面向岗位信息的分布式爬虫应用
2020-11-10冯成
冯 成
(贵州电子信息职业技术学院,贵州 凯里 556000)
1 岗位信息的需求
随着大数据时代的来临,信息的产生正呈指数形式增长,而传统岗位信息的获取方式过于单一,很难满足当前高校毕业生的求职需求。互联网中发布的岗位信息由多种元素组成,具有变动性大、时效性强、分布范围广等特点,虽然是学生获取就业岗位信息的有效渠道,但在高校依然存在就业信息不通畅的问题。为了提高就业信息使用率,文章利用分布式技术爬取招聘网站的相关招聘信息,通过算法抽取有用的数据信息,并存储到存储系统当中,通过信息分享平台将数据分享给全校学生使用[1-3]。
2 项目构建与实现
2.1 项目的构建
文章所需爬取的岗位信息数据来源于“前程无忧”网站,在项目的开发过程中使用了Scrapy框架完成指定数据的爬取,并将爬取到的数据保存到MySQL数据库当中。具体的开发流程如下所示。
第一步:在Windows的cmd命令提示符界面中进入代码存放目录,并在该目录下创建Scrapy工程名和模板名称。第二步:settings.py设置header代理头和Mysql连接参数的设置以及根据项目的需要设置相关反爬虫措施。第三步:items.py主要设置了需要爬取的字段内容,使用scrapy.Field()方法完成相关爬取字段的设定。第四步:piplines.py主要负责利用Python连接MySQL数据库,并自定义了MySQL数据插入方法insert_data(),用于将爬取到的内容放入到MySQL数据库当中。第五步:自定义爬取类Job,Job是爬虫的核心内容,主要负责页面的解析和数据爬取。
2.2 项目的实现
2.2.1 界面的分析
要爬取指定内容,需要到相应的网站访问填写相应的搜索关键词,文章当中的搜索关键词分别为地点:”全国”,全文:”Java”,其产生的URL如下:”https://search.51job.com/list/000000,000000,0000,00,9,99,Java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=”。
在URL中,Java表示搜索的岗位名称,其中,“..../list /000000 .....”中的000000表示全国,workyear表示工作年限,companysize表示公司的规模,providerSalary表示薪资水平。
2.2.2 详细信息的获取
信息的获取是本次应用的核心内容,文章使用了xpath库,定位获取“公司名称”“工作名称”“公司信息”“基本要求”“工作地点”等相关信息。具体的步骤如下。(1)设置编写的start_url的链接地址,用于获取招聘信息网页。(2)在parse方法中,主要处理两大部分内容:
第一部分为详情页的request,其主要是通过xpath定位到招聘信息列表,并使用for循环函数遍历该列表,获取招聘名称和详情页链接,之后将详情页链接发送给回调函数“detail_parse”处理。获取详情页的关键代码如下所示。
result_list=response.xpath("//div[@class=′dw_table′]/div")
for list in result_list:
#获取名称
name=list.xpath("./p/span/a/text()").get()
//获取链接地址
url=list.xpath("./p/span/a/@href").get()
第二部分主要工作是css选择器来提取数据以及判断是否存在下一页,如果存在下一页则将数据回调给parse处理。获取下一页的主要代码如下。
next_url = response.css(
′#resultList>div.dw_page>....>li:last-child>a::attr(href)′).extract_first());
调用parse_detaill方法,在该方法中使用response.xpath()方法获取要指定的爬取内容,如岗位名称、公司名称、薪水、岗位信息、福利待遇、公司规模、公司地址等内容,并将其发送给Items。详情页主要爬取代码如下。
jobname=list.xpath("./div[@class=′cn′]/h1/text()").get()
……
salary=list.xpath("./div[@class=′cn′]/strong/text()").get()
2.2.3 反爬虫措施
为了保护网站的资源和提高数据的安全性,限制爬虫措施已经广泛被使用在各大网站中,文章当中采用了反爬虫措施如下。(1)IP代理:通过IP动态代理的方式,避免网站侦测到真实的IP地址,防止了网站禁止本机IP的访问。(3)User-agent代理池:是一种有效的代理方式,能够有效地防止网站的侦测识别,将user-agent写入到settings文件中。
2.2.4 数据的存储
数据存储将极大地提高数据价值,文章将爬取数据存放到MySQL数据库当中,数据库的具体操作步骤如下。
(1)分别在settings和ITEM_PIPELINES文件中完成数据库的配置,具体的数据库连接配置如表1所示。
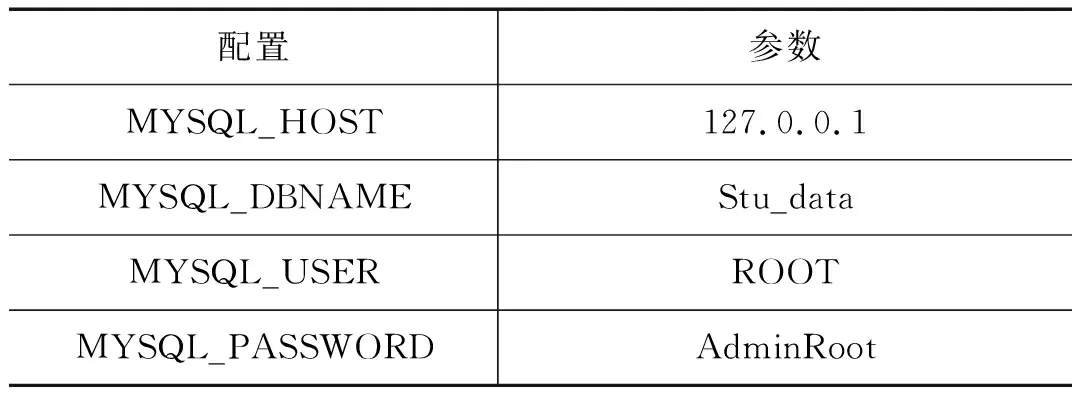
表1 数据库连接参数
(2)数据爬取完成之后,发送给pipeline的处理,主要完成的是数据库的连接和数据的插入,其中,在数据__init__(self, )时,完成指定数据库的连接,并使用process_item方法调用insert()方法完成数据的保存至数据库,存储部分内容如图1所示。insert插入数据的关键代码如下。
sql = "insert into java(jobname,.....,company_info) VALUES(%s,....,%s);"
params = (item[′jobname′],.....,item[′company_info′])
self.cursor.execute(sql, params)
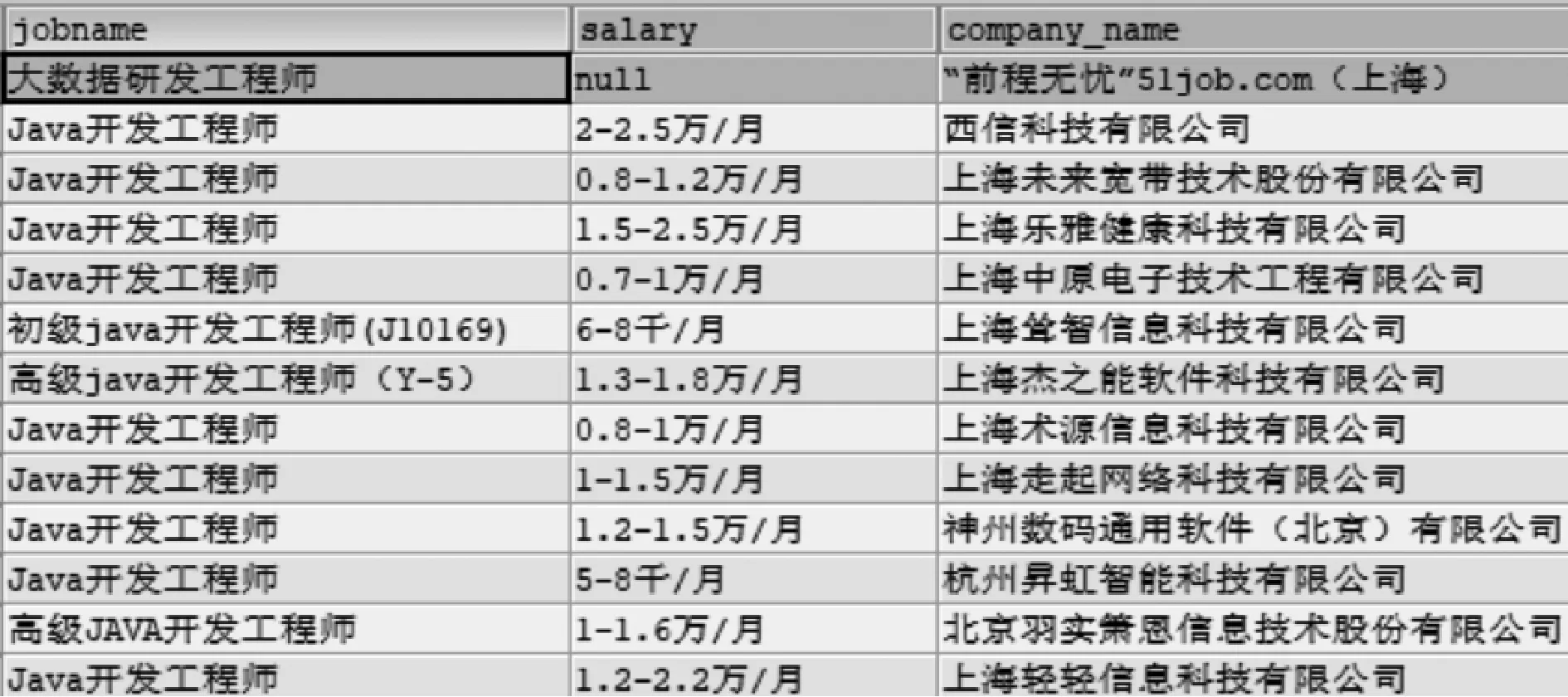
图1 爬取部分数据展示
3 结语
文章首先对分布式爬虫技术进行了介绍;其次,阐述了整个项目的构建过程;最后,介绍了项目的技术实现,实现数据爬取工作,并将数据存储到MySQL数据库当中,但是如何对数据进行处理分析、采用何种算法完成就业信息的预测,依旧是后期需要研究的重点内容。
