基于SpringBoot结果集序列化过滤插件的研究与实现
2020-10-20王春波葛雷文雪巍
王春波 葛雷 文雪巍

【摘要】SpringBoot是由Pivotal团队在2013年开始研发、2014年4月发布第一个版本的全新开源的轻量级框架。它基于Spring4.0设计,不仅继承了Spring框架原有的优秀特性,而且还通过简化配置来进一步简化了Spring应用的整个搭建和开发过程。该框架使用内置的注解与Jackson插件可方便的将结果集序化成适合于移动互联网厂商作为业务接口的JSON格式字符串。由于框架的高度集成使得结果集序列化成JSON字符串时过于规则化,不能适用于较为复杂的业务场景,且对于复杂的结果集还会出现堆栈溢出错误,笔者分析了SpringBoot消息序列化过程,结合业务场景,给出了如何灵活定义结果集序列化规则,如何避免堆栈溢出错误的设计与实现方法,从而为使用SpringBoot框架作为开发技术栈的项目组提供了借鉴与参考。
【关键词】SpringBoot Jackson 堆栈 JSON 序列化
一、引言
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发领域成为领导者。
SpringBoot框架中有两个非常重要的策略:开箱即用和约定优于配置。开箱即用,是指在开发过程中,通过在MAVEN项目的pom文件中添加相关依赖包,然后使用对应注解来代替繁琐的XML配置文件以管理对象的生命周期。这个特点使得开发人员摆脱了复杂的配置工作以及依赖的管理工作,更加专注于业务逻辑。约定优于配置,是一种由SpringBoot本身来配置目标结构,由开发者在结构中添加信息的软件设计范式。这一策略减少了开发人员需要做出决定的数量,同时减少了大量的XML配置,并且可以将代码编译、测试和打包等工作自动化,但也降低了部分灵活性,增加了缺陷定位的复杂性。
对于复杂的项目需求,SpringBoot缺少灵活性的结果集转换方式,不但不能降低开发人员劳动强度和复杂度,相反极大的增加了开发人员的工作量以及出现去缺陷的可能。因此,需要找到一个确实有效方法允许开发人员灵活配置结果集序列化规则,但同时又不能破坏或改变SpringBoot框架原有的优势。
二、SpringBoot结果集序列化的现状与问题
SpringBoot默认使用Jackson插件进行结果集序列化。SpringBoot允许开发者使用其他插件例如Fastjson替换默认的Jackson进行结果集序列化,但无论使用哪种插件都面临着序列化规则僵化、不灵活的弊端。试想当相同的视图对象应用于不同的请求接口时,就会出现需要的请求字段不一样场景,例如以下部门定义实体:
public class SysDepart {
private String departAddr; //部门地址
private String departPhone; //部门电话
private Integer departLevel; //部门级别
private String departName; //部门名称
private String departExplain; //部门说明
private String departType; //部门类型
private SysSchool school; //归属学校
private SysDepart parentDepart ; //父级部
private List
}
针对获取部门基本信息的接口,仅需要返回departAddr、departLevel、departName、departExplain、departType這个五个属性字段即可;针对获取部门员工列表的接口,仅需返回List
对于这类问题通常有以下4中解决办法:
(1)返回全部属性字段:即由接口发起方进行二次判断,这种解决办法不仅增加了开发人员的工作量,也给系统带来了额外开销。特别的,如果视图对象存在双向关联关系,即SysDepart拥有属性字段SysSchool school,同时SysSchool拥有属性字段List
(2)结果集二次处理:适当增加注解,对结果集进行二次处理。该方法虽能够避免开发人员进行多余的判断,但却不能避免首次结果集序列化JSON时发起的不需要的关联查询,以及避免序列化两个构成双向一对多关系实体时出现的堆栈溢出错误。
(3)Jackson提供@JsonFilter 注解实现结果集的动态过滤,但该注解使用麻烦,需要一个对象写多个子类以区分不同的结果集,对于更复杂关联查询则显得捉襟见肘。
(4)无论是Jackson还是FastJson都提供了简单过滤器,但这类过滤器仅能进行全局配置,无法做到个性化输出。
综上所述,无论是SpringBoot官方还是插件提供商均未曾为该类问题提供方便有效的解决办法。笔者充分分析SpringBoot结果集序列化过程,通过扩展接口、自定义解析规则、增加必要注解,利用AOP编程思想编码实现了解决该类问题的插件,插件命名为Power-filter。Power-filter可以根据不同的业务场景配置返回不同的结果集,不仅能够有效避免双向关联实体bean因循环查询导致的堆栈溢出问题,也能减少非必要查询,降低开发人员的编码复杂度的同时也提高系统的查询效率。
三、Power-filter的设计与实现
(一)SpringBoot 消息序列化原理
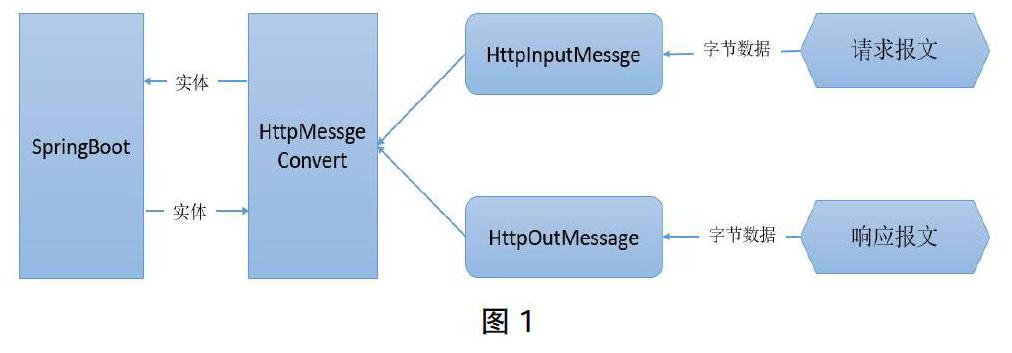
SpringBoot使用消息转换器对结果集进行序列化,原理图如图1:
从图2可知,客户端发送消息时,消息转换器的作用是将对象序列化为某一格式报文,然后将报文发送另一端;接收消息时,消息转换器作用是将某一格式报文转换为对象。
SpringBoot框架内置了很多HTTP消息转换器,不同消息类型转换器处理不同Content-type类型数据。如MappingJackson2HttpMessageConverter处理请求类型为application/json类型数据, StringHttpMessageConverter 处理类型为为 text/
html类型数据等。在框架内部会根据不同请求类型值选择不同类型转换器进行消息转换。目前,结果集的序列化过程就是通过默认名为MappingJackson2HttpMessageConverter的转换器来实现的。
SpringBoot框架提供了HTTP消息转换器的处理接口,允许开发者自定义消息序列化规则,因此可通过实现消息转换器处理接口,用于替换原有处理application/json类型数据的转换器来达到动态过滤属性字段的需求。
(二)Power-filter设计思路
Power-filter的设计目的是为了在原有的框架上扩展功能,适应多变的接口需求。通过深入分析 SpringBoot 消息序列化原理,结合需求,笔者得出如图2的设计思路。
图2中标识①②③的区域是Power-filter插件实现的关键点:①允许开发者根据不同业务接口需求灵活设置序列化规则。②请求发起时,框架能够获取到针对该请求设置的过滤规则,并缓存它。③SpringBoot调用自定义的消息转换器,获取相应规则,解析并应用规则进行消息序列化。
(三)Power-filter实现方法
针对图2的设计思路中提到的三个关键点,实现方式如下:
(1)对于①,笔者使用注解的方式进行实现。Java 注解又称 Java 标注,它允许Java 语言中的类、方法、变量、参数和包等都可以被标注。Power-filter新定义的注解如下:
注解1:PowerJsonFilter
@Retention(RUNTIME)
@Target(value = {ElementType.METHOD})
@Repeatable(value=PowerJsonFilters.class)
public @interface PowerJsonFilter {
Class<?> clazz();
String[] include() default {};// include為对象需要包含的字段
}
注解2:PowerJsonFilters
@Retention(RUNTIME)
@Target({METHOD })
public @interface PowerJsonFilters {
PowerJsonFilter[] value();
}
从代码中可以看出,两个注解只能使用在方法上,注解2是注解1的数组形态,可支持多规则设置。注解1接收两个参数:
clazz:用于指示哪些实体bean需要消息序列化。如 clazz = SysDepart.class
include:为字符串数组类型,用于指示需要消息序列化的实体bean中哪些属性可以被序列化,它的格式如下:include = {"字段1","字段2","字段m","字段x:{字段x-1, 字段x-2:{ 字段x-2-1,[字段y:{…}]}}","字段n"}。举例说明该格式的含义,对于注解:@PowerJsonFilters({@PowerJsonFilter(clazz = SysDepart.class,include= {"departId","departName" ,"parentDepart:{departName,school:
{schoolName}}"}))。它的含义是:对于SysDepart实体bean,需要对其属性"departId","departName","parentDepart"进行序列化,特别的对于parentDepart属性,其所属类型不是简单字符串、整形等常用数据类型,而是用户自定义的实体,parentDepart:{departName,school:{schoolName}}意味着仅需要序列化parentDepart所属实体的"departName","school"属性。对于school属性也做同样的解析。该规则支持多重嵌套,只要开发人员设置合理,即可避免实体bean的双向关联查询导致的堆栈溢出错误。
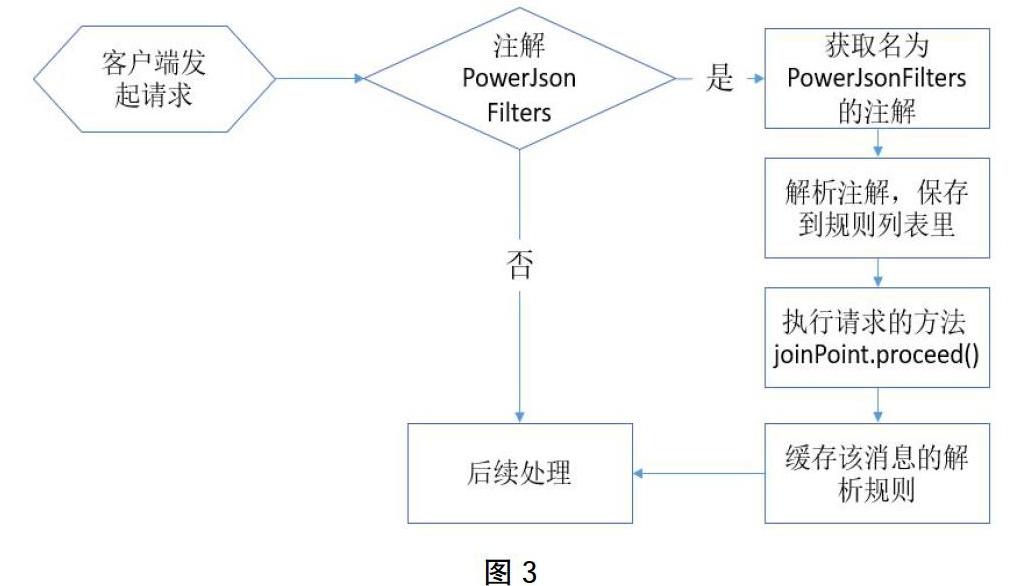
(2)对于②,使用AOP编程思想,定义新的切入点,实现流程图如图3:
(3)对于③,需要遵守SpringBoot框架的消息转换器的接口规范进行实现,实现流程如图4:
四、Power-filter应用与对比测试
(一)Power-filter安装与应用
Power-filter的设计初衷是解决SpringBoot对结果集进行序列化时遇到诸多不便问题,因此Power-filter仅是SpringBoot的有益补充,它的安装使用依赖于SpringBoot框架。Power-filter的安装使用步骤为:
(1)在SpringBoot启动方法上增加注解扫描范围,例如:@SpringBootApplication(scanBasePackages = {"xxx.xxx.xxx","com.hanb.filterJson"})
(2)删除原有消息转换器,增加自定义的消息转换器,代码如下:
public void configureMessageConverters(List
for (int i = converters.size() - 1; i >= 0; i--) {
//找到并删除默认的消息转换器
}
//声明自定义消息转换器并加入消息转换器转换链
PowerHttpMessageConverter myConverter=new PowerHttpMessageConverter();
converters.add(myConverter);
}
(3)在需要定义序列化规则的方法上增加注解,代码示例如下:
@RestController
public class XxAction {
@PowerJsonFilters({@PowerJsonFilter(clazz = SysDepart.class,include = {"departId","school","parentDepart:{departName,school:{schoolName}}"}),
@PowerJsonFilter(clazz = School.class,include = {"schoolAddr"})})
public Object queryDepart(参数列表) throws Exception{
//业务逻辑代码
} }
通过(1)、(2)的安装,(3)的应用,程序运行后即可得出规则设定的结果,如下示例:
[{"departId":1,"school":{"schoolAddr":"学院路"}},{"departId":2,"parentDepart":{"departName":"1级部门","school":{"schoolName":"财经"}},"school":{"schoolName":"财经"}}]
(二)SpringBoot使用Power-filter插件序列化效率前后对比
Power-filter能够通过设置过滤规则灵活对结果集进行过滤,为了对比应用插件前后的效率,笔者在同一软硬件环境下分别做了单表查询结果集序列化,多表关联查询结果集序列化对比测试。
(1)單表查询100条记录序列化对比如图5:
(2)多表关联查询100条记录序列化对比如图6。
通过对比测试可发现,对于单表查询,两者对查询结果的序列化耗时相差并不大,对于多表关联查询,框架由于应用了过滤规则避免了无用属性的关联查询与序列化,其效率大大提高。
五、总结
Power-filter是依赖于SpringBoot框架的插件,该插件使用AOP编程思想进行编写,主要做了以下3点工作:
(1)新增注解,用于对查询结果集序列化规则进行配置。
(2)新增过滤规则,使用堆数据结构完成对实体bean的多层嵌套比对。
(3)实现自定义的消息转换器,替换SpringBoot原生插件,完成结果集的序列化。
通过对比测试发现,使用了Power-filter插件的SpringBoot有以下4点优势:
(1)配置规则简单易懂,学习成本极低。
(2)对结果集序列化按规则进行配置,使得业务接口更加灵活,降低开发者的大量重复性工作。
(3)通过规则配置,可有效避免无用属性字段的关联查询,节约了系统开销。
(4)通过规则配置,可有效避免双向关联实体bean引起的循环查询,从而导致的堆栈溢出错误。
Power-filter作为SpringBoot的非原生插件,虽然有着自身的优点,但也存在着不足:
(1)需要做额外配置,插件方可生效。
(2)过滤规则暂不支持通配符配置,规则书写略显麻烦。
(3)规则配置方式单一,目前仅支持包含设置,不支持排除设置。
对于不足中的(2)和(3),笔者将继续完善该插件,争取早日弥补其不足。
总之,Power-filter作为SpringBoot的有益补充,虽然有些许不足,但仍能够为使用SpringBoot框架作为开发技术栈的项目组提供借鉴与参考,为其快速完成接口开发提供有效的解决方案。
参考文献:
[1]小马哥. Spring Boot编程思想(核心篇)[M].北京:电子工业出版社,2019:155-187.
[2][美] Bruce Eckel.Think In Java)[M].北京:机械工业出版社,2007:162-199.
[3]王晓东,计算机算法设计与分析(第5版))[M],北京:电子工业出版社,2018:202-351.
作者简介: 王春波(1978-),男,汉族,黑龙江海伦市人,硕士,信息系统项目高级管理师,研究方向:软件工程、大数据理论、神经网路算法;葛雷(1973-),男,汉族,黑龙江哈尔滨人,硕士,教授,研究方向:软件工程、教育理论;文雪巍(1979-),女,汉族,黑龙江哈尔滨人,硕士,教授,主研究方向:软件工程、人工智能。
