作为训练数据,后45 组数据作为测试数据.
对数据样本简单分析,查看是否有缺失值、异常值等情况,如表1所示.
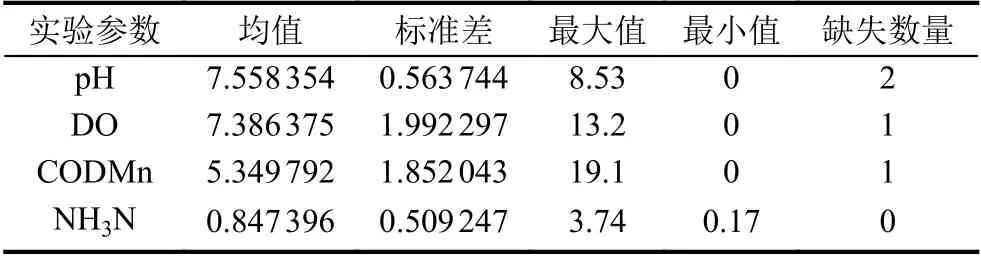
表1 数据样本统计分析 (DO 值、CODMn 值和NH3N 值的单位为:mg/L)
2.3 数据预处理
2.3.1 数据清洗
在数据采集和测量的过程中由于仪器设备故障、不当的人为操作以及其他不可控因素的干扰,采集到的数据不可避免的会导致一些数据丢失和数据录入失真的情况,如果直接使用这些含有噪声的数据开展实验研究,不仅耗费人力物力资源,还会产生不准确的实验结论,从而误导日后的研究工作.因此,在实验开始之前,首先要对数据进行清洗.观察实验数据和表1后发现仅存在几处数据缺失的情况,正常录入的数据没有发现明显噪声.采用均值平滑法将数据缺失部分的数据补充完整.均值平滑法是利用缺失数据左右相邻两处的数据,取平均值来替代缺失数据,如式(15)所示:
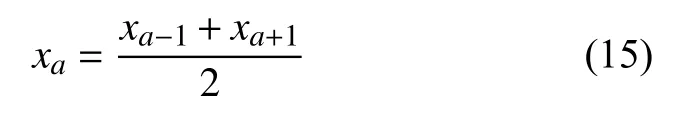
其中,xa为a时刻的缺失数据,xa-1为a-1 时刻的正常数据,xa+1为a+1 时刻的正常数据.
2.3.2 数据归一化
为了加快模型的收敛速度同时提升模型的预测精度,需要对数据进行归一化处理,将数据转换成[0,1]之间的数值.本文使用max-min 归一化方法,其计算方法如式(16)所示:
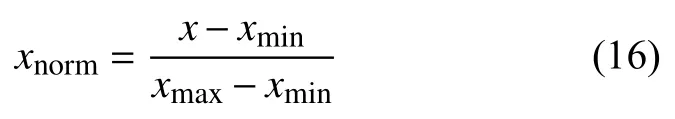
其中,xnorm表示归一化之后的数据,x表示未归一化的数据,xmax、xmin分别表示所有数据中的最大值和最小值.
2.4 离散小波变换流程
使用离散小波分解数据时应注意两点.第一、需要确定基小波的种类.常用的基小波有Haar 小波、db 小波、sym 小波、bior 小波、coif 小波、Morlet 小波、mexicanHat 小波以及Meyer 小波.他们都是一个小波族,每个小波族中包含众多具体的小波.最佳小波的选择没有明确的标准,但实际上无论选哪种小波作为基小波差别也不很大.本文选择Daubechies5 (db5)作为基小波(db5 是db 小波族中常用的小波之一,如图4所示),原因是db5 更适用于分解比较平滑的数据集,而我们采集的水质数据整体上比较平滑.第二,需要确定分解层数,利用式(17)[29]可以计算出数据的最大分解层数为5 层,但是根据经验选最大分解层数的一半即可,所以最终确定分解层数为3 层.
图4 db 小波示意图
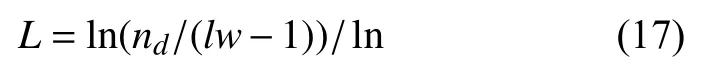
其中,lw表示小波分解低通滤波器的长度,nd表示数据长度.
2.5 模型评估
本文选择4 种评价指标作为判断模型预测效果优劣的依据,其分别是均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean Squared Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)和平均百分比误差(Mean Absolute Percentage Error,MAPE),其计算方法如式(18)~式(21)所示.
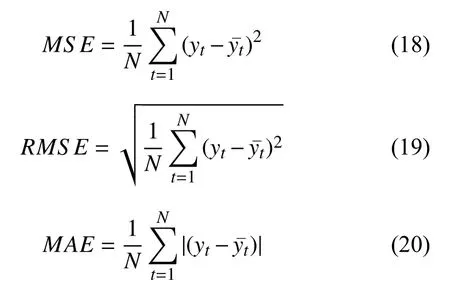
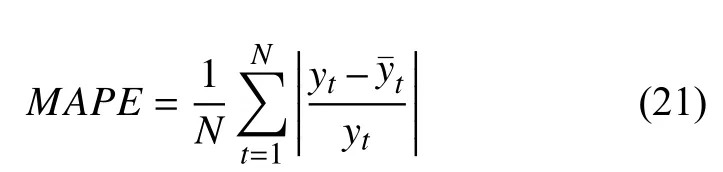
其中,N表示总数据量,yt表示真实值,表示预测值.
3 实验结果分析
3.1 实验平台与环境
实验所使用的计算机配置如下:处理器为英特尔Core i5-8250U,CPU 频率为1.8 GHz,内存为8 GB,操作系统为Windows 10 (64 位);程序设计语言为Python 3.7,数值计算、分析库为Numpy 1.17.1,Pandas 0.25.2,机器学习库为Tensorflow 1.14.0,数据可视化库为Matplotlib 3.1.1;集成开发环境为PyCharm Community Edition 2018.3.1.
3.2 结果分析
为了更好地验证所提出模型的精确性,选取传统的LSTM 神经网络与该模型对比实验.两种模型均在相同的实验平台和环境下进行.均采用自适应矩估计(adaptive moment estimation)进行优化,损失函数选择MSE、RMSE、MAE、MAPE4 种方式进行评价.为尽量避免实验中产生偶然因素,每组实验各进行10 次.3.2.1 小波分解
以pH 数据为例直观展示3 阶小波分解的结果,如图5所示.
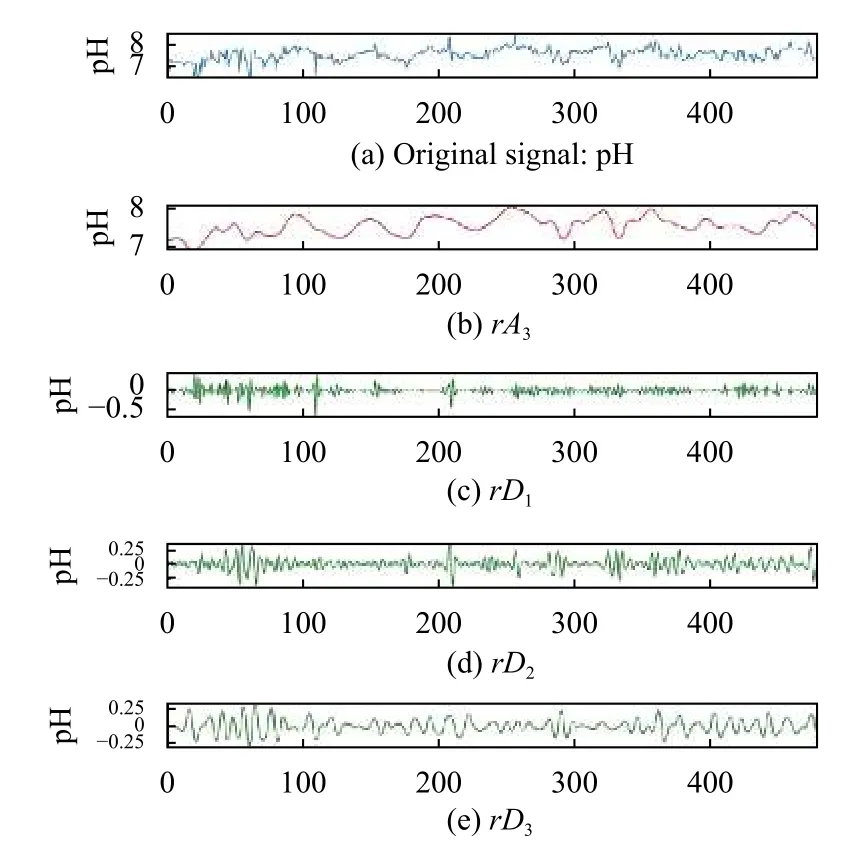
图5 pH 数据的原始值及其3 阶小波分解得到的低频数据rA3 和高频数据rD1、rD2、rD3
然而,将经过小波重构之后各个频段的数据信号相加还原,这一过程与原数据确实存在一定的误差.表2展示了本次实验中4 项指标重构后与原始数据的误差值.可发现其最大误差为6.70e-16,最小的误差为8.33e-17,此误差值对实验结果影响非常小,可以忽略不计.

表2 还原数据与原始数据的误差值
3.2.2 训练结果
本文中W-LSTM 模型和LSTM 模型的调节参数包括batch_size(批量大小),window_size(窗口大小),num_units(节点数量),Learning_rate(学习率),steps(训练步长).在保证网络快速收敛的同时又具有较高的预测精度,经过多次实验测试与参数调整,模型达到最优结果.表3展示了实验相关参数的最终配置结果.
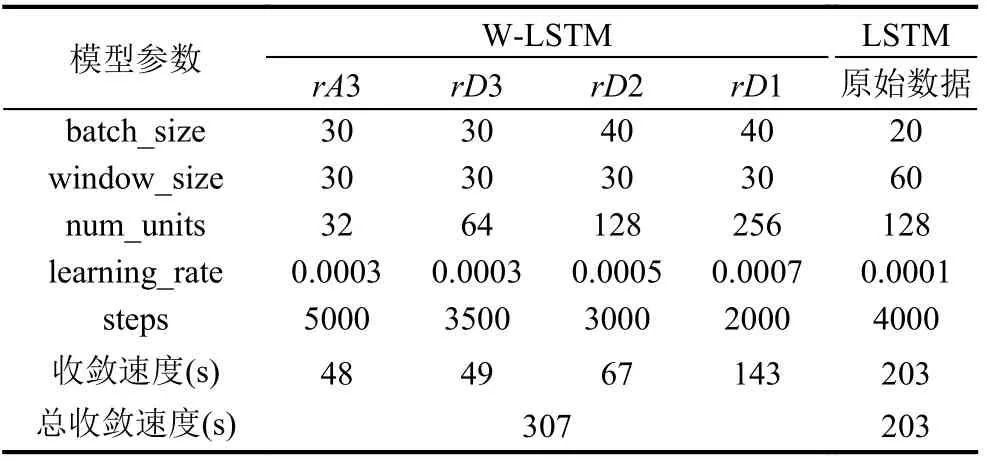
表3 W-LSTM 和LSTM 的网络参数以及收敛速度
实验中反映W-LSTM 和传统LSTM 两种模型训练拟合情况的各项评估指标值记录在表4中.结果显示两种模型对pH 的拟合情况基本一致,且相较于其他3 项实验参数拟合精度最高,MSE均低于0.0008,这与pH 数据的值域变化较小有关;而DO、CODMn 和NH3N 传统LSTM 模型训练拟合结果却都略优于WLSTM,3 项参数在MSE 上分别减小了0.0066、0.0073和0.002,究其原因,不难发现W-LSTM 模型将原数据分解为低频rA3和高频rD1、rD2、rD34 项值,并对它们分别拟合,拟合过程的增多不可避免地会增大误差,最终导致同样量级的训练过程会呈现不同的拟合效果,同样地,拟合过程增多会降低模型训练收敛的速度,其所耗时间必定高于传统LSTM 模型.表3结果显示WLSTM 经过4 个模型训练过程,总收敛时间比传统LSTM模型耗时多约100 s.
为了更加直观的表现各项数据的拟合情况,将WLSTM 与传统LSTM 的拟合情况进行对比如图6所示.从图中可以观察到两种模型都充分学习了训练数据的特性,拟合情况良好,并且没有过拟合的情况发生,能够达到训练要求,证明实验的有效性.

表4 4 项指标W-LSTM 和LSTM 模拟训练拟合精度评估结果
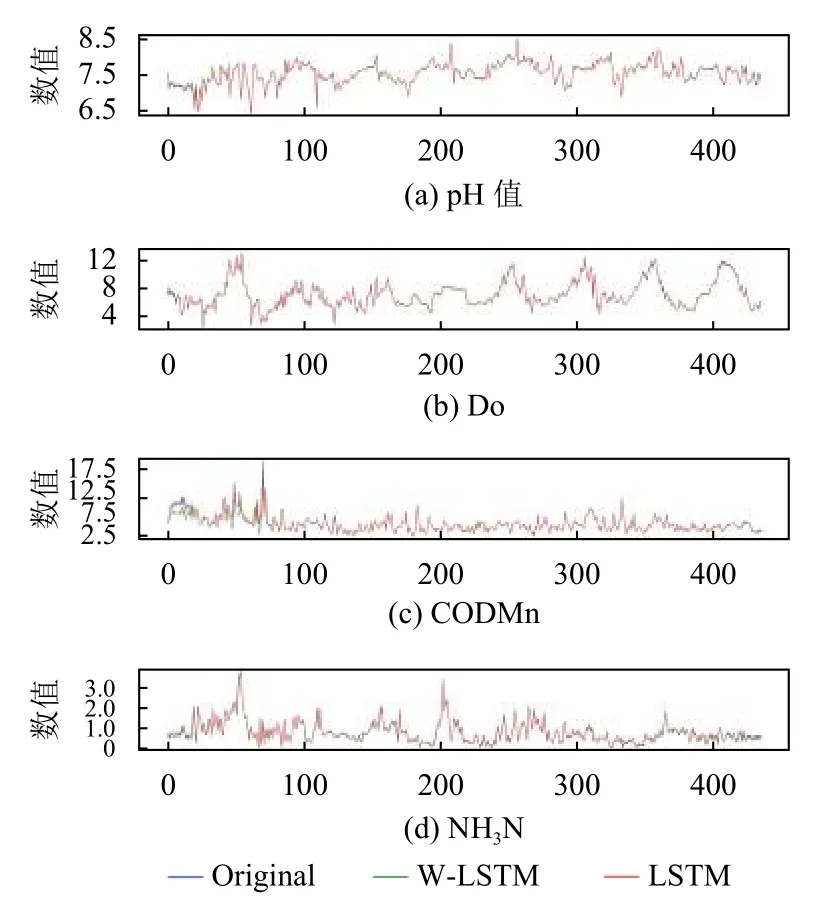
图6 W-LSTM 和LSTM 模型4 项指标训练结果对比图
3.2.3 测试结果
本文的实验数据其最大频率为240 Hz,对其做3 阶DWT,则rA3表示频段小于30 Hz 的分量数据,rD3、rD2和rD1分别表示频段30~60 Hz、60~120 Hz、120~240 Hz的分量数据.理论上相较于原始数据,分量数据的复杂度更低,所以对分量数据进行预测的准确度也更高,通过分量数据获得的全频率上的预测结果准确度也更高.其中,高频数据来自原始数据变化较快的部分,反映信号细节变化特征,低频数据来自原始数据变化较慢的部分,低频信号比较平滑,反映信号的变化趋势.
表5为W-LSTM 和传统LSTM 模型在10 次预测中各项指标的均值对比情况.
从表5中可以明显看出,W-LSTM 模型在水质时间序列指标数据预测方面优于传统LSTM 模型.在MSE、RMSE、MAE和MAPE4 项评估指标中,WLSTM 比传统LSTM 的预测精度在pH 数据上分别提高了35.1%、18.9%、28.3%和28.3%;在DO 数据上分别提高了62.3%、35.0%、34.6% 和31.3%;在CODMn 数据上分别提高了27.9%、15.4%、17.6%和15.4%;在NH3N 数据上分别提高了53.8%、32.3%、35.8%和44.7%.究其原因小波变换能够对数据的整体趋势和细节信息的分层把握能力,加上LSTM 模拟预测时间序列数据上的优势,保证了W-LSTM 不仅能够更清晰的了解数据的整体走势,还能更精确的预测数据的细节变化.这为W-LSTM 在时间序列数据预测方面提供了更强的能力,而且其效果更优于传统LSTM.观察表5中W-LSTM 模型的预测情况不难发现,在多项指标上pH 和NH3N 的结果精度较高,而DO 和CODMn 的结果精度相对较低.其主要原因是pH 和NH3N 数据的标准差较小(表1),数据离散程度较低,所以期望获得的预测精度越高;而DO 和CODMn数据的标准差相对较大(表1),数据离散程度相对较高,致使期望获得的预测精度稍有逊色.

表5 W-LSTM 模型和传统LSTM 模型在3 次预测中各项评估指标均值结果
图7进一步展示了W-LSTM 和传统LSTM 模型对pH、DO、CODMn 和NH3N 4 项水质指标的预测对比结果,可以看出W-LSTM 相较于传统LSTM 模型的预测情况,在总体趋势上与原数据更为一致,同时对某些细节信息例如峰值处也有更加精确的预测表现.
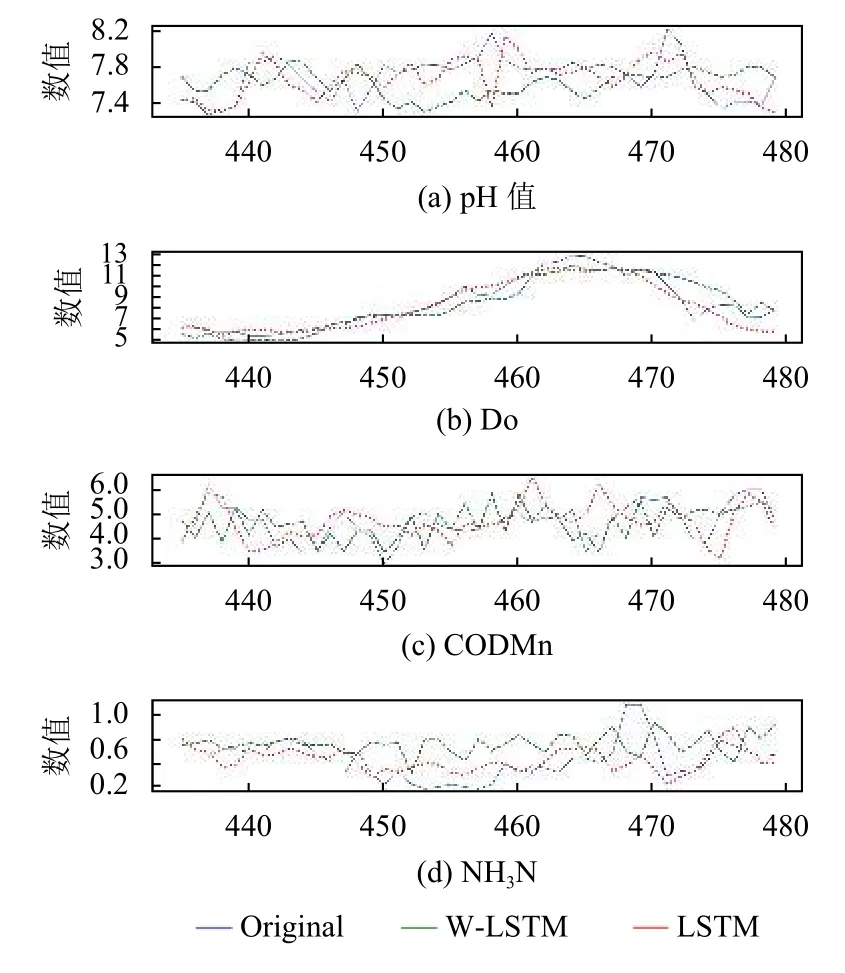
图7 W-LSTM 和LSTM 模型4 项指标预测结果对比图
4 结论
本文提出了基于小波分解的LSTM 时间序列预测模型(W-LSTM),对水质指标数据进行模拟预测实验.结果发现,使用db5 小波对水质数据进行分解与重构过程的误差非常小,表明离散小波变换具有完全重现原始数据的能力,保证实验的有效性.其次,传统LSTM模型预测水质数据的结果在整体趋势上通常不能很好地表现出来,而W-LSTM 最大优势在于对整体趋势的判断以及对细节的把握,实现了对时间序列数据的精确预测.最后,通过对低频数据预测的观察与分析还可以从宏观上了解数据的未来走势,从而更好地指导工作展开.
以王家坝水库水质数据作为研究时间序列数据的切入点,本文通过实验分析证明W-LSTM 能够显著提高水质数据预测的精度.然而,试验仅运用了一个水域的部分水质数据,研究结论是否具有通用性仍有待大量试验验证.因此,未来将W-LSTM 模型应用于更多场景,以研究和验证此方法的通用型.
