基于随机森林的银行贷款数据分析
2020-10-12梁佩
梁佩

摘 要:随着科学技术的快速发展,伴随着银行贷款的相关活动越来越频繁,但是贷款的拖欠及坏账的产生等现象出现,银行面临的贷款风险越来越大,而这时信用也越发显得重要。所以本文基于随机森林的方法将一批信贷数据进行数据分析,将 1000 个观测值分成两类,画出各个变量的重要性图,根据信用的好坏决定是否贷款,最后对这批数据做出总结与预测。
关键词:银行贷款;信用风险;数据分析;分类;总结预测
中图分类号:F23 文献标识码:A doi:10.19311/j.cnki.1672-3198.2020.33.053
0 引言
在经济的快速发展的今天,人们的消费观念已经从以前的“有就用,没有就不用”转变为“提前消费”,因此很多人会选择银行贷款解决自己在创业、购房中遇到的经济问题,这样会暂时缓解他们的经济压力,同时银行会承担银行贷款所带来相应风险,其中主要的就是不良贷款,倘若不良贷款率过高,会对银行的正常运营有一定的影响,因此对客户信息进行判断是有必要,而且影响银行贷款的因素有很多种,例如,客户财产状况、贷款目的、住房情况、工作情况、信贷金额等。因此明白银行和客户之间存在一个问题:银行针对客户的情况进行判断客户是否能够成功贷款,判断的结果会有一定的误差,同时客户对于自己是否能够贷款存在疑问。因此为了解决这一情况,就需要对银行的贷款数据进行分析预测,在知道真实数据的情况下,利用随机森林模型对银行贷款数據进行分析预测,从而得到较好的预测模型。
1 基于随机森林的银行贷款数据模型构建
1.1 随机森林基本原理
随机森林是根据bagging算法进行改变转化而来的,是一个树状的分类器{h(x,βk,k=1,…)},它是以自主法重采样为主,通过有放回地重复随机抽样组成一个有N个样本的新样本训练集合,再根据新的样本集构建出k个决策树,最终形成一个随机森林,最后由决策树投票的多少决定测试数据的分类结果,当有一个新的样本数据需要预测时,样本数据则需要经过随机森林中的每一棵决策树,最后在统计出的分类结果推断出可能性最大的分类。
1.2 随机森林模型的实现
(1)观察数据,选择并使用的时是来自UCI数据库中的关于是否贷款的数据集进行随机森林算法分析,该数据集时关于银行贷款中的各个变量对客户贷款的影响情况,首先对本数据进行预处理。
(2)利用R软件对数据集中的信息进行简要的概括,发现其中的有些变量并不是数据变量,并且最后一项是现实生活中的真实数据。在这个数据集中包含了1000个数据以及21个样本特征,为了更加了解V21变量,利用软件对V21进行分析,V21是真实结果,因此在本论文中它是作为结果变量,因此本文决定将样本中的“1”定义为“good”,“2”定义为“bad”,及对应客户是否贷款。
(3)建立模型,利用R软件对数据集进行建模,建立模型的过程中可以利用既定公式构建模型,也可以根据数据构建模型,而本论文所所选用的方式是第一种,为了更好的体现出模型的预测精度和泛化能力,本论文将数据集中的700(约70%)的数据作为训练集,300(约30%)的数据作为测试集,并且利用测试集对模型的预测精度和泛化能力进行一个了解。随机森林模型的影响因素主要有两点:树的节点看和决策树m的数量,在本次建模中将其设为m=500,k=4,以这些条件构建随机森林模型1。
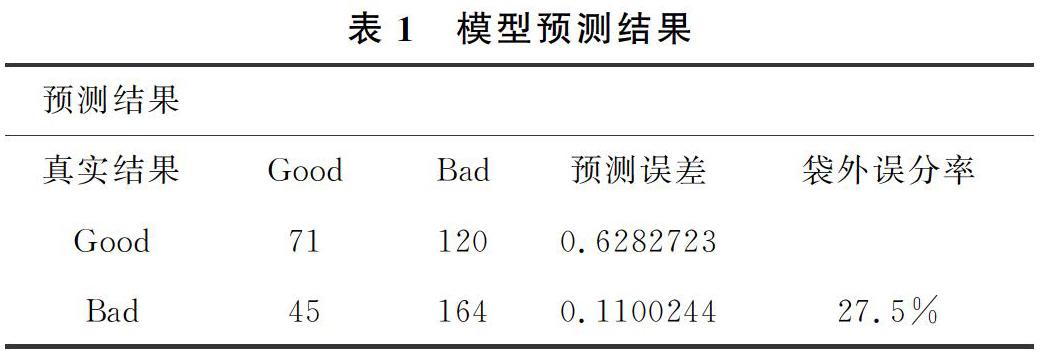
在表1所示,我们可以得到该模型的总的袋外误分率为27.5%,并且由表显示模型将类别bad中120个判给good,预测误判率是62.83%,将类别good判给bad的由45个,预测误判率是11.00%。
1.3 随机森林结果分析及其模型的优化
为了将模型的预测误判率降低,得到一个较好的模型,我们需要对模型1进行优化在上述过程中构建的随机森林模型并不是最优模型,因此我们需要对随机森林模型进行优化。有两个因素决定随机森林模型的预测能力:
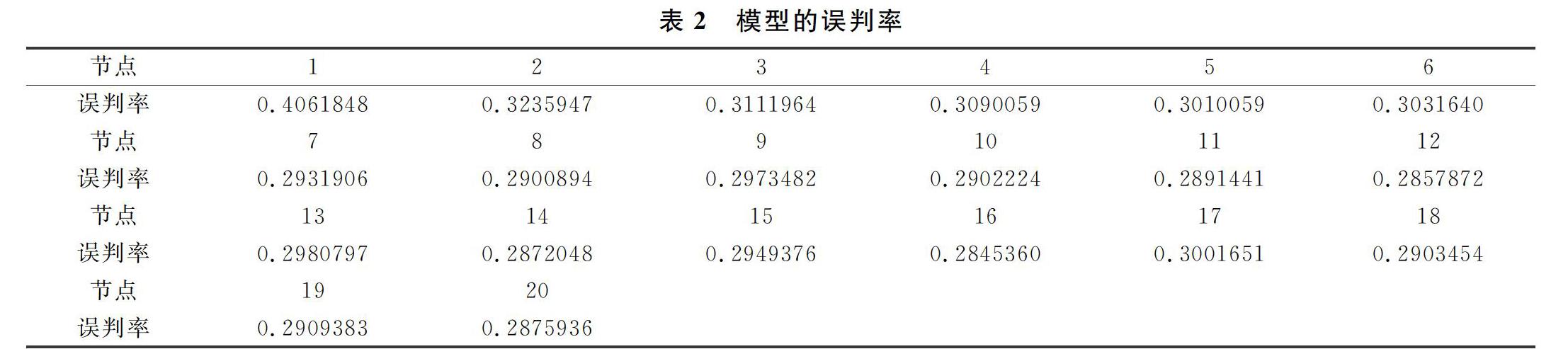
(1)第一个是决策树的节点,利用软件计算出在那个节点随机森林的误差率最小,即可得到最优节点,在R软件中,我们利用rate函数,展示出所有模型误判率的均值,通过图1可知随着树的节点的改变,在模型1的输出结果中可以得到该函数的默认节点的变量是4,并不是最优参数,但是由本数据构建的模型误判率均值最低的是在决策树的节点所选变量数为16时,因此在模型的优化过程中,模型的最优节点是16。
(2)通过上述实验,得到最优数节点k=16,最优决策树数量m=140时,得到随机森林模型2。
通过对模型的优化,发现随机森林模型2的预测误差比模型1 的要低,由表3显示模型将类别bad中149个判给good,预测误判率是49.67%,将类别good判给bad的由74个,预测误判率是10.57%都比模型1的要低。
1.4 变量重要性对比
在图1中列出了所有的自变量在两科不同算法下,得出相应自变量的重要值,在图中自变量对应的指标值说明该自变量对模型的判别影响较大,在图中的将平均精确率减少值和平均不纯度减少值进行降序排列,MDA值越大就说明该自变量对分类的准确性影响越大,该自变量也就更加重要,与此同时,当自变量的MDI值越大,表明该自变量对模型的分类结果影响也就越大,因此这样可以作为评价自变量的一种方式。
当我们利用R对贷款数据中的20个自变量进行MDA值和MDI值进行从小到大的排序,由图我们可以看出在这20个自变量中最影响客户是否能够成功贷款的因素有V1、V5以及V3,即为现有活期存款、信用记录和信贷金额,因此我们可以知道借款人的信用记录已然成为金融机构值得重视的一点,倘若借款人的信用记录不好的情况下,银行产生不良贷款的几率也会越大。相应的银行所承担的风险也会越大。因此当银行是否给予客户贷款的时候,可以查询贷款人的信用记录进行判断,并且信贷金额与活期存款也是需要考虑的问题,以此降低银行的信用贷款不良率。
2 总结与展望
本文利用随机森林算法针对银行贷款数据中20个变量构建随机森林模型,根据已有的条件对客户是否能够成功贷款做出预测,并与真实值做对比,得到一个预测精度高、泛化能力强的模型,对银行在面对客户贷款的时候,可以根据这一个模型做出一定的参考,以此降低不良贷款的几率,降低银行风险。
对于银行决策者而言,在了解个人/企业的基本信息之后,再推断是否向客户提供贷款,在这一过程中银行的目的是尽可能的降低不良贷款率,从而保障银行自身的发展,本文通过对国外银行贷款数据进行分析,发现在银行客户信息中的现有活期存款、信用记录和信贷金额对客户的影响较大,因此在银行对客户进行推断的时候,可以主要对这几个方面进行推断,例如信用记录,当一名客户信用记录良好的情况下将贷款拨给他,他按时还款的几率比较大,从而不会影响银行的正常操作,并且有利于银行的发展。
对于个人/企业而言缓解了一定时期内的经济压力,有利于自身的发展/壮大,通过银行数据的研究分析发现,客户需要关注自己的信用记录,一个人的信用记录是否良好,是银行贷款中最基本的一项,因此个人/企业需要保证自己的信用记录良好,倘若之后需要贷款,信用良好能够成为自己的一个加分项。
参考文献
[1]王春峰,万海晖.商业银行信用风险评估及其实证研究[J].管理科学报,1998,1(1):68-72.
[2]章彰商.业银行信用风险管理[M].北京:中國人民大学出版社,2002.
[3]李志辉.现代信用风险管理量化度与管理研究[M].北京:中国金融出版社,2001.
[4]李乐.我国商业银行信用风险管理的现状、问题及原因分析[J].金融经济,2008,(5).
[5]赵德川.论商业银行风险管理和政策——信用风险[J].商情,2013,(46):32-32.
[6]陆正飞,杨德明.商业信用:替代性融资,还是买房市场[J].管理世界,2011(04).
[7]商业银行财务风险管理研究[D].长春:吉林财经大学,2014.
[8]雷娜.企业利用商业信用筹资的利弊分析[J]. 财会研究,2015,(08).
[9]张余琴,杜宽旗.企业银行贷款与贸易信贷选择实证研究——以江苏省企业为例[J].金融经济,2013,(20).
