基于Hadoop 生态系统的工业实时数据及历史数据分析
2020-12-22刘昇鲁延灵王海峰周洋
刘昇,鲁延灵,王海峰,周洋
(1.广东中烟工业有限责任公司韶关卷烟厂,广东 韶关 512026;2.北京航天拓扑高科技有限责任公司,北京 100176)
在传统的烟草行业中,生产的历史数据存储在实时数据库或者关系型数据库中,无法满足业务对数据实时性的要求,并且这部分数据不利于进行其他的实时分析计算使用,导致制丝生产过程中的数据利用率不高。传统方式是将数据采集之后放至关系型数据库中存储,待业务需要使用时从关系型数据库中查询,这样会导致数据计算效率低下的问题,并且可能出现数据库连接数过多引起数据库异常。
1 传统的实时计算和历史计算
传统的烟草行业对数据的实时处理是先通过OPC 将数据采集上来,然后直接将数据存到关系型数据库中。业务的实时计算是直接从关系型数据库中取一段时间的数据或者取实时数据库中的数据进行聚合及实时的统计分析。这种方式不仅会造成其中任意一环出现问题都会导致数据丢失的问题,同时也增大了数据库的访问压力。传统的计算模式对于实时预警判定、实时计算特定有烟信号也都是较复杂的。
对数据的历史计算与实时计算类似,是直接从关系型数据库或者实时数据库中取出待计算的数据然后进行相应的计算分析,这同样会造成上面的问题。
制丝中控采集的原始数据都存储在Oracle 数据库中,当Oracle 数据库的数据量达到一定程度之后就会导致数据查询缓慢,所以不适合用来存储大量的数据。原始数据采集之后没有任何的中间件会导致所有的业务处理都压在一台服务器上,会导致服务器压力过大,易出现故障。难以实现对流数据实时、高效的聚合计算、统计计算。无法保证制丝中控内部处理数据的一致性以及与上层MES 系统的数据一致性。
2 基于Hadoop 生态系统的实时计算与历史计算
2.1 实现思想
通过中间件的技术运用可以在一定程度上防止数据丢失。通过数据采集程序采集生产过程中所有参数,存储这些参数实时数据,每个参数预先打上基本的标签,例如数据的有效性。对基本的有效数据进行实时的聚合计算、统计计算和预警判断;聚合时间可根据实际需要设置,实时的统计计算值根据需求进行配置,预警是根据八项预警规则进行的实时预警判断,以便在生产过程中能及时的发现问题并解决,从而提高工艺质量;对电机的电流、电机运行时间及阀门开关时间等数据展示趋势图,为预测性维护提供数据支撑;记录在生产过程中的关键性按钮操作以及参数标准的修改情况,以便发现较优的生产批次的生产情况,为后续的生产提供可靠的依据。
本文采用的消息中间件Kafka;分布式非关系型数据库Hbase;分布式文件系统HDFS 为Hbase 提供底层的存储服务;实时的缓存数据库Redis;Spark 进行离线数据分析。Kafka是一种高吞吐量的分布式发布订阅消息系统;分布式文件系统HDFS 是一个高度容错性、文件分块存储、适合部署在廉价的机器上、提供高吞吐量数据访问的系统;Hbase 在Hadoop 生态系统中也是不可或缺的,它是一个分布式的数据库,Hbase 底层存储依赖的是分布式Hadoop 的HDFS 文件系统,由HDFS 文件系统提供可靠保障;Redis 是一个key-value存储系统。Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了主从同步,由于Redis 是存储在内存中的,所以Redis 是一个实时数据库。
使用多个采集源,来保证单一采集源出现问题系统还能正常采集数据,采集后的数据发送至Kafka 中;业务使用数据直接从Kafka 中进行获取,这样就可以保证多个业务使用的数据源相同并且不会出现差异;实时计算业务获取到Kafka中的实时数据之后通过Redis 做实时的缓存,然后来做实时的数据处理以此得到准确的实时数据推送给页面展示给用户。历史数据存储在Hbase 中,Hbase 的访问速度是非常高的,这样运用历史数据进行数据分析的速度能得到很大的提升。
2.2 实时计算
实时计算的数据流向图如图1。
为了避免传统实时计算方式的弊端,所以扩展使用多个数据源,数采软件从数据源获取数据之后缓存在当前的程序中,经过初步的分类之后发送至分布式消息中间件Kafka 中。实时计算程序从Kafka 中获取到数据之后进行实时的分析计算,并且将数据缓存至Redis 中,待达到聚合条件之后进行聚合计算、预警判定。计算完成之后的数据同样放回Redis 中,由实时的推送程序获取后推送给页面进行展示。
实时的统计过程控制主要用于分析生产过程和评估生产状况,针对异常的状况,发现后能及时的采取措施来让过程保持稳定,这样能最大程度的保证产品质量。控制图则是其中最有效的一种工具,是统计过程控制的技术基础。控制图是指利用概率统计的原理在普通方格坐标纸上,通过计算画出两条控制线和一条中心线,横轴作为时间轴,把所有按规定的时间顺序所得的样件的数值,依次描绘在坐标图上面,并依次将相邻两个点用直线连接起来。如下图所示,以时间为横坐标,纵坐标为产品质量特性值或样本统计量,中心线记为 CL(Cnotorl Limit),两条控制界限使用虚线表示,在中心线上面的控制界限线为上控制线,记为 UCL(upper control Limit);在中心线下面的控制界限线为下控制线,记为 LCL(Lower Contorl Limit)。
控制图的设计原理主要体现在如下的三个方面:
(1)正态性假定。企业中的任何生产过程,总会存在一定程度的波动。当没有异常特性原因时,这些波动则主要来自于5M1E(即人、机器、材料、方法、测量和环境)的微小的普通变化,从而造成一定程度上的随机误差。此时,产品的质量特性值服从或近似服从正态分布,该假定就称之为正态假定。在此假定基础下,才可以使用正态分布的规律特征来建模。
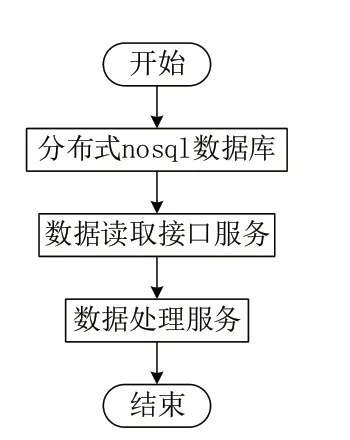
(2)3σ 准则。在正态性假定成立的前提下,距分布中心μ 左右两侧各为3σ(即±3σ)的范围内所含面积为99.73%。如果生产过程只受随机普通原因的影响,则该过程的产品质量特性数据就会有99.73%的数值会落在这个范围内,即:P{μ-3σ (3)小概率原理。小概率原理的定义即认为小概率事件一般是不会发生的。由 3σ 准则知当 X 服从正态分布 N(μ,σ2)时,过程的产品质量特性值落在控制界限之外的概率只有0.27%。即:1-P{μ-3σ 因此,认为没有特殊的异常原因发生的情况下,X 一般不会超出操作人员所定义的控制界限3σ。 历史计算的数据流向图如图2。 图1 图2 历史计算的数据来源于非关系型数据库Hbase,Hbase具有非常高的吞吐量,可以节省不少的查询时间,并能跟Flink、Spark 这样的计算引擎完美结合,使得数据分析变得更容易。 通过对比分析生产过程中关键性操作的记录分析出生产问题的原因;通过历史生产的批次内参数不同的权重计算出相同牌号的批次得分情况,从而分析出某牌号的最佳生产批次,在下一次生产相同牌号的批次时给与指导性建议;通过电机的运行情况及电流等参数分析出电机是否正常;通过关键性的参数及温湿度等情况预测出口水分等。 本文通过对比Hadoop 生态系统与传统计算模式在工业实时数据分析、历史数据分析中的应用,不仅解决了传统方式的单点故障问题还解决了传统方式无法做到的实时计算、离线分析等。这为Hadoop 生态系统在工业大数据中的应用提供了一种思路,方便了后续进行诊断烟草制造设备故障及预测性维护,这将极大提高烟草行业的制造水平。2.3 历史计算

3 结语
