多语种网站平行语料采集与对齐研究
2020-11-16刘佳雨程南昌
刘佳雨 程南昌

摘要:丰富的平行语料库对提升机器翻译准确度意义重大,然而目前研究中缺乏有效的平行语料获取方法,本文提出一种从多语种网站中自动获取平行语料的方法,并且通过6个多语种网站的平行语料采集和对齐研究,验证通过多语种网站获取大规模平行语料具有较高的可行性,这说明通过多语种网站获取大规模平行语料具有较高的可行性。
关键词:多语种;新闻网站;平行语料;篇章对齐;机器翻译
中图分类号:TP391.2 文献标识码:A 文章编号:1007-9416(2020)09-0214-04
0 引言
统计机器翻译通常需要大规模的平行语料来不断提高翻译的准确度,因此语料库的规模与持续扩充是提高机器翻译质量的重要因素。平行语料的人工标注难度很大,特别是小语种语料,而互联网上存在着大量多语平行语料资源,并且这些语料是持续增长的。如何通过网络爬虫技术和双语自动对齐技术从多语种网站采集并对齐语料,在机器翻译领域是一件值得研究的事。
1 相关研究
1.1 机器翻译的发展
Koehn[1]将机器翻译的过程定义为计算机自动将一种语言转化成具有相同意义的其他语言,机器翻译已经逐渐成为了互联网信息服务中不可或缺的一环。朱杰[2]指出人们普遍认为基于规则的方法和基于语料库的方法是机器翻译最常用的两大类方法。随着研究的深入,基于规则的方法逐渐暴露出质量低,成本高等缺点,基于语料库的方法开始流行。基于语料库的方法又可分为基于统计和基于实例两种,冯志伟[3]提到这两种方法都需要将语料库作为翻译训练的来源,通过大量的语料统计来进行翻译学习的数据获取。但在统计翻译模型面世很长一段时间内,语料的匮乏和缺失使得这种机器翻译的人工成本增高。之后通过基于序列的递归神经网络自动获取并记录词汇特征的方法出现,机器翻译在深度学习的发展中取得了突破性进展。
1.2 平行语料库
机器翻译相关的语料库有平行语料、多语语料、可比语料这三种。平行语料指使用不同语言撰写且存在对应翻译关系的文本数据集。肖维青[4]研究发现双语平行语料库在机器翻译应用中的作用越来越重要。目前用于机器翻译的平行语料主要为多语或双语平行句对。语料的规模影响着机器翻译的质量,另一个影响机器翻译质量的语料因素是语料的纯净度。邵健[5]将建立平行语料库的方法总结为两种:一是从数据库或权威文档中挖掘语料,二是从双语网站获取并整理生成平行语料。平行语料库的建立主要是通过对已有数据库的改造与处理,在权威的多语种文献中提取可作为平行语料的语句。此外,随着双语网站的不断增多,从互联网获取平行语料成为了语料扩充的重要渠道。
1.3 语料对齐
王斌[6]将语料对齐定义为确定源文本和目标文本是否互为翻译关系的过程。对于获取的原始语料存在噪音的问题,因为不能直接使用在机器翻译的模型训练中,所以需要通过篇章对齐等技术的处理,目前对齐主要思路是根据多语种语料间句子的特征寻找匹配度最高的句子,通过句子长度,词汇信息等因素来匹配最合适的句子。
2 实验过程
2.1 主要思路
选择主流官方媒体人民网,中国青年网,外交部官方网站等拥有多语种的网站作为采集目标,官方新闻网站在不同语种频道发布的新闻主要分为独立编辑新闻和翻译汉语新闻,根据需求进行篇章对齐的是后者。通过网页代码制定抓取规则,使用数据采集系统分别对上述网站的新闻进行抓取,分别选取其汉语、英语、日语、韩语、法语、俄语等多个不同语种频道的新闻。抓取内容包括标题布时间、内容等容易进行匹配的特征。
2.2 互联网平行语料调研
目前互联网上的多语种平行语料主要有精准翻译语料、双语词条语料、多语种新闻网站平行语料。
精准翻译语料以双语词条语料多存在于网络词典中。词典语料的优点对齐精度最高,主要是对齐到词汇一级,但针对网络词典句子级采集有难度,而且例句之间有重复性,通过双语词典获取的通常是一对多关系,其语料来源为已有实体词典,更新频率慢。
双语词条语料主要是发布的双语对照新闻,以外交部发言人办公室官方微信公众号为例,在发布的例行记者发布会内容中为一对一翻译的双语新闻,这种平行语料质量高,可以直接作为机器翻译的语料,但是这种平行语料较少且大部分只有中英对照,数据缺乏规模和普遍性。
多语种新闻网站平行语料是本次实验所探究采集的语料,在国家级政府机构的新闻网站会分为不同的语种频道,一些新闻报道会在间隔较短的时间内以不同语言发布在对应网站。这些语料虽然不是精确到一对一翻译,但能够从相同事件的文本中获取机器翻译语料,同时数据每天更新,可以不断丰富平行语料库。
2.3 平行采集
使用爬虫技术对选择的多语种网站进行抓取,数据从互联网采集到本地之后,将按照统一的标准进行数据分类,以.txt的格式存储在对应的文件夹中,通过设置对应的路径方便篇章对齐中文本数据的选取。
2.4 篇章对齐
对采集的语料进行分类后开始篇章对齐处理。如果篇章处理后发现网站的不同语种新闻存在较高的相似度,就可以将这些语料用于机器翻译的学习中。在篇章对齐的实现过程中主要接入百度通用翻译API,在调入接口的过程中设置自动识别语言,同时设置发送字符的换行符便于一次请求中翻译多段文本。之前已经对采集到的语料按照网站名称和语种进行了分类,因此在篇章对齐的过程中只需要选中需要進行对齐操作的文件夹,通过采集新闻标题中的时间进行匹配,设置好相似度即可。设置相似度的目的是为了根据需求来调控所需语料的精确度,同时也为了验证选择的网站在多语种频道发布的新闻相关程度。
2.5 对齐质量分析
采集对象主要是多语种网站,第一阶段实现篇对篇对齐。第二阶段开始考虑句子,词汇。根据不同的相似度对采集的文本进行篇章对齐,对齐后的多语种文本以其中第一篇新闻标题为名称归类于同一文件夹,同时进行汉语翻译,用于判断对齐质量。篇章对齐后利用翻译后的文本对比判断多语种的新闻内容关键词是否相关。在本次实验中主要确定观察篇章对齐后新闻文本是否满足作为双语语料的基本条件,具体的判断标准分为以下几个层次:(1)文章内容大致相同,逐句对应程度高;(2)文章内容不同,但是主题相对应;(3)文章内容与主题不相同,其中只有几个关键词可对应。
3 实验结果分析
3.1 数据采集结果
本次实验使用正则采集规则,从互联网中采集到人民网、外交部官网、新华网、国际在线、中国青年网、中国网六个网站的不同语种频道(主要为英、法、德、俄、日、韩)共1987条新闻数据。每条新闻为单独的一个.txt文件,并按照来源、语种和时间进行了分类处理。
3.2 篇章对齐结果
对收集到的语料进行自动篇章对齐,选取2019年9月1日-2019年10月20日的新闻文本为对齐对象,通过相似比得到不同的对齐结果,从而分析不同网站多语频道的文本对齐程度。先通过人工翻译将相似文章进行人工对齐,然后导入软件进行自动对齐,通过比较人工和软件的篇章对齐结果,评测多语种网站是否具有作为平行语料的资质。
3.2.1 人民网对齐结果分析
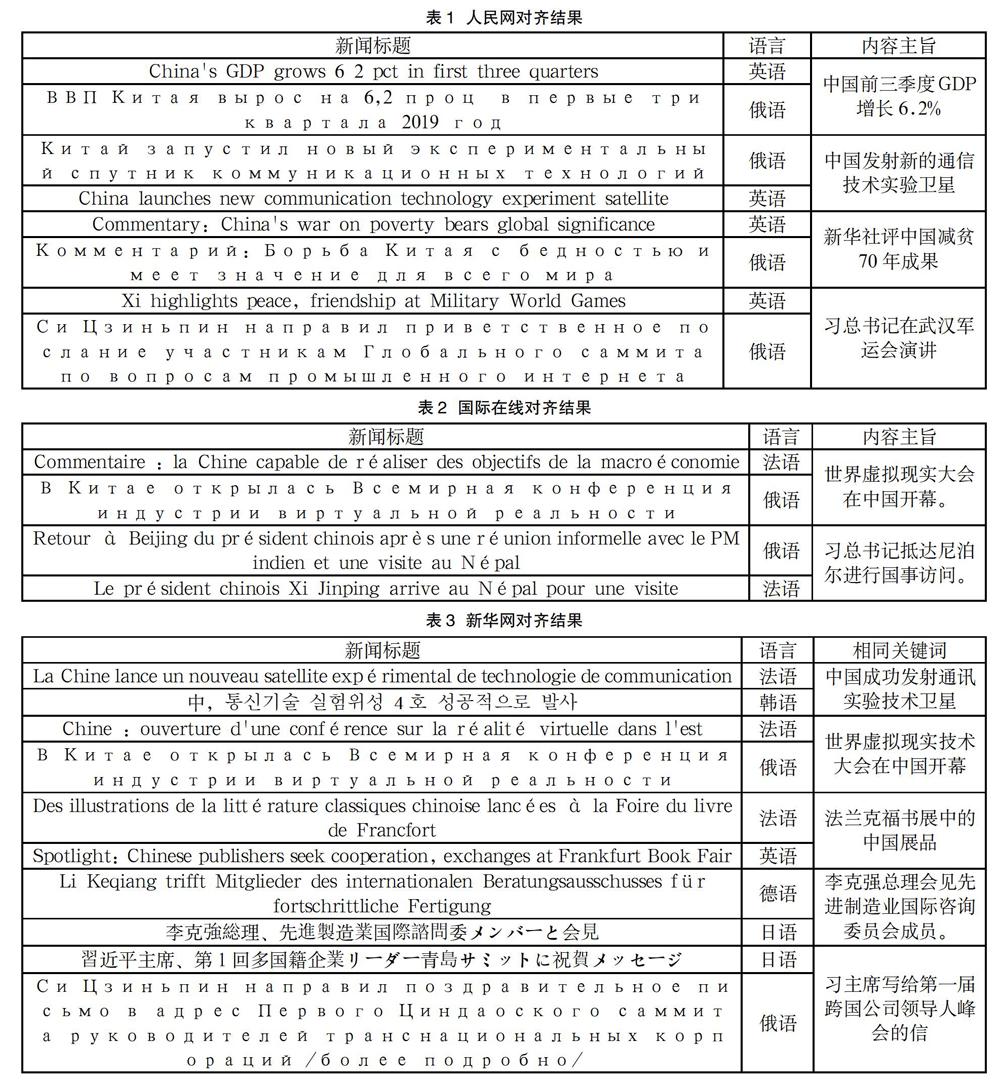
人民网采集数量如下:德语30篇、法语62篇、俄语85篇、韩语91篇、日语10篇、英语79篇。对人民网的新闻语料进行人工对齐,共计有11项新闻语料使用不同语种陈述相同事情,在相似度0.9的情况下进行篇章对齐,结果显示在对齐的17项主题中,有4项主题与文本内容一致,其余13项均为关键词相同,与人工比对结果相比对齊效果较好,作为平行语料具有参考价值,文本对齐结果如表1所示。
3.2.2 外交部官网对齐结果分析
外交部官网采集数量如下:法语16篇、英语15篇、截止采集日期,外交部官网俄语频道2018年3月份后无更新。人工对齐4篇相似主题新闻文章,在相似度比为0.9的情况下进行自动对齐结果为4篇同语种文章对齐,通过观察发现原因是因为外交部官方网站采集的语料较少,无法覆盖自动篇章对齐所需的数据量。但由于主要内容针对的新闻方向是外交与国际,采集结果文本多以外交新闻为主,因此关键词匹配度较高。
3.2.3 国际在线对齐结果分析
国际在线采集数量如下:德语26篇、法语37篇、俄语50篇、英语40篇。国际在线新闻文本人工对齐共8篇,4个主题。在相似度对为0.9的情况下使用软件进行篇章对齐结果在9项对齐结果中有2项主题和文本内容一致,其余7项均为部分关键词相同,新闻采集和初步篇章对齐结果显示国际在线多语种新闻文本可作为平行语料。文本内容对齐结果如表2所示。
3.2.4 新华网对齐结果分析
新华网共采集新闻348篇,采集语料数量如下:德语51篇、法语50篇、俄语51篇、韩语64篇、日语67篇、英语65篇。人工对齐结果为8个主题,共18篇文章在新闻内容上一致。对数据进行清洗后,在相似比为0.9的情况下对采集数据进行自动篇章对齐,在对篇章对齐结果进行数据清理后得到13项结果,其中5项对齐程度高新闻主题和内容相同,剩余8项为部分关键词相同。在篇章自动对齐结果中,新华网文本基本满足了多语种语料篇章对齐的要求,对齐结果质量较高,可以作为平行语料采用,具体对齐情况如表3所示。
3.2.5 中国青年网对齐结果分析
中国青年网共采集74篇,采集语料数量如下:法语20篇、俄语32篇、英语22篇。由于中国青年网部分网站运营出现问题,导致数据采集缺失。在后期人工对齐中,共有两项主题内容相同。通过软件进行自动篇章对齐,无准确结果,因此中国青年网不作为平行语料的采集对象。
3.2.6 中国网对齐结果分析
中国网共采集280篇,采集语料数量如下:德语44篇、法语60篇、俄语70篇、日语53篇、韩语54。人工对齐结果共有7项,16篇文本。使用软件进行自动篇章对齐结果一共有7项,其中2项主题内容相同,剩余5项为关键词对齐。综合对齐效果来看,中国网无论是从文章主题还是关键词的角度对齐数量少,因此不适合作为平行语料的数据采集库。
4 实验结果分析
本文通过对六个多语种网站(人民网、新华网、中国青年网、外交部官方网站、中国网、国际在线)的不同语言频道新闻进行采集和篇章对齐处理,得到以下结论:
(1)具备作为平行语料采集价值的多语种网站,其中人民网、新华网、外交部官网、国际在线这四个网站作为采集对象,通过篇章对齐后得到的文本对齐率高,自动对齐的文本较精准,可作为平行语料。另外两个网站由于更新问题,暂时还不具备作为多语种平行语料的价值。
(2)传统的平行语料大多来源自双语数据库,对拥有多语种频道的新闻网站而言,通过篇章对齐获得的平行语料相较传统数据库而言缺乏一定的精确性,但由于新闻需要每天更新,因此文本数据始终在增加,这样平行语料就会处于一直增加的状态,同时多语种网站提供了不同的语种组合,所以可以获得更多种语言的平行语料。下一步的工作主要是提高篇章对齐的准确度,从篇章对齐延伸至句子对齐,同时从具有平行语料价值的网站中获取更多的多语种文本。
参考文献
[1] Koehn P.Statistical machine translation[M].Cambridge:Cambridge University Press,2010.
[2] 朱杰,古明.基于语料库的机器翻译[J].现代交际,2019(17):100-101.
[3] 冯志伟.基于语料库的机器翻译系统[J].术语标准化与信息技术,2010(1):28-35.
[4] 肖维青.平行语料库与应用翻译研究[J].中国科技翻译,2007(3):25-28.
[5] 邵健,章成志.从互联网上自动获取领域平行语料[J].现代图书情报技术,2014(12):36-43.
[6] 王斌.汉英双语语料库自动对齐研究[D].北京:中国科学院研究生院(计算技术研究所),1999.
