基于深度神经网络的视觉手部姿态追踪系统*
2021-01-18陈永乐陈伟全严继超李武初
肖 金,翟 倩,陈永乐,张 彬,陈伟全,严继超,李武初
(广东工业大学华立学院,广州 511325)
0 引言
手部交互是目前计算机图像处理中的重要研究内容。手语识别,社交互动,虚拟现实和增强现实中,手是人机交互的主要输入设备[1-2]。目前的二维手部关键点识别及手部姿态追踪相关研究已日趋成熟。如过去通过传统图像算法,如肤色分割,掌心分割等来实现手部区域的分割,但这种处理方法的依赖静态的图像处理,对图像的彩色空间(RGB,HSI)等要求甚高。其次是依赖特征点提出,通过提出手部相关特征进行识别,一旦手部特征缺失,识别准确度就大幅下降[3]。并且这类传统的手势识别算法对双手遮挡交互、障碍物遮挡、夜间、强光照等环境下的识别问题难以解决。随着人工智能的发展,越来越多的手势识别算法引入了深度神经网络,通过各种环境下采集的数据集进行训练,大幅度提高了在遮挡,日夜光线等苛刻环境下的识别准确度,由此二维的手部追踪算法日趋完善[4-5]。但是二维的手部追踪仅有两个维度的信息,交互仅停留在平面阶段,从而无法实现在空间中对手部的位置进行定位,而许多手部的交互动作是纵深的,如手语交流中的许多动作,影音娱乐中的动作捕捉,虚拟现实中的交互等,二维手部追踪中缺失的第三维度信息就难以解决这些问题。而且通过二维的图像去预测三维的手部姿态非常困难,因为手部的肤色相似,从三维空间中辨认手部关键点非常困难,其次手部动作中非常容易产生遮挡问题[6-8]。许多非视觉的研究中研究采用惯性传感器解决遮挡问题,但在普通RGB相机中就非常困难[9]。
由于实现具备空间定位及SLAM 信息的三维手部模型重建需要三维度数据,而普通的RGB 相机仅能获取二维数据。本文对普通RGB相机如何实现二维升三维的重建及对某一特征的识别与追踪进行研究,从而实现了三维视觉手部追踪。
1 神经网络模块设计
1.1 总网络架构设计
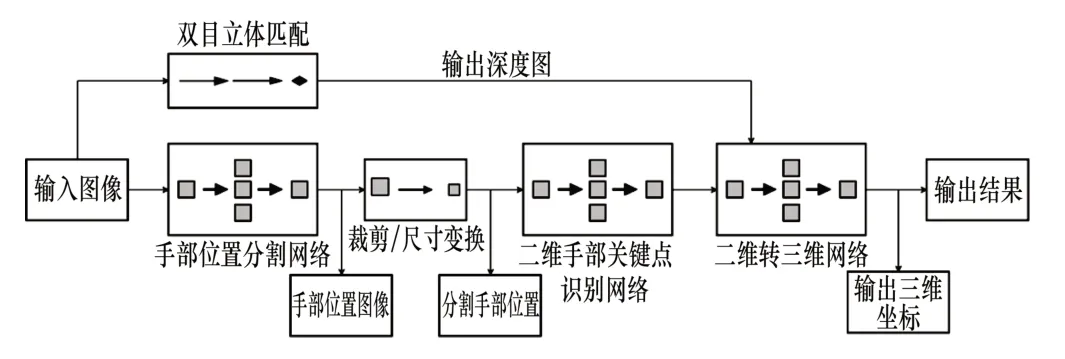
图1 神经网络架构图
如图1所示,整个神经网络由3个网络块构建成,输入的图像在手部位置分割网络中定位手部在整个图像中的位置,然后将输出图像经过裁剪和尺寸变换并将手部位置放大输入到下层的二维手部关键点识别网络中。放大后的手部图输入到二维手部关键点识别网络中,经过计算输出图像中的手部21 个骨骼关键点的位置,在手势识别的相关研究中,得出通过手部21 个关键点即可确定手部的位置。第3 层的二维转三维网络是整个神经网络的核心,它需要两个输入:第一个输入是原图像通过双目立体匹配算法计算后转换的深度图,图像中包含深度数据,可以通过矩阵变换转换成距离信息;第二个输入是二维手部关键点识别的结果。通过两个输入,将手部关键点结果赋值在深度图上,输出21个关键点的深度信息,然后在网络中进行匹配运算,预测在三维空间中最有可能的关键点坐标位置(xi,yi,zi),然后将这些坐标位置通过矩阵变换进行三维重建,得到三维空间中的手部位置。
1.2 手部位置分割网络
手部位置分割网络是图像分割网络,原理主要是通过一些手部姿态数据训练集进行训练,这些被当成是图像位置切割的样本,在图像输入的时候,检测输入图像中手部位置并将其分割出来。
该网络中的输入主要是经普通图像输入后矩阵变换处理后的张量,数据类型为tf.float32,及训练中用于判断真假的样本权重train。网络的输出为输入图像中分割出来手部位置的得分图,输出得分最高的手部位置float32 张量,并且将其分割出来生成新图像输入到下层网络中。
1.3 二维手部关键点识别网络
二维手部关键点识别网络是图像识别网络,原理主要是通过一些标注好的带关键点的二维手部姿态数据集进行训练,让网络不仅可以识别手部图像的关键点,还可以从某个关键点的位置在推理出其他关键点的的位置可能性信息。从上层分割出来的手部位置图输入后,通过训练中用于判断真假的样本权重train 进行检测,并且输出二维手部关键点的得分图,输出每个得分最高,即置信度最高的关键点到下层网络中。需要注意的是,这里输出的得分图为[B,256,256,21],包含手部骨骼21个关键点的得分。
1.4 二维升三维重建网络
二维升三维网络是这个神经网络的核心。在得到手部21个关键点的位置及深度数据后,首先是根据这些数据判断该手型是左手还是右手,通过训练中用于判断真假的的样本权重train 进行检测,估计最有可能的空间手部三维姿态,并且输出标准化的三维坐标点,格式为[21,3],意为输出21个关键点的三维坐标。
2 系统硬件模块设计
如图2 所示,硬件模块由成像模块,主板模块及AI 芯片模块组成。摄像头模块通过单目/双目/TOF摄像头采集图像/视频并且输入到主板处理。算法模块进行算法运算,该过程由AI 芯片模块对其进行加速,首先将原始图像的手部位置分割出来,输入的图像在手部位置分割网络中定位手部在整个图像中的位置,然后将输出图像经过裁剪和尺寸变换并将手部位置放大输入到下层的二维手部关键点识别网络中,经过计算输出图像中的手部21个骨骼关键点的位置,这与人体生理及运动学有关,在手势识别的相关研究中,得出通过手部21个关键点即可确定手部的位置。
第3 层的二维转三维网络是整个神经网络的核心,它需要两个输入:第一个输入是原图像通过双目立体匹配算法计算后转换的深度图,图像中包含深度数据,可以通过矩阵变换转换成距离信息;第二个输入是二维手部关键点识别的结果。通过两个输入,将手部关键点结果赋值在深度图上,输出21个关键点的深度信息,然后在网络中进行匹配运算,预测在三维空间中最有可能的关键点坐标位置(xi,yi,zi),然后将这些坐标位置通过矩阵变换进行三维重建,得到三维空间中的手部位置。

图2 硬件模块设计
3 实验数据
3.1 测试集范例
在公开数据集上实验之前,这里先抽选了来自不同程度,不同环境下的一些图片,这些图片部分来源于纯手部图像,来自网络的人像写真,一些随机搜索的包含手的图像。从“相机角度”、“光源强度”、“肤色”、“复杂环境”、“手部遮挡”来测试该神经网络在应对各种苛刻环境下的泛化性,为了排除可能会出现的偶然性和相似性,每组有3张程度因素从小到大的图像集,一共7 组数据,包含21 张测试图。测试集的图像数据如图3所示。

图3 测试集范例
3.2 范例实验结果
为了验证实验结果,同时也为了方便观察每一层神经网络输出图像是否满足需求和及时观察到可能出现的识别错误,这里将每层神经网络输出的结果都作为实验结果。测试集上的原图经过该三维手部追踪神经网络中,首先经过第一层“手部位置分割网络”将手部位置从整张图片中分割出来,输出到第二层“二维关键点识别网络”中,通过分割出来的手部图像,识别二维中的21个手部骨骼关键点,并且为了方便可视化效果,通过人体关节点间的生理学连接,进行matplotlib 画图连线,渲染出来。此时可看到二维图像的识别效果。输出的二维关键点结果及双目立体匹配得到的该位置的深度信息将会输出到第三层“二维转三维”网络中,通过该层网络预测缺失的第三维度信息,最终经过手掌根部root点确定,标准化坐标处理等过程输出在三维空间中的21个手部关键点三维坐标,通过matplotlib中的3D画图库,在三维空间中进行生成。图4所示为测试集的输出效果图。

图4 范例实验结果
可以看到,在大部分约束条件下,该网络的识别准确率都比较可观,除了一些手部信息缺失过多的图像发生了关键点丢失,错乱等情况;同时也有部分图像关键点位置不明确,稍微扭曲。因为这些测试集来源都大相径庭,图像的尺寸差异巨大,输入到神经网络中的图像最终会被缩放,裁剪成同一尺寸,这些图像因为某些尺寸比例的关系,经过缩放后比例失调,例如手掌变宽,手指压长等扭曲现象,因此关键点发生了位置不明确的问题。
但在实时摄像头测试中,因为摄像头输入尺寸是每帧固定的,因此实时效果良好,整体实验效果可以基本满足手部追踪的效果,同时,及时在某帧中发现识别错误,关键点连线错乱等情况,在第三层中也会在预测过程中根据来自真实的三维数据进行修正,简单来说,就是尽管手部识别效果异常“扭曲”、“不似人形”也会因为第三层的训练数据是来自真实的“手”,因此会强行将异常的数据转换为正常数据,不会出现在三维重建中手部形象“畸形”的情况出现。
3.3 效率分析
由收集的测试数据集范例和公开测试集的实验结果来看,可以看到,该网络在应对各种复杂条件下的泛化能力比较高,即使实验场景包含可能的各种条件约束,成功实现手部位置分割的成功率达到了78%,同时二维关键点识别达到60%,这相对第一层中必然是更低的,因为首先网络需要分割出手部的位置图像,才能进一步对其进行关键点识别,虽然60%并不是十分优秀的结果,但足以证明该网络在应对复杂环境下的能力,它包含的是图像背景复杂,存在多个检测角色,光源复杂,图像存在关键位置遮挡等约束条件。而在三维重建中成功率达到了72%,即使在某帧中发现关键点识别错误、连线错乱等情况,在第三层也会根据来自真实的已训练三维数据进行修正。
进一步分析观察,简单背景(男性)的数据集中三层网络的准确率达到了90%、80%、86.7%,说明该网络的训练结果良好,应对实验室简单背景环境的识别性能相对较高;而简单背景(女性)中三层网络的识别准确率达到了90%、80%、90%,这样的对比结果也说明了,该网络应对异性的能力是相似的,同时这两组数据的相似性,也排除了简单背景(男性)中的实验结果的偶然性。因为这两组数据的背景不一样,足以验证该网络在简单背景下的识别能力。
4 结束语
本文提出了一种从普通RGB图像中预测三维空间手部姿态并实现实时手部追踪的神经网络。这个神经网络分为三层,首先通过一个神经网络进行手部位置的识别与分割,第二层网络结构基于上一层输入的二维手部分割裁剪后的手型图,这层的处理主要是实现识别二维图像中的21个手部骨骼关键点。第三层网络首先通过一个隐式的合成三维手部模型数据和三维手部数据集进行训练,训练后的网络模型就可以实现从二维的手部关键点中与前置训练的三维手部数据集进行匹配,估计缺失的第三维度信息,这样就可以获得手部骨骼关键点的三维数据,进而可以通过OpenGL 或者Matplotlib等进行实时三维重建,将二维的手部追踪进行升维。简而言之,整个神经网络的结构分为三层,最终的目的是从普通的RGB相机中实现三维的手部姿态估计。
