基于CenterNet的小学生英文手写体区域检测
2020-10-20张朝晖刘远铎
张朝晖 刘远铎


摘 要:为了探索智能批阅小学生作业的可行性,以小學生英文手写体为研究对象,建立了基于关键点的CenterNet模型。首先,针对低显存环境下CenterNet模型的构造与学习,提出了一种新的以组规范化(GN)替换批量规范化(BN)的池化模块结构改造方案,得到了改造版CenterNet模型;之后,将改造版CenterNet模型用于小学生英文手写体区域检测,实现了基于深度学习的英文手写体区域检测。将改造版CenterNet模型与原始CenterNet模型和CornerNet-Lite基准模型进行检测比较。实验表明:2种版本CenterNet模型的英文手写体区域检测精度和平均召回率均高于基准模型的相应值,改造版CenterNet模型的AP0.5值甚至可达到73.1%,比基准模型高出近6%;此外,相比于基准模型,改造版的CenterNet模型的漏检情况更少,并在一定程度上有效抑制了误检。改造版的CenterNet模型不仅检测性能优于原始CenterNet模型,而且其学习过程更稳定、收敛更快,这为小学生作业智能批阅方案的设计提供了有价值的解决途径。
关键词:计算机神经网络;英文手写体区域检测;目标检测;CenterNet;组规范化;池化模块结构
中图分类号:TP3914文献标识码:A
doi: 10.7535/hbgykj.2020yx05001
收稿日期:2020-08-17;修回日期:2020-08-30;责任编辑:陈书欣
基金项目:国家自然科学基金(61702158);河北省自然科学基金(F2018205137,F2018205102)
第一作者简介:张朝晖(1969—),女,河北乐亭人,副教授,博士,主要从事机器学习、图像识别方面的研究。
通讯作者:刘远铎。E-mail:lyuanduo@163.com
张朝晖,刘远铎.
基于CenterNet的小学生英文手写体区域检测[J].河北工业科技,2020,37(5):291-299.
ZHANG Zhaohui, LIU Yuanduo. Detection of English handwriting area for primary school students based on CenterNet[J].Hebei Journal of Industrial Science and Technology,2020,37(5):291-299.
Detection of English handwriting area for primary school
students based on CenterNet
ZHANG Zhaohui1, LIU Yuanduo2
(1.College of Computer and Cyber Security,Hebei Normal University,Shijiazhuang, Hebei 050024, China; 2.Software College, Hebei Normal University, Shijiazhuang, Hebei 050024, China)
Abstract:
To explore the feasibility of intelligent workbook review for primary school students, a CenterNet model based on
the keypoints was established with primary English handwriting as the research object. Firstly, aiming at the construction and learning of CenterNet model in the case of low GPU (graphics processing unit) memory, a new scheme for pooling module structure modification was proposed by replacing BN (batch normalization) with GN (group normalization), and a modified CenterNet model was obtained. Then, the modified CenterNet model was used for the detection of English handwriting areas of primary school students, and the application of English handwriting area detection based on deep learning was realized. The comparison experiments with the original CenterNet model and the CornerNet-Lite baseline model show that the accuracy and average recall rate of the two versions of CenterNet model are higher than those of the baseline model, and the AP0.5 value of the modified CenterNet model can reach 73.1%, which is nearly 6% higher than that of CornerNet-Lite model. In addition, compared with the baseline model, the modified CenterNet model can get less missed detection and effectively suppress false detection to a certain extent. The improved CenterNet model not only has better detection performance than the original CenterNet model, but also has more stable learning process and faster convergence. This provides a valuable solution for the design of homework intelligent review scheme for primary school students.
Keywords:
computer neural network; English handwriting area detection; object detection; CenterNet; group normalization (GN); pooling module structure
當今时代是人工智能技术快速发展的时代,伴随着人工智能技术的不断普及,与之相关的应用不断引起人们的关注。中小学教育质量的优劣关系着国家的未来,如何将人工智能的最新成果与中小学数字教育应用需求有机结合成为研究的课题。在不断提升教育教学质量的背景下,作业批阅的质量与效率对家长和老师都是一个不可避免的新问题与挑战。准确、高效的作业批阅,有助于家、校双方更为客观、及时地了解学生的学习情况以及教学质量,因此实现作业的智能化批阅是一个迫切需要解决的问题。
目前小学生作业的载体以纸质作业册为主,而要实现作业的智能批阅,并构造手写体区域检测模块,以数字化的作业图像为输入,检测图像中的手写体区域;进而将检测结果输入至后续的手写内容识别及评分环节。其中,
一个尤为关键的环节是手写体区域的检测。它是实现准确、可靠的智能批阅的核心模块。为此
本文面向小学生作业智能批阅的应用需求,围绕作业图像中手写体区域检测,结合深度学习在目标检测方面的新成果,探讨了将基于关键点的目标检测模型应用于小学生英文手写体区域检测的可行性。
1 目标检测技术研究现状
手写体区域检测的目的在于从给定的包含手写体区域的图像中定位并提取手写体区域,这是一种典型的图像目标检测问题。从应用的角度来看,关于目标检测的研究主要有2种基本主题:一个是一般意义的目标检测,其目的是在统一框架下探究可以同时进行不同类型目标检测的方法;另一个则是结合具体的应用场景进行特定类型的目标检测,例如车辆检测、行人检测、文本检测等。
近年来,深度学习技术的快速发展为目标检测技术注入了新鲜的血液,2014年基于深度学习的R-CNN模型[1]打破了传统目标检测性能停滞不前的僵局。自此,基于深度学习的目标检测技术开始以前所未有的速度不断发展,其目标检测性能也不断创造着新的记录。有关目标检测技术的发展历程,可参见ZOU等[2]关于近年目标检测技术的系统化综述。按照目标检测过程中是否使用锚窗口(anchor),可以将目标检测模型分为两大类型:基于锚窗口(anchor-based)的目标检测法和无锚窗口(anchor-free)的目标检测法。
第1类方法为基于锚窗口的目标检测法。这类检测模型需要在特征图的各位置设置锚窗口,针对每个锚窗口预测目标对象存在的概率,借助锚窗口尺寸的调整来匹配可能的目标对象。可进一步将该类方法划分为2种典型形式,即:两阶段检测器(two-stage detector)和单阶段检测器(one-stage detector)。两阶段检测器首先基于输入图像生成高质量的目标区域候选框,之后借助分类与回归网络的连接进行候选框的类别判断及位置校正。最早出现的R-CNN及其后续衍生的Faster R-CNN[3],Mask R-CNN[4]等是两阶段检测器的典型代表。尽管Faster R-CNN在行人检测[5]等目标检测任务中有着优秀的表现,但是两阶段检测器以牺牲检测速度换得较高的检测精度,时间成本消耗较高。单阶段检测器直接对预先设置的锚窗口进行分类和回归。SSD[6],YOLOv3[7]是这类方法的典型代表。这类方法在预测区域候选框的同时,进行目标区域类别的预测和位置的回归。总之,基于锚窗口的目标检测法需要在图像中生成尽可能涉及更多感兴趣目标类型的大量锚窗口,锚窗口的引入导致更多额外超参数;相对于图像中密集分布的大量锚窗口,只有少量窗口被标记为目标,导致大量窗口的冗余;当检测类型的目标形状发生较大改变时,这种基于锚窗口的目标检测法的场景应用灵活性降低,需要结合具体目标类型仔细设计锚窗口的形状。
第2类方法为无锚窗口的目标检测法。人眼无需从候选窗口中进行选择即可感知监控场景中目标位置与大小,因此可以摒弃锚窗口的生成机制,建立一种直接进行目标检测的方法。其中,基于关键点的目标检测器是这类方法中出现时间较近的一种类型,检测器通过预测关键点的位置将其分组,以获得目标边界框。CornerNet[8]模型借助目标区域边框的左上角及右下角2个顶点预测,并以其嵌入到抽象特征空间的方式来确定目标区域的位置,该检测器在具有挑战性的交通标志检测[9]任务中得到了较为成功的应用。这种具有里程碑意义的更为简化的目标检测框架,意味着基于关键点的目标检测方法具有更大的发展空间。例如:为了能够在不牺牲检测精度的情况下提高效率、并提高实时检测的准确性,在CornerNet模型的基础上,LAW等[10]将该模型的2种变体组合,提出了CornerNet-Lite模型,其中CornerNet-Squeeze更适合实时目标检测;与此同时,DUAN等[11]提出了CenterNet模型,该模型在CornerNet模型所提出的基于2个关键点的目标检测框架基础上,引入了目标中心点的检测分支,增加了模型感知目标区域内部信息的能力,借助中心点的验证来有效抑制误检,其在MS-COCO数据集上的检测性能大幅度领先于同期出现的其他目标检测模型,表现出了令人瞩目的优势。
基于关键点的目标检测器无需进行锚窗口的生成,意味着其对不同大小、形状的目标检测更具场景适应力。
小学生作业图像中的手写体区域检测面临如下挑战:1)与中学生或大学生等成年人的大小适中、字形比较规范的书写字体不同,小学生书写风格不一,随意性强,缺乏规范性,字体形态各异, 特征学习难度大;2)市面上的相关练习册种类丰富,各页面场景内容多样,结构复杂,手写区域噪声较多,模型学习难度大;3)各练习册不同页面需要作答的内容长短不一,有些是单独字母和单词,有些是英文短语和句子,如何实现变长手写体区域检测还面临诸多未知。因此有必要结合更具场景适应能力的目标检测模型探讨其在手写体区域检测中的可应用性。
对于手写体区域检测,目前还未见基于关键点有效抑制误报边框的应用案例。本研究以CenterNet[11]目标检测模型为例,利用图像目标的内部特征能更好地感知目标内部信息的特点,面向小学生作业智能批阅的应用需求,进行基于关键点的目标检测模型在英文手写体区域检测中的应用探索。
2 结合池化结构改造的CenterNet目标检测模型
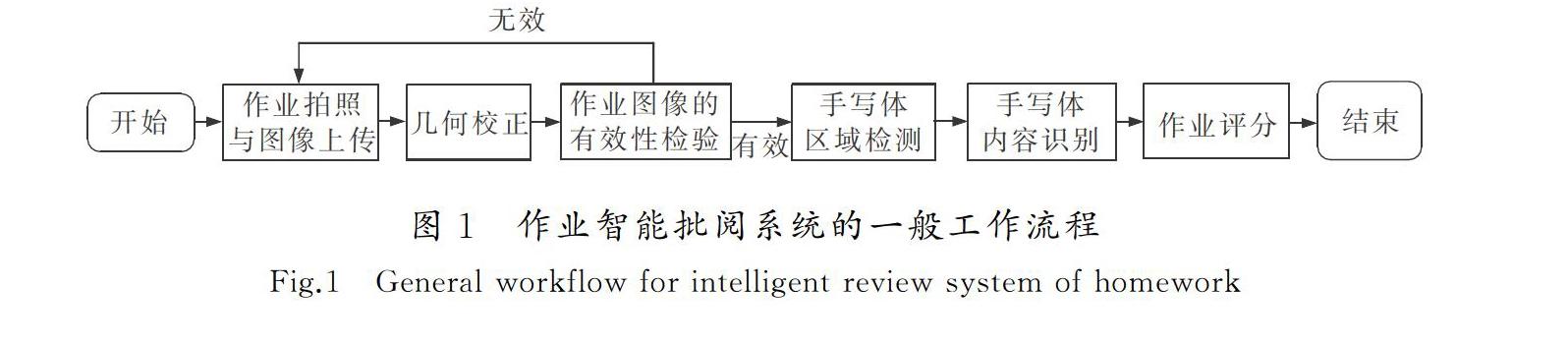
21 小学生作业智能批阅的一般流程
图1所示为纸质作业智能批阅系统的一般工作流程。
首先,用户将纸质作业拍照成像,实现纸质作业的数字化,并上传至作业批阅系统;之后对作业图像进行几何校正并检验有效性;检验有效的作业图像输入至手写体区域检测模块,该模块借助端到端的检测,获取作业区域的手写体部分;然后将手写体检测结果输入至后续的内容识别模块,将识别结果与目标答案进行比较,完成作业评分。图1中手写体区域检测模块即为本文的工作重点。
2.2 CenterNet模型的引入
图2所示为原始CenterNet模型的网络结构图[11]。CenterNet模型的网络结构继承了CornerNet模型中基于沙漏网络(Hourglass-52)的骨干网络,以实现关于输入图像的多通道特征图的提取;构造了2种类型的关键点池化模块(见图3),并以此为基础,采用多分支方式处理图像特征图,以实现目标区域的信息感知与定位。其中:1) 以中心点池化(Center Pooling)模块(见图3 a))为基础的分支网路,提取与目标类别或结构语义信息相关联的目标区域中心点热图(Center Heatmaps),以生成目标备选中心点;2) 以級联的角点池化(Cascade Corner Pooling)模块(见图3 b))为基础的分支网络,借助左、上或右、下不同方向的池化组合,提取图像中与目标区域边缘语义信息相关联的角点热图(Corner Heatmaps),以实现目标区域备选外边框左上角点和右下角点位置的估计。
最终,结合位置偏移量(Offsets)信息建立目标区域关键点在输入图像坐标系的映射;借助角点嵌入向量之间的距离信息生成备选的目标检测框;进一步结合中心点信息过滤目标边框信息,得到最终目标检测结果。
正是由于CenterNet在CornerNet的基础上关于目标区域新的关键点的引入、以及池化结构的巧妙构造与使用,使得CenterNet模型只需花费很小的代价,即可实现目标检测性能的明显提升。
2.3 池化模块结构改造方案的提出
CenterNet模型的参数寻优采用小批量(mini-batch)的梯度下降法。为防止梯度消失、促进模型尽快收敛,在CenterNet模型的中心点池化(Center Pooling)以及级联角点池化(Cascade Corner Pooling)模块中均使用了批规范化(batch normalization,BN)层[12],图3简单示意了BN层在2种类型池化结构中的相对位置。
假定每个小批量样本集的样本数目(即:batch size的取值)为m,并且由池化模块的卷积层针对每个样本图像生成了通道数目为C、大小为H行×W列的特征图。若采用BN方式规范化每个小批量样本集,就要以特征图的通道为单位,针对每个通道分别估计各种特征的均值与标准差,进而分别处理每个通道中m个特征图的不同特征。
设当前小批量样本集的第j个样本在第c个通道的第i个特征取值为x(j,c)i,基于BN层处理得到批规范化的结果为y(j,c)i,具体处理过程如式(1)、式(2)所示。其中:i∈{0,1,…,W×H-1},j∈{0,1,…,m-1},c∈{0,1,…,C-1}。
(j,c)i=1σ(c)i
(x(j,c)i-μ(c)i), (1)
y(j,c)i=a·(j,c)i+b, (2)
式(1)中第c个通道的特征图的第i个特征均值μ(c)i及标准差σ(c)i分别估计为
μ(c)i=1m∑mj=1x(j,c)i, (3)
σ(c)i=1m∑mj=1[x(j,c)i-μ(c)i]2+ε。(4)
式(2)中,a,b为预设值;为避免σ(c)i取值为0,在式(4)中引入小正数ε。由BN规范化方式可知,统计量μ(c)i以及σ(c)i的估计需要小批量样本数目m足够大。加大m值面临硬件资源的挑战;而降低m值将导致估计不准确。
当显存容量比较低时,只能通过下调m值缓解模型学习面临内存资源短缺的窘境,甚至只能将m设置为个位数(例如,取值为1或者2)。这种过小的m值,使上述统计量的估计失去意义,进而难以发挥BN层的作用,同时也为模型的学习增加了不必要的计算负荷。
在批规范化之后,针对模型学习的不同问题陆续出现了基于其他规范化的解决方案,如:层规范化[13]、实例规范化[14]、权重规范化[15]以及组规范化 (group normalization, GN)[16]等。为解决小批量样本数目过小情况下模型学习的问题,同时为了使CenterNet模型的学习可以更为灵活地适应于不同硬件配置环境(特别是显存容量低的学习环境),受文献\的组规范化思想的启发,提出了一种以GN层替换BN层的池化结构改造方案,以实现关于图3所示2种类型池化模块结构的改造,并基于这种新的改造版的池化结构构造CenterNet目标检测模型。
图4为本文提出的基于GN层的池化模块结构改造方案。不同于BN逐个通道的处理方式,基于GN方式的规范化是将各通道分组,以组为单位进行处理。
首先进行通道分组。若将C个通道分成G组,则落入第k个通道组的各通道序号构成通道序号集合,记为
Sk={c|c/G=k,c=0,1,…,C},其中k∈{0,1,…,G-1}。
分别处理每组通道。设当前小批量样本集第j个样本在第c个通道的第i个特征取值为x(j,c)i,基于GN层处理得到组规范化的结果为y(j,c)i。若通道序号c∈Sk,则具体处理过程如式(5)、式(6)所示。其中:i∈{0,1,…,W×H-1},j∈{0,1,…,m-1},c∈{0,1,…,C-1}。
(j,c)i=1σ(k)i(x(j,c)i-μ(k)i),
(5)
y(j,c)i=a·(j,c)i+b,(6)
式(5)中,位于第k组通道各特征图的第i个特征均值μ(k)i及标准差σ(k)i分别估计为
μ(k)i=1m·|Sk|
∑mj=1 ∑c∈Skx(j,c)i,(7)
σ(k)i=
1m·|Sk|
∑mj=1
∑c∈Sk
[x(j,c)i-μ(k)i]2+ε。 (8)
由上述BN与GN的规范化方式计算可知,基于GN的规范化使用了特征图的通道分组,使得各特征的均值与标准差的估计更为稳定,有效地弱化了小批量样本集的样本数m对特征规范化的影响。
因此,本文提出的这种基于GN的改造版池化结构CenterNet模型的构建方案,缓解了基于小批量样本集梯度下降法进行CenterNet模型学习时对小批量样本数目的依赖,为低显存容量下基于梯度下降法的模型学习提供了一种有效的解决途径。本文将使用这种基于改造版池化结构构造的CenterNet模型进行英文手写体區域的检测。
2.4 损失函数
如式(9)所示,基于改造版池化结构构建的CenterNet模型的学习使用了与文献\形式一致的损失函数,该损失函数由角点位置预测损失Lcodet、中心点位置预测损失Lcedet、用于最小化相同目标对象的角点嵌入向量之间距离的“内拉(pull)”损失Lcopull、用于最大化不同目标对象的角点嵌入向量之间距离的“外推(push)”损失Lcopush、以及角点位置偏移量预测损失Lcooff和中心点位置偏移量预测损失Lceoff组成。其中控制参数α,β,γ用于平衡各部分之间的相对重要性。
L=Lcodet+Lcedet+α·Lcopull+
β·Lcopush+γ·(Lcooff+Lceoff)。(9)
3 实验与分析
3.1 数据集
用于模型学习及测试的数据集源自调查收集的小学生英文练习册的作业图像;与作业图像对应的真值数据,则采用图像标注工具LabelMe标注得到。图5展示了数据集的部分图像样例。
由图5可知,关于英文作业手写体区域检测的应用场景大致分为6类:1)包含作业配图的作业册页面(如图5 a));2)大段印刷体区域与问答式填空区域相结合的作业册页面(如图5 b));3)光照条件不均匀现象明显、并伴有一定噪声干扰的作业册页面(如图5 c));4)作业区域紧凑并以句子作答的作业册页面(如图5 d)); 5)作答内容为单个英文字母的作业册页面(如图5 e));6)非常规的、背景趣味性较强的作业册页面(如图5 f))。
需要指出的是:因作业册页面的作业区域布局不同,学生在作业区域手写内容的紧凑程度、手写体区域的大小以及分布各不相同;即使在相同作业区域,因不同人的手写习惯不同,相应内容的字体、大小、手写区域的分布也不会统一。
具体实验时,首先将收集到的关于英文作业册的页面图像统一放缩为800像素×600像素,在此基础上,采用LabelMe标注生成真值数据。将上述数据集随机打乱,分成两部分,其中:5 084幅作业图像构成训练集,1 271幅作业图像构成测试集。
3.2 测试环境与学习策略
本实验采用CPU为Intel(R) i7-7700@2.80 GHz的笔记本,GPU为单张NEVIDA GTX 1060 8 GB显卡,基于Ubuntu18.04系统,在PyTorch GPU环境下进行模型学习。
在模型学习之前,首先进行了训练样本集的增强,具体的数据增强手段分别是:1) 针对每个样本图像进行随机放缩,其中水平、垂直方向放缩时的比例系数∈[0.6,1.4];2) 针对每个样本图像的颜色值进行随机抖动。
基于上述增强的训练集,采用基于小批量样本集的梯度下降法,结合Adam的优化方式进行了模型学习,其中式(9)所示模型损失函数中3个控制参数α,β,γ的取值分别为0.1,0.01以及1。设定最大迭代次数为10 000,每个小批量样本集的样本数目m=2,初始学习率为0.000 25;模型每迭代4 500次便使学习率减小至原来的1/10。训练开始时,损失函数的值为14;之后经过1 000轮迭代之后损失函数值下降到2~3左右,最终损失函数值稳定至1附近。因检测对象为英文手写体区域,所以设定这种检测对象的类别名称为“vocabulary”。模型学习时,统一将作业图像放缩至511像素×511像素,输入到网络。
3.3 模型评价
3.3.1 基准模型的选择
CenterNet模型在MS-COCO数据集的目标检测实验[11]中,各类目标总体平均检测精度
(average precision,AP)值达到47%,而当交并比(intersection over union,IoU)大于05时,各类目标平均检测精度AP05也达到了64.5%,其在MS-COCO数据集的目标检测性能已超过CornerNet及其之前其他典型的目标检测模型,这已证明CenterNet模型的目标检测性能已经超出CornerNet。
考虑到CenterNet与CornerNet-Lite[10]二者在基于关键点的CornerNet模型上接近同期发展而来,作为近年来具有较高检测性能的目标检测模型的典型代表,其在手写体区域检测的性能值得期待。因此,为了探讨这种类型的目标检测模型在手写体区域检测的有效性,选择CornerNet-Lite作为本文实验评价的基准模型,其模型结构采用了CornerNet的Squeeze版。
选择了基准模型之后,结合3.1节所述的训练集,在同样学习条件下实现了3个模型的学习,分别为CornerNet-Lite英文手写体区域检测模型、基于原始池化结构版本的CenterNet英文手写体区域检测模型、以及基于本文改造版池化结构的CenterNet英文手写体区域检测模型;并结合1 271幅测试图像进行了CenterNet英文手写体区域检测模型的性能评价。
3.3.2 模型的定量评价
因小学生英文作业的手写体区域目标以单个字母、单词、短语及单行短句为主,为此参考了文献\中关于目标检测的评价方式,选择了
AP05,ARSmall,ARMedium以及ARAll为英文手写体区域检测性能的评价指标。其中:AP05表示当IoU>0.5时英文手写体区域的平均检测精度;
ARSmall与ARMedium分别表示当k=0,1,…,9时对应IoU阈值的10种不同取值下小尺度目标(单个字母及单词)、中尺度目标(短语与单行句子)的英文手写体区域平均召回率(average recall,AR);
ARAll表示各种尺度英文手写体区域目标的平均召回率。
表1所示为基于上述指标将CornerNet-Lite基准模型以及基于原始池化结构版本的CenterNet模型与本文基于改造版池化结构的CenterNet模型进行手写体英文区域检测的性能比较结果。表1的最后1列还给出了不同模型关于单幅测试图像(511像素×511像素)的平均检测时间。
由表1的评价数据可知:1)与CornerNet-Lite模型相比,基于原始池化结构版本的CenterNet模型以及基于改造版池化结构的CenterNet模型的平均检测精度(AP05)和平均召回率(ARSmall,ARMedium及ARAll)均有不同程度提高,这证明了基于这2种版本的CenterNet手写体检测模型在检测精度、平均召回率方面性能更优;2)与基于原始池化结构版本的CenterNet模型相比,基于改造版池化结构的CenterNet模型进行英文手写体检测时,其AP05值可以提高1.3%,其中ARSmall,ARMedium及ARAll值分别提高0.4%,0.7%及0.8%,其平均单幅图像的检测时间也略短,进一步从检测精度、召回率以及检测速度方面,证明了基于改造版池化结构的CenterNet模型相對于原始池化结构版本的CenterNet模型在英文手写体检测方面更有效;3)尽管上述3种模型经过初步学习之后,其英文手写体区域检测的AP05值均超过了65%,但基于改造版池化结构的CenterNet模型则在检测精度、平均召回率达到最高,其AP05值甚至可达到73.1%,比CornerNet-Lite模型高出近6%。由表1的最后1列单幅测试图像(511像素×511像素)的平均检测时间可知,与2种版本的CenterNet模型相比,CornerNet-Lite模型的检测速度明显更快。
此外,在3.2所述相同硬件学习环境下对池化结构改造前后2种版本的CenterNet模型进行了学习过程的比较,其中:改造版池化结构的CenterNet模型的初始损失值为14,基于原始池化结构版本的CenterNet模型初始损失值在100以上。随着学习过程的不断进行,基于改造版的模型损失下降过程更加平稳,波动更少,可更快的收敛;而原始池化结构版本的模型损失值较大,与前者相比,其损失下降过程波动更多。这进一步证明改造版池化结构的CenterNet模型不仅在检测性能上优于原始模型,而且其学习过程更为稳定、收敛过程更快。
3.3.3 模型的定性评价
为了在主观上感受本文方法的有效性,图6展示了几个代表性的检测样例。由图6可知:对于不同的作业场景,即使作业区域布局各不相同、作业内容类型多样 (如:图6 a)的单个字母、图6 b)的单词、图6 c)—图6 e)的句子),模型均可较好地检测到手写体部分。特别强调的是本文模型还有效区分了如图6 a)左下角处的涂划作废的无效区域;对于图6 d)光线条件弱、以及图6 e)受红笔批阅干扰的样本图像也表现了不错的检测效果。
为实现模型检测性能的视觉比较,图7展示了本文改造版池化结构的CenterNet模型与Squeeze版CornerNet-Lite基准模型关于4个不同的样本图像在英文手写体区域检测结果的样例。其中第1行是改造版池化结构CenterNet模型的检测结果,第2行是CornerNet-Lite模型的检测结果。
将图7中第2行基于CornerNet-Lite模型的检测结果与第1行基于本文方法的检测结果进行视觉比较,可以发现:关于手写体单词的检测,CornerNet-Lite模型在样本图像a)中生成了一个明显的误检框;关于手写体句子的检测,该模型在样本图像b)与d)中出现了明显的漏检; 在样本图像c)中靠近页面的上部区域的手写字母处,CornerNet-Lite模型漏检了2个字母区域。相比之下,基于本文池化结构改造版的CenterNet模型针对上述4个样本图像的手写体目标区域的检测精度更高,没有发生误检;与前3个样本图像相比,样本图像d)中存在明显手写体倾斜,本文方法在该图像中漏检了1个句子区域。
图7所示的视觉效果比较表明:基于关键点的引入,可使CenterNet模型有效利用目标区域的内部信息;在CenterNet模型池化结构中以GN层替换BN层,为低容量显存配置下基于mini-batch的模型寻优提供了更为有效的解决方案,即使模型学习中设置mini-batch样本数目为2,模型针对不同场景的作业图像仍取得了较好的检测结果。因此,与基于Squeeze版CornerNet-Lite基准模型的检测结果相比,本文模型的漏检情况更少,并在一定程度上有效抑制了误检。
3.4 问题与不足
不可否认的是,当前训练条件下得到的CenterNet模型也存在手写体区域检测失效的情况。这主要表现为作业图像局部模糊、以及手写体部分局部几何形变明显时,会导致漏检(如图7的样本图像d));作业图像内容过于丰富、存在明显图文结合,或作业区域比较紧凑时,会导致误报(如图8所示,模型将多个单字符区域以大框标记为一体,误报为一个较大的目标区域)。
尽管基于改造版池化结构的CenterNet模型进行英文手写体区域检测时,其检测性能要明顯优于CornerNet-Lite模型,但是模型的检测速度还有待提升。
4 结 语
以小学生英文作业的智能评阅为应用场景,结合深度学习关于目标检测的研究成果,探讨了基于关键点的目标检测在手写体区域检测应用的有效性。
1)针对低显存容量情况下小批量样本集的样本数目(即:batch size的大小)对CenterNet模型学习的不良影响,提出一种以组规范化(GN)替换批量规范化(BN)的池化结构改造方案,有效弱化了小批量样本集样本数目对模型学习的影响,为低显存情况下CenterNet模型的构造及学习提供了一种有效的解决方案。
2)进一步面向小学生英文作业智能批阅的应用需求,将基于改造版池化结构构造的CenterNet模型用于小学生英文手写体区域的检测,进行了基于深度学习的目标检测模型在小学生英文手写体区域检测应用中的新尝试,并实现了基于该模型的小学生英文手写体区域检测。基于构造数据集的初步实验表明:即使设定小批量样本数目m=2,基于改造版池化结构的CenterNet模型的AP05值可以达到73.1%,与CornerNet-Lite基准模型的检测结果相比,漏检情况更少、误报更低、检测更加有效。
实验完成了基于CenterNet模型在小学生英文手写体区域检测的初步尝试,证明了这种应用的有效性,为小学生作业智能批阅方案的设计提供了一定的解决思路。后续将采用更为多样化的样本收集、基于多样化噪声干扰及不同几何形变的样本增强等方式,进一步改善模型的检测性能。
参考文献/References:
[1] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. NJ: IEEE, 2014: 580-587.
[2] ZOU Zhengxia, SHI Zhenwei, GUO Yuhong, et al. Object detection in 20 years: A survey[J]. Computer Vision and Pattern Recognition, 2019. arXiv:1905.05055.
[3] GIRSHICK R. Fast R-CNN[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision. NJ: IEEE, 2015: 1440-1448.
[4] HE Kaiming, GEORGIA G, PIOTR D, et al. Mask R-CNN[C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. NJ: IEEE, 2017: 2980-2988.
[5] 余珮嘉, 张靖, 谢晓尧. 基于自适应池化的行人检测方法[J]. 河北科技大学学报, 2019, 40(6): 533-539.
YU Peijia, ZHANG Jing, XIE Xiaoyao. Pedestrian detection based on adaptive pooling method[J]. Journal of Hebei University of Science and Technology, 2019, 40(6): 533-539.
[6] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//Proceedings of the 14th European Conference on Computer Vision. Berlin: Springer, 2016: 21-37.
[7] REDMON J, FARHADI A. YOLOv3: An incremental improvement[J]. Computer Vision and Pattern Recognition, 2018. arXiv: 1804.02767.
[8] LAW H, DENG Jia. CornerNet: Detecting objects as paired keypoints[C]//Proceedings of the 15th European Conference on Computer Vision. Berlin: Springer, 2018: 765-781.
[9] 范红超, 李万志, 章超权. 基于Anchor-free 的交通标志检测[J]. 地球信息科学学报, 2020, 22(1): 88-99.
FAN Hongchao, LI Wanzhi, ZHANG Chaoquan. Anchor-free traffic sign detection[J]. Journal of Geo-information Science, 2020, 22(1): 88-99.
[10]LAW H, TENG Yun, RUSSAKOVSKY O, et al. CornerNet-Lite: Efficient keypoint based object detection[J]. Computer Vision and Pattern Recognition, 2019. arXiv:1904.08900.
[11]DUAN Kaiwen, BAI Song, XIE Lingxi, et al. CenterNet: Keypoint triplets for object detection[C]//Proceedings of the 2019 IEEE International Conference on Computer Vision. NJ: IEEE, 2019: 6569-6578.
[12]IOFFE S, SZEGEDY C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//Proceedings of the 32nd International Conference on Machine Learning. Lille: ACM, 2015. arXiv: 1502.03167.
[13]BA J L, KIROS J R, HINTON G E. Layer normalization[J].Machine Learning, 2016. arXiv:1607.06450.
[14]ULYANOV D, VEDALDI A, LEMPITSKY V. Instance normalization: The missing ingredient for fast stylization[J]. Computer Vision and Pattern Recognition, 2016. arXiv: 1607.08022.
[15]SALIMANS T, KINGMA D P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona: MIT Press, 2016: 901-909.
[16]WU Yuxin, HE Kaiming. Group normalization[J]. International Journal of Computer Vision, 2020, 128(3): 742-755.
