基于演化博弈论的高校内控成效分析与策略优化
2020-11-19蒋欣然
蒋欣然
(北京信息科技大学 财务处,北京 100192)
0 引言
近年来,博弈论作为有效的经济学分析工具,被广泛应用于多个学科领域的内控研究。潘小珍[1]分析了医院财务部门和内控部门的博弈关系,提出了加强内控管理、调动积极性、细化预算、完善内审制度的建议;陈宇虹[2]分析了董事会内部控制的强弱、管理层是否舞弊、审计师审计三者之间的博弈,发现了董事会选择强、弱内部控制的不同的前提条件;雷颜行[3]借助演化博弈理论,阐述了企业内部控制体系持续改进的过程,并分析了企业内部控制体系改进的诸多类型和不同阶段性特征。
但基于博弈论对高校内部控制的研究尚且不多。赵乃璞[4]结合教育行业特殊制度背景,研究了高校管理层与审计部门之间的博弈行为;朱丽丽等[5]通过建立演化博弈模型,分析了不同条件下的稳定均衡点,建议在预算控制中公开预算指标、设置专岗、及时跟踪及事中控制;吴乐[6]将ERP管理系统和高校内部控制结合起来,假设博弈模型,提出优化高校内控结构、提升高校从业人员素质的策略;钟富胜[7]等构建高校和监管部门的博弈模型,发现了影响检查行为的4个因素,并对此进行了相应的机制设计。
从上述文献可知,目前基于博弈论的内部控制研究,主要是通过支付矩阵、博弈树和群体演化方程对群体开展博弈研究,其局限性主要表现在两方面:一是没有综合考虑内控管理力度对工作效率的影响以及舞弊收益、惩罚收益与内控力度三者之间的耦合关系,由于对调控力度的影响因素考虑较为粗泛,无法发掘并掌握内控过程的深层规律、进一步建立更细化和优化的动态调控策略;二是只关注调控的最终收敛状态,没有考虑调控收敛过程的速度即调控效果的时效性,亦没有考虑动态内控力度对群体演化进程的影响。这些局限性的存在,会使得管理人员在内部控制实施过程中,无法收获理想的短期和长期效果。
本文以高校全体课题组为研究对象,以遵循规范操作为内控目标开展研究。综合考虑内控管理力度对工作效率的影响以及舞弊收益、惩罚收益与内控力度三者之间的关系,基于演化博弈论建立较为精细的内控模型,针对长期的演化收敛特性与短期的演化成效问题,分别从静态内控策略和动态内控策略对调控的效果进行深入的分析。同时考虑调控的时间效应,在全局调控时间最优的约束下,探索动态内控的最速调控条件,并证明其具有全域收敛性。通过理论上的对比分析,进一步总结出动态内控策略与静态内控策略在高校内控建设过程中不同阶段的适用情况。
1 高校内控模型
将全校内部各个课题组视为群体内的个体,并将其视作内控对象的基本单位,其博弈策略集合为{规范操作,违规操作},任取两个课题组T1、T2进行博弈。由于博弈双方的可置换性,故此博弈为对称博弈,博弈支付矩阵如表1所示。
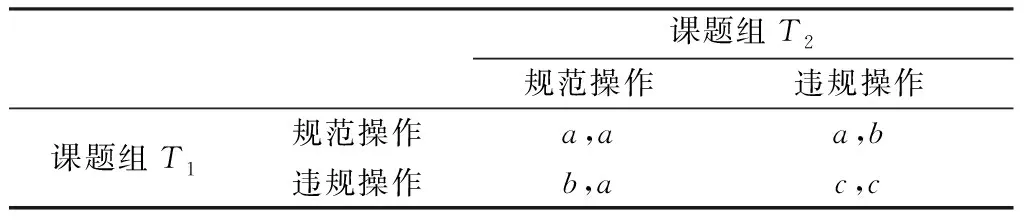
表1 课题组T1、T2博弈支付矩阵
表中:a为支付矩阵中博弈双方T1、T2均按规范进行正常研究工作时获得的收益。假设无内控时,执行规范操作获得的收益为Rw;若存在内控且内控力度为p,考虑到内控所附加的管理流程对研究工作效率的影响且影响系数为r,则a可表达为
a=Rw/(1+rp)
(1)
由于内控力度p越大,则防范和发现违规操作的可能性就越大,故而p可等效为防范和发现违规操作的可能性,定义其范围为[0,1]。
b为支付矩阵中博弈双方T1、T2其中一方为获得额外利益而进行了违规操作获得的最后收益,其影响因素包括:
①正常工作的收益a,即Rw/(1+rp);
②违规操作获得的额外收益Rf。考虑到内控力度p,则由于内控的预防效果,使得违规操作实际获得的额外收益衰减为(1-p)Rf;
③违规操作被查处受到的惩罚。此惩罚与违规操作获得的额外收益(1-p)Rf成正比,与内控力度p成正比,同时还与惩罚力度m(m>1)成正比。故b可表达为
b=Rw/(1+rp)+(1-p)Rf-mp(1-p)Rf
(2)
c为支付矩阵中博弈双方T1、T2均为获得额外利益而违规操作时获得的收益,其影响因素包括:
①正常工作的收益a,即Rw/(1+rp);
②违规操作获得的额外实际收益(1-p)Rf;
③违规操作被查处受到的惩罚。由于是群体违规,因此惩罚会加重。设加重系数为β,则β>1,故c可表达为
c=Rw/(1+rp)+(1-p)Rf-βmp(1-p)Rf
(3)
设全校课题组中选择规范操作的群体比例为x,违规操作的群体比例为1-x,则规范操作课题组的期望收益U1和违规操作课题组的期望收益U2分别为
U1=xa+(1-x)a=a
(4)
U2=xb+(1-x)c
(5)
全校课题组的平均收益为
(6)
全校内部各个课题组在博弈的过程中为获得更多收益,会不断学习其他课题组更优的策略,从而使得群体比例发生演化。规范操作的群体或违规操作的群体的增长率不仅取决于群体当前所占比例,也取决于本群体的相对收益状况。对于规范操作的群体,其增长动力学方程可表示为
(7)
此亦为对称演化博弈的复制动态方程。将式(1)~(6)代入式(7)可得
(βmp-1)(1-p)Rf)≜F(x)
(8)
2 静态内控策略分析
2.1 特殊内控
当p=0时,表示完全无内控,此时违规操作能获得额外收益而不受到惩罚。方程(8)退化为
(9)
由式(9)可知,x有2个均衡点:0和1,其相位图如图1所示。由图1可知,对于x的任意初始值(x≠0和1),其增长率均小于0,x负增长,故稳定均衡点为0。
当p=1时,表示绝对内控,式(8)变为
(10)
由式(1)~(3)可知,此时
a=b=c=Rw/(1+r)
(11)
此时绝对内控预防了所有可能的违规操作漏洞,即使有心违规也无法进行违规。所有群体均按规范进行正常研究工作,所有课题组的收益均相同,无额外收益产生驱动力。
2.2 一般内控
当内控力度p不为0和1时,由式(8)可知x有3个均衡点:0,1,(βmp-1)/((β-1)mp)。由于全校课题组选择规范操作的群体比例为x的取值范围为[0,1],故只有当(βmp-1)/((β-1)mp)∈[0,1]时,此均衡点才有意义。3个均衡点处的导数分别为:
F′(0)=(βmp-1)(1-p)Rf
(12)
F′(1)=(1-mp)(1-p)Rf
(13)
(14)
当(βmp-1)/((β-1)mp)∈(0,1)时,即mp<1<βmp时,x=0和x=1处的导数均大于0,而均衡点(βmp-1)/((β-1)mp)处的导数小于0,其相位图如图2(a)所示(图中所用参数为满足上述约束条件的任一取值,下同)。由图可知,当x<(βmp-1)/((β-1)mp)时,群体演化的增长率均大于0,当x>(βmp-1)/((β-1)mp)时,增长率小于0。故(βmp-1)/((β-1)mp)为稳定均衡点,而x=0、1为非稳定均衡点。
当(βmp-1)/((β-1)mp)=1,即mp=1时,F(x)在x=1处有重均衡点,x=0处的导数大于0,x=1处的导数等于0,其相位图如图2(b)所示。由图可知,当0 当(βmp-1)/((β-1)mp)=0,即βmp=1时,即F(x)在x=0处有重均衡点,x=0处的导数等于0,x=1处的导数大于0,其相位图如图2(c)所示。由图可知当0 当(βmp-1)/((β-1)mp)>1时,即1 当(βmp-1)/((β-1)mp)<0时,即mp<βmp<1时,x=0处的导数均小于0,x=1处的导数大于0,其相位图如图2(e)所示。由图可知,当0 综上所述,对7种情况下的稳定均衡点进行整理,可得到表2所示结果。 由表2可知,只有满足1≤mp<βmp的约束条件,才可使全校课题组选择规范操作的群体比例收敛到x=1的稳定均衡点,即让全体课题组向着规范操作演化。此结论也表明,收敛性的保障因素由“务虚”和“务实”两方面共同构成:“务虚”方面为对个体的惩罚加重系数m,即是一种预先的警示和威慑;“务实”方面为内控力度p,即为实际开展的内控管理工作。m的设定可视为零成本,因此,在一定条件下,可适当增大务虚因子m,以减少内控力度p,即可减小内控管理工作的成本投入。但过大的惩罚加重系数m又可能会造成矫枉过正的现象,对于某些非故意违规人员的惩罚过重而失去改过的机会,使得内控制度得不到受控人员支持而无法推行。因此,需要根据具体的实际工作情况,平衡好“务虚”和“务实”二者之间的关系。 静态内控策略主要是针对群体的收敛性,确保在特定条件下使规范操作的群体比例最终收敛到100%,但对于收敛过程所需要的时间并非最优。如何在最短时间内使内部控制活动收到显著成效,在有限的时间内更快速地解决问题,需要开展动态内控策略研究。 为了达到上述时间最短的优化目标,应在群体演化的每个发展阶段都采用使群体比例演化速率最快的内控力度,需要根据群体的演化进程调节适当的内控力度p。由式(8)对内控防范的力度p进行偏导可得: x(1-β)mRf+βmRf+Rf) (15) (16) (17) p*即为在规范群体比例为x的状态下使演化速率F达极大值的最优内控力度,遵照此式动态调整内控策略即为最速内控策略。 将时间最优内控力度p*代入式(8)中,整理化简后可得 F(x)=x(1-x)(1-p)Rf((x+β(1-x))× m-1)/2 (18) 因(x+β(1-x))m-1>(x+1-x)m-1=m-1>0,且x、1-x、1-p、Rf均大于0,故式(18)中演化速率F恒大于0,即代表x始终朝着正方向增长,最终能够使规范操作的群体比例x收敛到1。这表明,以时间最优为目标的动态内控策略是一种确保规范群体比例演化收敛到1的调控方法。 将式(17)等号两边乘上m,可得 (19) 根据表2,由式(19)可知,以最速为目标的内控力度,若不跟随群体演变状态而动态变化,即仅为了在最初始时的短期内速度最优,并不一定能保证收敛到x=1的稳定均衡点。例如,取惩罚加重系数β=10,惩罚力度m=1.1,违规操作获得的额外收益Rf=4,在初始规范操作的群体比例x0=0条件下,通过式(17)可知,演化速率最优的初始内控力度p0=0.545。当p0保持不变时,退化为静态内控,即有mp0<1<βmp0;同时由表2可知,在此约束条件下稳定均衡点无法收敛到1,只能收敛到(βmp0-1)/((β-1)mp0)=0.93。 若取m≥2,则无论x、β为何值,式(18)均大于1,即mp*恒大于1。若此时取p0=p*,且p0保持不变,则能使初始演化速率F0最大,并使稳定均衡点能够收敛到1。但此情况下,演化速率F不是全阶段最快。 若采用动态内控的方式,则模型由一维调控流形变为二维调控流形(p与x共同动态决定演化速率F),如图3(a)所示,可使演化速率F在整个演化过程中均是最大值,即演化的全阶段均为最快。同时,图3(b)为最速动态内控策略下的F-x相位图,由图可知x最终可收敛到1。图3(c)为p*随x的变化关系,由图可知,在x向着1收敛的进程中,内控力度会变得越来越大,这意味着需要付出的内控成本增高。由于此时的群体违规现象并不严重(违规群体的比例较小),根据式(17)可知,x(1-β)+β≈1,故而此时调节群体违规加重系数为β的作用并不显著,但增大惩罚力度m可一定程度上抑制这种内控力度与成本增加的趋势。而由式(8)可得 (20) 易知在0 本文以高校课题组的规范操作为内控目标,综合考虑内控力度、舞弊收益、惩罚收益、工作效率等多个因素的关系,基于演化博弈论建立内控模型,分别提出静态和动态内控策略。静态内控在设定初始内控力度后,不再对内控力度进行调节,其优点是能够免去对群体状态持续跟踪并调整内控强度的环节,在很大程度上节约了内控执行的各项成本。动态内控在内部控制的整个过程中,持续监控群体状态,并及时调整内控强度,其优点是能够细致地掌握内控动态,使内控力度始终处于最优状态,使规范操作的群体比例始终保持最快的演化速率,并最终收敛到稳定的理想均衡点。无论动态内控还是静态内控,适当地“务虚”,调整惩罚加重系数m,不但能保障规范操作的群体比例演化收敛到1,同时也可压制内控成本并加速群体的演化速度。因此,平衡好内控过程中“务虚”与“务实”的关系,是解决长期的演化收敛特性与短期演化成效问题的关键因素。 高校内部控制在选择内控策略时,应根据不同情况进行选择。在起步阶段,内控人员的业务尚不熟练、人员配备尚未齐全,此时可采用操作简单的静态内控策略,尤其当设定了针对个体的惩罚加重系数m≥2,可采用最速初始内控力度,以便短期内收到显著成效。在高校内控制度逐渐成熟,单一的静态内控已无法满足高校这个复杂的系统运转时,应采取动态内部控制,使演化速率在整个演化的全阶段均为最快,并最终实现群体的完全正向转化,达到预期理想效果。只有在实践中在不同阶段选择不同的内控策略,才能保证高校各项工作规范有序地进行,从而真正建立起高效运行、有效制衡、权责一致、稳健控制的内部控制体系,为高校的发展提供有力的支持。3 动态内控策略分析
3.1 最速内控策略
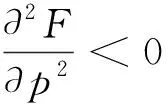
3.2 最速内控策略下的收敛性分析
4 结束语
