基于多模型融合的电动汽车行驶里程预测
2020-10-31翁灵隆覃雄臻杜玉峰高长斌
胡 杰,翁灵隆,覃雄臻,杜玉峰,高长斌
(1.武汉理工大学a.现代汽车零部件技术湖北省重点实验室,b.汽车零部件技术湖北省协同创新中心,武汉430070;2.新能源与智能网联车湖北工程技术研究中心,武汉430070;3.上汽通用五菱汽车股份有限公司,广西柳州545000)
0 引 言
电动汽车具有环保、节能的显著优势,但是电池技术尚未完善,影响着电动汽车的发展.对纯电动汽车行驶里程的准确预测,能有效解决用户的里程焦虑问题.因此,提高电动汽车行驶里程预测精度的研究具有重要的现实意义.电动汽车的行驶里程与电池端电压、整车和电机充放电电流、电池温度、车载耗能、电池循环次数、驾驶员行为、环境等因素有关[1].文献[2]考虑行驶路线的陡峭程度和驾驶行为特征,动态预测能量消耗预估续驶里程.文献[3]通过汽车能耗与负载的关系,提出基于不同载荷和驱动模式下的预测模型.文献[4]考虑道路网络拓扑结构和实时交通等计算平均能耗,提高预测精度.文献[5]对行驶里程与电池荷电状态(State of Charge,SOC)进行相关性分析,通过递推最小二乘法参数辨识进行预测.文献[6]提出粒子群算法(Particle Swarm Optimization, PSO)改进后的最小二乘法支持向量机(Least Square SVM,LSSVM)预测模型,以电池组使用天数等进行里程预测.文献[7]以端电压、电流等作为输入,基于改进的粒子群算法—径向基函数(PSO-RBF)模型进行里程预测.综上,现有研究主要以算法改进和增加影响因素提升预测精度.
本文针对现有回归算法在较短行驶片段预测精度低、较少见行驶片段相对误差高,引入滑动窗口重采样、样本同分布的方法解决样本不均匀问题,通过环境温度与电池健康状态分层耦合提升整体回归预测精度,提出将单点分类预测和片段回归预测融合,提高模型在较少见行驶片段预测效果,使用Stacking 模型将多种算法堆叠,实现精确的行驶里程预测.
1 里程预测方法
采集5 辆同型号且市面上正在使用的某款纯电动汽车,2018年1~12月在北京市内行驶过程中产生的数据,组成数据集,共计154万个样本,采样间隔为10 s.数据参数如表1所示.
1.1 问题分析
行驶里程是电动汽车从起始SOC 行驶到当前SOC 时所行驶的距离,行驶里程预测流程如图1 所示.数据集经预处理后,随机取出其1/5 行驶片段作为测试集,剩余4/5 的行驶片段在随机滑动窗口重采样增加数据量之后,根据行程中的样本量分成两个数据集,分别用于片段回归预测与单点分类预测;经过特征提取与模型选择后,进行stacking 模型融合及测试集验证,获得最佳预测模型.

表1 数据分类与说明Table 1 Data classification and description

图1 多模型融合行驶里程预测流程框图Fig.1 Multi model fusion mileage prediction
1.2 基于行程内样本量的双模型预测
数据集中每个行驶片段包含有效样本100~2 000 条不等,根据样本量的不同分别用片段回归和单点分类进行预测.
1.2.1 分层耦合片段回归预测
片段回归预测采用片段内不同行驶工况所占比例、片段SOC消耗量等相关特征,能够取得良好的预测结果.环境温度和电池健康状态(SOH)与电池荷电状态之间有较强的相关性,将两者分层耦合预测有助于提高片段回归预测的预测精度.
(1)温度分层.
电池的性能参数会随环境温度变化而变化,当环境温度降低时,电池容量会减小,电池内阻将增大,将影响电池的实际荷电状态.电池容量与环境温度的关系[8]为

式中:C为电池电容;T为环境温度;k1、k2、k3为常数.
电池容量减少和电池内阻增大都会降低电池电量的利用率,使电动汽车总行驶里程降低.若温度下降相同的值,由于低温下电解质溶液离子移动速度更慢,其内阻下降较高温时更明显.
(2)SOH分层.
电池SOH是电动汽车动力电池系统至关重要的性能指标,被称为电池健康、电池劣化程度等.电池SOH 包括:电池容量、内阻、自放电的健康程度等,将电池容量SOH定义式为

式中:CSOH为电池容量的健康程度;CT为在T时的额定容量;Ca为初始状态的额定电池容量.电池内阻SOH定义式为

式中:RSOH为电池内阻的健康程度;RT为在T时的电池内阻;Ra为初始电池内阻;Rz为寿命耗尽时的电池内阻.
电池电容、电阻的健康状态随着电池循环次数的增加存在明显地下降趋势.电池额定容量通常以循环次数1 000次为分界点,若循环次数超过分界点,电池容量将急剧下降.电池内阻与循环次数正相关,超过一定循环次数,内阻急剧增加.
1.2.2 单点分类预测
小样本量行驶片段采用片段预测方法会导致相对误差远大于大样本行驶片段,因此,采用单点分类预测,以累加每个样本点的预测值为该段行程的行驶里程.经过数据统一时间间隔处理后,行驶里程的差值在数据集中以0、0.1、0.2这3种形式出现,为常见的3分类预测.

式中:Mmile为行驶里程;k为该片段内点的个数;i为片段内某点;pi为该点行驶0.1 km的预测概率;qi为该点行驶0.2 km的预测概率.
1.2.3 双模型预测
k-Fold 交叉验证表明,在不同样本量的情况下,预测方法不同会导致相对误差存在较大的差异.图2为不同样本量下单点预测和片段预测的相对误差.

图2 不同预测方法相对误差关系Fig.2 Relative error diagram of different prediction methods
行驶片段内样本量较小时,单点预测平均相对误差低于片段预测;样本量较大时,则相反.片段信息中变化较大的数据(如速度、电流)在10 s内可能发生数次变化,难以用一个采集点表达;传感器也会有延迟、故障等.当片段内样本量过小时,异常信息的影响尤为明显,预测误差较大.单点预测是对每个样本点进行预测累加,对小样本片段更具鲁棒性,主要缺陷为耗时严重,并且存在一定的误差累计.以图2 中交点为界,在小样本量行程采用单点分类预测,大样本量行程采用片段回归预测,防止误差累积,降低异常干扰,提高预测精度.
2 数据预处理
车辆初始数据通过传感器收集,用无线传输,有受到各种异常因素影响产生异常数据的概率,如传感器故障,网络受天气、频道、端口等影响.表2 为存在异常数据的部分初始数据,包括采集间隔小于10 s,数值异常或重复的异常数据,以及缺失数据.

表2 2 号车部分初始数据Table 2 Partial initial data of vehicle 2
2.1 异常值处理
对异常数据采用删除处理,缺失值采用两种插值算法联合插值处理,通过均方根相对误差(RMSRE)指标对其评分,表3 为RMSRE 对各参数插值评分结果.

表3 不同插值处理的RMSRE 评分Table 3 RMSRE score of interpolation processing

式中:ERMSRE为插值结果RMSRE 评分;m为预测数据个数;j为某个数值缺失点;yj_pre为第j个数据的预测值;yj_real为第j个数据的真实值.
2.2 滑动窗口重采样
采用随机变步长滑动窗口重采样组建总训练集,解决某些片段数据不足的情况,原理如图3所示.
窗口约束为l~L(窗口总长),总训练集的子集形式为{xN,xN+1,…,xM} ,其中,xN为原训练集中的单条样本数据,N∈(a1,b1),M∈(a2,b2),M-N∈(l,L),即窗口上下界(N、M)都设置在不同预定区间内,同时约束窗口长度.初步采样完成后总训练集为

xNn等为各个滑动窗口内单条样本数据,Trans函数综合目标特征统计量(如特征均值、方差等),将训练子集T1,T2,…,Tn1中各特征的单点信息压缩为片段信息(如电流特征压缩为高功率用车比例、正常功率用车比例、制动能量回收比例等).压缩后为片段数据集X1,X2,…,最终构成1万条压缩数据的总片段训练集XTrain.总训练集xTrain、XTrain分别作为单点预测和片段预测数据库,提供足够数据量,有利于解决数据量不足、样本不均衡等问题.

图3 随机变步长滑动窗口重采样Fig.3 Resampling of sliding window with random variable step size
2.3 样本均衡
在实际行驶中,存在行驶里程数值分布差异,容易引起样本不均衡问题.为降低少见行程预测误差,使用样本同分布进行训练,达到降低相对误差的目的,即按测试集的样本量分布情况构造训练集,使两者的数据分布相同,同时采用上采样方式解决分类标签不均衡问题,提高单点预测精度.
3 特征与模型
3.1 特征工程
3.1.1 特征提取
(1)车辆运行特征.
车辆运行状况对行驶里程预测至关重要,从车辆总电流电压、电机电流电压、电池SOC 及电池温度可以提取车辆行驶能耗、负载能耗、动力电池能量状态,以及电池健康状态等特征.采用k-means对车辆行驶状态进行聚类,通过车辆总电压电流、电机电压电流进行聚类分析.k-means 以簇内稠密度和簇间离散度评估效果,其中,轮廓系数为常用评价指标,能够同时衡量样本与所在簇和其他簇中样本的相似度,取值范围为(-1,1),轮廓系数越接近1,相似度越高.图4为4分类时的轮廓系数图,图5为聚类散点图.可以看出,在聚类为4 分类时,每个簇的轮廓系数贡献值都较大,未出现负值或其中一簇完全低于平均值的情况,且每个簇在散点图上分类清晰,聚类效果极佳.
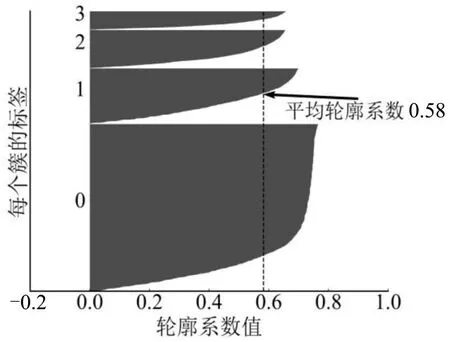
图4 每个簇的轮廓系数Fig.4 Contour coefficient map of each cluster

图5 车辆运行状态聚类散点图Fig.5 Clustering scatter plot of vehicle running status
(2)片段统计特征.
样本数据压缩为片段数据后,会产生一些片段信息.例如:片段行驶时间,片段内消耗SOC,片段内停车总时间等,可以通过统计学方法提取出相应的片段统计特征.其中,片段内消耗SOC及片段行驶时间与行驶里程具有较高相关度.
(3)信息类特征.
信息类特征时间、位置、车辆信息与电池信息,如月份、星期、早晚高峰时间、车辆编号、车辆位置、车辆电池充放电次数等数据,可以提取出环境温度、道路拥堵状况、车辆差异及电池SOH等特征.
3.1.2 特征选择
综合Filter和Wrapper特征选择方法进行特征选择,Filter 选择有互信息、方差选择、相关系数法等,其中,回归算法采用相关系数法计算特征与预测值之间的线性相关度,计算公式为

式中:Cov(X,Y)为特征集X、Y的协方差;xave和yave分别为两特征的平均值;xr、yr分别为两特征的第r个值;ρxy为两特征集的相关系数.相关系数越高,该特征与行驶里程线性相关度就越大.
分类算法特征集通过互信息法计算自变量与因变量之间的关系,可以计算出两者之间的共同信息,不同于线性相关度,该信息是考虑数据的分布,用于分类问题,计算公式为

式中:p(xr,yr)为特征集X、Y的联合概率分布函数;p(xr)、p(yr)分别为两特征集的边缘概率分布函数.特征构造中提取30个特征,初步选取相关度和互信息量较大的前15 项特征作为Filter 特征集Fa1、Fa2.在Filter 筛选基础上进行Wrapper 特征选择,按特征重要性顺序,先添后删进行包裹式特征选择,得到各算法平均相对误差最低,效果最佳的特征集合.
3.2 模型建立与选择
采用5-fold交叉验证所得RMSRE平均得分作为评价指标,将数据集随机分成5 等份,进行5 次训练,每次训练以其中1 份作为测试集,其余4 份为训练集,有效降低偶然性.LightGBM算法[9]是微软的开源GBDT 算法,其算法性能优越且具有较快运算速度及较小的内存要求.构建前文筛选的特征后,建立LightGBM 模型,并进行贝叶斯优化超参数调优,取得模型最佳预测效果.贝叶斯优化流程如图6所示,最初使用随机产生的初始点训练计算,通过高斯过程及AC 函数反复计算求解,最终得到最优模型.
除LightGBM 集成算法外,使用XGBoost、线性回归clf、弹性网络回归ENet等算法进行预测对比,图7 为特征筛选前、后,各算法的RMSRE 评分对比.
由图7 可知,LGB 算法评分最佳,将评分较好的LGB、XGB与差异性较大的Lasso、RF作为基模型,Ridge 作为元模型进行Stacking 模型融合.Stacking[10]是通过将各种算法融合的一种数据驱动预测方法,其原理如图8 所示,多种预测模型作为第一级预测模型,预测结果作为第二级预测模型的输入,在堆叠过程中,不断优化模型预测结果.
图9 为Stacking模型融合的学习曲线:实线表示针对训练数据集计算出来的分数,反映模型对于训练集拟合的准确性;虚线表示测试集交叉验证得分,最终测试集收敛在0.97附近,说明模型可以很好地拟合数据;通过Stacking融合预测的测试集RMSRE最终评分为0.035.

图6 贝叶斯优化Fig.6 Bayesian optimization

图7 各算法RMSRE 评分图Fig.7 RMSRE score graphs of different algorithms

图8 Stacking 模型原理Fig.8 Stacking model
图10 和图11 为测试集预测结果的绝对误差及相对误差散点图,其平均相对误差为1.71%,平均绝对误差为0.9 km.
图12 为行驶里程预测对比图,单片段回归预测的预测误差明显高于多模型融合预测,经过单点分类、片段回归和分层耦合的多模型预测方法能更好地拟合行驶里程曲线.预测结果显示,本文预测方法较传统预测方法具有更高的准确性.

图9 Stacking 算法模型学习曲线图Fig.9 Stacking model learning curve

图10 测试集绝对误差散点图Fig.10 Test set absolute error scatter plot

图11 测试集相对误差散点图Fig.11 Test set relative error scatter plot
4 结 论
通过多模型融合的方式实现行驶里程预测,将样本分层耦合思想引入回归预测中;结合单点分类与片段回归预测两种不同类别预测方法,克服各自缺陷,能够降低平均相对误差1.13%;采用Stacking 模型融合进一步降低RMSRE 误差评分12.5%,提高行驶里程预测精度;经测试集验证,平均相对误差为1.71%,RMSRE 评分0.035,表明本文提出的方法能有效降低预测误差,提升行驶里程预测准确度.后续研究将加入更多类型的车辆数据,使模型适应更多车型,增加模型的泛化能力.
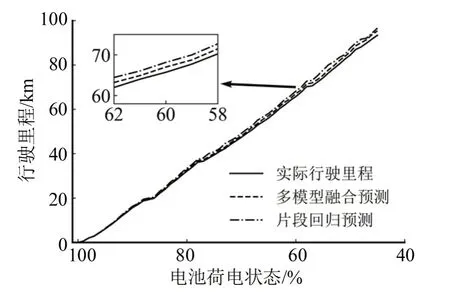
图12 行驶里程预测对比图Fig.12 Comparison chart of mileage prediction
