基于云计算技术的分布式网络海量数据处理系统设计
2020-09-23卢鹏芦立华
卢鹏 芦立华


摘 要: 传统的数据集中处理系统数据处理频率较低,导致对海量数据的反馈效果不佳,为此基于云计算技术,设计网络海量数据的分布式处理系统。该系统在原有系统硬件基础上,替换其中的数据处理器,并增加该处理器的总使用数量,实现对海量数据的分布式同步处理。在软件设计方面,通过协议使系统单元、模块之间形成交互,改进系统的数据通信方式;计算欧氏距离,设置系统的分布式处理方式;根据云计算定义,使用分类函数确定约束条件,建立处理频率方程,实现对海量数据的快速处理。实验结果表明,与传统系统相比,所设计系统对海量数据的处理频率更快,反馈给用户的效果更好。由此可见,该系统的应用可以增强用户的体验感受。
关键词: 分布式网络; 数据处理; 系统设计; 云计算技术; 处理方程建立; 对比验证
中图分类号: TN915?34; TP311 文献标识码: A 文章編号: 1004?373X(2020)18?0036?04
Abstract: As the traditional centralized data processing system has a low frequency of data processing, which results in poor feedback effect on mass data, a distributed processing system of mass data of network is designed based on cloud computing technology, in which the original system hardware is reserved, but the data processor is replaced and the total quantity in use of the processor is added, so that the distributed synchronous processing of mass data is realized. In terms of the software design, the interaction between system units and modules is formed by means of the protocol, which improves the data communication mode of the system. In this paper, the Euclidean distance is calculated, and the distributed processing mode of the system is set. The classification function is used to determine the constraint conditions according to the definition of cloud computing, and the processing frequency equation is established to realize the rapid processing of mass data. The experimental results show that, in comparison with the traditional system, the designed system can process mass data more quickly and give better feedback to users. Thus it can be seen that the application of the system can enhance the users′ experience.
Keywords: distributed network; data processing; system design; cloud computing technology; processing equation building; contrast validation
0 引 言
目前网络技术发展迅速,越来越多的数据均可以在一个网络平台中体现,因此形成一个具有庞大数据体量、复杂数据类型、极高数据密度的网络环境。为了让用户拥有更好的使用体验,传统的海量数据处理系统,将集中分析算法与模糊聚类方法相结合,形成对复杂海量数据的集中处理模式。此系统的运行,在短时间内解决了数据量过大,导致用户体验不佳的问题,但随着行业的优化升级、技术水平的优化创新,大量类型不同的数据涌入网络环境中,给数据处理系统带来了巨大的处理压力[1]。
为了加快系统响应速度,提升系统对海量数据的处理频率,在传统数据系统设计的基础上,基于云计算技术,设计分布式的海量数据处理系统。云计算利用网络,将其中的数据处理程序分解成无数个子程序,通过添加多个处理器,加快分析速度,并将反馈结果迅速返回给用户。这项技术在极短的时间内完成了对数以万计数据的分布式处理,从而实现该系统的强大处理功能。该系统的出现,缓解了海量数据对网络环境造成的压力,解决了现阶段海量数据与处理系统之间的矛盾,为网络及其他领域的数据处理,提供强有力的技术支持[2]。
1 设计分布式网络海量数据处理系统硬件
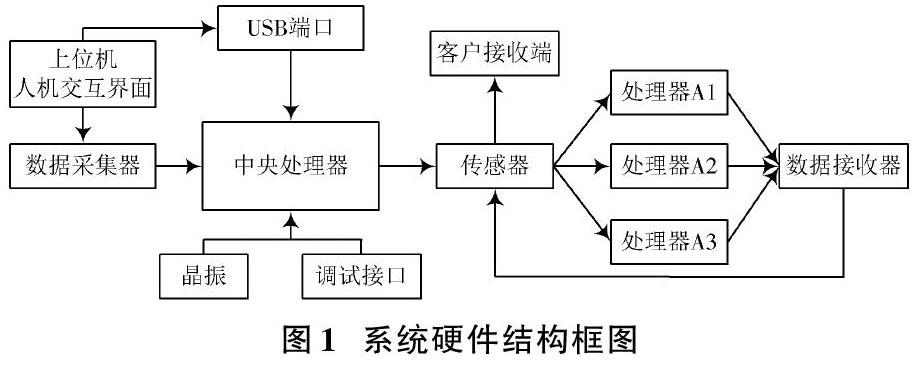
在原有系统硬件的基础上,将原有数据处理器替换成多个功能强大的数据处理器,保证子程序协同运行,根据海量数据的类型不同,实现同步的分布式处理。该设计的硬件结构框图如图1所示[3]。
由系统硬件结构可知,此次设计调整原有系统的硬件集中连接形式,海量数据经传感器迅速调配,由中央处理单元发送,将多个处理器与传感器相连接,保证数据被实时同步接收,并协同运行处理。该处理器的型号为KR?i59400F,运行频率在5.0 GHz以上,总线速度在8 GT/s DMI3。该处理器可以快速对海量数据进行同步分析,直接获取数据的特征量,且耐热性好、效率高、可长时间工作,从系统硬件上提升了系统的运行速度和处理强度[4?5]。
2 基于云计算技术设计处理系统软件
在系统硬件设计基础上,对该系统软件优化,以提升系统处理海量数据的频率。
2.1 改进处理系统的通信方式
为提高系统对海量数据的处理频率,将该系统的通信方式重新设计。将主控单元的通信与子处理单元的通信重新连接,确保数据的接收以及同步处理[6]。在处理单元数据处理完成后,通过数据传送单元,将该信息反馈给用户,保证系统中的数据通信之间形成一个完整的通信闭环[7?8]。同时,为了保证主控通信进程与数据处理进程之间的同步性,还需要在二者之间进行协议交互,如图2所示。
通过该协议,确保该系统在数据接收、数据处理以及数据反馈上的同步性[9]。
2.2 基于云计算技术设置系统分布式处理方式
云計算技术将海量数据的计算处理转换成无数个子处理程序,在相同处理时间内,加快了数据处理频率[10]。该技术预先设置子程序之间的欧氏距离:
式中:[duv]表示任意2个相邻子程序[u]和[v]之间的欧氏距离;[Rus],[Rvs]表示对程序[u],[v]的第[s]个变量。设置此时的距离矩阵为[K],确定最小距离元素[dmin],当子程序中的数据对应的位置为[a],[b],且其数值小于阈值[Y]时,则合并该距离矩阵实现降维。设置程序中距离最近的两个数据类簇为[Csa],[Csb],合并后的新类簇为[Csab=Csa,Csb],因此新分类为[Cs1,Cs2,…,Csm]。该处理系统根据新的类簇设置分布式的数据处理子程序[11]。
2.3 实现对海量数据的快速处理
在分布式处理方式设置完毕的基础上,对海量数据线性分类,令每一处理单元中的数据同属一个类型,或具有同一目的,或具有相似价值。随机选则两个样本数据,将其分为2个大类,通过[k]维向量[x]表示相应的数据特征,[y]表示相应的分类标志,该线性分类超平面与分类函数的计算表达式为:
式中:[wT]表示针对数据类型建立的转置矩阵;[b]表示一个固定常数;[fx]表示分类函数。当[fx>0]时,对应的分类标志[y=1];当[fx<0]时,[y=-1];当[fx=0]时,则该数据的支持向量在超平面之上[12]。根据式(2)可知,该线性分类如图3所示。
图中,三角形与圆圈代表随机选取的两类样本向量。设置约束条件,根据云计算技术建立极速处理函数[μ],实现对海量数据的瞬时处理。
式中:[c]为数据总体量;[ω]为误差修正系数;[fy]为处理约束条件;[ki]为处理频率在[i]数据段的极限值;[q]为控制调和系数;[t]为瞬时反应时间;[n]为处理路径。依据上述式(3),设置海量数据处理程序,控制子程序的处理进程。至此基于云计算技术,实现对网络海量数据的分布式处理系统设计。
3 仿真实验
利用仿真实验检测所设计系统的可行性,并将本系统与传统的数据集中处理系统进行对比。
3.1 实验准备
实验将系统运行分为3部分:Hadoop云处理平台;HBase分布式海量信息数据库;Web管理控制系统,利用上述系统搭建实验测试环境。Web系统在开发包JDK、服务器Tomcat的支持下正常运行,配置每台测试机器的IP地址和主机名,保证系统程序正常运行。构建Hadoop平台的运行环境,安装并配置HBase数据库,并将其分发到集群中的所有阶段上实施解压程序,如图4所示。
实验时随机选取某年度、某平台的海量交易数据作为实验对象,该平台具体数据信息如表1所示。分别利用2种数据处理系统,处理上述表格中的数据。
3.2 结果分析
2个系统的数据处理结果如图5所示。
由图5可知,当所处理的数据量为564.33 GB时,所设计系统在第0.1 s迅速做出反应,瞬间将系统处理频率提升到7 GHz以上;而传统系统在0.4 s时才做出处理,处理频率在3.073 5 GHz左右,比所设计系统的处理频率慢了50.05%。为保证实验结果真实,利用2个系统处理11月份数据的实验结果如图6所示。
图6曲线是对数据量为1 022.59 GB的11月份数据的测试结果。根据曲线走势可以看出,面对体量更大的平台数据,所设计系统还是在第0.1 s做出处理反应,处理频率在7 GHz以上;而传统系统在0.47 s做出反应,处理频率降至3 GHz以下,比设计的处理系统慢了61.12%。综上,基于云计算技术设计的海量数据处理系统的处理数据频率更快,响应更迅速。
4 结 语
此次设计的海量数据处理系统,从数据处理频率入手,通过云计算技术,将体量庞大的网络海量数据分解成若干个小程序,通过多部服务器组成的系统软件,加快了系统的分析能力和响应速度。实验结果表明,所设计系统比传统系统的处理频率提高了50%以上,解决了传统系统中受分析能力较弱、响应速度偏慢导致处理频率偏低的问题。
参考文献
[1] 班娅萌,赵月鹏,平金珍.基于云计算的分布式电源管理系统设计与实现[J].电源技术,2017,41(2):310?311.
[2] 窦金凤,于文华,曹家宝,等.基于云计算平台的工程材料询价系统[J].计算机应用,2018,38(S1):158?161.
[3] 余昌发,程学林,杨小虎.基于Kubernetes的分布式TensorFlow平台的设计与实现[J].计算机科学,2018,45(z2):527?531.
[4] 徐一凤,丰大军,张瀚文,等.基于跨平台的实时数据处理系统的设计[J].电子技术应用,2017,43(9):98?100.
[5] 王佳玉,张振宇,褚征,等.一种基于轨迹数据密度分区的分布式并行聚类方法[J].中国科学技术大学学报,2018,48(1):47?56.
[6] 林静怀.基于云计算的电网调度控制培训仿真系统设计[J].电力系统自动化,2017,41(14):164?170.
[7] 覃伟荣.云计算网络环境和大数据结合的物联网信息化建设[J].激光杂志,2018,39(5):120?123.
[8] 王传连,张宗朔.基于私有云的大规模交通视频处理框架设计[J].计算机工程与应用,2017,53(21):254?257.
[9] 张海阔,陆忠华,刘芳,等.面向海量告警数据的并行处理系统设计与实现[J].计算机工程与设计,2018,39(2):407?413.
[10] 陈涛,乔佩利,孙广路,等.实时网络流特征提取系统设计[J].哈尔滨理工大学学报,2017,22(2):99?104.
[11] 顾东晓,李童童,梁昌勇,等.基于云计算的管理信息系统迁移模式与策略研究[J].情报科学,2018,36(12):71?76.
[12] 莫勇,张海燕.基于云计算的电力数据在线安全分析并行化[J].控制工程,2017,24(4):823?828.
