基于2K?means算法的读者兴趣分类图书自动推荐系统设计
2020-10-22林艳凤苑吉洋
林艳凤 苑吉洋


摘 要: 为了能够满足读者的个人兴趣特点和应用需求,提出基于读者兴趣分类的图书自动推荐系统设计思路。介绍了读者兴趣需求的图书自动推荐系统设计理论技术基础,包括数学挖掘、2K?means算法及UML语言。详细分析了基于读者兴趣分类的图书自动推荐系统需求和性能需求,将读者的兴趣与图书类别完成聚类分析,并提取最终聚类所获结果匹配图书类别,建立读者兴趣分类图书自动化推荐模型。引入聚类算法、关联规则算法实现读者感兴趣图书规律的统计分析,从而整合读者的图书信息源并充分发现具有较大价值的信息,最终将与相似性需求相符的图书,采用电子邮件或网页方式,自动推荐给读者。该系统设计能够为读者提供可能感兴趣的图书摘要、馆藏类相关信息,且运行性能良好,具有良好的推广应用前景。
关键词: 读者兴趣分类; 图书自动推荐; 系统设计; 2K?means算法; 数据挖掘; 聚类分析
中图分类号: TN850.3?34 文献标识码: A 文章编号: 1004?373X(2020)20?0141?04
Design of 2K?means algorithm based book automatic recommendation system for readers′ interest classification
LIN Yanfeng, YUAN Jiyang
(Qingdao University of Science &Technology, Qingdao 266000, China)
Abstract: An book automatic recommendation system based on readers′interest classification is proposed to meet the individual interest characteristics and application needs of readers. The design theory and technical basis of book automatic recommendation system for readers′ interest needs are introduced, including mathematical mining, 2K?means algorithm and UML language. The requirements and performance requirements of the book automatic recommendation system based on readers′interest classification are analyzed in detail, the clustering analysis of readers′interest and book category is completed, and the results of the obtained final clustering are extracted to match the book category. The book automatic recommendation model of readers′interest classification is established. The clustering algorithm and association rule algorithm are introduced to realize the statistical analysis of the book rule that readers are interested, so as to integrate the book information sources of readers and fully discover the information of greater value. The books that meet the requirements of similarity will be automatically recommended to readers through E?mail or webpage. The design of the system can provide readers with the relevant information of book abstracts and collections that may be interested in. It has good operation performance and good application prospect.
Keywords: readers′interest classification; book automatic recommendation; system design; 2K?means algorithm; data mining; cluster analysis
0 引 言
随着各种类型大量图书资源出版量的急速增长,读者可利用资源越来越多,但与此同时也给读者在图书阅读中,带来选择难度较大、无法抉择、图书类型多等问题。科技水平的进步发展给各行业带来较大的本质改变,以传统图书馆为轴心的被动式服务模式,已经无法更好地满足当前读者的个人需求[1]。由于专业、水平、兴趣、行为等各方面差异,不同的读者对于图书的兴趣需求点也就各有不同。并且,近年来为了更好地顺应信息技术飞速发展的需求,图书馆也在原本技术手段上提供了诸多新型技术服务,如目录查询、借阅服务、续借服务、书刊催还等技术,更是不断加大个性化服务力度,彻底改变了传统图书馆的服务模式及内容[2]。图书馆拥有海量图书资源,能够满足不同读者为其提供高品质差异化服务模式,但是在馆藏资源日趋增加的当下,怎样才能够真正从海量图书资源中,真正为读者提供感兴趣的图书和个性化服务,就作为目前需要迫切解决的关键问题[3]。所以提出基于读者兴趣分类的图书自动推荐系统设计思路,能够对图书馆图书资源充分合理利用的同时,还可以有效确保读者可以对相关信息进行针对性的有效检索,很大程度上提升管理读者的图书搜索效率,满足了读者的个性化便捷服务需求。
1 相关理论和关键技术
1.1 数据挖掘及相关理论
数据拥有大量、随性、含噪且不安全性等特点,数据挖掘是提取用户潜在且有一定价值的感兴趣知识信息的过程,决策管理人员可以分析处理相关信息的过程[4?6]。那么在数字图书馆中的数据挖掘技术是能够运用各类技术工具,在大型网络数据库中提取规律潜在信息,寻找信息中存在的关联规则性。目前,数据挖掘的主要技术包括了信息关联分析、聚类分析、分类、预测、时序模式、偏差分析等,比较常用的数据挖掘方法包括决策树、聚类、统计、遗传算法、神经网络、近邻预测等已被应用于不同区域。
1.2 2K?means算法
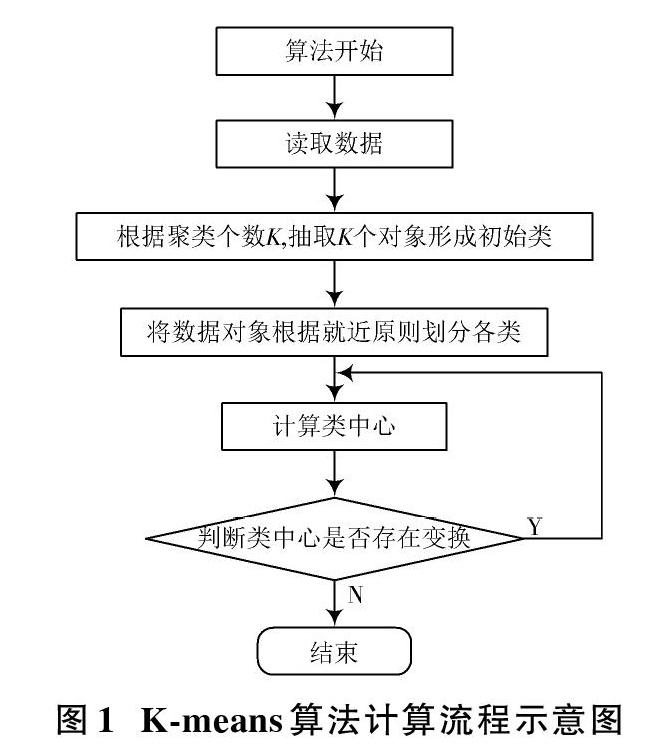
2K?means算法是以输入均值作为类中心,从而完成的一种聚类分割算法,假设K表示输入量,拥有n个聚类对象,具体计算流程如图1所示[7]。
1) 结合相应需求完成K个对象的自动化生成,并视不同对象作为类中心[8];
2) 根据“距离中心就近”这一原则,寻求最匹配每一个对象的类,并且完成各类对应,分配剩余对象;
3) 完全划分后,对于各类对象均值逐一计算,并行形成全新的类中心;
4) 重新以“距离中心就近”原则划分所有类对象;
5) 对所有类进行判断,假如存在变化则从步骤3)重复,反之结束算法。
1.3 UML语言
想要成功研发一个系统达到预期目标,其关键在于能够实现需求者与系统开发者之间的沟通,那么UML语言即作为沟通工具,帮助系统开发者了解、掌握并发挥想象力。
UML作为可视化建模语言,能够实现系统开发者轻易理解且统一标准方式,成功建立系统开发设计蓝图,所提出的统一机制实现不同主体之间的交流共享。图2为UML语言视图。
由图2可知,通过用例描述功能行为,UML能够描述系统用户的观点,由此派生其他相关模型视图。目前比较常用的UML图包括了用例图、行为图、静态图、交互图、实现图[9?11]。通过建立UML语言视图,主要给出两类模型元素,分别包括了概念表述模型元素、元素关系表述。
2 系统设计分析
2.1 系统需求
结合前期调研结果发现,目前以亚马逊、当当等图书网站,均可以实现基于读者兴趣分类个性化推荐图书这一服务功能[12]。本文设计思路主要是为了能够分析数字图书馆的读者兴趣需求,和图书馆的馆藏文献需求。通过分析读者的兴趣偏好需求情况,能够更好地掌握读者的需求借阅特点,实现个性化需求图书推荐服务。
2.2 读者兴趣需求
以高校数字图书馆为例,读者主体主要包括了学生、教师、教研者。了解以往研究结果汇总高校数字图书馆的读者兴趣需求情况,需要数字图书馆提供图书预借、兴趣推荐、跨库互借、定制服务、引文检索、学术评价等需求[13]。了解高校数字图书馆的读者,主要知识集中于大专及以上水平,汇总数字图书馆图书数据特点如下:
1) 大量性。随着高校招生数量扩增,图书馆软硬件水平提升,也随之不断增加数字图书馆的服务系统数据。
2) 关联性。经分析读者的图书借阅数据,能够发现在差异化读者借阅图书时,在一定程度上存在数据关联性。
3) 潜在性。图书馆的海量图书数据中,通常包括具备较大价值的图书信息,通过运用数据挖掘技术,对读者兴趣个性化需求进行分析识别,从而向读者推送相应的信息手段,能够真正发挥图书馆读者兴趣分类的个性化作用[14]。
2.3 系統功能需求
在设计基于读者兴趣分类的图书自动推荐系统中,势必要真正以读者的个人图书阅读兴趣为依据,开发主动、个性、针对性图书自动推荐平台。本文系统主要功能模块包括读者登录管理、读者信息管理、图书推荐、后台管理等。
2.4 数据流程图
系统图书自动化推荐架构流程如图3所示。
3 系统设计实现
3.1 系统设计目标及原则
设计基于读者兴趣分类的图书自动推荐系统,主要是为了能够满足读者的个性化兴趣需求,基于现有数字图书馆应用系统的基础上优化改进,运用B/S三层架构,经UML语言设计建模,旨在设计安全可靠、美观便捷、操作简单的个性化图书自动推荐系统。
在设计该推荐系统过程中,需要确保严格遵循软件开发正常流程,同时还在本次开发设计中引入UML建模语言,所以做到了该系统的易学易用、安全可靠、完整灵活、兼容可拓展性及针对性。
3.2 系统开发环境
该系统的设计开发环境如表1所示,运用目前新型技术软件,均基于Windows系统平台,确保本次设计系统的可拓展性及兼容性[15]。
3.3 系统结构设计
该系统作为满足读者兴趣个性所需的图书自动推荐平台,能够向读者主动的提供针对性推送服务,共计划分四大模块,如图4所示。
1) 读者登录管理。该子系统模块主要保证了用户应用该系统的安全保密性,可以通过输入用户名、登录密码和验证码,系统验证用户权限后即可决定是否进入系统。
2) 读者信息管理。读者成功登入该系统后可以自由查看个人信息,并且进行自主编辑修改。显示读者的相关注册信息,包括邮箱地址、感兴趣图书类型、急需的新书等信息。
3) 自动化推荐。该模块是向读者自动推荐感兴趣图书的核心功能,能够让读者更加高效、便捷地寻找自己感兴趣及所需图书,包括输出输入层、个性化服务层、基本数据库层。
4) 后台管理。该子系统模块负责对系统所有功能的后台管理,包括添加、修改和删除管理员信息、感兴趣图书,设置自动化图书推荐时间间隔、制定服务器邮箱等功能。