数据治理中数据智能分类技术的应用研究
2020-08-04李柳音
李柳音
【摘要】由于许多企业存在数据资产过量的现象,治理起来较为繁琐复杂,所以出现了一种基于数据智能分类技术的数据处理方法。先借助于数据智能分类技术对企业的数据展开分类,接着运用关键词提取方法对数据展开关键词提取,然后联系专家的评判建议来确立每一类数据中可表现当下类别的关键词,同时做出敏感度标记,以此来处理企业数据量级过盛问题,查找出当中的敏感性数据。在这一背景态势下,本文展开数据智能分类技术在数据治理当中的运用分析,以为业内人士提供可鉴参考。
【关键词】数据治理;智能分类技术;应用研究
中图分类号:TN01 文献标识码:A 文章编号:1673-0348(2020)09-015-03
[Absrtact] due to the fact that many enterprises have excessive data assets and the management is complicated, a data processing method based on data intelligent classification technology has emerged. First, the data of the enterprise is classified by means of the data intelligent classification technology, then the keyword extraction method is used to extract the data, and then the expert's evaluation suggestions are contacted to establish the keywords that can represent the current category in each type of data, and at the same time, the sensitivity mark is made, so as to deal with this paper analyzes the application of data intelligent classification technology in data governance to provide reference for the industry.
[Key words]data governance; intelligent classification technology; Application Research
如今社会讯息化速度加快,网络化发展迅捷,数据呈现爆炸式增长。全世界的数据量大概每两年涨一倍,这表示人类在近两年间产生形成的数据总量和此前产生形成的数据总量相当。按照IDC数据显示,到2020年底,全世界会共掌控有35ZB的数据量,比2010年数据量上涨了大约30多倍。大数据一方面为大众带来极大的便利性,一方面也造成了讯息的安全和隐私问题。像其他讯息一样,大数据在储存、处理、传输当中会存在大量的安全风险,伴随而来的管理、监管要求也越来越高越来越严苛。信息安全国际标准表示,不同数据的价值性是截然不同的,价值越高的数据越需要更为严苛的保护。国资委《中央企业商业秘密保护暂行规定》中明确表示要把数据进行分类化、分级式管理,同时加以标识。银监会《十二五信息科技发展规划监管指导意见》中也明确表示要推动信息资产分类、分级管理的发展进度。所以在大数据时代下,企业亟需进行数据治理。
1. 数据治理相关理论简述
1.1 数据治理的概念
最近几年伴随着大数据时代的发展,各大企事业单位都累积了大量的数据资源,社会各界也都意识到这些累积的海量数据资源具备可利用价值,并着手进行对数据资源的深层次挖掘和分析,建立了具备有企业特色的知识数据。数据是一个企业最为关键的资产之一,如今怎样盘活企业内部数据资产,挖掘数据资产的深层次价值是一项亟待完善的业务,自保值朝着增值跨越的目标也发展为当下企业数据治理工作的首要任务。数据治理工作内容有多种,包括有对数据资产的搜集、處理、储存、运用、核实、监管等等多项。数据治理是企事业单位为了增强数据资产质量、促进数据交融、充分施展数据资产的内在价值而建立的一套体系化技术方式、规范准则、管理制度。
1.2 数据治理的价值性
因为数据生产源头变得多元化,数量锐增且结构差异化较大,同时系统更新升级的速度加快,技术的运用频度也明显提高,所以令不同的数据源或者相同的数据源间产生了矛盾和问题,加上数据搜集、集成是多个团队协作的结果,这一过程也是增加了数据处理中引发问题数据的几率性。运用传统数据人工错误检测修复或其他程序进行解决,很明显是完全跟不上大数据环境之下的各类复杂的数据问题的。所以怎样确保数据的完整、数据质量的真实稳妥,创建高效数据治理底层解决体系是非常有必要的。
1.3 数据治理的体系框架
1.3.1 数据模型管理
这一模型包含有概念数据模型、逻辑数据模型两类。可以对数据源展开统一化管理,多是运用可视化方法来管理异构数据源,内容包含各个数据源的物理储存地址、认证鉴权讯息等,规避了传统管理方法中要采用诸多个不同客户端操作的不足。也可以用可视化语言来定义模型的概念,按照显示诉求,拓展出更符合客户业务语言的类型。
1.3.2 进行数据血缘管理
血缘、影响分析管理目标是借助于数据血统追踪,于分布数据共享过程中处理数据的质量、版本等多方面讯息。血缘分析即对来源加以溯源,来测量数据是否可信以及质量如何。影响力分析指的是自特定模型着手,找寻倚重这一实体的处理过程模型。比如可采取递归形式加以寻找处理。
1.3.3 数据质量管理
数据质量管理包括数据绝对质量管理、过程质量管理。在数据质量稽核方面,要提供自统一管理数据标准规范辐射至每一数据字段的质量属性的能力以及数据质量稽核配置,来保障辐射行业的质量标准,同时保障数据在转换、储存、传输等过程中不会发生错误等等。数据质量回溯方面,需对数据质量稽核发觉的问题展开根本性溯源分析和维护,如此保障历史经验、数据累积的准确性,从而推进指导管理的发展。
1.3.4 数据安全管理
主要处理的是数据储存、运用、交换当中的安全问题。具体表现下四点上,其一数据运用的安全性,如数据储存、访问、权限管控。其二数据隐私问题,如银行账号等讯息有无加密,以防止被非法访问。其三访问权限管理。其四数据安全审计,数据修订、运用等步骤中军需设置审计方法,事后予以审计和究责。
2. 数据智能分类技术的具体方法和过程分析
本文把自然语言处理技术运用到数据治理当中,借助数据智能分类技术对企业的资产展开数据治理工作。其一,对企业当中有待分类的数据通过智能分类方法加以分类,其二采用关键词提取技术来对每一类数据加以关键词提取,然后联系专家的判断来确立每一类数据当中可用作甄别当下分类的关键词,同时对敏感度予以标注。另外本文采取朴素叶贝斯、SVM算法效果比较展开对数据智能分类算法的筛选,结果显示后者在关键词提取当中的精确度更高、召回率更强。
2.1 待分类数据
待分类数据,指的是企业当中那些有待整理的过量数据,比如分布于企业服务器、邮件、数据库、终端等多地的一些数据,或齐整或杂乱,均在等待被整理和挖掘。
2.2 数据智能分类
数据智能分类是运用智能分类技术把待分类数据整理成不同的类别,比如把企业当中那些杂乱的、无序的、过多的数据,整理分成专利、企业讯息、审计稽查报告、公文、图纸、财务数据等多个不同类型的数据。具体的步骤如下。
2.2.1 进行预处理
文档数据预处理包含了对文档的切分、文本的分词、去停用词等几个步骤。如果文档集合是一个单独性文件,全部文章都被储存在这一文件中时,可进行文档切分,来把当中的文章提取出来独立的储存于一个文件中。换句话讲,单一文件的文档集合当中,各个文章间会采用不同的标记加以区分,例如特定的符号或者空行等。文档分词是把文档中具备独立型含义的词汇予以单独汇总出来。去停用词是因为并非文本中每一个单词都可对该文档进行代表和体现,所以要将这些词自文本当中除去。
2.2.2 特征的表示与提取
其主要功用是提取足以表现文档核心关键讯息的词汇,通过一定的特征项来对文档予以代表。文本挖掘之时要对这些特征予以处理,进而完成对于非结构化文本的处理,此为非结构化朝着结构化转型的一大必经步骤。在词条权值的处理上,本文选用的是TF IDF方法。
2.2.3 特征匹配、分类
文本转作向量方式,且经过特征提取之后,则可展开分类挖掘了,也就是特征匹配工作。本文选用文獻检索技术相似度法。假定样本文档是U,待学习文档是V,其相似度可以通过向量夹角度数来进行衡量,简言之,夹角愈小,相似度愈高。
2.2.4 文本分类体系
智能分类算法筛选当中,应用频率最高的分类算法有两种,即为朴素贝叶斯算法、SVM算法。前者是借助于计算向量分类至两大类别中的机率值来统计分类结果。后者则是一种在统计学习理论基础上建立起来的模式识别方法。该方法最早诞生于1995年,在分类领域中运用价值非常高。
2.3 关键词提取
关键词提取,指的是不同类别数据当中查找出定位最精准、权重比例最高、区分力最强的关键词,借助于自然语言处理技术,对分类数据文本内容加以切词,采用机器统计,实现对关键词的自动提取。候选关键词提取之时是进行自动排序的,依靠下述几点展开,其一指定分类中出现次数,出现次数愈多,排序则愈居于前列;其二,其他分类中的出现次数,次数愈少,排序愈居前;其三关键词的长度,长度愈长,排序愈居前。就像能源行业市场分析报告当中,关键词特征提取时,原油期货价格必然是排在期货价格之前的。
2.4 专家判断结果
专家按照软件给出的统计数据、评定的分数,联系自我专业的知识储备,自对每一个类别候选关键词列表中筛选出的可用作甄别当下分类的关键词,展开敏感度标注。实现对企业数据的分级、分类管理,建立健全按照数据敏感度差异订立的截然不同的保护制度。
3. 实验数据结果研究
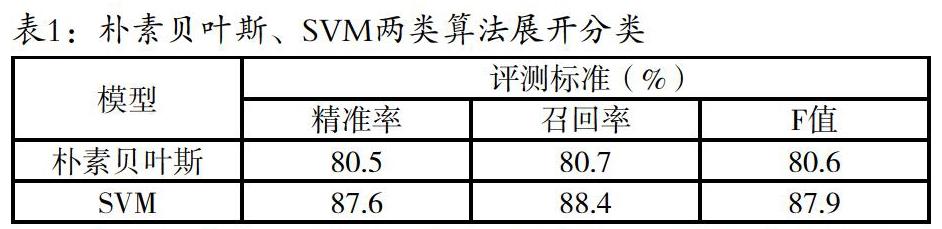
实验数据挑选的十大类别的文档数据,包含合同类、专利类等,每一类的样本数量大概在85篇左右,即合计850篇文档,把这些文档散布于企业内服务器、邮件、数据库、终端等当中。采用讯息检索领域的评价准则对数据分类展开评价,即精确率P、召回率R、评测值F。具体公式为:P=A(AцB) R=A/(AцC) F=2*P*R*(P+R),当中,A指的是正确分类的文档数量,B指的是分类失误的文档数量。C指的是文档本应分在这一类,但却并未划分到这一类当中的文档数量。文章采用朴素贝叶斯、SVM两类算法展开分类,具体的实验结果详见表1。
如表1当中,相较于朴素贝叶斯,SVM算法精准率、召回率都要偏高许多,而这也证明,SVM算法在数据智能分类当中效果更佳。
4. 结语
为了处理大数据时代企事业单位数据资产引发的一些问题和不足,本文应用自然语言处理技术来展开数据治理工作,也就是借助于数据智能分类技术对企业的超多数据展开分类统计,运用关键词提取方式对每一个类别的数据展开关键词提取,最终联系专家的判断来对每个类别中关键词数据予以确立,同时加以敏感度标注。借助于上述步骤和方法完成对企业数据资产的分级化、分类式管理,帮助企业建立健全的数据治理系统。本文选用Naive Bayes(朴素贝叶斯)、SVM(支持向量机)两种算法展开核算,最终发觉后者在数据智能分类当中的效果更优。
参考文献
[1]冯登国,张敏,李昊.大数据安全与隐私保护[J].计算机学报.2017(05)
[2]张伟丽,冯伟.万物互联网带来的新风险及其技术对策[J].信息安全与通信保密.2018(4)
[3]李振,鲍宗豪.云治理:大数据时代社会治理的新模式[J].天津社会科学.2018(33)
