基于Householder矩阵和Butterworth滤波器组的反馈延迟网络人工混响
2020-10-30吴礼福陶明明申浩郭业才
吴礼福 陶明明 申浩 郭业才
0 引言
人工混响(artificial reverberation)是指人为地对原始声音信号进行处理,使其能够具有适当的混响效果[1-2].在音乐、广播、电视和电影制作过程中,人工混响是不可缺少的部分.混响处理方法可以采用数字人工混响方法或模拟技术,其中数字人工混响方法是利用电声学知识以数字信号处理手段来模拟混响效果[2].
数字人工混响方法主要有3种:一是反馈延迟网络(Feedback Delay Network,FDN),它将输入信号(干净无混响)延迟、滤波并根据参数化混响特性沿着多个路径反馈给前端,叠加后得到混响信号;二是卷积方法,它将输入信号与房间脉冲响应卷积得到混响信号;三是基于计算声学的方法,将输入信号模拟声能在几何模型中传播,从而得到混响信号[3].反馈延迟网络方法在音乐技术领域使用较多.计算声学方法通常可用于声学设计和场景分析.而卷积方法在实时实现方面非常困难,脉冲响应的计算很耗时.本文主要研究内容是反馈延迟网络.
1971年,反馈延迟网络首先由Gerzon提出用于人工混响[4],他指出单个反馈梳状滤波器质量很差,但是当交叉耦合时,使用几个反馈梳状滤波器效果会好很多.1996年,Jot等[5]提出了一种反馈延迟网络(FDN)方法来处理数字混响,将FDN方法发展到目前的应用水平.Jot等[5]提出的反馈延迟网络方法目前被认为是高质量人工混响的最佳选择之一,其中,正交反馈矩阵的选择是一个特别有趣的话题,它显著影响所获得的混响质量[6-8].1998年,Piiril等[9]已经提出了如何使用2个具有稍微不同参数的FDN或其他修改的梳状滤波器结构来产生非指数衰减的混响响应.2011年,Sana等[10]通过结合频率相关的墙壁吸收、信源和接收器的方向性进一步扩展了FDN概念.
2010年,Smith教授提出了反馈延迟网络的一种算法[11],它是基于Hadamard反馈矩阵和Butterworth滤波器的,混响程度很深,但是延迟线个数的选择有限制.2017年,美国苹果公司发布一个名为SoundSoup的应用程序,它是基于Householder反馈矩阵和单零点极点的滤波器,运算量小、处理时间短[12],但是需要提供混响室的具体长宽高和墙壁的吸声系数,通过Sabine公式来计算混响时间T60,无法精确设定子带的混响时间.
为了克服以上2种方法的缺点,本文研究了一种新的反馈延迟网络方法,它基于Householder反馈矩阵和Butterworth滤波器组,延迟线的个数选择相对自由,可以精确设定子带混响时间.
1 反馈延迟网络
图1所示是用于人工混响的反馈延迟网络,它是一个使用3条延迟线的反馈延迟网络的例子.x(n)表示输入信号(干净无混响),s1(n),s2(n),s3(n)是经过延迟线的信号,b1,b2,b3表示输入因子,c1,c2,c3表示输出因子,g1,g2,g3表示频带增益,q11等表示反馈矩阵的元素,y(n)则表示输出的混响信号.
对于N=3,图1所示FDN的关系式可以写成:
(1)
输出结果为
(2)
推广到N=n时,FDN的关系式可以表示为
(3)
(4)
或者,使用z变换,在频域中写为
S(z)=D(z)[GQS(z)+bX(z)],
(5)
Y(z)=cTS(z)+dX(z),
(6)
其中G=diag(g1,g2,…,gn)为增益组成的对角矩阵,Q=[qi,j]N×N为反馈矩阵,b=[b1,b2,…,bn]为输入因子组成的列向量,c=[c1,c2,…,cn]为输出因子组成的列向量,D(z)=diag(z-M1,z-M2,…,z-Mn)为延迟线组成的对角矩阵.
脉冲响应的后期混响部分理想情况下应该类似于指数衰减的随机噪声[13].一旦在无损的脉冲响应中听到平滑的噪声,就可以在每个频带中获得期望的混响时间,而噪声的平滑性受FDN反馈矩阵以及延迟线长度的影响.
1.1 延迟线
平均延迟线的长度通常粗略地等于混响环境下的平均自由程.平均自由程的定义为声波在传播并衰减的过程中,经过每两个界面之间的平均距离.平均自由程ρ近似为
ρ=4V/S,
(7)
其中V表示的是房间的体积,S表示房间的表面积.如果将每条延迟线视为平均自由程延迟,则可将延迟平均值设为平均自由程:
(8)
其中c表示声速,T表示采样周期.给定ρ的值,选择一组具有预设的最小间距素数,其平均值尽可能接近所需值[10 ].
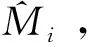
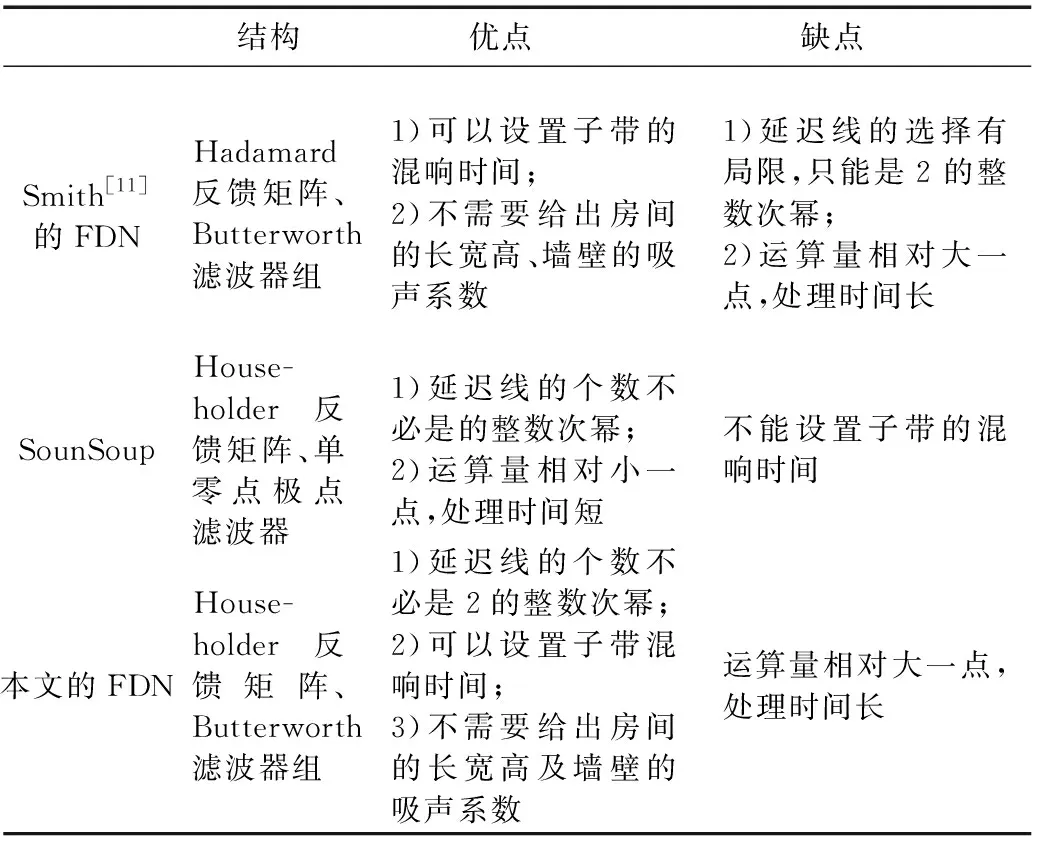
M1 (9) 其中mi的计算方法如下: (10) 其中Mi为所需延迟线的长度,pi为使用自然顺序的素数.round()表示对数值进行四舍五入运算,floor()表示对数值进行向下取整. 当房间的具体几何模型和墙壁的吸声系数未知时,就无法使用Sabine公式计算出所需的混响时间.多频带FDN延迟滤波器可以克服这个困难,它可以单独设置混响时间,混响时间应该至少在3个频段内独立可调[14].相对于一阶延迟滤波器,更多地使用多频带FDN延迟滤波器,通常可以使用滤波器组来实现多频带延迟滤波器.例如,每条延迟线的输出被分成K(K≥3)个频带,那么长度为Mi的延迟线的第k个频带的增益为 (11) 其中n60(ωk)=t60(ωk)/T,t60(ωk)表示频率ωk的混响时间. 本文在反馈延迟网络中选用的是Butterworth滤波器组.Butterworth滤波器是一种通带频率响应曲线很平坦的滤波器,是使用低通和高通Butterworth滤波器来实现所需特性的滤波器组.也就是说,整个频谱在最高的交叉频率被分割,在下一个交叉频率将低通区域再分割成2个频带.本文设置S个交叉频率,整个频带就被分成S+1个频带,那么就需要2S个Butterworth滤波器组成滤波器组.例如,设置2个交叉频率,那么整个频带就被分成3个频带,就需要4个滤波器组成滤波器组. 图2所示的是N=3,基于Butterworth滤波器组的FDN.x(n)为输入信号(干净无混响),filter1~filter4为Butterworth滤波器组,y(n)为输出信号. Householder反馈矩阵QN的另一个很好的特性就是,当N≠2时,矩阵中的所有数都是非零的,这就意味着每条延迟线都会反馈给其他延迟线,从而有助于尽可能地最大化回声密度.例如,当N=4时,Householder反馈矩阵为 (12) 由于N=4的Householder反馈矩阵的平衡性,Jot等[14]在此基础上提出了一种N=16的反馈矩阵嵌入FDN内: (13) 本文也采用式(13)的反馈矩阵. 在实验仿真中,将一段采样率为8 000 Hz的干净语音依次通过延迟线、滤波器组,产生所需要的混响时间,再通过反馈矩阵,最后得到混响信号.表1为仿真中的基本参数设置.其中房间(学校体育馆)的长为48 m,宽为19 m,高为18 m,声源位置的三维坐标为[18,11,12],传声器位置的三维坐标为[18,8,12]. 表1 仿真实验中的基本参数设置Table 1 Basic parameter settings in the simulation experiment Smith[11]的FDN的方法使用16条延迟线,设定3个子带的混响时间,SoundSoup使用16条延迟线,一个总的混响时间,而本文的方法是用18条延迟线(延迟线不必是2的整数次幂,选择自由),设定3个子带的混响时间. 图3a—3d分别为真实房间产生的混响信号、Smith[11]方法处理后的信号、SoundSoup处理后的信号以及本文方法处理后的信号的语谱图.对比图3a、图3b和图3c可以看出Smith[11]方法、SoundSoup处理过的信号能量强的频率衰减过程变得不清楚. 为了进一步评价加混响的效果,采用语音质量感知评价[15](Perceptual Evaluation of Speech Quality,PESQ)对混响效果进行评价,ITU-T(国际电信联盟电信标准化部)的相关资料已经证明:PESQ能够精确地给出编码失真、传输丢失、环境噪声和时间扭曲的预测值.PESQ得分的高低可以用来评价信号的好坏,通常情况下,PESQ的得分在1.0~4.5之间. 本文选用了10条测试语音和10个房间脉冲,分别通过3种方法处理共得到300个混响信号.对比混响信号和真实房间产生的信号,得到3种方法PESQ得分的平均值.图4所示的是3种处理方法得到的混响信号的PESQ得分情况.Smith[11]的FDN方法得到的混响信号PESQ的平均值为2.48,SoundSoup方法得到的混响信号PESQ的平均值为2.36,而经过本文方法处理得到的混响信号的PESQ的平均值为2.55.图4表明经过本文方法处理过的信号的PESQ得分较高,比Smith[11]方法提高了0.07,比SoundSoup方法提高了0.19. 听者的主观感觉是判断混响感的重要评价标准[16].因此,本文还采用听音实验来评价3种不同的人工混响信号.测试中音频文件采样率为8 kHz,单声道,分别经过3种方法进行处理得到的混响信号.实验中选择10名听众,均为在校研究生,听力正常,对处理后的混响信号和真实房间产生的信号进行试听,选出3种方法中最佳、最接近真实房间产生的混响信号.10名听众选出来的100条中语音中,Smith[11]的FDN方法处理的语音有26条,占26%;SoundSoup方法处理的语音有2条,占2%;本文方法处理的语音有72条,占72%.大部分听者选择了本文方法,表明了在3种方法中,本文方法能产生最佳且最接近真实房间的混响信号. 表2将3种方法的组成结构和优缺点进行了比较,可以看出本文的FDN方法更便于进行参数的设置. 表2 3种方法对比结果Table 2 Comparison of three methods 本文在Smith[11]FDN方法和苹果公司推出的SoundSoup基础上,提出了一种基于Householder反馈矩阵和Butterworth滤波器组的人工混响方法.语谱图、语音质量感知评价和主观评价结果表明,本文方法能产生比其他2种方法更加接近真实房间的混响信号,证明了本文方法的有效性.1.2 Butterworth滤波器组
1.3 Householder反馈矩阵
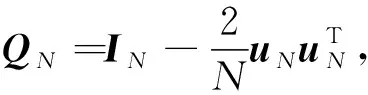
2 实验及分析

3 结论
